Бережливый стек автоматизации для небольшой компании с частичным CTO
Бережливый стек автоматизации охватывает формы, очереди, логи и AI-проверку без платформенной команды. Посмотрите, как внешний частичный CTO может это спланировать.
Содержание
Почему маленькие команды застревают
Маленькие команды редко застревают потому, что людям всё равно. Они застревают потому, что работа приходит слишком многими путями, и ни у кого нет времени выстроить один понятный маршрут.
Лид от продаж приходит на почту. Запрос в поддержку появляется в чате. Последующие действия живут в таблице, потому что тогда это казалось быстрым решением. Каждое решение выглядит безобидным. Но через несколько месяцев команда тратит слишком много сил на то, чтобы понять, куда делся запрос и кто за него отвечает.
Приложение часто тормозит по той же причине. Небольшая компания выполняет долгие задачи в том же запросе, которого ждёт клиент. Приложение отправляет файл, вызывает внешний API, создаёт PDF и записывает несколько записей, прежде чем ответить. При низкой нагрузке это работает. Потом один медленный шаг блокирует остальные, и всё приложение начинает казаться хрупким. Без очереди любая задержка бьёт по пользователю.
Та же картина с логами. На сервере один набор логов, в приложении другой, а оповещения приходят вообще в другое место. Разработчик смотрит на одну панель, пропускает другую и узнаёт о реальной проблеме из сообщения клиента. Команды не игнорируют логи специально. У них просто нет одного места, которое сразу понятно с первого взгляда.
Проверка кода скатывается в ту же ловушку. Маленькие команды выкатывают срочные исправления поздно, часто после целого дня другой работы. Проверка проходит впопыхах. Люди смотрят только на очевидные поломки и идут дальше. Потом проскакивают простые проблемы: отсутствующее правило валидации, медленный запрос, секрет в конфиге или крайний случай, который никто не тестировал.
Вот где часто помогает внешний частичный CTO. Его задача — не навешивать ещё больше инструментов. Нужно убрать хаос до небольшого стека, дать каждой форме понятный маршрут, перенести медленную работу в очереди, свести логи в один экран и добавить быструю проверку перед запуском рискованных изменений.
Звучит как мелкая уборка. На практике это может сэкономить часы каждую неделю и убрать ту самую фоновую неразбериху, которая выматывает команду.
Что должен уметь стек
Небольшой компании не нужен отдел платформы. Ей нужен один понятный путь для входящих запросов, одно место, где будут ждать долгие задачи, один экран с логами, который можно искать, один этап проверки кода перед релизом и один человек, который получит оповещение, когда что-то сломается.
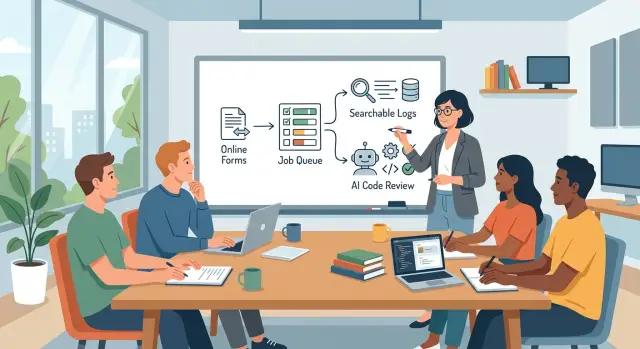
Начните с входящих запросов. Если сообщения приходят по почте, в чате, по телефону и из случайных таблиц, команда тратит время на сортировку шума, прежде чем сможет заняться реальной работой. Простая форма решает большую часть проблемы. Каждый запрос должен попадать в одно и то же место с одними и теми же полями, чтобы команда понимала, что это такое, кто попросил и что нужно делать дальше.
Некоторые задачи не должны выполняться, пока человек ждёт на экране. Обработка файлов, создание отчётов, синхронизация, повторы webhook и AI-проверки должны идти через очередь. Очередь позволяет приложению быстро принять запрос и завершить более тяжёлую работу в фоне. Пользователь видит прогресс, а команда избегает таймаутов и путаных повторов.
Логам тоже нужен один дом. Когда что-то ломается, никто не должен искать по серверным панелям, облачным кабинетам и скопированным кускам терминала. Поиск по логам экономит время, потому что показывает запрос, ошибку и порядок событий в одном месте. Если отправка формы сломалась в 14:13, команда должна найти именно этот запуск за секунды.
