Безопасность SQL, сгенерированного ИИ: роли только для чтения и проверка
Безопасность SQL, сгенерированного ИИ, начинается с простых ограничений: роли только для чтения, лимиты строк, этапы проверки и ясные правила одобрения до выполнения.
Содержание
Почему SQL, написанный ИИ, нуждается в защитных ограждениях
Модель может сгенерировать SQL, который выглядит аккуратно и при этом причинить серьёзные проблемы. Она предсказывает наиболее вероятный следующий запрос. Она не чувствует стоимости полного сканирования таблицы, не знает, в каких таблицах хранятся чувствительные данные, и не замечает, что в продакшене уже высокая нагрузка.
Именно в этом разрывe начинаются проблемы. Подсказка вроде "покажи заказы клиентов за прошлый месяц" может превратиться в запрос, который читает все заказы за всё время, если фильтр по дате неверный или отсутствует. Результат при этом может выглядеть правдоподобно, и ошибку легко пропустить.
Некоторые сбои очевидны. Если модель пишет DELETE FROM users без WHERE, строки исчезают быстро. Другие — тише. Плохой JOIN может дублировать показатели выручки. Широкий SELECT * по огромной таблице может замедлить базу для всех остальных. Запрос, пропускающий фильтры по арендаторам, может раскрыть данные другого клиента.
Безопасность SQL, сгенерированного ИИ, в основном — проблема проектирования системы, а не вопрос доверия. Старательные люди всё ещё одобряют рискованные запросы, если они сначала кажутся разумными. Мощные модели тоже ошибаются, когда имена таблиц похожи, бизнес-правила лежат вне схемы или старые примеры в подсказке вводят в заблуждение.
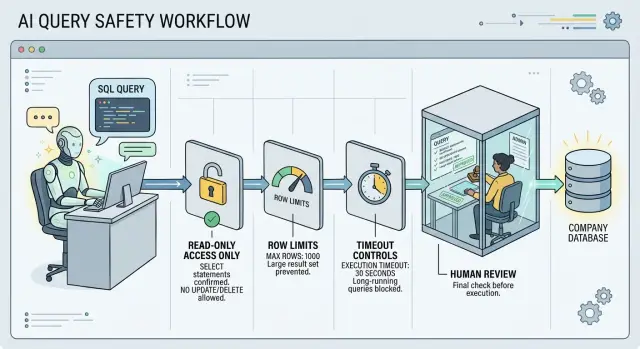
Ограждения ловят эти слабые места до того, как случится вред. Роли только для чтения блокируют изменения. Лимиты запросов останавливают безудержные чтения. Шаг проверки даёт одно ясное мгновение, чтобы спросить: "Тронет ли этот запрос нужные таблицы, с нужными фильтрами и по правильной причине?"
Это гораздо дешевле, чем убирать последствия ошибки. Не нужно предполагать, что модель безрассудна. Нужно лишь допустить, что она может ошибаться в мелочах, а мелкие SQL-ошибки очень быстро превращаются в проблемы с данными.
Что может сделать один плохой запрос
Плохой запрос не обязан выглядеть опасно, чтобы нанести вред. Он может выглядеть аккуратно, даже разумно, и всё же попасть в неправильную таблицу, просканировать лишние данные или заблокировать загруженную базу.
Модели угадывают. Иногда они предполагают имена таблиц по частым шаблонам вроде users, orders или transactions, даже если в вашей схеме используются другие имена. Если модель указывает не на ту таблицу, результат может быть пустым, запутать или, что хуже, раскрыть данные, к которым человек не хотел обращаться.
Отсутствующие фильтры — ещё одна частая проблема. Одна забытая WHERE может превратить маленький отчёт в полный проход по таблице за месяцы или годы. Человек может попросить "ошибочные платежи за прошлую неделю" и получить все платежи за всё время. Это перестаёт быть мелкой ошибкой, когда таблица содержит данные клиентов, внутренние заметки или финансовую информацию.
Медленные запросы наносят другой тип ущерба. Большой JOIN или сортировка могут заставить базу работать гораздо тяжелее, чем ожидается. Остальные пользователи почувствуют это немедленно. Страницы загружаются медленно. Фоновые задания накапливаются. Отчёты начинают конкурировать с обычным трафиком продукта.
Доступ на запись делает любую ошибку дороже. Плохой UPDATE может изменить тысячи строк за секунды. Плохой DELETE может стереть данные до того, как кто‑то заметит. Даже при бэкапах восстановление занимает время, и команде всё равно придётся разбираться, что изменилось.
