Безопасные виды отладки для команд поддержки в масштабе
Узнайте, как безопасные виды отладки помогают поддержке отслеживать ошибки, просматривать историю задач и решать обращения быстрее, не раскрывая данные из production.
Содержание
Почему поддержка застревает без безопасных видов отладки
Команды поддержки обычно оказываются перед двумя плохими выборами. Либо ждать инженера, чтобы он посмотрел production, либо пользоваться сырыми внутренними инструментами, которые не предназначались для работы с клиентами.
Ожидание замедляет всё. Агент поддержки просит помощи, инженер переключается на тикет, затем просит дополнительные данные, потому что в заявке нет нужного ID, метки времени или состояния ошибки. Один простой вопрос клиента может превратиться в несколько обменов сообщениями, прежде чем кто-то вообще найдёт проблему.
Открывать сырые инструменты быстрее, но рискованнее. Дашборды, логи и представления базы данных часто показывают слишком много: полные email'ы, платёжные данные, токены, внутренние заметки и нефильтрованные payload'ы событий. Даже внимательные команды ошибаются, когда конфиденциальные данные лежат прямо перед глазами.
Отсутствие контекста усугубляет ситуацию. Поддержке не нужны все поля таблицы или каждая строка лога. Им нужны простые ответы на простые вопросы. Отправилось ли письмо подтверждения? Упал ли фоновой job? Сталкивался ли этот клиент с той же проблемой раньше? Это известная проблема или единичный случай?
Когда эти ответы трудно найти, тикеты тянутся. Клиенты повторяют информацию. Поддержка просит у инженеров скриншоты или фрагменты логов. Инженеры отвечают техническим языком, который поддержке потом приходится переводить. Задержка на одном тикете может показаться небольшой, но сотни таких случаев быстро складываются.
Безопасный debug view закрывает этот разрыв. Хороший экран для поддержки даёт агентам достаточно фактов, чтобы действовать, не раскрывая сырых production-данных. Он может показывать замаскированный email, текущий статус, недавние результаты задач, trace ID и короткую причину сбоя. Во многих случаях этого достаточно, чтобы объяснить проблему, повторить нужный шаг или сразу отправить дело инженерам с нужным контекстом.
Это практически меняет повседневную работу. Поддержка перестаёт работать вслепую. Инженеры перестают быть инструментом мгновенного поиска по данным.
Начните с вопросов, на которые поддержке нужно ответить
Эти экраны работают только если отвечают на реальные вопросы поддержки. Если поддержке всё ещё приходится просить инженера о базовых фактах, экран — лишь украшение.
Начните с истории тикета, логов чатов и заметок звонков. Шаблоны обычно видны быстро. Одни и те же вопросы повторяются снова и снова:
- Дошёл ли пользователь до конца действия или остановился на середине?
- В каком сейчас статусе аккаунт, заказ или задача?
- Отправлялась ли система письмом, webhook'ом или делала повторную попытку?
- Когда началась проблема?
- Может ли поддержка исправить это сейчас, или нужно привлекать инженеров?
Последний вопрос заслуживает отдельного внимания. Некоторые случаи решает поддержка: они могут повторно отправить письмо, подтвердить статус или объяснить следующий шаг. Другие требуют инженеров — например, сломанный worker, застрявшая очередь или ошибочный деплой. Очертите эту границу заранее. Это экономит время и избавляет поддержку от догадок.
Для каждого типичного случая запишите несколько фактов, которые поддержке нужно видеть. Держите их конкретными. Если письмо подтверждения при регистрации не ушло, поддержке могут понадобиться статус аккаунта, информация о том, запускалась ли задача отправки письма, последнее понятное сообщение об ошибке и время последней попытки. Им не нужен полный текст письма, секретные токены, сырые payload'ы запросов или приватные профильные данные.
Простое правило фильтрации работает хорошо: если поле не меняет дальнейшее действие, удалите его. Поддержка теряет скорость, когда команды сбрасывают всё из production на одну страницу. Это замедляет людей и повышает риск случайно раскрыть что-то приватное.