Проверке кода нужна та же простота. Бережливый стек должен запускать AI-проверку в обычном потоке поставки перед выкладкой. AI может заметить очевидные ошибки, рискованные изменения, пропущенные тесты и странные паттерны. Он не должен заменять человека. Он должен сделать первый проход намного быстрее.
Оповещения нужны одному владельцу, а не группе в чате, где все говорят «возможно». Если очередь зависла или релиз провалился, один человек должен получить сообщение и понять, что следующий шаг за ним. Хороший внешний CTO может настроить это простыми правилами и теми инструментами, которые у команды уже есть.
Этого достаточно для большинства небольших компаний. Если стек умеет принимать запросы, ставить задачи в очередь, вести логи, проверять код и оповещать, он уже справляется с самым сложным.
Держите стек маленьким с первого дня
Небольшие команды попадают в неприятности, когда решают одну и ту же проблему в трёх местах. Одна форма для продаж, другая для поддержки, отдельный чат-бот для входящих и ещё таблица сверху. Неделю это кажется гибким решением. Потом уже никто не понимает, где лежат настоящие данные.
Выберите один путь для входящих запросов и сделайте его скучным. Веб-форма отправляет данные в ваше приложение или базу данных, а затем одна фоновая очередь обрабатывает следующий шаг. Если позже вы добавите AI-проверку, отправляйте эту задачу через ту же очередь, а не стройте отдельную линию только для AI.
Большинству небольших команд нужно меньше частей, чем они ожидают: один вход для каждого типа запроса, одна очередь для фоновых задач, одно хранилище логов для приложений и worker'ов и одно место для правил хранения и оповещений.
Этого хватает многим компаниям. Форма поддержки может создать запись, поставить задачу на отправку письма, запустить проверку документа и сохранить результат в одном месте. Когда что-то ломается, команда смотрит в одно хранилище логов, а не бегает по пяти панелям.
Логам нужны правила, иначе они быстро превращаются в мусор. Полные логи храните недолго. Ошибки храните дольше. Шумные debug-данные удаляйте по расписанию. Большинству небольших команд в первый день не нужна огромная observability-система. Им нужно отвечать на три простых вопроса: что сломалось, когда это случилось и кто должен действовать.
Выбор инструментов важнее количества функций. Берите то, с чем текущая команда справится без отдельного ops-специалиста. Если форма, очередь или система логов требуют постоянной настройки, для компании из десяти человек с одним инженером это слишком тяжёлая конструкция.
Именно здесь внешняя помощь часто полезнее всего. Задача не в том, чтобы добавить блестящие новые части. Нужно уменьшить стек до нескольких элементов, которые экономят время каждую неделю и оставляют пространство для роста.
Стройте поток по шагам
Бережливый стек автоматизации должен начинаться с одного бизнес-процесса, а не с кучи инструментов. Возьмите что-то скучное и частое, например форму на сайте, которая превращается в запрос на расчёт цены, обращение в поддержку или задачу на follow-up для продаж.
Запишите поток на одной странице до того, как начнёте что-либо строить. Пишите просто: человек заполняет форму, один сервис проверяет и сохраняет данные, worker обрабатывает медленную часть, а команда получает понятный результат.
Хорошая первая версия проста. Сначала отправляйте каждую отправку формы в один сервис. Этот сервис должен проверить поля, сохранить запрос и вернуть простой ответ об успехе или ошибке. Медленную работу выносите в очередь. Отправка писем, создание PDF, синхронизация с CRM и AI-проверки должны идти в фоне, чтобы форма оставалась быстрой.
Добавьте request ID на первом шаге и ведите его через весь поток. Когда что-то ломается, вы сможете найти точную отправку формы, задачу в очереди и строку лога за минуты. Делайте логи читаемыми. Логируйте момент поступления запроса, запуск worker'а, завершение работы и причину сбоя.
Запускайте AI-проверку на pull request'ах, а не в продакшене. Пусть она ищет очевидные баги, пропущенные тесты, рискованные изменения и неясный код до того, как кто-то сольёт изменения.
Это ещё одно место, где частичный CTO может сэкономить время. Один человек может выбрать сервис для входящих запросов, одну очередь для долгих задач и одно место для логов вместо того, чтобы позволять команде склеивать пять пересекающихся инструментов.
Небольшой пример делает это понятнее. Допустим, у клининговой компании есть форма бронирования. Сервис формы сохраняет запрос, присваивает ему request ID 84271 и отправляет расчёт в очередь. Worker считает цену, отправляет письмо и записывает каждый шаг под этим же ID. Если расчёт ломается, команда видит, где именно всё остановилось.
