Альтернативы SaaS с открытым кодом для молодого продуктового стека
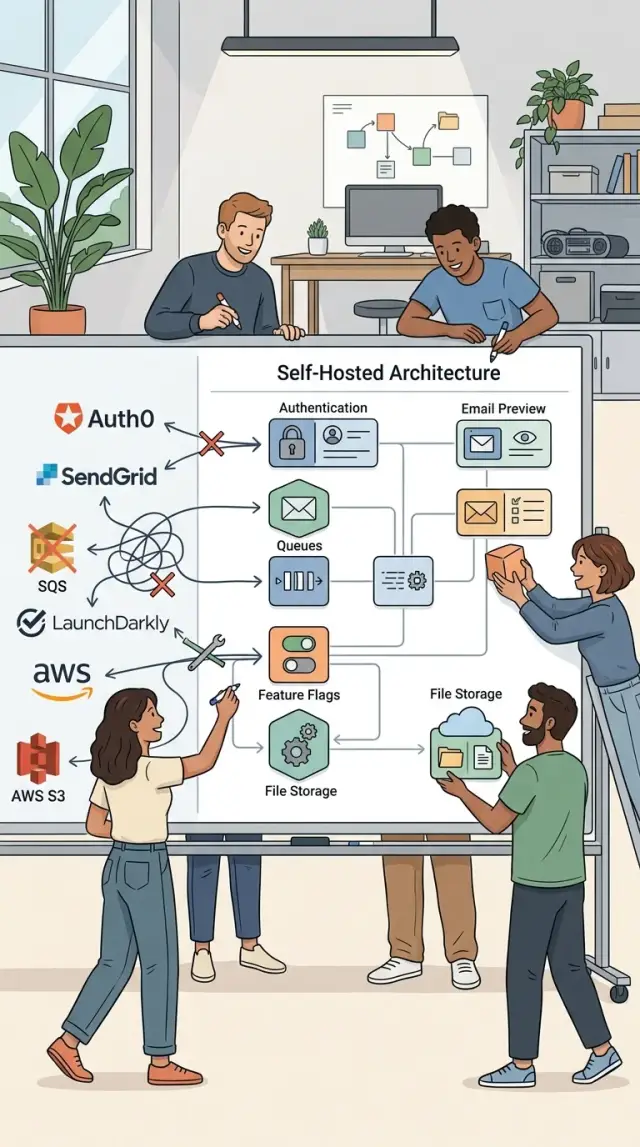
Альтернативы SaaS с открытым кодом могут снизить ранние расходы, если вы выберете практичные инструменты для auth, email preview, очередей, feature flags и файлов.
Содержание
Почему счета за SaaS быстро растут
Ранние продуктовые команды покупают hosted-инструменты по простой причине: они экономят время в первый день. Сервис для входа, inbox для тестирования писем, dashboard для очередей, инструмент для файлов, сервис feature flags. Каждый из них по отдельности кажется недорогим.
Проблема начинается тогда, когда эти маленькие платежи превращаются в постоянный ежемесячный расход. Команда может платить $19 здесь, $49 там, а потом ещё и отдельно за места, логи, хранилище или API-вызовы. Пока у продукта нет стабильной выручки, у стека уже есть вполне реальный ежемесячный платёж, как за аренду.
Есть и скрытая цена слишком большого количества админ-панелей. Кто-то должен управлять пользователями, ролями, настройками биллинга, webhook-секретами, алертами и продлениями в каждой из них. Даже если инструменты работают нормально, команда тратит время на переключение между вкладками и синхронизацию всего подряд.
Модель оплаты по использованию делает это ещё заметнее по мере роста продукта. Больше пользователей — больше логинов. Больше регистраций — больше писем. Больше активности — больше фоновых задач и больше файлов на хранении. Расходы растут вместе с успехом, что звучит справедливо, пока молодой продукт не сталкивается со счетами, рассчитанными на куда более крупную компанию.
Многие ранние задачи проще, чем это выглядят на страницах с тарифами SaaS. Многим командам не нужен hosted-сервис для каждой части стека. Им нужны письма для сброса пароля, которые нормально отображаются, очередь, которая запускает задачи, и загрузка файлов, которая не ломается. Поэтому open source SaaS alternatives на раннем этапе часто оказываются уместным выбором.