Прежде чем кто-то начнёт проектировать экран, карту каждого случая сведите в четырёх коротких частях: вопрос поддержки, факты, которые нужны, действие, которое поддержка может выполнить, и момент, когда дело передаётся инженерам. Мелкий, чёткий вид почти всегда лучше гигантской админ-страницы, которая пытается ответить на всё сразу.
Показывайте только безопасные поля на экране
Экран поддержки должен отвечать "что произошло?" без раскрытия данных клиента. Если первым на странице стоит полный профиль, сырой JSON или API-токен, экран делает слишком много.
Везде маскируйте персональные данные. Имена, email'ы, номера телефонов, адреса, session ID и токены не должны показываться полностью в базовом виде. Поддержке обычно не нужен «[email protected]», чтобы выполнить работу. Достаточно «a***@example.com», чтобы подтвердить, что это та самая запись.
Стабильные ID делают больше работы, чем персональные данные. ID клиента, workspace ID, номер заказа, job ID и trace ID позволяют поддержке отслеживать одну проблему в разных инструментах, не видя приватных данных. ID также устраняют путаницу, когда у двух клиентов одинаковые имена или похожие email'ы.
Держите сырые payload'ы вне основного экрана. Показывайте краткое резюме: статус, время события, код ошибки, количество повторов, последний завершённый шаг и связанные ID. Если поддержке действительно нужен дополнительный контекст, давайте им ограниченное углубление с логированием доступа. Инженеры могут иметь более подробный вид. Поддержка должна сначала получать безопасную версию.
Копирование деталей важно больше, чем многие думают. Позвольте поддержке копировать редактированные факты одним кликом, чтобы они могли вставить их в тикет или отправить инженерам без очистки. Полезная копируемая сводка может выглядеть так:
- Customer ID: 48291
- Signup job: job_9c1f
- Email: a***@example.com
- Error: SMTP 550
- Last retry: 10:42 UTC
Это экономит время и предотвращает распространённую ошибку — вставку секретов в чат.
Логируйте доступ к любым чувствительным данным. Фиксируйте, кто открыл вид, когда и какую запись проверял. Если позже кто-то попросит более широкий доступ, вы сможете посмотреть реальное использование вместо догадок.
Добавьте trace-ссылки, которые следуют за одной проблемой
Поддержка теряет время, когда одно действие клиента разрывается на несколько записей. Регистрация может начаться в веб-приложении, пройти через API, поставить задачу отправки письма в очередь и закончиться ошибкой в воркере. Если эти записи не связаны одним trace ID, команде придётся собирать историю вручную.
Создавайте этот ID при первом действии пользователя. Если клиент нажал "Sign up" или "Pay", приложение должно создать trace ID прямо там и передавать его на все последующие шаги. Делайте его коротким, удобным для копирования и поиска в логах, экранах поддержки и алертах.
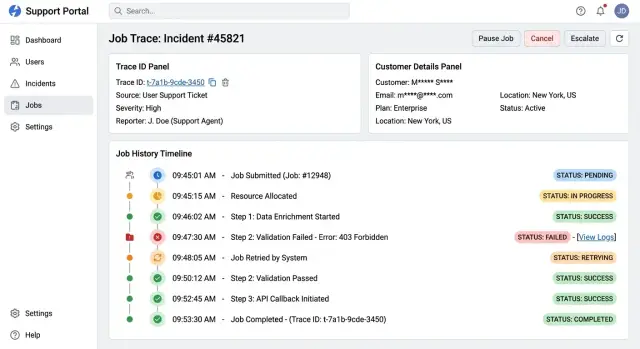
Вид поддержки должен показывать тот же trace ID в тикете, исходном запросе, фоновой задаче и событии ошибки. Это даёт агентам один путь для расследования, а не несколько мест для поиска.