Обычные точки отказа просты:
- угадывание имён таблиц или столбцов
- отсутствующие фильтры или диапазоны дат
- соединения, которые по ошибке умножают строки
- запросы, читающие намного больше, чем нужно
- любая команда, способная изменить или удалить данные
Небольшой пример проясняет риск. Если кто‑то просит "неактивных пользователей из Европы", а запрос пропускает и фильтр по дате, и по региону, инструмент может вернуть всю таблицу пользователей. Большинству команд достаточно увидеть это один раз.
Начните с доступа только для чтения
Дайте модели отдельного пользователя базы данных. Никогда не позволяйте ей работать под тем же аккаунтом, что использует ваше приложение, аналитик или админ. Если этот аккаунт может записывать данные, удалять таблицы или менять права, одна плохая подсказка может превратить отчётную задачу в простой.
Доступ только для чтения — первое правило. Модель должна иметь право выполнять SELECT и больше ничего. Блокируйте INSERT, UPDATE, DELETE, TRUNCATE, ALTER, CREATE и DROP. Если база позволяет, блокируйте функции или расширения, которые могут обращаться к файловой системе или вызывать внешние сервисы.
Сократите зону доступа. Многие команды открывают всю отчетную базу, потому что так кажется быстрее в начале. Чаще лучше открыть небольшой набор утверждённых представлений, которые уже скрывают лишние столбцы, соединяют общие таблицы и переименовывают поля в понятные имена. Для большинства команд allowlist вроде sales_summary_view, customer_orders_view, monthly_revenue_view и support_ticket_counts_view хватит. Такая настройка специально скучная. Скучно = безопаснее.
Чувствительные таблицы должны оставаться вне зоны доступа, даже если модель "навряд ли" понадобятся. Сюда входят payroll, сырые записи пользователей, данные паролей, токены, логи аудита, внутренние заметки и любые таблицы с юридическими или медицинскими данными. Если человеку нужен специальный доступ к таблице, модель не должна видеть её по умолчанию.
Простой тест помогает: если вы хотите, чтобы модель ответила "Сколько платных заказов было в прошлом месяце?", ей не нужен доступ к полной таблице users или всей истории платежей. Достаточно чистого отчётного представления с полями, нужными для ответа.
Такая настройка также облегчает проверку. Когда модель может читать только несколько утверждённых представлений, у каждого запроса меньше способов пойти не туда.
Установите жёсткие лимиты до выполнения
Модель не должна сама решать, сколько данных вытянуть, сколько может выполняться запрос или допустимо ли широкое соединение. Исполнение должно быть с контролем доступа, а не просто следующим шагом в чате.
Начните с жёсткого предела по строкам. Если модель просит 500 000 строк, база всё равно должна остановиться на меньшем заранее установленном числе. Для многих отчётов 100–1 000 строк достаточно, чтобы убедиться, что запрос верен. Огромные наборы результатов дорогие, долго просматриваются и легко используются не по назначению.
Временные лимиты так же важны. Запрос, который выполняется 30 секунд в продакшене, может блокировать другую работу, сжечь ресурсы и сделать безобидный отчёт похожим на аварию. Установите statement timeout на уровне базы или сессии, чтобы длинные запросы умирали быстро. Проваленный запрос раздражает. Зависший — хуже.
Некоторые формы запросов требуют дополнительных ограничений. Полные сканирования больших таблиц должны проваливаться, если можно использовать индекс. Очень широкие JOIN стоит ограничивать. Доступ между базами или схемами должен требовать одобрения. SELECT * на широких таблицах нужно отклонять, особенно если там есть чувствительные колонки.
Подход "сначала образец, затем одобрение" работает хорошо. Сначала модель возвращает SQL и небольшой сэмпл — например, 20 строк. Человек проверяет, подходят ли столбцы, фильтры и соединения. Только после этого система должна разрешить более крупный запуск, и даже тогда под более жёстким лимитом времени.
Этот шаблон ловит много плохого SQL на раннем этапе. Если модель соединяет customers и orders без нужного условия, дублированные строки появятся в образце прежде, чем станут гигантским экспортом. То же верно для пропущенных WHERE, случайных сканирований и отчётов, вытягивающих намного больше данных, чем просили.
Эти контролы просты. Именно поэтому они работают.
Добавьте контрольные точки проверки
Человек должен одобрить каждый новый запрос до того, как любой инструмент выполнит его над продакшен-данными. Звучит медленно, но обычно это добавляет минуту или две и может сэкономить часы на очистке последствий.