Oleg Sotnikov часто советует командам сначала убирать дублирующие сервисы. Это разумное правило: платите за хостинг там, где он действительно экономит время, а скучные части запускайте сами, пока они остаются маленькими и предсказуемыми.
Что заменить в первую очередь
Начните с SaaS-инструментов, которые становятся дороже каждый раз, когда растёт ваш продукт. Оплата за место и оплата за использование сначала кажутся безобидными, а потом превращаются в ежемесячный налог на обычную активность. Админ-аккаунты, внутренние тестировщики, очереди задач и preview environments могут резко поднять расходы задолго до того, как вырастет выручка.
Хорошие первые замены обычно объединяет одно: команда может запустить их без освоения новой профессии с нуля. Если настройка занимает неделю, требует трёх дополнительных сервисов или ломается при каждом деплое, для этого перехода ещё рано.
Рабочая последовательность обычно такая:
- Сначала заменяйте инструменты с оплатой за место или резкими скачками использования
- Пока оставьте платёжные сервисы на managed-решениях
- Пока оставьте реальную отправку писем на managed-решениях
- Переносите по одному слою и наблюдайте за ним неделю
Платежи и исходящая email-рассылка обычно не лучший первый кандидат. Они затрагивают деньги, доставляемость, антифрод, комплаенс и поддержку. Молодая команда редко выигрывает достаточно, если слишком рано переносит их внутрь.
Feature flags, внутренний auth, воркеры очередей, email preview и обработка файлов — более безопасные места для старта. Они ближе к вашему приложению, проще тестируются и проще откатываются, если что-то пойдёт не так. Поэтому при выборе open source SaaS alternatives они часто выглядят убедительнее.
Небольшой пример помогает понять логику. Если у вашего продукта шесть участников команды и несколько тысяч фоновых задач в день, замена платного dashboard для очередей или инструмента для preview inbox может быстро сократить счета. А вот перенос платежей на том же этапе может создать намного больше работы, чем сэкономить.
Выберите слой, который команда уже понимает, замените его и не трогайте остальное, пока новая схема не начнёт казаться скучной. Именно скучность здесь и нужна.
Auth, который можно держать у себя
Платные auth-инструменты сначала кажутся удобными, а потом счёт растёт с каждым новым пользователем. Для молодого продукта self-hosted auth часто даёт достаточно контроля, не добавляя ещё одну постоянную подписку.
Если ваше приложение работает на Next.js или на простом Node-стеке, Auth.js — практичная отправная точка. Он хорошо подходит, когда нужны вход, сессии и популярные провайдеры без тяжёлой админ-надстройки. Если команда хорошо знает код приложения, Auth.js обычно ощущается естественной частью стека.
SuperTokens — хороший вариант, если с самого начала хочется больше готового функционала. Он покрывает вход, сессии, сброс пароля и управление пользователями так, что маленькая команда экономит время. Вы по-прежнему хостите его сами, но получаете больше страховки, чем с более лёгкой библиотекой.
Keycloak — это уже другой сценарий. Он уместен, когда нужны SSO, подробные роли или единый вход для нескольких продуктов. Для небольшого приложения с одним веб-клиентом он может ощущаться слишком тяжёлым. Для B2B-продукта с админскими ролями и корпоративными аккаунтами он начинает выглядеть гораздо логичнее.
Полезно держать простое правило:
- выбирайте Auth.js для лёгкого Next.js- или Node-приложения
- выбирайте SuperTokens, если хотите быстрее получить готовые auth-сценарии
- выбирайте Keycloak, если рано важны SSO и управление ролями
Начните с email-входа, прежде чем подключать социальные провайдеры. Вход через Google или GitHub звучит привлекательно, но добавляет настройку, крайние случаи и поддержку. Email magic links или email + пароль часто вполне достаточно для первой версии.
Сделайте сброс пароля и приглашения простыми. Основателю, который приглашает двух коллег, не нужна сложная система аккаунтов. Одно понятное письмо для сброса, одно письмо-приглашение и короткие правила сессии закрывают большинство ранних сценариев.
Если вы не можете объяснить auth-поток на одной странице, он, скорее всего, слишком сложен для молодого продукта.
