Выполняйте бэкоффлайн без замедления живого трафика
Проведите бэкоффлайн без тормозов живого трафика: ограничивайте чтения, группируйте записи, задавайте правила паузы и наблюдайте нагрузку до того, как пользователи почувствуют её.
Содержание
Почему бэкоффлайны вредят живым пользователям
На бумаге задача байка кажется безобидной: читаются старые строки, заполняются пропущенные поля и результат записывается обратно. В продакшене она конкурирует с реальными пользователями за тот же CPU базы данных, диск I/O, память и блокировки.
Эта конкуренция быстро становится заметной. Крупное сканирование пробегает по страницам, которые приложение редко трогает, и вытесняет часто используемые данные из кэша. Следующий пользовательский запрос вынужден снова читать горячие данные с диска, поэтому время ответа растёт, даже если код приложения не менялся.
Записи обычно вредят больше, чем чтения. Когда задача обновляет тысячи строк в резком всплеске, это создаёт давление блокировок и дополнительную работу для индексов, реплик и хранилища. Запросы, которые ещё минуту назад были быстрыми, начинают ждать завершения записи. На системах с репликами такой всплеск может повысить задержку репликации, и пользователи будут читать устаревшие данные или видеть экраны, которые не соответствуют их последнему действию.
Не нужен полный аутедж, чтобы люди заметили проблему. Страница, которая обычно грузится за 300 мс, может уехать в 2–3 секунды во время бэкоффлайна. Некоторые пользователи попадают в таймауты. Другие повторяют запросы, что добавляет ещё больше нагрузки. Поддержка слышит про «случайную медлительность», а настоящая причина — фоновая задача обслуживания.
Простой пример делает проблему очевидной. Допустим, приложение обновляет старые записи заказов в рабочие часы. Задача сканирует миллионы строк и записывает их большими блоками. Оформление заказа всё ещё работает, но страницы товаров тормозят, поиск становится медленным, а обновления состояния недавних заказов приходят с опозданием из‑за отставания реплик.
Поэтому безопасный бэкоффлайн нуждается в ограничениях с самого начала. Без них фоновая работа перестаёт быть «фоном».
Найдите точки давления в первую очередь
Бэкоффлайны редко терпят неудачу из‑за одного драматического падения. Чаще они изнашивают части системы, к которым пользователи обращаются каждую минуту. Если вы не знаете, где проявляется давление, вы увидите проблему только после того, как люди начнут ждать.
Начните с базы данных, но не останавливайтесь только на CPU. Задачи с большим количеством чтений часто бьют по задержке диска и глубине очередей раньше, чем CPU начнёт выглядеть пугающе, особенно если они сканируют большие таблицы или читают строки в неэффективном порядке.
Среднее время ответа может скрывать ущерб. Следите за p95 и p99 по важным endpoint'ам: вход, поиск, оформление заказа или основная панель. Если они замедляются, задача уже слишком дорогая, даже если медиана всё ещё выглядит нормально.
Блокировки требуют отдельного наблюдения. Очистка, которая обновляет строки маленькими всплесками, всё равно может вызывать ожидания блокировок, а длинные ожидания могут перерасти в дедлоки, когда живые запросы трогают те же записи. Если вы используете реплики, следите за отставанием репликации. Бэкоффлайн, который держит primary в тонусе, но оставляет реплики на минуты позади, всё равно вредит продакшену.
Задайте пороговые значения до начала
Решите заранее, что заставит вас замедлить или приостановить задачу — до первого запроса. Так вы не будете спорить над графиками, пока система уже под нагрузкой.
Держите правила простыми и конкретными. Приостанавливайте, если p95 на пользовательском endpoint'е вырастет более чем на 20%, если задержка диска держится выше обычного несколько минут, если начинают появляться всплески ожиданий блокировок или дедлоков, если отставание реплик превысит допустимый вашей командой уровень, или если очереди запросов растут вместо того, чтобы уменьшаться.