Этап проверки должен показывать точный SQL, а не сводку. Ревьюерам нужно видеть, что именно модель собирается запустить, какие таблицы будут затронуты и сколько строк может вернуться. Если стек умеет показывать оценку количества строк до выполнения, используйте это. Запрос, который должен вернуть 50 строк, но может просканировать 8 миллионов, требует пересмотра.
Модель также должна кратко объяснить запрос простым языком. Одно короткое предложение достаточно: "Посчитать активных клиентов, которые сделали заказ за последние 30 дней." Это предложение помогает быстро поймать несоответствия. Если SQL говорит одно, а объяснение — другое, остановитесь.
Хороший экран одобрения или тикет должен включать полный текст SQL, задействованные таблицы и представления, оценку числа строк или объёма сканирования, причину запроса простым языком и имя утверждающего с меткой времени. Этот последний пункт важнее, чем команды ожидают. Когда вы логируете, кто и когда одобрил запрос, люди внимательнее относятся к процессу, и аудит становится проще.
Держите правило простым. Низкорисковые запросы могут проходить через одного ревьюера. Необычные запросы — большие JOIN, доступ к финансовым данным или повторные попытки — должны требовать второго человека.
Маленькая команда может делать это без сложного процесса. Один аналитик просит отчёт, модель пишет черновик SQL, а коллега проверяет его в очереди перед выполнением. Эта одна контрольная точка ловит неожиданно много ошибок.
Постройте поток шаг за шагом
Безопасный поток начинается до того, как модель напишет хоть строчку SQL. Сначала дайте ей запрос пользователя простым языком, например: "покажи оплаченные счета за прошлый месяц по клиентам." Чёткая формулировка уменьшает угадывания.
Далее позволяйте модели писать SQL только против безопасной карты схемы. Эта карта — небольшой утверждённый вид базы: разрешённые таблицы, столбцы и допустимые соединения. Если модель видит только customers, invoices и несколько полей отчёта, у неё гораздо меньше пространства для рискованных запросов.
Практичный поток выглядит так:
- Приложение отправляет запрос простым языком и безопасную карту схемы модели.
- Модель возвращает черновой SQL и короткое объяснение простым языком того, что, по её мнению, делает запрос.
- Автоматические проверки сканируют SQL на предмет команд записи, отсутствующих фильтров по строкам или датам и признаков очень больших сканирований.
- Рецензент одобряет или отклоняет черновик, и система запускает только одобренные запросы.
- Приложение сохраняет SQL, размер результата, статус одобрения и итог в логе.
Держите автоматические проверки строгими. Блокируйте всё, что содержит INSERT, UPDATE, DELETE, ALTER или DROP. Помечайте запросы, которые трогают целые таблицы без лимита, или соединяют слишком много больших таблиц одновременно. Простые правила здесь лучше хитрых.
Человеческая проверка особенно важна, когда запрос новый, широкий или дорогой. Ревьюер быстро поймает простые ошибки: неверное поле даты, пропущенный фильтр по арендатору или агрегат, который следовало сгруппировать. Для рутинных отчётов команды часто переходят на выборочную проверку вместо просмотра каждого запроса.
Ведите запись о том, что произошло после выполнения. Сохраняйте текст запроса, сколько строк он вернул, сколько времени шел и прошёл ли проверку. Через несколько недель логи обычно покажут одни и те же слабые места снова и снова. Это даёт ясную точку для ужесточения процесса.
Простой пример отчёта
Менеджер поддержки хочет знать суммы возвратов за прошлую неделю по странам. Это звучит просто, поэтому хорошо подходит как тестовое задание. Модель может помочь написать черновик, но ей не нужен свободный доступ к базе.
В более безопасной настройке модель может обращаться только к утверждённым отчётным представлениям. Вместо доступа к живой таблице orders она делает SELECT по представлению, которое уже предоставляет нужные поля для возвратов.
SELECT
country,
SUM(refund_amount) AS total_refunds
FROM reporting.refunds_by_order
GROUP BY country
ORDER BY total_refunds DESC
LIMIT 50;
Черновик близок, но он пропускает важную деталь: фильтр по дате. Если запустить этот запрос как есть, вы получите все суммы возвратов, а не только за прошлую неделю. Здесь и проявляется ценность слоя исполнения.