Предпросмотр писем без платного inbox-инструмента
На раннем этапе продукты отправляют неожиданно много писем. Сбросы пароля, приглашения, подтверждения регистрации, уведомления о биллинге и ответы поддержки нужно проверять ещё до того, как их увидят реальные пользователи.
Платный инструмент для тестирования inbox в этот момент часто кажется лишним. Если команде в основном нужно перехватывать исходящую почту во время разработки и проверять шаблоны локально, Mailpit или MailHog обычно справляются отлично.
Mailpit или MailHog
Mailpit — более удобный выбор для большинства новых проектов. Вы запускаете его рядом с приложением, указываете SMTP на него, и каждое исходящее сообщение попадает в локальный inbox вместо реального почтового сервиса. Так легко проверять тему письма, имя отправителя, сломанные блоки и отсутствующие переменные.
MailHog тоже хорошо работает, особенно в старых Docker-настройках, где команда его уже знает. Он простой, лёгкий и достаточно хороший, если вам нужно только смотреть на сырые письма и базовый HTML.
Такая схема ловит ошибки, которые часто пропускают, если проверять письма слишком поздно. В письме для сброса может быть неверное название продукта. В письме-приглашении может сломаться кнопка. Письмо подтверждения может отлично выглядеть на десктопе и странно — на мобильном.
Для молодого продукта вот какие проверки важнее всего:
- Отправить письмо для сброса пароля из реального сценария приложения
- Сгенерировать приглашение для нового коллеги или тестового пользователя
- Открыть HTML- и plain text-версию
- Проверить подставные данные, такие как имена, URL и время действия
- Убедиться, что ничего случайно не ушло реальному клиенту
Если использовать email preview tools именно так, мелкие ошибки будут пойманы до того, как превратятся в обращения в поддержку. Это ещё и ускоряет повседневную работу. Разработчик меняет шаблон, обновляет inbox и видит результат за секунды.
Используйте реальный почтовый сервис только тогда, когда вам действительно нужны доставляемость, репутация и отправка в продакшене. Для локальной работы self-hosted inbox дешевле, быстрее и обычно менее раздражающий.
Очереди для фоновой работы
Если ваше приложение отправляет письма, уменьшает изображения, вызывает webhooks или импортирует данные, не заставляйте пользователя ждать этого в рамках самого запроса. Отправьте задачу в очередь. Страница ответит быстро, а работа завершится через несколько секунд.
Это один из самых простых способов уменьшить всплески нагрузки и случайные тайм-ауты в молодом продукте. И это же делает сбои менее болезненными. Если целевой сервис webhook недоступен две минуты, приложению не нужно падать вместе с ним.
Для Node-приложений BullMQ — надёжный выбор. Он использует Redis, хорошо работает с отложенными задачами и даёт понятный способ настраивать повторы и управлять параллельностью. Если в стеке уже есть Redis, BullMQ обычно кажется самым коротким путём.
Если хочется меньше движущихся частей, pg-boss — умный вариант. Он работает на Postgres, поэтому задачи можно хранить в той же базе данных, которую вы и так используете. Для маленьких команд это часто лучше, потому что не нужно следить, патчить и бэкапить ещё один сервис.
Python-команды часто останавливаются на Celery. Он хорошо подходит для долгих задач, особенно когда работа занимает время, например при разборе документов или обработке видео. Celery требует больше настройки, чем лёгкая очередь, но это окупается, когда фоновая работа — реальная часть продукта.
Простое правило помогает: сначала убирайте из request path медленные и потенциально проблемные задачи. Обычно это:
- обработка изображений после загрузки
- исходящие webhooks
- отправка писем
- генерация отчётов
- импорт и синхронизация данных
С самого начала задайте несколько ограничений. Добавьте повторы с лимитом, логируйте каждый сбой вместе с payload задачи и ошибкой, а также ограничьте concurrency, чтобы один шумный тип задач не задушил worker. Команды часто пропускают это на старте, а потом тратят выходные, пытаясь понять, почему задачи исчезли или выполнились пять раз.
Feature flags без очередного счёта
Feature flags помогают маленьким командам выкатывать код до того, как его увидят все. Это важно, когда нужно протестировать новый сценарий на 5% пользователей, быстро выключить его или дать ранний доступ одному клиенту без свежего деплоя.
