AI-помощь в архитектурных ревью по живой кодовой базе
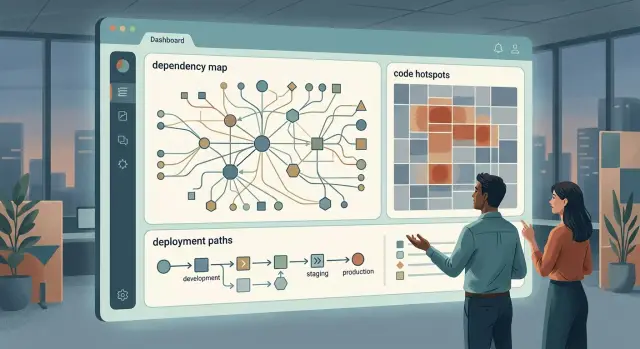
AI-assisted architecture reviews объединяют карты зависимостей, hotspots кода и пути деплоя, чтобы команда получала короткие и точные советы на основе реального кода.
Содержание
Почему общие ревью архитектуры не попадают в цель
Большинство плохих замечаний на ревью звучат разумно, пока команда не попробует применить их на деле. Там пишут что-то вроде «разделите этот сервис», «уменьшите связанность» или «улучшите observability», но не показывают, где именно начинается проблема.
Так происходит, когда советы не учитывают, как код работает на самом деле. В репозитории есть свои привычки, обходные решения, старые решения и скрытые зависимости, которые никогда не видны на аккуратной диаграмме. Если ревьюер не видит, какие модули вызывают друг друга, какие файлы меняются вместе и на каком шаге деплоя всё ломается из-за одного скрипта, советы остаются расплывчатыми.
Статическая схема выглядит аккуратно. Реальные системы обычно нет. Сервис может казаться маленьким на бумаге, но код покажет, что два файла внутри него тянут за собой полприложения, вызывают большую часть регрессий и замедляют каждый релиз.
Та же разница видна и в поставке изменений. На диаграмме можно нарисовать «API -> worker -> database» и всё равно не заметить путь релиза, который зависит от ручной миграции, одного хрупкого переменного окружения и забытого шага в CI. В итоге команда получает архитектурные комментарии, которые звучат умно, но не помогают к релизу на следующей неделе.
Главная цена — шум. Инженеры тратят часы на то, чтобы отделить полезные замечания от общих, спорят о формулировках и проверяют, вообще ли совет подходит текущей системе. Продуктовые команды тоже теряют время, потому что широкие советы превращаются в такие же широкие задачи.
AI-assisted architecture reviews работают лучше, когда они начинают с данных проекта, а не с теории. Если ревью видит реальные карты зависимостей, hotspots кода и пути деплоя, ответ становится короче и точнее. Вместо «уменьшите связанность» вы получаете: «этот auth package лезет в billing и notifications, поэтому любое изменение логина повышает риск релиза». С этим уже можно работать.
Короткие и точные советы появляются не потому, что модель говорит меньше. Они появляются потому, что ей дают лучший вход.
Что сначала взять из кодовой базы
Начинайте с фактов, а не с мнений. Ревью лучше всего работает, когда модель видит, как устроен код, где команда постоянно что-то меняет и как эти изменения доходят до production.
Первое, что стоит выгрузить, — это карта зависимостей. Сделайте её простой. Покажите сервисы, основные модули и общие пакеты, а затем покажите, кто кого вызывает или импортирует. Это не должно быть идеально. Нужна лишь достаточная детализация, чтобы заметить рискованные связи, например когда один общий пакет оказывается в центре половины системы.
Затем отметьте hotspots. Ищите файлы или модули с высокой недавней активностью, повторными исправлениями багов или тестами, которые падают или тормозят. Именно такие области создают большую часть шума в разговорах об архитектуре, потому что там смешиваются проблемы дизайна и ежедневная боль поставки изменений. Спокойный, стабильный модуль важен меньше, чем тот, который переписывают двенадцать раз в месяц.
Пути деплоя важны не меньше самого кода. Запишите, что происходит от коммита до production для каждой части системы. Включите сборку, тестовые проверки, создание пакета или образа, изменения инфраструктуры, согласования и шаги выката. Если один сервис выходит за десять минут, а другой требует ручных исправлений в трёх инструментах, ревью должно увидеть эту разницу.
Владение часто пропускают. Отметьте, у каких сервисов или модулей есть понятный владелец, а у каких нет. Когда за общей библиотекой никто не следит, она обычно начинает развиваться не в ту сторону. Когда две команды считают, что сервис принадлежит другой, баги лежат дольше, а рискованные изменения проходят незаметно.