Простая цепочка trace обычно включает внутреннее дело, запрос, который запустил действие, фоновую задачу, которая продолжила его, и запись об ошибке, если действие провалилось. Каждый шаг должен показывать три простых факта: когда начался, когда завершился и в каком он сейчас состоянии. Состояния вроде "queued", "running", "done" и "failed" достаточно для большинства команд. Точные времена важны, потому что они показывают, где произошла задержка.
Возьмём неудачную отправку письма при регистрации. Поддержка открывает тикет и видит trace ID. Запрос завершился в 10:02:11, задача отправки письма стартовала в 10:02:12, была две повторы и в 10:03:01 завершилась с таймаутом провайдера. Это ясная история, и поддержка может объяснить её без доступа к сырым production-логам.
Если в цепочке есть разрывы, отмечайте их явно. Если запрос есть, а job не найден — укажите "job not found." Если retention удалил запись об ошибке — скажите и об этом. Пустые места заставляют людей думать, что инструмент сломался, когда на самом деле данных просто не хватает.
Когда поддержка может проследить одну проблему от начала до конца на одном экране, они отвечают быстрее и реже эскалируют. Небольшие команды замечают это сразу.
Держите историю задач читаемой
Хаотичный журнал задач тратит время поддержки. Когда один экран смешивает отложенные задачи, повторы, клики пользователей и служебный шум, люди перестают ему доверять. Чистая история должна быстро отвечать на один вопрос: что произошло, в каком порядке и на чем сейчас надо сосредоточиться?
Размещайте каждое событие на одной временной шкале, выбирая порядок (новейшее или старейшее) один раз и сохраняя его везде. Большинству команд лучше смотреть от старого к новому, потому что так поддержке легче прочитать историю от начала до конца без мысленных прыжков назад.
Каждая строка должна показывать имя задачи, время начала, время завершения, статус и количество повторов. Если задача ждала в очереди или была на паузе перед повтором, показывайте эту задержку рядом с номером попытки. Поддержке не нужно открывать три панели, чтобы узнать, что задача отправки письма упала, ждала 10 минут, дважды пыталась и затем удалась.
Для ошибок нужен короткий человеческий ответ, а не сырой стек-трейс. "Email provider timeout" или "Customer record missing verified address" достаточно для большинства случаев. Более глубокие технические детали держите за внутренним уровнем доступа, а вид для поддержки — простым.
Отделяйте действия клиента от последующих действий системы. Клик регистрации, запрос на сброс пароля или изменение тарифа должны выглядеть иначе, чем фоновая работа — отправка писем, синхронизация биллинга или обновление поисковых индексов. Это помогает поддержке понять, началось ли всё с действий пользователя или проблема возникла позже.
Простой формат таймлайна работает хорошо:
- 10:02:14 - Клиент запросил сброс пароля
- 10:02:15 - Задача отправки письма поставлена в очередь
- 10:12:15 - Повтор 1 после таймаута провайдера
- 10:22:15 - Повтор 2 после таймаута провайдера
- 10:22:18 - Итог: отправлено
Храните историю достаточно долго для реальных привычек поддержки, а не идеальных. Если клиенты часто жалуются на пропавшее письмо спустя две недели, 48-часового лога будет недостаточно. На практике более длительное хранение с редактированием полей помогает больше, чем хитрый интерфейс.
Стройте первую версию по шагам
Большинство команд пытаются на первом же этапе спроектировать полноценную внутреннюю консоль. Это обычно замедляет прогресс. Начните с одного случая поддержки, который появляется каждую неделю и требовал много времени для ручной проверки — например, фоновая задача, которая не завершалась, или застрявшее биллинговое событие.
Начните с одного случая
Опишите путь этого кейса от начала до конца. Какое событие его запускает? Какие сервисы участвуют? Какие ID нужны поддержке? Где живёт конечный статус? Держите карту короткой и понятной. Если поддержке сложно проследить путь на бумаге, они не будут следовать ему на экране.
Затем выберите только те поля, которые отвечают на вопрос тикета. Хороший первый экран часто содержит текущий статус, метки времени каждого шага, один trace ID, короткую заметку о последней ошибке и данные клиента, сведённые к безопасным фрагментам — например, замаскированный email или последние четыре цифры номера заказа.