Unleash — хороший выбор, когда нужен более тонкий контроль. Он даёт правила раскатки, сегменты пользователей и историю изменений, так что видно, кто и когда поменял флаг. Это особенно важно, когда релизами занимается больше одного человека.
Flagsmith проще, если потребности скромнее. Он хорошо подходит для переключателей в приложении и API и не требует много времени, чтобы разобраться. Если продукт ещё молодой и вам в основном нужно скрыть незавершённую работу или включить функцию для небольшой группы, этого может быть достаточно.
Используйте флаги для управления релизом, а не как вечные настройки. Флаг должен помогать запускать, тестировать и снижать риск. Если переключатель остаётся включённым месяцами и никто не планирует его убирать, перенесите логику в обычные настройки продукта или в простой код. Старые флаги быстро накапливаются и усложняют поиск багов.
Названия флагов важнее, чем ожидают команды. Называйте их по действию пользователя или поведению продукта, а не по внутреннему имени спринта. "allow_team_invites" говорит правду. "sprint_17_toggle" через три месяца почти ничего не объясняет.
Рабочее правило простое:
- добавляйте флаг, когда релизу нужна безопасность
- пересматривайте старые флаги каждые несколько недель
- удаляйте флаг, когда функция становится обычным поведением продукта
Такая привычка делает feature flags полезными, а не превращает их в хлам.
Работа с файлами под вашим контролем
Платные file-сервисы сначала выглядят просто, но часто становятся дорогими как раз в тот момент, когда пользователи начинают загружать реальные данные. Молодой продукт может избежать этого счёта с помощью небольшого стека, который он запускает сам.
MinIO — хорошая основа. Он даёт object storage в стиле S3 на ваших собственных серверах, так что приложение может хранить изображения, документы, резервные копии и экспорты, не меняя привычный способ работы с файлами. Если вы уже используете инструменты, которые ожидают S3, MinIO обычно вписывается без лишней боли.
На стороне браузера Uppy делает загрузку обычной, а не хрупкой. Он обрабатывает выбор файлов, полосы прогресса, повторы и сообщения о статусе. Это важнее, чем кажется. Если пользователь загружает пять фото, а одно из них не прошло, ему нужно понять, какое именно и что делать дальше.
Большие загрузки требуют дополнительной заботы. tusd помогает, когда кто-то отправляет большой видеофайл или тяжёлый ZIP с нестабильным соединением. Если загрузка останавливается на 82 процентах, tusd может продолжить её вместо того, чтобы заставлять пользователя начинать заново. Уже этого достаточно, чтобы сэкономить много обращений в поддержку.
Для изображений лучше держать обработку простой. libvips часто оказывается лучшим выбором, если вам нужны быстрая ресайз-обработка и меньшее потребление памяти. ImageMagick тоже работает хорошо и известнее по названию, но для простого создания миниатюр и конвертации форматов он нередко кажется тяжелее, чем нужно.
Перед запуском задайте несколько правил:
- ограничьте размер файла по типу
- разрешайте только те форматы, которые вам реально нужны
- проверяйте загрузки на вредоносное ПО
- храните оригиналы и созданные миниатюры отдельно
- удаляйте забытые временные файлы по расписанию
Простой пример подходит многим командам: Uppy на фронтенде, tusd для возобновляемых загрузок, MinIO для хранения и libvips для задач с изображениями. Это скучный в хорошем смысле стек. Он даёт контроль, снижает расходы и уменьшает количество сюрпризов, когда объём загрузок начинает расти.
Простая схема для молодого продукта
Молодому продукту не нужен набор дорогих сервисов, чтобы хорошо работать. Небольшая команда может запустить веб-приложение на Next.js, хранить основные данные в Postgres и использовать Redis для кэша, сессий и фоновых задач. Так получается стек, который легко объяснить, легко отлаживать и который при этом достаточно недорог, пока продукт только обретает форму.
Практичная схема использует несколько self-hosted-инструментов вокруг этой базы.
- Auth.js управляет входом и сессиями внутри приложения.
- Mailpit перехватывает сбросы паролей, magic links и приветственные письма во время разработки.
