Аудит доступа к боевым данным во время работы поддержки
Узнайте, как аудировать доступ к боевым данным при расследованиях поддержки — что фиксировать: причину, просмотренные записи, время начала и окончания, и кто одобрил доступ.
Содержание
Почему доступ поддержки должен иметь четкий след
Запрос в службу поддержки может выглядеть рутинным, пока кто‑то не откроет живой аккаунт. Клиент пишет, что заказ исчез, счёт выставлен неверно или файл не загружается. Чтобы проверить проблему, агент поддержки или инженер может открыть продакшен‑записи, прочитать заметки или просмотреть недавнюю активность.
Это происходит в обычной работе, а не только при крупных инцидентах. Один человек проверяет запись по выставлению счета, другой открывает профиль пользователя, а третий сверяет историю сообщений с системными метками времени. За несколько минут несколько людей могут коснуться приватных данных.
Если никто не записывает эти действия правильно, у компании остаётся не история, а расплывчатое воспоминание. Тикет есть, но никто не может точно сказать, кто открыл какие данные, зачем ему это было нужно и как долго он находился в аккаунте. Эта дыра быстро создаёт проблемы.
Заметки в чате это не исправляют. Сообщение вроде «я проверил аккаунт» почти ничего не говорит. Память ещё хуже. Люди забывают, какой экран, таблицу или файл они открывали, и редко помнят, длился ли доступ 30 секунд или 20 минут.
Риски просты. Проблемы с приватностью растут, когда люди смотрят больше, чем требует тикет. Доверие клиента падает, если компания не может ясно объяснить расследование. Споры затягиваются, потому что у менеджеров догадки вместо фактов.
Чёткая запись защищает клиентов и сотрудников одновременно. Если клиент спрашивает: «Зачем кто‑то открыл мои данные?», компания должна указать на одну запись, которая показывает причину, номер тикета, имя человека, что он увидел и когда доступ закончился.
Именно поэтому важны логи доступа к продакшену. Они превращают расплывчатое пересказ в нечто осязаемое. Они показывают, что доступ был нужен для конкретной поддержки, а не ради привычки или любопытства.
Простой тест работает хорошо: спросите, может ли ваша команда ответить на один вопрос в одном месте — кто открыл этот аккаунт и зачем? Если ответ разбросан по тикетам, чатам, памяти и системным логам, процесс слишком свободный.
Что фиксировать каждый раз
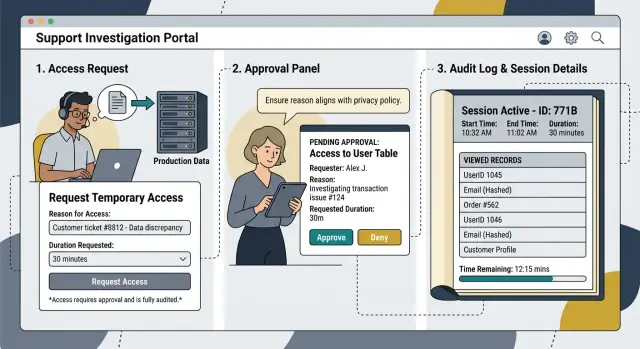
Если кто‑то открывает живые данные клиента в рамках дела поддержки, лог должен позволить другому человеку восстановить сессию без догадок.
Начните с идентификации и одобрения. Зафиксируйте имя или учётную запись того, кто открыл данные, и имя лица, кто одобрил доступ. Если инженер вынужден действовать при срочном инциденте, отметьте это явно и назначьте последующую проверку.
Добавьте номер тикета, дела или инцидента в ту же запись. Заметка в другой системе недостаточна. Когда позже менеджер, аудитор или клиент задаст вопросы, никому не придётся рыться в пяти инструментах, чтобы сложить картину.
Причина доступа должна уложиться в одно простое предложение. Будьте конкретны. «Проверка жалобы на дублирующее выставление счета для клиента 1842 после того, как поддержка не смогла подтвердить источник в staging» — полезно. «Требуется отладка» — нет.
Затем запишите, что именно просмотрел человек. «Данные клиента» слишком широко. Пропишите записи, поля, файлы или экраны, которые открывали: одна запись заказа, два PDF‑счёта, поле email, последние четыре цифры токена карты или экран настроек аккаунта.
Время так же важно, как и объём. Сохраните время начала, время окончания и общую длину сессии. Если тот же человек открыл продакшен дважды по одному делу, логируйте обе сессии отдельно, а не объединяйте в один блок.