Перед запуском специально проверьте один сбой. Сломайте шаг отправки письма или заставьте worker отклонить задачу. Если команда не может проследить этот сбой от формы до лога за несколько минут, стек всё ещё слишком рыхлый.
Простой пример из небольшой компании
Представьте сервисную компанию из 15 человек, которой нужно быстро обрабатывать каждый запрос с сайта без того, чтобы кто-то дежурил у почты. Бережливая автоматизация может хорошо делать одну вещь: принимать каждый запрос, маршрутизировать его и оставлять понятный след.
Клиент открывает форму обратной связи, указывает имя, компанию и короткую заметку, а затем нажимает отправить. Приложение не пытается сделать всё сразу. Сначала оно сохраняет запрос в базу данных, присваивает ему ID и помещает небольшую задачу в очередь.
Такое разделение важно. Если письмо идёт медленно или downstream-инструмент на минуту работает плохо, форма всё равно работает. Клиент видит сообщение об успехе, а команда не теряет лид.
Через несколько секунд worker забирает задачу из очереди. Он создаёт задачу на follow-up для продаж или поддержки, отправляет внутреннее уведомление и может подготовить черновик ответа, если компании это нужно. Если один шаг ломается, worker повторяет именно этот шаг, а не заставляет клиента отправлять форму заново.
Логи связывают весь путь. Отправка формы, задача в очереди, запуск worker'а и финальный результат — всё идёт под одним request ID. Когда кто-то спрашивает: «Мы получили это сообщение?», команда отвечает за минуту, а не роется в трёх инструментах и не гадает.
Система остаётся маленькой: один обработчик формы, одна очередь, один worker, одно место для логов. Никакой платформенной команды, никакого лабиринта сервисов, никакой схемы, которую никто не обновляет.
AI-проверка подключается перед релизом, а не в живом пути запроса. Когда разработчик меняет обработчик формы, этап AI-проверки может проверить, нет ли пропущенной валидации, небезопасной обработки ввода, дублирующего создания задач или секретов в логах. Он отмечает рискованный код до того, как он попадёт в продакшен.
Этого достаточно для многих небольших компаний. Такой поток покрывает формы, очереди, логи и AI-проверку, не превращая обычную страницу контактов в мини-энтерпрайз систему.
Где уместна AI-проверка
В бережливом стеке автоматизации AI-проверка должна стоять после автоматических тестов и перед тем, как человек одобрит слияние. Это важно, потому что инструмент видит diff, результаты тестов и изменённые файлы. Он комментирует реальный риск, а не гадает.
Если использовать его правильно, AI-проверка становится быстрым вторым взглядом. Она может заметить слабые названия, пропущенные крайние случаи и тесты, которые должны быть, но которых нет. Она также может увидеть паттерны, которые часто создают проблемы, когда небольшая команда работает быстро.
Сначала держите область применения узкой. Начните с одного репозитория или одного сервиса, а не со всей компании. Частичный CTO может задать простые правила проверки, подключить их к CI и настроить комментарии так, чтобы команда получала меньше шумных сигналов.
Что должен отмечать AI
AI-проверка особенно полезна, когда проверяет короткий список проблем, которые люди часто пропускают в загруженные недели:
- неясные названия, из-за которых позже сложнее вносить изменения
- пропущенные тесты для сценариев ошибок и необычных входных данных
- рискованные правки в авторизации, логике биллинга и миграциях базы данных
- изменения, которые влияют на повторы очереди, обработку дубликатов или логирование
Последняя область важнее, чем кажется командам. Форма может отправиться дважды. Worker может повторить одну и ту же задачу. Одна строка лога может скрыть именно то поле, которое вам нужно во время сбоя. AI может предупредить о таких паттернах до того, как они попадут в продакшен.
Человеческое одобрение по-прежнему должно управлять слияниями и релизами. AI недостаточно хорошо понимает контекст бизнеса, чтобы принимать финальное решение, и он никогда не должен самостоятельно отправлять код в продакшен. Правило должно быть простым: AI комментирует, люди решают.
Допустим, у компании есть один сервис, который принимает формы, ставит задачи в очередь и записывает статус в базу данных. Разработчик меняет логику повторов для неудачных задач. AI-проверка может указать, что теперь код рискует создать дублирующие списания, не имеет теста для случая таймаута и переименовывает поле так, что ломается поиск по логам. Это экономит болезненную чистку позже.
Сложность не в том, чтобы добавить AI-ревьюера. Сложность в том, чтобы объяснить ему, что именно ваша команда считает рискованным.