- BullMQ обрабатывает медленные задачи вроде генерации отчётов, обработки файлов и очистки загрузок.
- MinIO хранит пользовательские файлы в bucket, совместимом с S3, который вы контролируете.
- Postgres остаётся источником истины для пользователей, продуктов и данных о биллинге.
Приятная часть в том, как эти элементы сочетаются без лишней церемонии. Пользователь входит через Auth.js, загружает файл в MinIO, а приложение ставит задачу в BullMQ, чтобы просканировать или преобразовать этот файл. Если поток отправляет письмо, команда может проверить его в Mailpit до того, как оно попадёт в реальный inbox.
Именно поэтому open source SaaS alternatives имеют смысл на раннем этапе. Вы держите движущиеся части рядом с продуктом, поэтому локальная разработка ощущается как production, а не как его грубая копия. Когда что-то ломается, команда смотрит на одно приложение, одну базу данных, один экземпляр Redis и сервисы вокруг них.
Для многих молодых продуктов этого хватает надолго. Можно работать на скромной инфраструктуре, держать ежемесячные расходы предсказуемыми и менять части стека позже только тогда, когда реальное использование заставит это сделать.
Как перейти без поломок
Безопасная замена начинается с простой рутины. Составьте список всех платных инструментов, их реальную ежемесячную стоимость и то, какая часть продукта от них зависит. Включите скрытые расходы: дополнительные места, превышение лимитов и время, которое команда тратит на обходные пути.
Потом выберите самый громкий счёт, а не инструмент с самым красивым заменителем. Если один сервис стоит $300 в месяц, а другой $20, обычно больше пользы даст замена дорогого. Молодым командам лучше один понятный выигрыш, чем пять недоделанных миграций.
Используйте небольшой процесс и повторяйте его.
- Сначала запустите новый инструмент локально.
- Повторите один реальный сценарий, например регистрацию, загрузку файла или фоновое письмо.
- Переведите этот один сценарий в production для небольшой группы.
- Несколько дней наблюдайте за ошибками, обращениями в поддержку и временем выполнения задач.
- Продолжайте только если показатели остаются стабильными.
Этот пошаговый подход важнее самого инструмента. Self-hosted auth-система может работать отлично, но всё равно создаст проблемы, если сброс пароля сломается или без предупреждения изменится время жизни сессии. То же относится к очередям, файловому хранилищу и feature flags.
Во время миграции делайте короткие заметки. Вам не нужен большой мануал. Запишите, как делать бэкап сервиса, как его восстановить, как обновлять и кто за него отвечает. Когда что-то ломается в пятницу вечером, эти четыре заметки экономят больше времени, чем длинный документ по планированию.
Команды, которые переключаются аккуратно, обычно тратят меньше и спят спокойнее. Команды, которые переносят всё сразу, часто в итоге платят и за старый, и за новый стек, пока исправляют ошибки, которых можно было избежать.
Ошибки, которые создают лишнюю работу
Самый быстрый способ потерять время с open source SaaS alternatives — выбрать инструменты, рассчитанные на команду в десять раз больше вашей. Продукту на двух человек обычно не нужен кластер, три dashboard-а и неделя настройки только для того, чтобы отправлять письма или запускать фоновые задачи. Если инструмент требует постоянного ухода, он не дешёвый. Он создаёт дополнительную работу.
Ещё одна ошибка — добавлять новую базу данных для каждого сервиса. Один инструмент хочет Redis, другой — Postgres, а третий — и то и другое. Позже это может быть нормально, но на раннем этапе каждый новый datastore добавляет бэкапы, обновления, алерты и новые точки отказа. Если одна хорошая настройка Postgres закрывает большую часть потребностей, часто это более спокойный вариант.
Команды также слишком рано копируют enterprise-подходы к auth. SSO, mapping тенантов, сложные роли, история устройств и длинные цепочки согласований звучат серьёзно, но они замедляют простой продукт. Если пользователям достаточно email и пароля плюс сброса, начните с этого. Добавляйте больше только когда реальные клиенты об этом попросят.
Файлы и задачи часто игнорируют до первого сбоя. Молодой продукт может работать месяцами без проблем, а потом один полный диск или неудачный деплой стирает очередь или загруженные файлы. Бэкапы кажутся скучными, но восстанавливать потерянные счета, изображения или письма регистрации куда хуже.