Используйте цифры, которым команда уже доверяет. Если приложение обычно работает при 35% CPU базы и 4 ms задержки диска, не ждите катастрофы. Пауза при нарушении тренда — найдите горячее место и подправьте размер задания или интервалы сна, прежде чем пользователи почувствуют следующую волну.
Ограничьте чтения, чтобы приложение дышало
Большинство команд ошибаются в оценке чтений. Они думают, что опаснее будут записи, а затем обнаруживают, что несколько слишком активных воркеров способны замедлить приложение задолго до того, как появятся серьёзные блокировки.
Начните с меньшего числа воркеров, чем кажется нужным. Один–два воркера часто достаточно для первого запуска. Наблюдайте за задержками приложения, CPU базы и временем запросов несколько минут, затем осторожно увеличивайте конкурентность, если система остаётся спокойной.
Полные сканирования таблиц — место, где многие задачи проваливаются. Читайте по диапазонам ID или временным окнам и используйте колонку, по которой база может быстро делать seek. Задача, которая обрабатывает строки 1–5000, затем 5001–10000, намного проще для контроля, чем один запрос, который пытается взять всё оставшееся.
Держите каждое чтение небольшим. Чанк должен завершаться достаточно быстро, чтобы отменить, повторить или приостановить его было легко. Если один запрос выполняется секунды на загруженной таблице, уменьшите размер чанка, пока он не завершится заметно быстрее секунды.
Запрашивайте только те колонки, которые нужны задаче. Широкие SELECT’ы тратят I/O, память и сеть впустую. Если нужны только id, status и updated_at — берите только их.
Когда живая задержка растёт, замедлите задачу намеренно. Добавьте короткую паузу между чанками и дайте приложению догнать. Пауза 100–500 ms часто помогает больше, чем упаковка дополнительных строк в каждый запрос.
Безопасная стартовая конфигурация обычно: один–два воркера, чанки по ID или времени, узкие SELECT‑ы и короткая пауза при росте p95. Это выглядит консервативно. В продакшене консерватизм обычно выигрывает. Бэкоффлайн, который выполняется шесть часов без жалоб, лучше того, что заканчивается за сорок минут и тянет приложение вниз.
Батчевые записи без долгих блокировок
Долгие блокировки обычно происходят от одной ошибки: обновления слишком большого объёма за раз. Бэкоффлайн, трогающий 200 000 строк в одной транзакции, может блокировать нормальную работу, увеличивать отставание реплик и замедлять повторы.
Хороший размер батча — тот, который коммитится за секунду–две при нормальной нагрузке. Это может быть 100 строк или 5000 строк. Протестируйте на данных, похожих на продакшен, и начните с меньшего, чем кажется нужным. Малые коммиты быстро освобождают блокировки, дают базе место для обслуживания активных запросов и ограничивают ущерб при падении батча.
Сортируйте батчи по primary key, когда можете. База проходит строки в порядке вместо того, чтобы прыгать по таблице, что снижает случайную работу на диске и делает поведение кэша более устойчивым. Это также упрощает возобновление работы, потому что у каждого батча есть чёткая граница.
Паттерн прост: прочитать следующий диапазон по primary key, обновить только этот диапазон, сразу закоммитить и сохранить последний обработанный ID. Этот последний шаг важен. Если задача остановится, вы продолжите после последнего коммита, а не будете сканировать всю таблицу заново или гадать, где продолжить. Фиксируйте прогресс после каждого коммита, а не каждые несколько минут.
Огромные транзакции выглядят эффективными на бумаге, но обычно они тратят время при очистке продакшен‑базы. Они держат блокировки дольше, пишут большие журналы транзакций и делают ошибки дороже. Один плохой батч должен стоить вам несколько секунд, а не часа.