Этого достаточно для многих случаев. Пропустите сырые payload'ы, полные персональные данные, секреты и свободные логи. Если поддержке действительно нужны такие данные для решения проблемы, экран всё ещё слишком близок к production.
Протестируйте на старых тикетах
Сделайте одну простую страницу, а не полный админ-панель. Поместите статус вверху, историю событий по времени под ним и ссылку trace там, где поддержке удобно её скопировать. Если проблема пересекает несколько сервисов, сделайте trace-идентификатор «позвоночником» страницы, чтобы поддержка могла следовать по одному пути без догадок.
Далее возьмите 10–20 реальных тикетов за последний месяц. Попросите поддержку пройти их с новым экраном. Наблюдайте, где они останавливаются, что ещё просят у инженеров и какие подписи сбивают их с толку. Небольшие правки формулировок часто помогают больше, чем дополнительные фильтры.
Перед широким доступом ужесточите права. Дайте экран только тем, кому он действительно нужен, логируйте каждое открытие и держите доступ поддержки отдельно от доступа инженеров. Команды часто откладывают это на потом и потом жалеют. Хорошая первая версия — небольшая, читаемая и немного скучная. Это обычно хороший знак.
Простой случай: неудачное письмо регистрации
Клиент говорит, что форма регистрации прошла, но письмо не пришло. Поддержке не нужен прямой доступ в production, чтобы это проверить. С безопасным debug view они открывают запись аккаунта и смотрят один trace, который связывает событие регистрации с задачей отправки письма.
Экран сначала показывает базу: время регистрации, статус аккаунта, статус доставки письма и замаскированный адрес вроде "m***@example.com." Этого достаточно, чтобы подтвердить, что клиент ввёл тот адрес, который он ожидает, не раскрывая полного значения.
Далее поддержка следует за trace ID. Они видят, что запрос регистрации создал задачу отправки письма, почтовый сервис принял сообщение, система сделала одну повторную попытку через несколько минут, и задача завершилась финальным bounce'ом от провайдера.
Каждый исход указывает на следующий шаг. Если задача вообще не стартовала — проблема может быть в приложении или очереди. Если провайдер принял сообщение, а потом вернул bounce — поддержка может перестать обвинять поток регистрации и сосредоточиться на доставке.
Замаскированный адрес снова помогает. Клиент говорит, что регистрировался с "maria.santos@...", а экран показывает "m***.s*****@...". Поддержка может подтвердить совпадение шаблона, не проговаривая полный адрес клиенту. Эта маленькая деталь сильно сокращает ненужные уточнения.
Теперь дело идёт быстрее. Поддержка может сказать клиенту, что аккаунт создан, задача отправки письма выполнена, и провайдер вернул bounce после повтора. Они могут попросить клиента проверить адрес, повторно отправить письмо или попробовать другую почту.
Никто не открывал сырые логи. Никто не прерывал инженера только чтобы посмотреть production. Инженеры привлекаются только если trace показывает, что система сломалась до того, как письмо покинуло приложение.
Ошибки, которые создают риск или замедляют поддержку
Плохие инструменты для поддержки обычно терпят неудачу двумя путями: они либо раскрывают слишком много, либо скрывают нужные факты. Хорошие debug view занимают среднюю позицию. Они дают поддержку достаточно контекста, чтобы действовать быстро, не превращая экран в копию production.
Распространённая ошибка — вкидывать сырые логи в вид для поддержки. Сначала это кажется полезным, но сырые логи часто содержат токены, payload'ы, заголовки, email'ы или внутренние заметки, которых поддержка не должна видеть. Они ещё и шумные. Агенту не должно приходиться просматривать 500 смешанных событий, чтобы найти один таймаут.
Ещё одна ошибка — строить одну гигантскую страницу со всеми полями из базы. Люди теряют доверие к таким страницам, потому что не понимают, что важно. Выводите в первую очередь поля, которые объясняют проблему, а внутренние детали оставляйте вне инструмента.
