API-шлюз против реверс-прокси для небольшой продуктовой команды
Выбор между API-шлюзом и реверс-прокси может показаться мелочью, но влияет на аутентификацию, лимиты, задержки, стоимость и повседневную работу команды.
Содержание
Какую проблему вы на самом деле решаете
Многие команды добавляют новые сетевые инструменты, потому что система кажется запутанной. Это чувство реальное, но само по себе недостаточно, чтобы оправдать ещё один уровень. Если запросы уже доходят до приложения, новый прокси или шлюз помогают только тогда, когда он решает конкретную, названную вами боль.
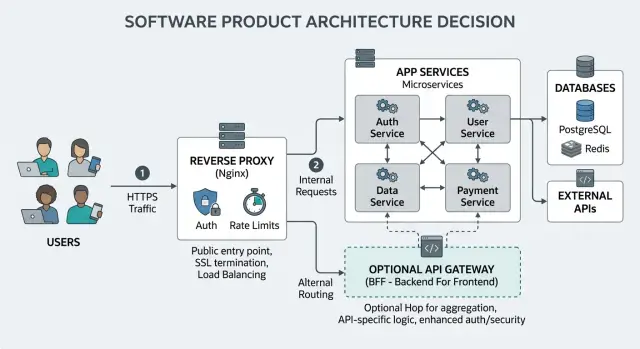
Вопрос «API-шлюз или реверс-прокси» становится проще, если разделить проблемы на те, что на входе, и те, что внутри приложения. Проблемы на входе — это то, что происходит у «двери»: завершение TLS, маршрутизация по хостам и путям, базовая фильтрация запросов и простые лимиты. Проблемы приложения — глубже: слабые роли пользователей, запутанные границы сервисов, медленные обработчики, непоследовательные API и отсутствие правил аудита. Новый хоп не исправит плохой дизайн приложения.
Аутентификация часто решает выбор. Если нужно только передать токены в одно приложение и проверять сессии там же, достаточно простого реверс-прокси. Если нужно единое место для применения API-ключей, правил для арендаторов и лимитов для нескольких сервисов, аргументы в пользу шлюза сильнее. То же самое по контролю злоупотреблений: если боты атакуют один endpoint для логина, вам может понадобиться более точная логика внутри приложения и сфокусированный лимит там, а не крупный разворот шлюза.
Задайте четыре прямых вопроса перед установкой любого инструмента:
- Где сегодня проявляется боль: в маршрутизации, аутентификации, логах или злоупотреблениях?
- Где должно лежать исправление — на входе или внутри приложения?
- Устранит ли одна общая политика повторную работу между сервисами?
- Кто будет владеть изменениями конфигурации, тревогами и странным трафиком каждую неделю?
Последний вопрос слишком часто пропускают. Инструменты кажутся дешёвыми в день запуска. Они стоят времени позже, когда заголовки ломаются, лимиты блокируют реальных пользователей или одно плохое правило вызывает ночной инцидент.
Малой команде с одним продуктом и двумя сервисами обычно важнее ясность, чем новая инфраструктура. Запишите точный отказ, который вы хотите остановить. Если ответ расплывчат, ждите. Если ответ — «нам нужен централизованный контроль аутентификации и лимитов для нескольких сервисов», тогда у вас есть реальная причина добавить больше, чем реверс-прокси.
Что уже покрывает реверс-прокси
Много дискуссий об API-шлюзе против реверс-прокси начинается после того, как команда уже имеет рабочий вход. Этот вход часто делает больше, чем ему приписывают. Для маленького продукта простой реверс-прокси может аккуратно справляться с первым слоем трафика, не добавляя ещё один сервис для работы.
Обычно всё начинается с TLS. Прокси принимает HTTPS-трафик, держит управление сертификатами в одном месте и пересылает запросы приложению или API за ним. Это значит, что бэкенд-сервисам не нужно всем беспокоиться о сертификатах, публичном доступе или прямом интернете.