Хорошая запись отвечает на пять вопросов: кто открыл данные, кто одобрил доступ, какому делу это принадлежало, что именно они посмотрели и сколько длился доступ. Это звучит базово, но отсутствие хотя бы одного пункта часто ломает след позже.
Установите правила прежде, чем кто‑то откроет продакшен
Работа поддержки становится запутанной, когда люди решают правила доступа прямо во время инцидента. Определите правила заранее, держите их короткими и требуйте от всех одинакового пути.
Только именованные люди должны взаимодействовать с живыми данными. Общие админ‑учётки разрушают подотчётность, а широкий командный доступ превращает простой тикет в поле для догадок. Если доступ открыл один человек, все должны знать, кто это был, почему у него было право и кто это одобрил.
Доступ должен начинаться с тикета, даже если проблема кажется небольшой. Тикет даёт причину, влияние на клиента, временное окно и ожидаемую задачу. Если кто‑то не может описать проблему достаточно, чтобы открыть тикет, ему, вероятно, не стоит открывать продакшен.
Временные ограничения тоже важны. Давайте каждой сессии автоматическое истечение, например 30 минут или 2 часа, в зависимости от задачи. Не полагайтесь на людей, чтобы они вспомнили закрыть доступ позже. Система должна сделать это за них.
Во многих случаях живые данные вообще не нужны. Замаскированная запись, недавний снимок или копия для поддержки часто дают достаточно деталей для отладки без раскрытия имён, email или платежных данных. Команды, которые пропускают этот шаг, начинают считать продакшен по умолчанию, а это обычно просто небрежно.
Внерабочее время требует отдельного правила. Выберите одного человека или небольшую ротирующуюся группу, которая может одобрять срочный доступ ночью или в выходные. Укажите это в политике, чтобы никто не тратил время на бессмысленные запросы, когда клиент заблокирован.
Представьте жалобу по биллингу в 23:40. Дежурный инженер открывает тикет, получает одобрение у назначенного согласующего, получает сессию на час, сначала проверяет замаскированную запись и только потом открывает живой аккаунт. Это занимает лишнюю минуту, но избегает обычного «кто смотрел это?» утром.
Лучший путь по умолчанию строг и скучен: только именованные аккаунты, тикет до начала доступа, автоматическое истечение, сначала замаскированные данные и один явный согласующий для срочных случаев. Скучные правила проще соблюдать.
Как должно проходить расследование поддержки
Хорошее расследование начинается до того, как кто‑то прикоснётся к продакшену. Начните с отчёта клиента, истории тикета, логов приложения, трассировок ошибок и недавних релизов. Во многих случаях этого достаточно, чтобы найти проблему без открытия живых записей.
Если доступ к продакшену всё же нужен, исследователь должен создать запрос, привязанный к тикету поддержки. В запросе нужно объяснить, зачем нужен доступ, какой клиент или аккаунт в зоне поиска, какие системы планируют проверить и сколько должна длиться сессия. «Отладка» или «проверка данных» — слишком расплывчато.
Одобрение должно происходить до начала сессии. Держите это просто: один именованный согласующий, ясное время начала и время истечения. Доступ только для чтения должен быть по умолчанию. Если нужен больший объём прав, указывайте это в запросе, а не решайте на ходу.
Во время сессии след investigatory trail — оставляйте след, по которому другой член команды сможет пройти позже. Именно это делает логирование расследований полезным на практике.
Полезная запись включает ID тикета или инцидента, точную причину доступа, когда доступ начался и закончился, какие записи, таблицы, файлы или экраны открывали и что узнали или изменили. Полезно также отметить, если ничего не меняли.
Конкретные заметки отличают полезную запись от шума. «Просмотрел профиль клиента, статус биллинга и последние три неудачные API‑вызова» — полезно. «Проверил продакшен» — нет. Если человек выполнял запросы, запишите имя запроса или цель. Если он смотрел одну запись клиента — укажите её.
Когда расследование завершено, закройте доступ сразу. Отозовите токен, завершите сессию и подтвердите, что временное право удалено. Затем добавьте итоговые заметки в тикет: что вызвало проблему, были ли данные клиента раскрыты за пределы одобренного объёма и какие последующие работы нужны команде.
Это звучит строго, но экономит время позже. Когда клиент спросит, кто открывал его данные прошлым вторником, вашей команде не придётся гадать.