Команды, которые двигаются быстрее всего, обычно делают несколько базовых вещей правильно. Они держат видимые метки времени, чтобы поддержка понимала, застряла задача или просто ещё выполняется. Они показывают счётчик повторов и финальный статус, потому что одна ошибка и восемь попыток — это совсем разные сценарии. Они используют один стабильный ID между системами или явно показывают соответствие, когда это невозможно. Они держат экран только для чтения, чтобы небольшие правки не превращались в скрытые изменения данных. И они избегают смешения пользовательских ярлыков с внутренними именами. Если один экран говорит "signup", а другой — "user_create_v2", путаница начинается быстро.
Простое правило: если поле помогает объяснить, что произошло, показывайте его в безопасной форме. Если поле приглашает к случайным изменениям, может вытечь приватная информация или добавляет шум — оставьте его вне. Поддержке обычно удобнее иметь чёткую дорожку, чем полный доступ.
Быстрые проверки перед запуском
В день запуска — плохое время узнавать, что поддержке всё ещё не хватает ответов на самые частые тикеты. Протестируйте экран на ваших топовых типах тикетов сначала. Возьмите пять реальных случаев, уберите имена клиентов и попросите агента поддержки решить их, используя только новый вид.
Если им всё ещё нужен инженер для базовых фактов вроде "Выполнялась ли задача?" или "Какой аккаунт затронут?", экран не готов. Вся цель — убрать первый раунд вопросов туда-обратно.
Пройдите короткий чеклист перед выпуском:
- Может ли поддержка ответить на самые обычные вопросы с одного экрана или по ясному trace-пути?
- Остаются ли замаскированные поля замаскированными в экспортах, копируемом тексте, печати и скриншотах?
- Может ли новый сотрудник прочитать историю и объяснить, что произошло, меньше чем за минуту?
- Прослеживает ли один trace проблему через API, фоновые воркеры и запланированные задачи?
- Есть ли у инженеров отдельный, проверяемый доступ к сырым данным при реальной необходимости?
Тест маскировки ловит больше команд, чем вы ожидаете. Поле может выглядеть скрытым на странице, но просачиваться в CSV-экспорте, в подсказке ошибки или автозаполнении браузера. Инструменты поддержки быстро распространяются в живых инцидентах, поэтому если маскирование даёт брешь в одном месте, модель безопасности нарушена.
История задач требует того же стресс-теста. Попросите новичка открыть одну запись и назвать три вещи: что запустило поток, где он упал и пытался ли система повторить. Если ответов нет — лог слишком шумный или подписи слишком расплывчаты.
Держите грань между доступом поддержки и доступом инженеров очень чёткой. Поддержке нужен безопасный контекст, trace-ссылки и читабельная история. Инженеры могут иметь более глубокий доступ через более строгие контроли, одобрения и аудиторские логи. Смешивать эти пути обычно сначала создаёт риск, а затем — проблемы со скоростью.
Что делать дальше
Когда первый экран запущен, отслеживайте тикеты, которые всё ещё возвращаются к инженерам. Эти тикеты показывают, какого безопасного контекста поддержке не хватает. Возможно, они не могут понять, запущена ли задача отправки письма, какое состояние блокировало вход, или дошёл ли webhook до системы. Выберите паттерн, который встречается чаще всего, и добавьте это следующим.
Не стройте сразу пять новых видов. Одно дополнительное направление достаточно, если оно убирает частую передачу между командами. Хорошим вторым шагом часто становится одна узкая дорожка — регистрация, повтор оплаты или статус импорта. Небольшие дополнения сохраняют инструмент понятным и облегчают тестирование правил доступа.
Обучение важно не меньше, чем экран. Дайте поддержке несколько реальных кейсов, короткую подсказку для каждого поля и простое правило эскалации. Если редактированное значение всё ещё сбивает с толку — переименуйте его. Если trace-ссылка ведёт через три экрана — укоротите путь.