Маршрутизация тоже менее драматична, чем многие ожидают. Если у продукта есть пути вроде /api, /admin и /app, реверс-прокси может направлять каждый из них к нужному сервису парой ясных правил. Можно разделять трафик по имени хоста, пути или порту и держать публичную точку входа понятной.
На входе также можно задать скучные правила, которые экономят время позже. Реверс-прокси может добавлять или передавать заголовки, ограничивать размер запроса, устанавливать разумные таймауты и блокировать очевидно плохой трафик по IP или диапазону сетей. Это не заменит полноценную аутентификацию шлюза или детальное управление политиками, но покрывает многие повседневные нужды.
Логи важнее, чем большинство команд думает. Когда запросы сначала заходят через один прокси, у вас есть одно место для проверки кодов статуса, задержек, путей запросов и IP клиентов. Это ускоряет первичную отладку. Если запрос на вход не проходит, вы часто можете за минуту-две понять, началась ли проблема на входе, в приложении или между сервисами.
Поэтому экономные настройки часто дольше остаются с nginx или похожим прокси. Для маленьких команд держать управление трафиком близко к точке входа часто достаточно. Вы получаете обработку TLS, маршрутизацию путей, контроль заголовков, базовую фильтрацию и полезные логи без ещё одного хопа, ещё одного уровня конфигурации и ещё одной вещи, которая может разбудить кого‑то в 2:00 ночи.
Что даёт API-шлюз
API-шлюз начинает оправдывать себя, когда у продукта несколько сервисов, которые должны вести себя как единая система. Вместо копирования одинаковых правил доступа, лимитов и проверок запросов в каждый сервис, вы помещаете эти правила в одно место. Это делает поведение более согласованным и сокращает число мелких расхождений, которые позже превращаются в запросы в поддержку.
Аутентификация обычно первое место, где это важно. Простой реверс-прокси может просто переадресовывать запросы, а шлюз может сам выполнять часть пропускного контроля. Он может выдавать API-ключи, проверять их для каждого запроса, отбрасывать плохих клиентов на входе и прикреплять идентификацию клиента до того, как запрос попадёт в приложение. Если у вас есть клиенты, внутренние инструменты и внешние партнёры, которые обращаются к разным сервисам, централизованный контроль экономит реальное время.
Квоты — ещё один крупный шаг. Реверс-прокси обычно справится с простыми лимитами, например по IP. Шлюз может применять лимиты по аккаунту клиента, партнёру или тарифному плану одновременно к нескольким сервисам. Это важно, когда один клиент должен получать 100 запросов в минуту, другой — 1 000, и оба используют одну и ту же поверхность API. Вы избегаете постоянного дублирования логики биллинга и учёта использования.
Шлюз также помогает, когда API нужно держать стабильным, а бэкенд меняется. Допустим, старое мобильное приложение всё ещё вызывает старый формат endpoint, а команда уже разбила бэкенд на новые сервисы. Шлюз может трансформировать запрос, переписывать заголовки или пути и маршрутизировать трафик туда, куда нужно. Старые клиенты продолжают работать, пока команда обновляет продукт в спокойном темпе.
Это та часть выбора API-шлюз vs реверс-прокси, которая часто важнее всего: шлюз — это не просто ещё один хоп трафика. Это центральное место для политик, идентичности, квот и работы совместимости. Если эти проблемы реальны в вашем продукте, дополнительный слой окупает себя.
Как аутентификация и лимиты влияют на выбор
Аутентификация и лимиты часто решают вопрос быстрее любого списка функций. Если обе задачи просты, реверс-прокси обычно достаточен. Как только правила начинают различаться по клиентам, тарифам или сервисам, приложение часто должно оставаться главным источником правды.
Вход пользователей — хороший пример. Если команда постоянно меняет шаги регистрации, правила сессий, passwordless-вход или приглашения в команду, держите эту логику близко к приложению. Прокси всё ещё может передавать заголовки или блокировать очевидно плохой трафик, но поток должен контролироваться приложением. Так продуктовые изменения остаются в одном месте, а не раздрӧблены между приложением и ещё одним слоем.