Реалистичный пример из тикета поддержки
Клиент пишет: «Мой возврат помечен как выполненный, но деньги не дошли до карты». Агент поддержки не может ответить из обычного админ‑экрана, потому что там только «refund sent». Они запрашивают временный доступ только для чтения к одной продакшен‑записи, связанной с тикетом #48271.
Перед открытием доступа команда создаёт запись в логе с ID тикета, ID клиента, именем агента, согласующим, временем начала и причиной доступа: проверить, вернул ли платёжный шлюз ошибку после запуска задачи возврата. Эта причина имеет значение. «Нужно проверить аккаунт» слишком расплывчато.
Агент открывает одну запись возврата и связанное событие платежа. Он не просматривает других клиентов, недавние возвраты или всю историю платежей. Объём остаётся узким: один ID возврата, один ID клиента, одно временное окно.
Запись о том, что просматривалось, должна быть конкретной:
- refund_status, чтобы подтвердить, что приложение пометило возврат как отправленный
- gateway_response_code, чтобы увидеть, отклонил ли банк операцию
- gateway_response_message, чтобы прочитать точную причину отказа
- updated_at, чтобы сопоставить время с тикетом
- account_status, чтобы исключить холд, который заблокировал выплату
Если система хранит полные номера карт, налоговые данные или приватные заметки, агент не должен их открывать. Они не помогают в данном случае и остаются вне области просмотра.
В 10:14 начинается сессия. В 10:18 агент находит ответ: шлюз вернул код decline, потому что первоначальная транзакция была вне окна возврата. Агент сразу закрывает доступ. Надёжный аудиторский след показывает оба времени, так что длина сессии ясна: четыре минуты.
Итоговая заметка для команды по работе с клиентом может быть короткой и понятной: «Проверили запись возврата по тикету #48271. Запрос на возврат покинул нашу систему, но платёжный провайдер отклонил его с кодом отказа 54. Другие записи клиента не просматривались. Доступ закрыт в 10:18. Пожалуйста, предложите ручной путь возврата средств.»
Так вы аудитируете доступ к продакшен‑данным, не превращая простую задачу поддержки в широкое необозначенное просмотрение.
Сделайте логирование трудным для пропуска
Если логирование зависит от памяти, люди забывают его, когда клиент ждёт и давление растёт. Более защищённая настройка записывает большую часть следа автоматически, ещё до того, как сотрудник увидит живые данные.
Начните с идентичности. Не разрешайте сотрудникам делиться одной поддерживающей админ‑учёткой. Используйте SSO или именованные админ‑аккаунты, чтобы каждая сессия привязывалась к одному человеку, одному времени и одному пути одобрения. Если подрядчик помогает неделю, дайте отдельную учётную запись и удалите её по окончании работы.
Сессия должна запрашивать номер тикета сразу. Ещё лучше — вытягивать его из инструмента поддержки и автоматически ставить на запрос доступа, сессию и каждую аудиторскую запись, созданную в этом окне. Когда кто‑то позже смотрит событие, он должен видеть причину доступа без открытия нескольких систем.
Запись входа недостаточна. Нужно фиксировать, что именно человек открывал: страницы клиента, ID аккаунтов, типы записей, экспортированные файлы и имена запросов. Если команда использует сохранённые запросы, логируйте имя запроса и размер результата. Если кто‑то искал по тысячам записей, это должно выделяться.
Храните логи в месте, где персонал поддержки не может их менять. Отправляйте их в отдельное хранилище аудита с жёсткими правилами записи, ограниченным доступом админов и оповещениями в попытке изменить ретеншен. Если одна и та же команда может смотреть данные клиентов и править доказательства этого доступа, контроль теряет смысл.
Два триггера проверки ловят много плохого поведения и простых ошибок. Флагируйте сессии, которые намного длиннее нормы, и флагируйте поиски, которые затрагивают намного больше записей, чем требует тикет. 12‑минутная сессия для проверки одной записи биллинга выглядит нормально. 90‑минутная сессия с повторяющимися широкими поисками заслуживает более пристального рассмотрения.
Лучшее логирование по началу кажется немного раздражающим. Это нормально. Небольшая преграда в начале экономит часы выяснений позже.
Частые ошибки, которые скрывают, кто что сделал
Худшие дыры обычно происходят из привычек, которые кажутся нормальными внутри занятой команды поддержки. Они экономят несколько минут в моменте, а потом превращают простую проверку в гадание.
