Бережливая инфраструктура для глобального продукта с одним владельцем
Бережливая инфраструктура для глобального продукта означает меньше сервисов, простое наблюдение и понятные бэкапы, которые один технический владелец может поддерживать без хаоса.
Содержание
Почему длинный список вендоров ломает маленькую команду
Небольшие продукты редко падают потому, что один сервер слишком простой. Обычно проблема в том, что стек превращается в лабиринт.
Каждый лишний сервис добавляет счет, логин, алерт и еще одно место, где что-то может сломаться незаметно. Когда системой владеет один человек, эта цена не абстрактная. Она всплывает в 2 часа ночи, когда перестает работать почта, ломается вход в систему или приложение тормозит, а позвонить больше некому.
Проблема становится хуже, когда инструменты зависят друг от друга. Небольшая ошибка в DNS может сломать auth. Проблема с auth может заблокировать приложение. Потом мониторинг начинает ругаться на симптомы, а не на настоящую причину. Исправление может занять пять минут. А вот поиск причины — три часа.
Обычная работа тоже страдает. Продление подписок, проверка лимитов использования, ротация секретов и разбор шумных алертов съедают те же часы, которые должны идти на работу над продуктом. Фичи сдвигаются, баги ждут дольше. Простое обслуживание превращается в полдня кликов по пяти админ-панелям.
Именно поэтому опытные операторы обычно сначала сокращают инструменты, а уже потом добавляют новые. Олег Сотников на практике показал ту же идею, удерживая глобальную платформу с крошечной AI-усиленной операционной командой. Вывод простой: маленьким командам нужны понятные системы, а не еще больше систем.
Если новый сервис не убирает еженедельную работу, он, скорее всего, добавляет будущие сбои.
Что на самом деле нужно глобальному продукту
Большинство продуктов ломаются не потому, что им не хватает еще одного вендора. Они ломаются потому, что базовые вещи выходят из строя в самый неудобный момент.
Для бережливой инфраструктуры глобального продукта первая цель простая: страницы должны открываться быстро, вход в систему должен работать всегда, а приложение должно оставаться стабильным при обычной нагрузке. Пользователи замечают задержку раньше, чем замечают фичи. Если первый экран тормозит, люди уходят. Если вход ломается хотя бы раз, доверие быстро падает.
Надежная база данных важнее, чем куча дополнительных систем. Выберите базу, которую умеете обслуживать, держите ее в порядке и не спешите слишком рано распылять данные по лишним инструментам. Для многих продуктов одной хорошо настроенной PostgreSQL с проверенными бэкапами хватает надолго.
Еще нужны быстрые ответы, когда что-то идет не так. Понятные алерты, свежие логи и простой обзор ошибок экономят реальное время. Алерт, который говорит, что после деплоя выросла частота ошибок, полезен. Пятьдесят уведомлений за час — нет.
Бэкапы имеют смысл только если восстановление работает. Храните свежие снимки, тестируйте восстановление по графику и пишите шаги простым языком. Многие founders сначала тратят деньги на сложные инструменты, а уже потом выясняют, что не могут восстановить базу меньше чем за час. Это неправильный порядок.
Пиковая нагрузка требует запаса, а не десятка платформ. Оставьте достаточно CPU, памяти и соединений с базой, чтобы запуск продукта или email-рассылка не уронили приложение. Именно такая схема помогает маленьким командам держать высокий uptime: достаточно простая, чтобы один технический владелец все понимал, и достаточно надежная, чтобы оставаться онлайн.
Начните с простого базового стека
Большинство продуктов могут работать на меньшем количестве частей, чем люди думают. Если всем управляет один человек, каждый лишний сервис — это еще одна панель, еще один счет и еще одно место для отладки.