Проверки общих API-ключей — другое дело. Если многие сервисы принимают одинаковые машинные запросы, проверка ключей на входе может сэкономить время и сократить дублирование кода. Шлюз может отбрасывать плохие ключи до того, как трафик дойдёт до внутренних сервисов. Это важнее, когда у вас публичный API, фоновые задания и несколько внутренних инструментов, обращающихся к одному бэкенду.
Лимиты запросов тоже делятся на две разные задачи. Одна — грубый контроль злоупотреблений у двери. Реверс-прокси с этим справится: слишком много запросов с одного IP, слишком много попыток входа, слишком много обращений к тяжёлому endpoint за несколько секунд. Эти правила просты и быстры.
Другая — бизнес-логика. Если один план получает 1 000 запросов в день, другой — 100 000, а у корпоративных клиентов свои правила, держите это в коде приложения. Биллинг, триалы, льготные периоды и правила перерасхода меняются. Команда будет ненавидеть обновлять это в конфиге шлюза каждую неделю.
Простое правило работает хорошо:
- Ставьте широкую блокировку на входе
- Сохраняйте изменяющиеся продуктовые правила в приложении
- Деляйтесь только теми проверками, которые действительно переиспользуют многие сервисы
- Логируйте каждое отклонение с понятной для клиента причиной
Последний пункт важнее, чем команды ожидают. Кто‑то должен просматривать заблокированные запросы, прежде чем тикеты в поддержку накапают. Решите, кто будет владеть этой очередью: инженеринг, поддержка или оба. Если никто не проверяет ложные срабатывания, лимиты и правила аутентификации быстро превратятся в боль для клиентов.
Для малого SaaS- продукта обычное разделение скучно, но эффективно: прокси для базовой защиты от злоупотреблений, приложение — для входа и правил тарифов. Скучно — это хорошо, когда у команды три человека и слишком много задач по доставке.
Стоимость команды при добавлении ещё одного хопа
Дополнительный хоп добавляет не только несколько миллисекунд. Он добавляет ещё один уровень конфигурации, ещё одно место, где заголовки могут измениться, и ещё одно место, где запрос может упасть до того, как приложение его увидит.
Эта стоимость проявляется быстро, когда что‑то ломается. 401 может исходить от реверс-прокси, API-шлюза или приложения. 429 может означать, что один лимит сработал на входе, а другой — глубже внутри. Исправление часто простое, но найти правильное место для исправления — нет.
Нагрузка на дежурство растёт тоже. Вместо проверки одного access-лога и лога приложения команда теперь смотрит логи прокси, логи шлюза, логи приложения и часто отдельную панель для политик или плагинов. В 2:00 ночи этот дополнительный путь поиска важен.
Новые члены команды ощущают это сильнее. С простым реверс-прокси они обычно могут проследить запрос за один присест. Добавьте шлюз — и им придётся понять, где завершается TLS, какой слой переписывает пути, где добавляются заголовки аутентификации и какой сервис возвращает финальный код ответа.
Ранние признаки проблем обычно таковы:
- Прокси и шлюз оба обрабатывают редиректы или CORS
- Лимиты живут в двух местах с разными цифрами
- Один слой проверяет аутентификацию, а другой всё ещё содержит старые правила allow
- Переписывания маршрутов различаются между окружениями
- Никто не уверен, какая конфигурация — источник правды
Дрейф — реальный налог. Команды начинают с чётких границ, потом накапливаются мелкие исключения. Кто‑то добавляет allowlist в прокси, потому что так быстрее. Кто‑то ещё добавляет то же правило в шлюз, потому что ожидает найти его там. Через шесть недель оба слоя выполняют по половине работы.
Управляемый продукт может добавить ещё один вид нагрузки. Он часто хочет, чтобы команда работала внутри его модели маршрутов, плагинов, идентичностей и лимитов. Это может быть нормально, если вам нужны эти функции каждый день. Для маленькой команды это также может значить дополнительное обучение, более медленную отладку и ещё одну вендорную коробку вокруг обычного HTTP-трафика.