Общие админ‑учётки наносят самый большой урон. Если три человека используют один вход, ваши записи могут показать, что доступ был, но не кто именно его осуществил. У каждого должен быть свой аккаунт и своё временное одобрение.
Постоянный доступ создаёт следующую проблему. Команды часто оставляют широкие права, потому что просить каждый раз кажется медленно. В результате история путается и контроль слабеет. Когда любой может открыть живые данные в любое время, никто не сможет объяснить, почему доступ был во вторник в 16:12 вместо одобренной задачи поддержки.
Что логи часто пропускают
Многие системы логируют только начало сессии и на этом останавливаются. Этого недостаточно. Полезная запись должна ответить на простые вопросы: зачем человек открыл продакшен, какого клиента или экран он смотрел, только читал или изменял данные, когда начался и закончился доступ и какой тикет одобрил работу?
Команды также пропускают причину доступа, рассчитывая заполнить её позже. Позже редко происходит. Тикет может содержать «срочно» и ничего больше. Это почти не помогает при разборе, особенно если дело включает персональные или финансовые данные.
Ещё одна частая ошибка проявляется в конце расследования. Тикет закрывают, все переходят к другим задачам, а повышенный доступ остаётся открытым днями или неделями. Этот оставшийся доступ потом используется для посторонней работы и снова ломает след.
Одно простое правило исправляет многое: не закрывайте тикет, пока не закрыт и доступ. Свяжите эти шаги в одном рабочем процессе. Если у вас ручные одобрения, назначьте одного человека, который подтверждает оба действия.
Если вашей компании нужен более строгий доступ команды поддержки без громоздких процедур, держите исправление простым. Короткий запрос на доступ, именованные учётные записи и автоматическое истечение обычно работают лучше толстых политик, которые никто не читает.
Короткий чеклист для вашего процесса
Дело поддержки может идти быстро, особенно когда клиент ждёт. Именно тогда команды пропускают учёт, который важен позже. Если вы хотите процесс, который выдержит давление, держите чеклист коротким и строгим.
- Зафиксируйте причину простым языком. Опишите проблему клиента, симптом и зачем нужен доступ к продакшену. «Проверка неудачного возврата после жалобы клиента на дублирующий платёж» — ясно. «Обзор поддержки» — бесполезно.
- Привяжите событие к реальному тикету. Используйте точный ID дела или инцидента, чтобы любой мог проследить доступ до отчёта клиента, бага или простоя.
- Отметьте, что именно просматривал пользователь. Назовите таблицы, записи, экраны или области аккаунта. Если искали по email, ID заказа или номеру счёта — тоже логируйте.
- Зафиксируйте временное окно. Сохраните, когда доступ начался и когда закончился. Если доступ был открыт 47 минут, лог должен это показать, а не только дату.
- Проверяйте необычный доступ по расписанию. Менеджер должен проверять дела с широкими поисками, повторяющимися запросами, доступом вне часов работы или доступом без соответствующего тикета. Для небольшой команды обычно достаточно еженедельной проверки.
Это лучше всего работает, когда чеклист находится внутри потока поддержки, а не в отдельном документе, который забывают. Поместите поля в форму тикета, запрос доступа или инструмент, который выдаёт временные права. Если в форме не указан тикет или причина, доступ не должен открываться.
Логи доступа к продакшену не обязаны быть красивыми. Они должны быть полными. Даже у скромной команды должен быть след, который отвечает на пять базовых вопросов: зачем кто‑то открыл данные, какой тикет это позволил, что они увидели, когда это началось и кто позже проверял странные случаи.
Что делать дальше
Начните с одного реального пути поддержки, а не с политики на самых верхах. Выберите тип тикета, где сейчас кто‑то уже открывает продакшен — например, неудачные платежи, блокировки аккаунтов или пропавшие записи. Пропишите каждый шаг: кто запрашивает доступ, кто его одобряет, какие данные открывают, где смотрят и когда доступ должен закончиться.
Эта маленькая карта обычно быстро выявляет слабые места. Команды часто находят общие админ‑учётки, доступы без истечения или логи, которые фиксируют только вход, но не причину.
Потом выберите самые небольшие правила, которые вы можете ввести в этом месяце. Требуйте номера тикета перед тем, как открыть продакшен. Записывайте причину доступа, согласующего и время начала и конца. Отмечайте, что просмотрели или изменили достаточно подробно для последующего разбора. Уберите широкие продакшен‑роли у сотрудников поддержки, которым они больше не нужны. Каждую неделю проверяйте выборку таких логов и сразу исправляйте пробелы.