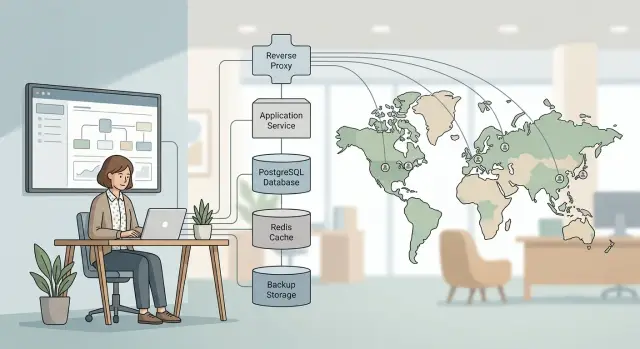
Держите в центре один сервис приложения и делайте путь запроса коротким. Web-приложение или API, одна основная PostgreSQL и один понятный способ деплоя могут долго тянуть реальный продукт. Так у владельца будет меньше движущихся частей и меньше мест, куда смотреть при поломке.
Не добавляйте кэш в первый же день только потому, что он есть у других команд. Добавляйте Redis, когда можете назвать для него понятную задачу: повторяющиеся тяжелые чтения, медленная работа сессий или фоновые задачи, которые блокируют запросы пользователей. До этого база данных часто справляется и так.
То же правило работает и для других хранилищ данных. Поисковые движки, message brokers, event-системы и отдельные аналитические базы могут пригодиться позже. На раннем этапе они обычно добавляют больше задач по бэкапам, обновлениям и точек отказа, чем пользы.
Небольшой стек часто выглядит скучно:
- один основной сервис приложения
- одна основная база данных
- один путь деплоя
- одно место для логов и алертов
Здесь «скучно» — это комплимент.
Знакомые инструменты важнее модных. Если владелец уже знает Docker, PostgreSQL, Linux и простой CI/CD-процесс, такая схема обычно лучше, чем новый стек, который еще пришлось бы изучать прямо во время инцидента. Система остается понятной, а это уже половина победы.
Собирайте систему в правильном порядке
Стек для одного технического владельца не должен начинаться с похода по магазинам. Собирайте систему в том порядке, который в первую очередь защищает uptime.
Сначала поставьте один reverse proxy. nginx может обрабатывать TLS, маршрутизировать запросы и дать одно место для управления правилами трафика. Затем настройте PostgreSQL и оставьте его простым. Большинство продуктов гораздо дольше, чем кажется, спокойно живут на одной надежной базе.
Сделайте бэкапы, прежде чем гнаться за масштабом. Если вы не можете быстро восстановиться, дополнительные серверы только добавляют новые способы все сломать. После этого добавьте Redis, если можете назвать задачу, которую он будет решать. Если не можете объяснить, зачем он нужен, подождите.
Второй регион должен появляться позже — после того как вы измерите реальную проблему. Продукту с пользователями в Европе, США и Азии не нужны три региона в первый день. Сначала держите приложение и базу в одном регионе, измеряйте время ответа и смотрите поддержку. Если приложение ощущается достаточно быстрым и никто не жалуется, оставляйте схему маленькой.
Redis — одна из самых частых ранних ошибок. Команды добавляют его, потому что он кажется частью современного стека, а потом неделями разбираются с cache miss, устаревшими данными и еще одной системой, которую надо мониторить. Если PostgreSQL выдерживает нагрузку и время загрузки страниц остается нормальным, отложите Redis, пока продукт не докажет обратное.
То же касается многорегиональной архитектуры. Ночной дамп базы и отработанная тренировка восстановления важнее, чем второй регион, на который вы ни разу не переключались при аварии. Пусть реальная задержка, рост или требования к соответствию сами заставят вас что-то менять.
Практичный стек, который остается маленьким
Небольшому глобальному продукту не нужны десять вендоров и пять панелей. Ему нужен один стек, который один человек может понять под давлением и быстро починить после плохого деплоя или всплеска трафика.