В выборе API-шлюз против реверс-прокси легко прозевать: дополнительный хоп должен убрать достаточно работы, чтобы окупить себя. Если этого не происходит, команда получает больше движущихся частей без реальной выгоды.
Простой способ принять решение
Для большинства команд самое чистое решение исходит из текущего трафика, текущих правил и доступного времени команды. Игнорируйте версию продукта, которая может быть через год. Запишите, какие вызовы идут в вашу систему сегодня.
Этот список обычно короче, чем люди думают. Это может быть веб‑приложение, мобильное приложение, пара внутренних админ-инструментов и одно‑два вебхука от внешних сервисов. Если это ваша реальная картина трафика, не нужно проектировать систему под десять типов клиентов, когда у вас всего четыре.
Далее запишите правила аутентификации на одной странице простым языком. Без политики. Пишите предложения вроде «клиенты входят по сессиям», «внутренние инструменты доступны только из офисного VPN», или «вебхуки партнёров требуют подписанный секрет». Если вы не можете просто объяснить правила аутентификации, добавление шлюза не исправит путаницу.
Лимиты тоже требуют честности. Посчитайте типы лимитов, которые вам реально нужны сейчас, а не те, что красиво выглядят на диаграммах. Многие маленькие продукты нуждаются в нескольких базовых:
- лимит по IP для публичных эндпоинтов
- лимит по пользователю для дорогих действий
- более строгий лимит для попыток входа
- отдельное правило для трафика партнёров или вебхуков
Если ваш реверс-прокси может применять эти правила без уродливых костылей, оставляйте его. Простой реверс-прокси плюс проверки на уровне приложения часто покрывают больше, чем люди думают. К тому же это проще отлаживать в 2:00 ночи, когда один путь запроса начинает падать.
Добавляйте шлюз, когда столкнётесь с настоящей стеной. Эта стена обычно выглядит так: многие сервисы нуждаются в одинаковой логике аутентификации, лимиты отличаются по тарифам клиента, внешние партнёры требуют отдельные политики, или команда постоянно заново строит одни и те же контролы в разных местах. Тогда дополнительный хоп окупает себя.
До этого момента выбирайте меньшую систему. Меньше движущихся частей — меньше сюрпризов, меньше дрейфа конфигурации и меньше времени на объяснение вашего слоя на входе каждому новому инженеру.
Реалистичный пример для маленького продукта
Представьте маленькую SaaS-команду с одним веб‑приложением, мобильным приложением и двумя бэкенд-сервисами. Один сервис обслуживает продукт, другой — задачи поддержки: события биллинга, экспорты или фоновые задания. У команды один поток логина, один клиентский API и мало людей для управления инфраструктурой.
На этом этапе реверс-прокси часто достаточен. Он может завершать TLS, маршрутизировать трафик к нужному сервису и блокировать очевидные злоупотребления базовым лимитом. Если веб‑приложение, мобильное приложение и публичный API используют одинаковые правила аутентификации, настройка остаётся понятной.
Обычная схема: реверс-прокси спереди, /api уходит в основной бэкенд, админ‑маршруты — во второй сервис, а проверка личности пользователя делегируется приложению. Это скучно, но хорошо. Меньше движущихся частей обычно значит меньше ночных сюрпризов.
Здесь же многие команды начинают переусердствовать. Они добавляют API-шлюз, потому что это звучит как «правильная» архитектура, но у них всего один публичный API и одна группа пользователей. Теперь каждый запрос делает ещё один хоп, каждое изменение конфига живёт в ещё одном месте, а отладка замедляется, потому что команде приходится смотреть логи прокси, правила шлюза и логи приложения.