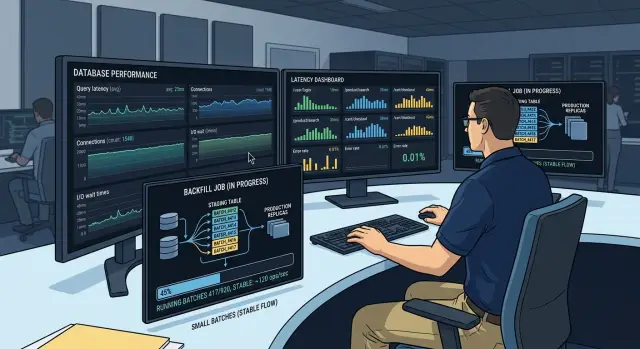
Представьте задачу, которая заполняет новый столбец в таблице orders. Обновление 50 000 строк за раз может заморозить части приложения. Обновление 500 строк, коммит и переход к следующему диапазону по ID кажется медленнее при наблюдении, но оно завершает работу с гораздо меньшим вредом для пользователей.
Если батч начинает выполняться дольше обычного — уменьшайте его. Если растут ожидания блокировок — уменьшайте снова. Быстрые скучные коммиты лучше амбициозных.
Выполняйте задачу маленькими шагами
Бэкоффлайн идёт в сторону проблем, когда ведёт себя как один гигантский запуск, а не как длинная серия маленьких скучных движений. Маленькие чанки дают место для измерения, сравнения с живой задержкой и остановки до того, как пользователи почувствуют эффект.
Начните с образца, который кажется почти слишком маленьким. Несколько тысяч строк часто достаточно, чтобы понять поведение запроса в продакшене. Если 3000 строк проходят быстро и задержки приложения остаются стабильными, попробуйте 6000 или 10 000. Если страницы начинают тормозить, CPU базы растёт или время ожидания блокировок удлиняется — вернитесь к последней спокойной настройке.
Используйте стабильный порядок, например по возрастанию id или created_at. Обрабатывайте одно фиксированное окно за раз. Закоммитьте батч, запишите контрольную точку, ненадолго приостановитесь, если система выглядит занятой, и переходите к следующему окну только после чистого завершения предыдущего.
Контрольная точка важнее, чем большинство команд думают. Сохраняйте последний безопасный id, метку времени или курсор после каждого успешного коммита. Если задача упадёт посередине чанка, вы сможете перезапустить её с последней подтверждённой позиции, а не гадать, где продолжать. Записывайте контрольную точку только после коммита базы. Если сделать это раньше, есть риск пропустить строки.
Допустим, нужно заполнить отсутствующий столбец для старых заказов. Пройдите 5000 заказов, проверьте пользовательскую задержку несколько минут и решите, оставаться ли на этом размере или увеличить. Если 5000 строк выполняются за 12 секунд и трафик нормальный — можно немного увеличить размер. Если оформление начинает занимать на 300 ms дольше — батч уже слишком большой.
Постоянные окна лучше одного гигантского толчка. Самые безопасные бэкоффлайны выглядят скучно в логах: много маленьких коммитов, чёткие контрольные точки и никакой драмы.
Безопасная пауза при всплесках трафика
Бэкоффлайн должен остановиться до того, как пользователи почувствуют его. Если p95 растёт, ожидания блокировок увеличиваются или отставание реплик начинает расти — приостанавливайте задачу и дайте приложению восстановиться.
Не убивайте воркеров посередине батча, если есть альтернатива. Жёсткая остановка может оставить наполовину завершённые записи, дубли в повторных попытках или путаницу в журнале прогресса. Чистое правило работает лучше: скажите воркерам не брать новую работу, дайте каждому закончить текущий батч и выйти.
Триггер паузы должен быть простой и очевидный. Большинству команд подходят несколько порогов: p95 держится выше лимита несколько минут, ожидания блокировок растут и продолжают расти, отставание реплик пересекает уровень, который угрожает чтениям или failover, или уровень ошибок растёт во время выполнения задачи.