Хороший стартовый вариант простой. Держите web-приложение и API за одним reverse proxy и на одной инфраструктуре, пока это работает. Один вход означает меньше сертификатов, меньше правил маршрутизации и меньше мест, где запросы могут потеряться.
Позвольте PostgreSQL хранить большую часть данных продукта, если нет ясной причины делить их раньше времени. Аккаунты пользователей, записи биллинга, данные приложения и внутренние админ-инструменты могут долго жить там же. Многие команды сами создают себе лишнюю работу, слишком рано добавляя вторую базу.
Для деплоев используйте один CI/CD-путь и держите откат в том же самом процессе. В self-hosted инфраструктуре это особенно важно, потому что у вас нет большой ops-команды, которая подхватит дрейф конфигурации. Олег часто использует self-hosted GitLab CI/CD для бережливых систем именно по этой причине: один pipeline может собирать, тестировать, выкатывать и откатывать без лишней склейки.
Держите вместе и observability. Prometheus и Grafana для метрик, Loki для логов, Sentry для ошибок приложения и один канал алертов к владельцу — это практичная схема. Так можно перейти от скачка CPU к плохому деплою и к точному исключению, не открывая шесть вкладок и не гадая.
Когда пользователи распределены по регионам, сначала вынесите статические файлы за CDN. Изображения, загрузки, JavaScript и CSS сразу выигрывают, а приложение и API могут оставаться централизованными намного дольше. Олег использует Cloudflare и nginx в production для такой схемы, потому что это снижает задержку без необходимости полностью переделывать систему.
Если один человек может за пять минут объяснить весь стек на доске, скорее всего, он все еще достаточно маленький.
Делайте деплои скучными и обратимыми
Когда стеком владеет один человек, каждый деплой должен идти по одному и тому же пути. Никаких особых случаев. Никаких ночных команд в shell. Никаких догадок, что менялось на сервере в прошлый раз.
Простой релизный процесс лучше хитрого. Отправьте код, прогоните те же тесты, соберите тот же артефакт, разверните его тем же способом, а потом проверьте те же сигналы здоровья. Повторяемость и делает деплои безопасными.
Маленькие релизы проще доверять. Если изменение затрагивает один API-роут, одно правило биллинга или одну фоновую задачу, проблему можно быстро заметить и быстро откатить. Большие пачки работают наоборот. Они скрывают причину ошибок, усложняют откат и превращают короткое исправление в час чтения логов.
Хороший процесс деплоя не обязан быть сложным. Используйте один pipeline для каждого окружения. Храните чеклист отката с точными командами. Пишите заметки к релизу простым языком. Добавляйте метки версии в систему ошибок и алерты, чтобы сразу видеть, не вызвал ли release 1.8.4 скачок.
Шаги отката должны помещаться на один экран. Если процесс требует десяти ручных действий, он сломается, когда вы устанете.
Команды, которые работают бережливо, обычно держат все просто: понятные теги релизов, один видимый след деплоя и observability-инструменты, показывающие, что и когда изменилось. Названия брендов здесь менее важны, чем сама форма процесса.
Потренируйте откат до того, как он понадобится. Выпустите маленькое изменение в обычный будний день, посмотрите на rollout, подтвердите алерты, а потом один раз откатите все специально. Если эта тренировка кажется раздражающей, это полезный сигнал. Значит, в процессе еще слишком много трения.
Мониторинг и бэкапы, которым может доверять один человек
Одному владельцу не нужно больше алертов. Одному владельцу нужны правильные алерты.
Если ломается вход, не работает checkout, страницы начинают ползти, а ошибки API растут, отправляйте срочное уведомление. Если CPU подпрыгнул на минуту, а пользователи ничего не заметили, зафиксируйте это и вернитесь позже. Алерты должны реагировать на боль пользователя, а не на драму сервера.
Свежие логи должны легко находиться, пока проблема еще жива. Держите логи приложения, события деплоя и базовые метрики рядом друг с другом и с одинаковыми временными метками. Когда человек на дежурстве один, потерять десять минут между тремя панелями — слишком дорого.