Этого достаточно, чтобы процесс стал реальным. Вам не нужен огромный проект сначала. Короткая форма, временная роль и еженедельная проверка лучше отточенного плана, который никто не выполняет.
Будьте строги с открытым доступом без срока. Если сотруднику поддержки нужны повышенные права для живой проблемы, дайте им временный доступ и позвольте ему истечь. Постоянный доступ «на всякий случай» — откуда начинаются большинство плохих привычек.
Если команда растёт и процесс всё ещё запутан, внешний аудит поможет. Oleg Sotnikov на oleg.is работает как Fractional CTO и советник стартапов — это тот тип операционной уборки, с которым он часто помогает.
Практический шаг на эту неделю прост: выберите один тип тикета поддержки, прогоните его через текущий процесс и проверьте, можете ли вы ответить на три вопроса — зачем кто‑то открыл данные, что они увидели и сколько длился доступ. Если не можете ответить на все три, сначала исправьте этот путь.
Часто задаваемые вопросы
Почему заметки в тикете недостаточны?
Запись в тикете обычно слишком короткая. Если кто‑то пишет «проверил аккаунт», вы по‑прежнему не знаете, кто одобрил доступ, какую запись открыли или когда доступ закончился.
Реальный лог должен привязывать сессию к одному тикету и показывать причину, объём и временное окно в одном месте.
Что должно включать каждый лог доступа к продакшену?
Записывайте, кто открыл данные, кто одобрил, ID тикета или инцидента, причину доступа, что именно просмотрели и когда сессия началась и закончилась.
Если человек открывал продакшен дважды по одному делу, логируйте обе сессии отдельно. Это сильно упрощает последующий разбор.
Должны ли агенты поддержки иметь постоянный доступ к продакшену?
Нет. Постоянный доступ превращает продакшен в значение по умолчанию и делает проверки запутанными.
Даёте именованным сотрудникам временный доступ для конкретного случая, пусть он истекает автоматически, и делайте чтение (read‑only) нормой.
Можно ли открывать продакшен до одобрения в экстренном случае?
Только для действительно срочной работы, и даже тогда нужно документировать это сразу. Человек, открывший продакшен без ожидания одобрения, должен записать, почему нельзя было ждать, и кто позже проверил это решение.
Так процесс продолжает работать, но сохраняется ответственность.
Сколько должен длиться временный доступ?
Коротко. Для многих кейсов 30 минут — 2 часа подходит.
Выберите значение по умолчанию, подходящее вашей работе, и пусть система закрывает доступ автоматически. Не полагайтесь на память сотрудников.
Всегда ли нам нужны живые данные клиента для расследования тикета?
Используйте замаскированные данные, снимки (snapshots), логи и копии для поддержки в первую очередь. Многие проблемы можно решить без живых данных клиента.
Если эти источники дают ответ, останавливайтесь на них. Продакшен должен быть крайней мерой.
Насколько подробно нужно описывать, что было просмотрено?
Достаточно подробно, чтобы коллега мог представить сессию без догадок. «Просмотрел одну запись возврата, одно событие платежа и поле статуса аккаунта» — работает. «Проверил данные клиента» — не годится.
Если человек выполнил запрос, логируйте имя запроса или цель и какие записи/файлы затронуты.
Как обнаружить небрежный или подозрительный доступ?
Фильтруйте сессии, которые намного длиннее обычного, происходят вне рабочего времени или затрагивают намного больше записей, чем требует тикет.
Также отмечайте доступ без соответствующего тикета, широкие поиски по многим аккаунтам и случаи, где поле причины остается расплывчатым.
Какие ошибки обычно ломают аудиторскую цепочку?
Общие админ‑учётки ломают идентификацию в первую очередь. Широкие постоянные права, расплывчатые причины вроде «требуется отладка» и логи, которые фиксируют только время входа без просмотренных записей, — следующие по частоте.
Ещё одна ошибка: тикет закрывают, а повышенные права остаются открытыми и потом используются для посторонних задач.
Как быстрее всего улучшить процесс на этой неделе?
Начните с одного типа тикета, который уже приводит людей в продакшен — например, неудачные возвраты или блокировки аккаунтов. Добавьте обязательный ID тикета, короткое поле с причиной, именованные аккаунты и автоматическое истечение.
Потом каждую неделю проверяйте небольшую выборку. Если процесс всё ещё запутан, Oleg Sotnikov может помочь упорядочить его как Fractional CTO.