Feature flags создают собственный беспорядок. После запуска многие команды оставляют старые флаги в коде, потому что удалять их кажется рискованным. Спустя полгода никто уже не помнит, что контролирует "new_checkout_v2", и любое изменение затрагивает мёртвые ветки. Если флаг выполнил свою задачу, удалите его из кода, конфигурации и заметок. Такая уборка потом экономит реальные часы.
Быстрые проверки перед выбором
Дешёвый инструмент всё равно может обойтись слишком дорого, если команде придётся учить новый стек только ради его поддержки. Начинайте с того, чем разработчики уже пользуются каждую неделю. Если продукт уже работает на Node.js и Postgres, пакет, который естественно ложится в эту схему, обычно выигрывает у хитрого решения на языке, который никто в команде не знает.
Прежде чем добавить что-то в список open source SaaS alternatives, проверьте несколько практичных вещей:
- Команда может читать код, разбирать логи и обновлять инструмент без внешней помощи.
- Его можно запускать с Docker и с как можно меньшим количеством движущихся частей, в идеале с одной базой данных.
- Его можно бэкапить тем же способом, который вы уже используете для остального продукта.
- Он выдержит объём загрузок файлов, фоновых задач и повторов, который вы ожидаете в течение следующего года.
- Новый инженер сможет разобраться в настройке за один присест.
Отдельного внимания заслуживают бэкапы. Инструмент может казаться простым в первый день, а потом стать мучительным, когда после неудачного деплоя нужно восстановить пользовательские данные, email-шаблоны или записи задач. Если на этапе настройки backup и restore выглядят запутанно, в инциденте они будут ощущаться ещё хуже.
Важен и объём. Очередь, которая нормально работает на 100 задачах в день, может не справиться, когда вы отправляете тысячи писем, обрабатываете загрузки или генерируете отчёты рывками. На первый день вам не нужна огромная масштабируемость, но вам нужно ясно понимать, где находятся пределы.
Маленькая команда должна выбирать скучные инструменты. Если auth требует трёх дополнительных сервисов и длинной инструкции по настройке, пропустите его. Когда к команде присоединится следующий инженер, он должен быстро понять стек и вносить изменения без страха.
Следующие шаги для вашего стека
Большинство команд выигрывают, если заменяют по одному платному сервису за раз. Менять auth, очереди, feature flags и обработку файлов в одном месяце звучит эффективно, но чаще приводит к багам, лишней поддержке и сложным откатам.
Выберите область, которая сейчас болит сильнее всего. Если расходы на логин продолжают расти, начните с self-hosted auth. Если фоновые задачи слишком часто падают, сначала перенесите очередь. Если вашей команде нужен только безопасный способ смотреть письма во время разработки, замена inbox-инструмента может дать самый быстрый выигрыш.
Обычно достаточно небольшого плана:
- выберите один сервис для замены в этом месяце
- назначьте одного ответственного за обновления, бэкапы и мониторинг
- копируйте только те функции, которые продукт уже использует
- по возможности оставьте старый сервис включённым на короткое время параллельной работы
Первую версию держите скучной. Для молодого продукта это чаще всего правильное решение. Если приложение отправляет сбросы пароля и magic links, сначала поддержите именно эти сценарии. Если вы загружаете аватары и PDF-файлы, сначала сделайте их надёжно, а уже потом стройте image pipeline, правила вирусной проверки и шесть вариантов хранилища.
Простой пример: небольшая команда может пока оставить платный auth без изменений, но за день заменить платный инструмент email preview и на следующей неделе перевести фоновые задачи. Так можно сократить расходы, не трогая самую рискованную часть продукта.
За мониторинг тоже должен кто-то отвечать, даже если схема совсем маленькая. Кто-то должен проверять логи, следить за дисковым пространством, обновлять секреты и понимать, что ломается, когда сервис перестаёт работать.
Если команда разделилась между вариантами, Oleg Sotnikov может помочь разобраться в trade-offs как fractional CTO. Короткий разбор может уберечь вас от выбора стека, который сначала кажется дешёвым, а потом каждую неделю съедает время.