Небольшая observability-схема часто работает лучше, чем хитрая. Отслеживание ошибок приложения, несколько uptime-checks и панели для состояния базы, очередей и времени ответа обычно достаточно. Поиск по логам особенно важен во время инцидентов. Если можно фильтровать по request ID, релизу или аккаунту клиента, вы очень быстро убираете догадки.
Олег Сотников использует такую бережливую production-схему с Sentry, Grafana, Prometheus и Loki. Суть не в названиях инструментов. Суть в том, что один человек может открыть систему и быстро найти проблему.
Бэкапы тоже требуют дисциплины. Храните копии базы отдельно от основных серверов и основного аккаунта. Держите свежие копии для быстрого восстановления и более старые — на случай медленных ошибок, которые замечают через несколько дней.
Потом по расписанию проверяйте полное восстановление. Для многих небольших команд хороший старт — раз в месяц. Бэкап считается бэкапом только тогда, когда вы восстановили его в рабочую среду, убедились, что приложение запускается, подключается и отдает трафик.
Запишите, кого и когда будить по тревоге, даже если ответ — в основном один и тот же человек. Отдельно отметьте, что должно будить вас в 2 часа ночи, а что может подождать до утра. Такая маленькая заметка экономит время, когда стресс уже высокий.
Реалистичная схема для пользователей в трех регионах
Небольшой SaaS-продукт может обслуживать клиентов в США, Европе и Азии без огромного стека. Один владелец часто может вести одно приложение, одну базу PostgreSQL и небольшой Redis в одном основном регионе. Этого достаточно для многих продуктов, построенных вокруг форм, дашбордов, отчетов и фоновых задач, а не live-видео или тяжелого realtime-трафика.
Пользователи в каждом регионе все равно могут получать достойный опыт, потому что CDN отдает статические файлы ближе к ним. JavaScript, CSS, изображения и загрузки приходят с edge-локаций, поэтому сервер приложения обрабатывает только ту работу, которой нужны свежие данные. Это делает основной сервер легче и сокращает лишний трафик.
Такая схема остается управляемой, потому что у каждого элемента есть понятная задача. PostgreSQL хранит данные продукта. Redis отвечает за кэш или короткоживущие задачи, если приложению это действительно нужно. Приложение делает остальное. Вам не нужно платить одному сервису за кэш, другому — за очереди, третьему — за логи, а четвертому — за повторное хранение тех же метрик.
Ежедневные проверки тоже остаются простыми. Смотрите на ошибки приложения, рост диска базы, память Redis, если вы его используете, успешность бэкапов и то, что алерты по-прежнему приходят в одно место и имеют смысл. Один человек может сделать это за кофе. Один человек не может жить с 40 шумными алертами от шести вендоров.
Это подойдет не каждому продукту. Если у вас live-collaboration, low-latency trading или большие медиа-пайплайны, вам понадобится больше. Но для типичного SaaS с пользователями в трех регионах это разумное сочетание скорости, uptime и спокойствия.
Ошибки, которые создают лишнюю работу
Большая часть лишней работы появляется из-за вещей, которые вам пока не нужны. Стек становится больше, а продукт не становится ни безопаснее, ни проще в обслуживании.
Kubernetes — частый пример. Если одно приложение и так нормально работает на небольшом числе серверов или даже на Docker Compose, Kubernetes может добавить больше движущихся частей, чем убрать. И тогда вы начинаете разбираться с обновлениями кластера, сетевыми правилами, секретами, ingress и сбоями, которые вообще не связаны с вашим продуктом.
Использование нескольких баз данных ради маленьких фич дает ту же проблему. Команда начинает с PostgreSQL, добавляет Redis, потому что так делают все, потом Elasticsearch для поиска, ClickHouse для отчетов и, возможно, еще одно хранилище для очередей. Каждому из них нужны бэкапы, обновления, алерты, настройка памяти и план на случай дрейфа данных.