Когда воркер останавливается, сразу сохраните контрольную точку. Используйте последний обработанный id, метку времени или другой стабильный курсор. Сохраняйте её вне памяти воркера, чтобы рестарт, деплой или падение не стерли ваше место.
Эта контрольная точка важнее, чем люди думают. Если вы возобновите с неточной позиции, то либо переработаете строки и потратите лишнюю запись, либо пропустите строки и оставите очистку неполной. Обе ошибки неприятны.
Держите поведение при возобновлении простым. Запускайтесь снова с тем же ограничением чтения и размером батча, который был до паузы. Смотрите графики несколько минут, прежде чем повышать лимиты. Если трафик всё ещё скачет — оставьте задачу медленной. Закончить на час позже намного дешевле, чем повредить живым запросам.
Дайте on-call возможность ручной остановки. Это может быть feature flag, строка в таблице управления или маленькая админская команда. Главное — скорость. Когда продакшен шумит, никто не хочет деплоить код только чтобы остановить фоновую задачу.
Хорошая пауза — спокойная, обратимая и понятная.
Простой практический пример
Команда добавила новый столбец статуса в таблицу orders с 80 миллионами строк. Нужно было заполнить старые записи, чтобы отчёты и экраны поддержки показывали корректные данные, но при этом нельзя было замедлить оформление заказа.
Они начали с простого правила: читаешь медленнее, чем пишешь. Задача брала 5000 ID заказов за раз, затем обновляла только по 500 строк на коммит. Это держало каждую транзакцию короткой, а значит — меньше долгих блокировок и меньше боли для активных пользователей.
Чтение было преднамеренно лёгким. Задача брала ID по порядку, сохраняла последний обработанный и шла маленькими шагами. Если воркер останавливался, он мог перезапуститься с сохранённого ID, а не сканировать всю таблицу заново.
Записи были ещё осторожнее. После каждого коммита на 500 строк воркер ждал немного перед следующим батчем. Эта маленькая пауза кажется медленной, но давала приложению место обслуживать реальный трафик в первую очередь.
Трафик менял расписание. В обед, когда больше пользователей просматривали и платили, команда снижала скорость работы. Они не гадали: смотрели задержки запросов, время оформления и нагрузку на базу. Как только цифры начинали расти, воркер замедлялся.
Во время распродажи бэкоффлайн полностью приостановили. Поскольку задача сохраняла последний завершённый ID после каждого успешного коммита, пауза была чистой. Никаких наполовину выполненных чанков, никакого путаного плана отката и никакой необходимости начинать заново.
Это шло несколько ночей. Команда не пыталась сделать всё в один заход, и поэтому всё получилось. В конце все 80 миллионов заказов имели новое значение статуса, служба поддержки могла корректно фильтровать записи, а оформление заказа оставалось стабильным всё это время.
Вот как на практике выглядит безопасный бэкоффлайн: маленькие чтения, ещё меньшие записи, реальные паузы и терпение.
Ошибки, которые делают очистку болезненной
Большинство проблем в продакшене начинается с одной плохой предпосылки: «на стейджинге прошло, значит в продакшене тоже пройдёт». Так команды стартуют на полной скорости и узнают тяжёлый урок: реальный трафик меняет всё. Тихая тестовая база не имеет нетерпеливых пользователей, отставания реплик, дрейфа кэша или фоновых задач, которые борются за одни и те же строки.
Скорость не является первоочередной целью. Контроль важнее. Задача, которая заканчивает работу за шесть часов без влияния на пользователей, лучше той, что старается уложиться в сорок минут и тянет приложение вниз.
Одна большая транзакция — ещё одна классическая ошибка. На бумаге это аккуратно, но в продакшене такие транзакции могут блокировать нормальные записи, держать блокировки слишком долго и делать откат медленным и неприятным. Малые коммиты дают базе пространство для дыхания и дают вам чистую точку остановки, если трафик подпрыгнул.
Команды также читают гораздо больше, чем нужно. Они хватают целые строки, лишние JOIN’ы и колонки, которые задача не использует. Это тратит I/O, заполняет память и замедляет батч ещё до записи. Если задаче нужен только id и одно поле — читайте только их.