Картина меняется, когда появляются внешние партнёры. Публичный клиентский API — одно. Десять партнёров с отдельными API-ключами, разными квотами и разными правилами доступа — совсем другое. Тогда команде могут понадобиться лимиты по партнёрам, лучше аналитика и аккуратный способ отзывать или вращать креденшелы без правки кода приложения каждый раз.
В этот момент API-шлюз начинает иметь смысл. Шлюз может владеть ключами партнёров и квотами, в то время как реверс-прокси по‑прежнему обрабатывает базовый входной трафик. На первом дне команда этого слоя не требовала — он нужен, когда меняется бизнес-модель.
Oleg часто работает с компаниями, которые хотят снизить облачные расходы и сократить операционный оверхед. Это та же идея в меньшем масштабе: сокращайте путь, пока настоящая потребность не заставит добавить контроль. Когда партнёры требуют отдельных правил — добавляйте шлюз. До этого реверс-прокси справится отлично.
Ошибки, которые добавляют работы
Большая часть лишней работы начинается с выбора инструмента, который решает будущую проблему, а не текущую. Шлюз звучит как более полноценный вариант, поэтому команды покупают его раньше времени и чувствуют себя безопаснее. Потом они получают больше конфигураций, больше логов, ещё один шаг деплоя и ещё одно место, где запрос может упасть.
Для маленького продукта это быстро проявляется. Если один сервис обрабатывает большую часть трафика и ваш реверс-прокси уже делает TLS, маршрутизацию и базовую защиту, шлюз может добавить больше движущихся частей, чем реальной пользы.
Аутентификация становится грязной, когда команды разбрасывают её по слоям. Прокси проверяет токен, шлюз добавляет утверждения, а приложение всё ещё хранит собственные правила прав. Через пару месяцев никто не может ответить на простой вопрос: какой слой решает, кто что может делать?
Выберите один источник правды и держите его скучным. Если приложение владеет правами, пусть входной слой передаёт доверенные данные о личности и остаётся тонким. Если входной слой отвергает плохие токены, сделайте это правило ясным и задокументированным.
Лимиты причиняют ту же путаницу. Команды часто копируют дефолт вроде 100 запросов в минуту, не зная своего трафика. Это может блокировать нормальных пользователей при запуске продукта, в то время как плохой трафик всё ещё проскальзывает по менее защищённым маршрутам.
Реальные паттерны трафика важнее аккуратных чисел. Логин, сброс пароля и публичный поиск часто требуют разных лимитов. Начинайте после просмотра логов, а не до.
Переписывания запросов — ещё одна ловушка. Правило переписывания может временно починить сломанный путь или заголовок и сделать вид, что приложение работает нормально. Но баг остаётся в приложении, и позже никто не помнит, зачем прокси несёт странное правило, которое нужно только одному endpoint.
Чиниьте приложение, когда это возможно. Держите переписывания для стабильных публичных URL, миграций или поддержки старых клиентов.
Изменения на входе также требуют плана отката. Одно плохое правило может в считанные секунды заблокировать все запросы. Сохраняйте версии конфигурации, держите последнюю рабочую копию и тестируйте изменения сначала на узком маршруте.
Маленькая команда обычно выигрывает от меньшего числа слоёв, ясной ответственности и правил, которые можно объяснить без трёх панелей мониторинга.
Быстрые проверки перед окончательным решением
Большинство малых команд застревает не потому, что прокси или шлюзу не хватает фич, а потому, что никто не может объяснить путь запроса, когда что‑то ломается. Если один человек не может описать весь поток за 30 секунд, настройка уже сложнее, чем должна быть.
Этот тест звучит почти смешно, но он работает. Ясный путь значит более быструю отладку, меньше передач эстафеты и меньше догадок в 2:00 ночи. Когда спорят об API-шлюзе vs реверс-прокси, это часто важнее списка функций.
- Попросите одного коллегу объяснить обычный запрос от публичного края до приложения, включая где выполняется аутентификация и куда попадают логи. Если им нужен рисунок для простого ответа, скорее всего вы добавили слишком много.