Разрозненная observability — еще один медленный слив времени. Когда что-то ломается, одному человеку не стоит открывать пять панелей, чтобы ответить на один простой вопрос. Если деплои, логи, uptime-checks и отслеживание ошибок живут в разных системах с разными временными метками и правилами алертов, диагностика занимает дольше, чем само исправление.
Команды также слишком рано бросаются в многорегиональную архитектуру. На бумаге это выглядит умно, но на практике часто удваивает работу по деплоям, репликации, кэшированию, failover и поддержке. Если большинству пользователей достаточно одного удачно расположенного региона и CDN, ранний multi-region — обычно дорогое репетиционное шоу.
Бэкапы создают самую опасную ложную уверенность. Зеленые статусы бэкапов выглядят успокаивающе, пока не случается неудачная миграция и не выясняется, что восстановление неполное, слишком старое или слишком медленное.
Хорошее правило простое: добавляйте сложность только после того, как текущая схема дважды создала реальную проблему. До этого держите один понятный стек, одну основную базу, один путь observability и регулярные тесты восстановления.
Быстрые проверки перед добавлением еще одного сервиса
Каждый новый сервис должен решать боль, которую вы уже чувствуете. Если причина звучит расплывчато, например «лучшая масштабируемость» или «больше гибкости», подождите.
Новый инструмент — это не только еще один счет. Он добавляет еще и логин, API-токен, еще одну панель, еще один источник алертов и еще одну точку отказа, о которой придется помнить, когда что-то сломается.
Прежде чем соглашаться, сделайте четыре быстрые проверки:
- Назовите точную проблему одним предложением.
- Посчитайте новый счет, секрет, алерт и точку отказа, которые он добавляет.
- Проверьте, не делает ли текущий стек уже большую часть этой работы.
- Убедитесь, что владелец сможет объяснить, как это работает, за десять минут.
Эта третья проверка экономит много денег. Команды часто покупают отдельные сервисы для очередей, cron-задач, feature flags, логов или внутренних инструментов, хотя PostgreSQL, GitLab CI, Grafana или Sentry уже закрывают большую часть потребности.
Объяснение важнее списка функций. Если человек на дежурстве не может объяснить, что делает сервис, как он ломается и как его обойти, стек слишком сложный.
Инциденты быстро показывают лишний вес. Если во время аварии никто не открывает какую-то панель, уберите ее. Если алерты идут в канал, который люди игнорируют, выключите их или перенесите в систему, которой вы уже доверяете. Меньший стек проще защищать, дешевле поддерживать и гораздо спокойнее с ним жить.
Если не уверены, отложите покупку и запишите обходной вариант. Если обходной вариант мешает каждую неделю, тогда добавляйте сервис. Если нет — вы только что избежали еще одной постоянной зависимости.
Когда одному владельцу нужна подстраховка
Одному владельцу не нужен план спасения, построенный вокруг пяти консультантов. Ему нужна простая карта того, что работает, сколько это стоит и что ломается первым.
Вынесите каждый сервис на одну страницу с его ежемесячной стоимостью, тем, кто им управляет, и тем, от чего он зависит. Включите и скучные части: DNS, email, отслеживание ошибок, CI, бэкапы, CDN и биллинговые аккаунты. Маленькие команды обычно быстро находят дубли. Два инструмента мониторинга, две системы сборки или платный сервис, который почти делает то же самое, что и основной серверный стек, добавляют расходы и стресс, но почти не добавляют безопасности.
Рядом с этим списком держите короткий runbook. Отметьте, где лежат секреты, как перезапустить приложение, куда идут логи и у кого есть доступ к production. Если другой человек не сможет следовать этим заметкам за 15 минут, схема все еще слишком завязана на вас лично.