Ошибки, которые создают лишнюю работу
Небольшие команды редко тонут из-за нехватки инструментов. Обычно они тонут в слишком большом количестве маленьких решений, которые быстро накапливаются. Хороший частичный CTO часто исправляет это, убирая лишнее, а не добавляя ещё одно приложение.
Первая ошибка — покупать отдельный инструмент для каждой проблемы. Один инструмент для форм, другой для фоновых задач, третий для оповещений и четвёртый для логов красиво выглядит на странице с тарифами. В реальной работе это означает четыре панели, четыре счёта и четыре места, где никто не чувствует себя полностью ответственным.
Другая частая проблема начинается тогда, когда команда продолжает добавлять workflow, но никто за них не отвечает. Форма продаж отправляется в одну очередь, запросы в поддержку идут куда-то ещё, а полуготовая автоматизация всё ещё работает, потому что никто не хочет к ней прикасаться. Через три месяца люди перестают доверять системе и возвращаются к сообщениям в чате и таблицам.
Логи создают свою собственную боль, когда у запросов нет ID, который проходит через весь путь. Клиент отправляет форму. Задача попадает в очередь. Этап AI-проверки проверяет результат. Что-то ломается, но команда не может проследить этот запрос между сервисами. В итоге они тратят час на чтение логов, которые выглядят не связанными.
Сбои задач приносят ещё больше тихого ущерба, когда в стеке нет правил повторной попытки. Сети дают сбои. API не успевают ответить. Очереди зависают. Если одна неудачная задача просто исчезает, сотрудники начинают вносить данные вручную, а это медленно и легко приводит к ошибкам. Большинству небольших компаний хватает простой логики повторов, dead-letter queue и понятного оповещения, когда задача всё ещё не выполнилась после нескольких попыток.
AI-проверке нужна та же дисциплина. Если позволить AI одобрять код, контент или действия поддержки без письменных правил, всё быстро начнёт расплываться. Модель может быть быстрой, но скорость — это не суждение. Заранее задайте границы. Решите, что AI может одобрять сам, какие изменения требуют проверки человеком, записывайте каждое решение AI вместе с prompt и результатом и заранее опишите шаги отката перед релизом.
Бережливый стек автоматизации должен быть скучным в лучшем смысле. Команда должна уметь проследить каждый запрос, быстро исправлять сбои и знать, кто отвечает за каждый движущийся элемент.
Короткая проверка перед тем, как вы закрепите изменения
Прежде чем добавить ещё один инструмент, прогоните один реальный запрос через весь поток. Попросите человека, который его спроектировал, объяснить каждый шаг меньше чем за пять минут. Если ему нужны доска, три вкладки и куча оговорок, значит, для небольшой команды система уже слишком сложная.
Начните с входной двери. Человек без технического опыта должен суметь отправить тестовую форму без помощи, дождаться результата и понять, что произошло. Если для первого теста рядом нужен разработчик, процесс сломается в тот момент, когда команда станет занята.
Потом проследите тот же запрос до конца. Вы должны знать, где форма сохраняет данные, какая очередь её забрала, какой worker её обработал, куда ушли логи и как вернулся результат. В бережливом стеке автоматизации этот путь должен казаться почти скучным. Это хороший знак.
Несколько проверок говорят о многом:
- Один человек может вслух объяснить весь поток за пять минут.
- Команда может проследить один запрос от отправки формы до финального результата.
- Неудачные задачи видны в одном месте без ручных поисков.
- Человек без технического опыта может отправить тестовую форму и подтвердить результат.
- Вы можете убрать один инструмент и при этом сохранить работу основного процесса.
Последний пункт важнее, чем кажется. Если вся система рушится, когда вы меняете одну очередь, инструмент логов или этап AI-проверки, у вас не стек. У вас куча зависимостей.
AI-проверке нужен тот же тест. Команда должна знать, что именно проверяет модель, где появляется результат проверки и что происходит, когда модель что-то отмечает или не успевает ответить. Никому не нужно искать сырые логи только ради ответа на вопрос: «Проверка вообще запускалась?»
Что делать дальше
Выберите один процесс, который каждую неделю съедает время, и автоматизируйте только его. Не начинайте сразу с пяти идей. Лид-форма, которая никуда не ведёт, запросы в поддержку, которые застревают в чате, или согласование счетов, зависящее от памяти, — всё это хорошие первые цели.
Опишите текущий поток простыми словами. Держите его коротким: где запрос начинается, где он ждёт, кто его проверяет и где появляются проблемы. Если вы не можете описать это в шести-семи строках, процесс всё ещё слишком запутан для автоматизации.