База данных — не единственное место, которое может захлебнуться. Очистка часто бьёт по репликам, поисковым индексам, кэшам, очередям и аналитическим пайплайнам. Бэкоффлайн может казаться нормальным на primary, в то время как реплики остаются на минуты позади и обновления поиска собираются в стопки. Пользователи всё равно почувствуют ущерб, просто в другой части продукта.
Логика возобновления часто пропускается. Вы это заметите только после падения, деплоя или ручной остановки. Протестируйте это намеренно: убейте задачу во время теста и посмотрите, что произойдёт дальше.
После прерывания адекватный бэкоффлайн должен перезапуститься с известной контрольной точки, избегать двойных записей и приостанавливаться без оставления наполовину выполненной работы в плохом состоянии. Если вы не можете безопасно остановить задачу — вы ей не управляете, вы просто надеетесь, что она ведёт себя хорошо.
Быстрые проверки до, во время и после
Скучные проверки важнее всего. Задача, которая может приостанавливаться, возобновляться и подтверждать прогресс — обычно безопаснее, чем быстрая задача, работающая вслепую.
Перед запуском подтвердите, что путь чтения использует правильный индекс. Если задача сканирует всю таблицу — исправьте это первым делом. Убедитесь, что у задачи есть жёсткие лимиты на размер батча, время сна между батчами, макс. число воркеров и пределы повторных попыток. Проверьте, что каждый батч пишет надёжную контрольную точку (последний обработанный id или timestamp). Наконец, согласуйте правила остановки до старта — например, пауза при выходе p95 за нормальную полосу, при отставании реплик выше лимита или при длительных ожиданиях блокировок.
Когда задача запущена, наблюдайте за системой как операционный инженер, а не как зритель. Бэкоффлайн может выглядеть нормально на своей панели, в то время как пользователи испытывают боль где‑то ещё. Следите за пользовательской задержкой и уровнем ошибок, отставанием реплик или глубиной очередей, ожиданиями блокировок и дедлоками, количеством обработанных строк относительно ожидаемого темпа и объёмом повторных попыток.
Если задача серьёзно отстаёт от графика, не спешите удваивать число воркеров. Сначала спросите почему. Может быть, индекс неверен, записи слишком большие или дневной трафик выше, чем предполагал тестовый интервал.
После завершения задачи проверьте результат перед тем, как объявлять её выполненной. Сравните число строк в источнике и в целевой таблице, затем выборочно проверьте реальные записи из разных диапазонов: старые, свежие и пограничные кейсы, которые часто ломают значения по умолчанию или форматирование. Скрипты очистки тоже выполняйте маленькими шагами, особенно если они удаляют временные колонки, перестраивают индексы или чистят вспомогательные таблицы.
Затем уберите временные меры безопасности. Удалите флаги, существовавшие только для бэкоффлайна, сбросьте переопределения воркеров и выключите дополнительный лог, если вы включали его на время прогонки. Если оставить этот мусор, следующий инцидент будет сложнее разбираться.
Что делать дальше
Бэкоффлайн должен оставить после себя не только очищенные данные, но и понятный рукбук, который следующий инженер сможет следовать в 2 утра без догадок. Запишите размер батча, лимиты чтения, правила паузы, поведение при повторе, шаги отката и сигналы, за которыми вы следили во время прогонки.
Этот рукбук должен стать шаблоном для будущих задач. Командам не нужно заново придумывать правила безопасности каждый раз. Добавьте фиксированные контрольные точки, пороги паузы на основе трафика и простое правило, кто может останавливать задачу и кто может её рестартовать.
Короткий обзор сейчас может спасти от тех же проблем в следующем месяце. Проверьте старые задачи, которые всё ещё работают с завышенными батчами. Понизьте скорости чтения на задачах, конкурирующих с пользовательскими запросами. Разбейте большие всплески записи на мелкие коммиты. Добавьте точки возобновления, чтобы при паузе задача могла продолжить корректно. Зафиксируйте безопасное окно, когда система имеет свободную пропускную способность.