Потом поставьте несколько задач в календарь на этот месяц: перечислить все сервисы и их счета, восстановить один бэкап в чистую среду, специально откатить один деплой и убрать дубли до покупки чего-то нового. Эти проверки меняют настроение команды, где всем управляет один человек. Вы перестаете гадать и начинаете измерять.
Иногда стек кажется тяжелее, чем сам продукт, потому что никто давно не ставил под вопрос старые решения. Часто это как раз тот момент, когда нужен взгляд со стороны. Fractional CTO для стартапов может помочь сократить расходы на инфраструктуру, упростить путь деплоя и убрать слабые места, не переворачивая всю систему с ног на голову.
Олег Сотников занимается такой консультативной работой через oleg.is, делая акцент на архитектуре, инфраструктуре и практичных AI-подходах для маленьких команд. Иногда короткой ревизии достаточно, чтобы вернуть стэк, которым управляет один человек, под контроль.
Часто задаваемые вопросы
Что должно быть в моем первом production-стеке?
Начните с одного сервиса приложения, одной базы PostgreSQL, одного reverse proxy вроде nginx, одного пути деплоя и одного места для логов, метрик и ошибок. Так у одного владельца будет короткий путь запроса и меньше мест для отладки в 2 часа ночи.
Нужны ли мне несколько регионов с первого дня?
Обычно нет. Сначала запустите приложение и базу в одном надежном регионе, отдайте статические файлы через CDN и измерьте реальную задержку, прежде чем расширяться. Для многих SaaS такого набора достаточно по всему миру.
Хватит ли PostgreSQL для раннего глобального продукта?
Для многих продуктов — да. PostgreSQL может долго хранить аккаунты, биллинг, данные продукта и внутренние инструменты, если вы регулярно проверяете бэкапы и следите за состоянием базы. Делите данные позже, когда появится поняткое узкое место.
Когда стоит добавить Redis?
Добавляйте Redis только тогда, когда можете назвать для него одну конкретную задачу: кэшировать повторяющиеся тяжелые чтения, хранить сессии или запускать фоновые задачи. Если PostgreSQL и так держит скорость страниц, Redis пока можно не добавлять и не усложнять мониторинг.
Что мониторить, если стеком управляю один я?
Сначала реагируйте на проблемы пользователей: сбои входа, ошибки оформления заказа, медленные страницы, рост ошибок API и неудачные деплои. Храните логи, события деплоя, метрики и ошибки приложений рядом друг с другом, чтобы быстро перейти от алерта к причине.
Как часто нужно тестировать бэкапы и восстановление?
Проверяйте восстановление по реальному графику, и для многих маленьких команд раз в месяц — хороший старт. Бэкап полезен только тогда, когда его можно восстановить в рабочую среду, запустить приложение и убедиться, что оно обслуживает трафик.
Стоит ли Kubernetes того для маленького продукта?
Скорее всего, нет на старте. Если одно приложение нормально работает на нескольких серверах или через Docker Compose, Kubernetes часто добавляет кластерные задачи, сетевые правила и работу с секретами, не решая реальную проблему.
Как безопасно делать деплои, если я один?
Используйте один pipeline для всех окружений, выпускайте небольшие изменения и держите шаги отката настолько короткими, чтобы они помещались на один экран. Добавьте отметки версии в систему ошибок, чтобы сразу видеть, не вызвал ли релиз скачок.
Как понять, что новый сервис действительно нужен?
Сначала запишите точную проблему одним предложением, затем посчитайте, какой счет, логин, секрет, источник алертов и точку отказа добавит сервис. Если ваш текущий стек уже закрывает большую часть задачи, подождите и не усложняйте систему.
Когда стоит обратиться за внешней помощью?
Привлекайте вторую пару глаз, когда стек начинает весить больше, чем сам продукт, расходы продолжают расти или никто не доверяет бэкапам и деплоям. Короткий архитектурный разбор может убрать дубли, сократить расходы и упростить работу одному владельцу.