Для большинства небольших команд первая версия требует меньше, чем ожидают люди: один способ собирать входящие данные, одна очередь, где ждёт работа, одно место для чтения логов и один этап проверки перед тем, как результат пойдёт дальше. Этого достаточно, чтобы закрыть формы, очереди, логи и AI-проверку, не превращая всё в побочный проект. Если команда уже использует инструмент для форм, список тикетов и просмотр логов, оставьте их. Новые инструменты редко спасают слабый процесс.
Назначьте одного ответственного. Ему не нужно строить всё самому, но он должен отвечать за настройку, тестовые прогоны и короткую еженедельную проверку. Пятнадцати минут раз в неделю часто хватает, чтобы заметить зависшие задачи, шумные логи или AI-замечания, которые никто не читает.
Простой первый workflow уже может принести пользу. Форма на сайте создаёт элемент очереди, система логирует каждый шаг, а AI пишет черновик ответа или помечает запрос для нужного человека. Человек проверяет результат перед отправкой. Это экономит время и делает ошибки видимыми.
Если первая версия работает, не поддавайтесь искушению навесить сверху ещё больше. Погоняйте её месяц. Посчитайте, сколько задач прошло через неё, где люди всё ещё выходят из процесса и какие оповещения никто не читает.
Некоторые команды привлекают внешнюю помощь, потому что у них нет времени самостоятельно разбирать инструменты, расходы и архитектуру. Олег Сотников из oleg.is консультирует малый и средний бизнес по таким задачам — от поддержки в роли частичного CTO до бережливой инфраструктуры и разработки с AI. Если цель — маленький стек, который команда действительно сможет обслуживать, такая практическая помощь может сэкономить много переделок позже.
Часто задаваемые вопросы
Что должна автоматизировать небольшая компания в первую очередь?
Начните с одного процесса, который отнимает время каждую неделю, например с контактной формы, запроса в поддержку или запроса на расчёт цены. Выберите то, что встречается часто, легко проверить и достаточно болезненно, чтобы все заметили сбой.
Почему стоит использовать очередь, а не делать всё в одном запросе?
Очередь сохраняет скорость формы или приложения, потому что переносит медленную работу в фон. Пользователь сразу отправляет запрос, а worker потом обрабатывает письма, создание PDF, синхронизацию или AI-проверки, не блокируя экран.
Сколько инструментов нужно бережливому стеку автоматизации?
Большинству команд нужно меньше, чем кажется: один способ собирать входящие данные, одна очередь для фоновых задач, один экран с логами и один этап проверки перед релизом. Если для одной задачи нужно три инструмента, стек быстро станет путаным.
Где AI-проверка должна стоять в процессе поставки?
Поставьте AI-проверку после тестов и перед тем, как человек одобрит слияние. Так модель видит изменения, результаты тестов и контекст файлов и может заметить очевидные баги, слабую валидацию, проблемы с повторами и пропущенные тесты, не управляя релизами.
Кто должен отвечать за оповещения, когда что-то ломается?
Отдайте оповещения одному конкретному владельцу, а не группе в чате. Когда деплой падает или worker зависает, один человек должен знать, что именно ему нужно проверить, решить вопрос и закрыть проблему.
Как сделать так, чтобы сбои было легко отслеживать?
Добавьте request ID на первом шаге и сохраняйте его во всём потоке. Логируйте поступление запроса, задачу в очереди, запуск worker, повторы и финальный результат под этим же ID, чтобы команда нашла точный сбой за минуты.
Нужна ли нам большая observability-система с первого дня?
Нет, не сразу. Небольшой компании обычно важнее поиск по логам, несколько полезных оповещений и понятные правила хранения, чем огромная система наблюдаемости.
Могут ли неразработчики тестировать workflow?
Да, и это даже лучше. Человек без технического опыта должен отправить тестовую форму, дождаться результата и понять, что произошло, без помощи разработчика на протяжении всего процесса.
Когда имеет смысл нанять частичного CTO?
Привлекайте его, когда команда постоянно добавляет инструменты, никто не доверяет рабочему процессу или сбои слишком долго приходится разбирать. Внешний CTO может убрать дубли, выбрать более компактный стек и настроить понятную ответственность без долгой переделки.
Какие ошибки создают больше всего лишней работы в небольшом стеке автоматизации?
Команды обычно создают больше всего лишней работы, когда дробят входящие запросы по слишком многим местам, не используют request ID, игнорируют правила повтора или позволяют AI действовать без письменных ограничений. Держите один понятный путь для запросов, одно место для логов и человеческое одобрение для рискованных изменений.