Перед выполнением система ограничивает размер результата, ставит короткий таймаут и сверяет запрос с исходной просьбой. Она видит, что в подсказке просили прошлую неделю, а в SQL нет диапазона дат. Запрос блокируется и уходит на проверку.
Рецензент сравнивает запрос и просьбу, затем исправляет SQL.
SELECT
country,
SUM(refund_amount) AS total_refunds
FROM reporting.refunds_by_order
WHERE refund_date \u003e= CURRENT_DATE - INTERVAL '7 days'
AND refund_date \u003c CURRENT_DATE
GROUP BY country
ORDER BY total_refunds DESC
LIMIT 50;
Теперь запрос соответствует вопросу. Рецензент одобряет его, запускает с ролью только для чтения и сохраняет как повторно используемый отчёт для команды поддержки.
Так это выглядит на практике. Модель быстро справляется с рутинной частью. Лимиты ловят очевидные упущения. Человек принимает окончательное решение.
Ошибки, которые совершают команды на старте
Большинство команд не начинают с катастрофы. Они начинают с одной удобной детали, которая кажется безобидной. Модель отвечает на пару простых запросов, все расслабляются, и базовые контролы так и не добавляются.
Первая плохая привычка — доступ. Команды часто дают модели те же учётные данные, что уже использует разработчик. Это кажется быстрым, но даёт модели гораздо больший охват, чем нужно. Если одна подсказка пойдёт не так, ущерб может распространяться дальше, чем ожидается.
Те же ранние ошибки повторяются снова и снова. Команды используют обычный dev или admin логин вместо узкой роли только для чтения. Ранние тестовые запросы возвращают маленькие наборы, поэтому никто не добавляет лимиты по строкам или таймауты. Люди сразу направляют модель в продакшен, потому что реальные данные лучше, а копия тестовой БД выглядит старой. Проверка происходит после выполнения — кто‑то смотрит на диаграмму или таблицу, а не на SQL, который её получил. Одобренные запросы теряются в чат‑логах, скриншотах или памяти, и позже никто не может ответить, кто что и зачем запускал.
Пропуск проверки SQL встречается чаще, чем команды признают. Люди смотрят на финальные числа, видят, что они выглядят разумно, и идут дальше. Но запрос может просканировать слишком много данных, соединить неправильные таблицы или открыть колонки, к которым никто не хотел давать доступ. Смотреть только на результат — всё равно что проверять готовый торт, не спрашивая, что в тесте.
Привычка работать прямо в продакшене особенно рискованна. Копия базы даёт пространство для поиска плохих соединений, медленных сканирований и краевых случаев до того, как реальные пользователи почувствуют их. Даже частичная копия лучше, чем учиться на продакшене.
Аудит trails важны тоже. Когда команда хранит одобренный SQL, подсказку, имя проверяющего и время выполнения, мелкие проблемы остаются мелкими.
Быстрая проверка перед запуском
Безопасная настройка должна по умолчанию падать в закрытое состояние. Если модель просит слишком много данных, трогает неправильную таблицу или пишет новую форму запроса, система должна остановиться и попросить помощи, а не догадываться.
Короткий предзапусковой чек‑лист лучше длинной политики:
- Создайте отдельную роль только для чтения специально для запросов ИИ.
- Установите жёсткие лимиты на возвращаемые строки, время выполнения и доступ к таблицам.
- Требуйте человеческое одобрение для любого нового запроса или значимого изменения.
- Логируйте всю цепочку: подсказку, сгенерированный SQL, решение об одобрении, время выполнения и размер результата.
- Протестируйте весь поток сначала на непроизводственных данных, включая плохие подсказки и краевые случаи.
Каждый пункт блокирует разный тип отказа. Роль только для чтения останавливает записи. Ограничение таблиц держит модель подальше от payroll и секретов клиентов. Таймауты и лимиты строк не дают проблеме SELECT * превратиться в замедление.
Человеческое одобрение особенно важно, когда модель делает что‑то новое. Если шаблон запроса уже прошёл проверку и меняется только диапазон дат, часто можно автоматизировать это безопасно. Если модель добавляет соединения, касается новой таблицы или расширяет фильтры так, что увеличивает доступ, человек должен проверить это первым.
Логи нужны не только для аудита. Они помогают быстро заметить закономерности. Если одна подсказка постоянно генерирует большие запросы, вы можете исправить подсказку, сузить вид схемы или полностью заблокировать этот путь.
Тестируйте поток не только на SQL, но и на процесс. Попробуйте невнятные запросы, запутанные формулировки и заведомо большие отчёты. Если ограждения выдерживают там, вы ближе к надёжной настройке.