Простой цикл обзора работает хорошо:
- Соберите 10 недавних тикетов, которые всё ещё требовали помощи инженеров.
- Отметьте, что поддержка не могла подтвердить самостоятельно.
- Добавьте недостающее безопасное поле, шаг trace'а или событие задачи.
- Протестируйте изменение на 2–3 реальных кейсах.
Потом посмотрите, изменило ли это повседневную работу. Экономия хотя бы одного прерывания инженера в день быстро складывается. Если экран никто не использует, вероятно, он слишком шумный или слишком расплывчатый.
Держите заметки короткими и близкими к работе. Одностраничное руководство с реальными примерами обычно лучше длинного внутреннего мануала, который никто не открывает. Поддержке должно быть ясно, что значит каждый статус, что они могут безопасно сказать клиенту и когда остановиться и попросить помощи.
Если хотите внешнюю проверку, Oleg at oleg.is может просмотреть модель данных, правила доступа и рабочий процесс поддержки. Это хорошо сочетается с его работой Fractional CTO и консультациями для стартапов, особенно для команд, которые хотят укрепить внутренние инструменты, не раскрывая production-данные.
Часто задаваемые вопросы
What is a customer-safe debug view?
Клиентско-безопасный debug view даёт поддержке факты, необходимые для ответа на тикет, без доступа к сырым production-инструментам. Он должен показывать статус, время, недавние результаты задач, trace ID и короткую заметку об ошибке, скрывая приватные данные — полные email-адреса, токены и сырые полезные нагрузки.
What should the default support screen show?
Начните с текущего статуса, времени запуска проблемы, последнего системного результата и одного идентификатора, который связывает весь поток. Добавьте короткий таймлайн и замаскированную деталь клиента, чтобы агент быстро подтвердил, что открыл правильную запись.
Which fields should I mask?
Скрывайте всё, что раскрывает личность или даёт доступ к системам. По умолчанию маскируйте email'ы, телефоны, адреса, session ID, токены и платёжные данные; используйте стабильные внутренние ID для основной навигации.
Why should I use one trace ID across systems?
Один trace ID позволяет поддержке проследить одно действие клиента от приложения до API, очереди, воркера и записи об ошибке без догадок. Когда все шаги используют один ID, агенты перестают собирать историю вручную и отправляют инженерам более понятные эскалации.
Should support see raw logs or payloads?
Нет. Держите сырые логи и payload'ы вне вида для поддержки. Давайте простую сводку вроде не удалось после 2 повторных попыток или таймаут провайдера, а более глубокие данные оставляйте для инженеров за жёстким доступом и аудит-логами.
What makes a job history easy to read?
Делайте просто и последовательно. Показывайте каждое событие в хронологическом порядке с названием задачи, временем начала и завершения, текущим статусом, количеством повторов и короткой понятной причиной ошибки — так поддержка сможет объяснить, что произошло, за секунды.
When should support hand a case to engineering?
Очертите границы передачи дела заранее. Пусть поддержка решает ситуации, где они могут подтвердить статус, отправить повторную попытку или объяснить следующий шаг, а направляют инженерам случаи, когда trace показывает сломанный воркер, отсутствующую запись, застрявшую очередь или проблему деплоя.
Should the support view stay read-only?
Да, держите вид для поддержки только для чтения. Это снижает риск, сохраняет чистую историю аудита и не позволяет быстрым фиксам превратиться в незаметные изменения данных, которые потом никто не сможет объяснить.
How do I build the first version without overbuilding?
Выберите один тип тикета, который часто появляется и отнимает много времени, и сделайте одну маленькую страницу для этого потока. Используйте только те поля, которые влияют на следующее действие, протестируйте экран на старых тикетах и не превращайте его в мини-админку.
How should I test the screen before and after launch?
Тестируйте на реальных тикетах, а не на демозаписях. Попросите поддержку решить 10–20 недавних кейсов, используя только новый экран, наблюдайте, где они всё ещё просят инженеров о помощи, и исправляйте подписи, недостающие поля или битые шаги trace'а, которые замедляют работу.