- Протестируйте случаи отказа специально. Отправьте плохой токен, просроченный токен и достаточно повторных вызовов, чтобы сработали лимиты. Команда должна знать код статуса, сообщение об ошибке и какой слой его вернул.
- Проверьте логи заблокированного запроса. Хотите понятную причину, а не расплывчатый 401 или 429 без контекста.
- Представьте, что трафик удвоился. Останется ли у вас одно место для управления лимитами и правилами доступа, или люди начнут копировать конфиг по нескольким слоям?
- Уберите дополнительный хоп на бумаге. Если вы не можете сделать это без правки кода приложения, кода клиента и логики аутентификации, слой слишком глубоко встроен.
Малые команды обычно получают больше пользы от понятных логов и меньшего числа движущихся частей, чем от ещё одного слоя контроля. Реверс-прокси часто кажется проще, потому что решения остаются близко к приложению. Шлюз может иметь смысл, но только если команда сможет полноценно его протестировать и объяснить без воды.
Именно здесь часто начинаются проблемы с затратами. Один дополнительный хоп сначала не кажется дорогим. Потом он требует собственной конфигурации, дашбордов, алертов и плана на случай отказа. Если вы хотите лишённую церемоний инфрастуктуру, держите вход читаемым и с возможностью отката.
Хороший выбор остаётся простым и когда трафик растёт, и когда приходит новый инженер, и когда в пятницу сменяются правила аутентификации. Если это работает только тогда, когда онлайн единственный человек, кто это собрал — не принимайте решение сейчас.
Следующие шаги для вашей команды
Начните с диаграммы, а не со списка продуктов. Нарисуйте полный путь запроса от пользователя до приложения и обратно: DNS, CDN, реверс-прокси, сервер приложения, фоновые сервисы и любые сторонние сервисы аутентификации. Отметьте, где заканчивается TLS, где выполняется аутентификация, куда попадают логи и где запрос может быть заблокирован.
Большинство дебатов «API-шлюз vs реверс-прокси» становится проще, когда этот путь на бумаге. Команды часто обнаруживают, что у них уже есть два места переписывания заголовков, два места проверки токенов или ни одного ясного места для обработки 429.
Выберите один дом для правил аутентификации и один дом для лимитов от злоупотреблений. Если прокси проверяет одно правило, шлюз — другое, а приложение — третье, люди тратят время на погоню за неверным слоем. Сделайте владение ясным и запишите это короткой заметкой для всей команды.
Практический чек-лист поможет:
- Нарисуйте путь запроса для логина, публичных API-вызовов и вебхуков.
- Запишите, какой слой владеет аутентификацией, лимитами, логами запросов и ответами с ошибкой.
- Начните с более простой настройки, если она уже покрывает маршрутизацию, TLS и базовые лимиты.
- Измерьте, что именно болит несколько недель: дублирующийся конфиг, медленные изменения, отсутствие метрик или труднодоступные для отладки ошибки.
- Добавляйте ещё один хоп только когда сможете назвать недостающую задачу в одном предложении.
Последний пункт важнее списка функций. Если ваш реверс-прокси уже покрывает маршрутизацию, заголовки и базовую защиту, используйте его сначала. Добавляйте шлюз, когда вам нужны именно его возможности, а не потому, что в индустрии считается, что зрелые команды его используют.
Небольшой пример снова проясняет ситуацию. Допустим, у вас одно веб‑приложение, один API и пару админ-маршрутов. Вы можете обнаружить, что реверс-прокси и аутентификация на уровне приложения достаточны месяцы. Позже, если появятся потребности в пер-клиентских политиках, трансформации токенов или строгих правилах для арендаторов через несколько сервисов — тогда шлюз начнёт окупать себя.
Если хотите второе мнение перед добавлением слоя, Oleg Sotnikov может помочь с обзором компромиссов как временный CTO или советник стартапа. Он управлял экономными продакшн-стеками в масштабе, поэтому советы остаются практичными: меньше церемоний, меньше движущихся частей и только те контролы, которыми команда будет реально пользоваться.