Что делать дальше
Выберите одну низкорисковую отчётную задачу и держите её маленькой. Еженедельная сводка доходов, отчёт по объёму поддержки или счётчик новых регистраций — достаточно, чтобы протестировать процесс, не рискуя операциями. Если модель проиграет, вы потеряете отчёт, а не данные клиентов.
Напишите правило одобрения до расширения доступа. Команды часто пропускают это, а затем спорят, какие запросы требуют проверки. Запишите простым языком: какие подсказки могут выполняться сами по себе, какие шаблоны SQL всегда требуют проверки, кто одобряет исключения и что блокируется всегда.
Постепённый развёртывание работает лучше, чем большой запуск. Начните с одной роли только для чтения, которая видит лишь таблицы, нужные для отчёта. Добавьте жёсткие лимиты по строкам, времени и размеру результата до любого запуска. Направляйте необычные запросы человеку на одобрение, даже если они выглядят безобидно. Затем просмотрите логи через неделю и ужесточьте слабые места.
Эта проверка логов важнее, чем многие думают. Ищите запросы, которые выполнялись слишком долго, трогали больше таблиц, чем планировалось, возвращали грязные результаты или отклонялись по одной и той же причине чаще, чем один раз. Эти паттерны покажут, где подсказка, права или лимиты оставляют слишком много свободы.
Если первый кейс стабилен неделю‑две, добавьте ещё один отчёт и держите те же правила. Не расширяйте доступ к базе только потому, что модель справилась с простыми задачами.
Если нужен внешний аудит, Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами по практическому внедрению ИИ, инфраструктуре и поддержке в роли Fractional CTO. Короткий обзор ролей, лимитов и шагов одобрения поможет подтянуть процесс, не замедляя отчётность.
Часто задаваемые вопросы
What are the minimum guardrails for AI-written SQL?
Начните с отдельной роли базы данных только для чтения, которая может выполнять SELECT и ничего больше. Затем добавьте жесткие лимиты на количество строк и время выполнения, показывайте каждый новый запрос человеку на проверку и логируйте, что выполнялось и почему.
Why should the model use a read-only role?
Потому что одна неверная подсказка или небольшая ошибка в SQL могут быстро изменить или стереть данные. Роль только для чтения превращает плохой запрос в неудавшийся отчёт, а не в простой.
Is a sample result enough to make AI SQL safe?
Нет. Выборка помогает понять форму результата, но она не заменяет лимиты. Оставляйте лимиты по строкам, короткие таймауты и обязательно проверку даже для пробных выборок.
How do I stop the model from touching the wrong tables?
Используйте утверждённые отчётные представления вместо сырых таблиц. Дайте модели маленькую карту схемы с теми таблицами, столбцами и соединениями, которые ей разрешено использовать.
How many rows should I let an AI query return?
Установите жесткий предел по числу строк на уровне базы или слоя исполнения до запуска запроса. Для большинства отчётов небольшой набор строк достаточно, чтобы проверить корректность перед тем, как разрешать больший объём.
What should I do about slow or expensive queries?
Установите короткий statement timeout, чтобы длинные запросы быстро прерывались. Это защищает базу, когда модель пишет широкое соединение, пропускает фильтр или сканирует больше данных, чем ожидалось.
Do I really need human review every time?
Да — для каждого нового запроса и для любого запроса, который по форме меняется существенно. Когда шаблон отчёта подтвердил стабильность, можно автоматизировать простые изменения вроде диапазона дат, но всё остальное должно проходить через проверку.
Should I test AI SQL on production or a copy first?
Начните на непроизводственных данных. Копия продакшен-базы, пусть даже частичная, даёт возможность поймать плохие соединения, пропущенные фильтры по арендаторам и медленные сканирования прежде, чем реальные пользователи почувствуют проблемы.
What should I log for AI-generated SQL?
Сохраняйте исходную подсказку, сгенерированный SQL, имя утверждающего, время выполнения, размер результата и итог. Эти записи помогут находить повторяющиеся ошибки и ответить на вопрос, кто и зачем запускал запрос.
When should I bring in outside help for setup or review?
Выберите один низкорисковый отчёт, заприте его за ролью только для чтения и сузьте схему. Если хотите внешний взгляд, Oleg Sotnikov на oleg.is поможет проверить роли, лимиты и процесс одобрения и подтянуть безопасность без торможения работы отчётов.