Внимательно посмотрите на задачи, которые «обычно работают». Именно они часто создают проблемы при всплеске трафика, потому что никто не возвращался к ним после роста базы. Размер батча, который казался маленьким полгода назад, сейчас может быть слишком большим.
Если команде нужен второй взгляд, Oleg Sotnikov at oleg.is проверяет дизайн задач, ожидаемую нагрузку на базу и планы выкатывания для стартапов и маленьких команд. Такой обзор часто не про тонкую настройку, а про ловлю одной рискованной предпосылки на ранней стадии, например отсутствующей контрольной точки или правила паузы, зависящего от постоянного ручного наблюдения за дашбордом.
Лучший результат — скучный: бэкоффлайн завершился, пользователи этого не заметили, и команда сохранила тот же набор правил для следующей задачи.
Часто задаваемые вопросы
Why can a backfill slow down live traffic?
Потому что он конкурирует с живыми запросами за те же ресурсы базы данных: CPU, диск, память и блокировки. Большие сканирования могут вытеснить горячие данные из кэша, и обычные страницы снова читают данные с диска, из‑за чего они замедляются, даже если код приложения не менялся.
What should I monitor during a backfill?
Следите за p95 или p99 задержками на пользовательских endpoint'ах, а не только за средними значениями. Контролируйте дискoвую латентность, ожидания блокировок, дедлоки, отставание реплик, уровень ошибок и глубину очередей — чтобы остановиться до того, как пользователи начнут жаловаться.
How many workers should I start with?
Начните с одного или двух воркеров. Дайте им поработать несколько минут, проверьте задержки приложения и нагрузку на базу, и увеличивайте параллельность только если система остаётся стабильной.
How should I throttle reads?
Читать маленькими диапазонами по ID или временным окнам, вместо того чтобы просить всё оставшееся в одном запросе. Делайте чанки настолько малыми, чтобы на загруженной таблице они выполнялись заметно быстрее секунды, и выбирайте только те колонки, которые реально нужны задаче.
Why should I use small write batches?
Маленькие батчи коммитятся быстро, освобождают блокировки раньше и ограничивают ущерб при отказе. Огромные транзакции могут показаться быстрыми, но обычно повышают давление блокировок, увеличивают отставание реплик и усложняют повторы.
How do I resume a backfill safely after a stop?
Выберите стабильный курсор — например, возрастающий ID или метку времени, сохраняйте его после каждого успешного коммита и храните контрольную точку вне памяти воркера. При рестарте продолжайте с последней подтверждённой контрольной точки, а не догадывайтесь, где остановились.
When should I pause the job?
Пауза при повышении p95 выше обычной полосы, при росте ожиданий блокировок, при слишком большом отставании реплик или когда очереди запросов перестают спадать. Не ждите полного простоя — если тренд идёт в сторону ухудшения несколько минут подряд, замедлите или остановите задачу.
What is the safest way to pause a backfill?
Сообщите воркерам не брать новую работу и дайте им закончить текущий батч. Жёсткая остановка внутри батча может оставить незавершённые записи, дубли или путаницу в журнале прогресса.
Should I only run backfills at night?
Часто да, многие команды запускают задачи в часы с меньшей нагрузкой, но одно только время не спасёт плохую задачу. Медленный, контролируемый бэкоффлайн с контрольными точками и правилами паузы обычно лучше, чем быстрая ночная загрузка с гигантскими батчами.
How do I verify the backfill finished correctly?
Сравните количество строк в источнике и в целевой таблице, выберите произвольные записи из старых, недавних и пограничных диапазонов и убедитесь, что данные корректны. После этого удалите временные флаги, переопределения воркеров и лишний лог, чтобы не усложнять чтение следующих инцидентов.