Небольшой пример делает это понятным. Допустим, у вашего SaaS-приложения есть auth service, billing service и общий пакет для уведомлений. Карта зависимостей показывает, что billing и auth оба зависят от этого пакета. Данные по churn показывают, что пакет менялся каждую неделю. Путь деплоя показывает, что обновления notifications всё ещё требуют ручного шага. В заметках по владельцу видно, что никто не хочет брать за это ответственность. Этого уже достаточно для полезного ревью, потому что факты конкретны.
Выберите один вопрос для ревью
AI-assisted architecture reviews работают лучше всего, когда запрос задаёт один чёткий вопрос. Если попросить сразу дать полный вердикт по структуре, надёжности, производительности, безопасности и процессам команды, ответ быстро станет расплывчатым.
Начните с проблемы, которую хотите уменьшить в этом месяце. Это могут быть падения релизов, медленная работа над фичами, тяжёлые ночные дежурства или слишком много изменений, которые затрагивают одни и те же файлы. Узкая цель даёт ревью фильтр: карты зависимостей, hotspots и пути деплоя имеют значение только тогда, когда помогают ответить именно на неё.
Хорошие вопросы звучат просто:
- Почему изменения в billing постоянно вызывают проблемы с релизами?
- Что делает этот API таким медленным для изменений?
- Какой сервис создаёт больше всего риска деплоя в этой части продукта?
- Где этот checkout flow зависит от слишком многих команд?
Держите рамки узкими. Выберите одну область продукта, например onboarding или billing, либо одну группу сервисов, которые обычно релизятся вместе. Если включить всю платформу, ревьюер половину времени будет описывать очевидную форму системы вместо того, чтобы найти несколько решений, которые постоянно вызывают боль.
Также сразу укажите, что ревьюер должен игнорировать. Это важнее, чем ожидают многие команды. Если ваша цель — ускорить изменения в одной группе сервисов, так и скажите. Попросите игнорировать старые admin tools, фоновые задачи вне этого потока и стилистические замечания, которые не влияют на скорость поставки. Ревью станет короче, а советы — удобнее.
Аудитория тоже важна. Staff engineer, возможно, нужны цепочки вызовов, границы модулей и связь деплоя. Основателю чаще нужен более короткий ответ: что тормозит релизы, что менять первым и что может подождать. Если за результат никто не отвечает, даже точное ревью останется без дела.
Полезно добавить короткую заметку к запросу: для кого предназначен ответ, какое решение он должен поддержать, что входит в область анализа и что не входит. Такой маленький шаг часто сокращает итог вдвое.
Постройте процесс ревью по шагам
Начинайте с малого. Если выгрузить в модель весь репозиторий, она уходит в общие советы и пропускает то, что реально мешает команде каждую неделю.
Сначала дайте карту зависимостей. Она задаёт форму ревью. Так видно, где один сервис слишком сильно опирается на другой, где общий модуль затрагивает слишком много областей и где маленькое изменение может разойтись дальше, чем ожидалось.
Затем добавьте hotspots. Hotspot — это код, который часто меняется, вызывает баги или постоянно появляется в pull requests и заметках по инцидентам. Это важно, потому что модуль, который на диаграмме выглядит чистым, может быть вашей главной проблемой, если команда правит его каждые несколько дней.
Потом добавьте пути деплоя. Именно здесь многие ревью становятся полезными очень быстро. Покажите путь от коммита до production, включая сборки, проверки, согласования, скрипты и любой ручной переход между людьми или системами. Сервис может выглядеть нормально в кодовой базе, но всё равно создавать риск, если один релиз зависит от shell-скрипта, шага copy-paste или того, что кто-то вспомнит правильный порядок.
Простой порядок уже достаточен:
- Передайте карту зависимостей для области, которую хотите проверить.
- Добавьте данные о hotspots из недавних коммитов, багов или боли поддержки.
- Прикрепите путь деплоя для той же области.
- Задайте один узкий вопрос, например: «Где изменения создают наибольший риск релиза?»
- Попросите только три действия, отсортированные по влиянию и усилиям.
Последний пункт очень важен. Если попросить полный отчёт, обычно получается длинный документ, который никто не использует. Если попросить три действия, модель вынуждена выбрать. В итоге ответ становится понятнее, короче и проще для проверки в следующем спринте.
Сохраняйте точные входные данные вместе с запросом. Оставляйте тот же фрагмент карты, тот же промежуток hotspots, те же заметки по деплою и тот же вопрос для ревью. Тогда команда сможет прогнать процесс снова после рефакторинга и сравнить результат, не гадая, поменялся ли сам запрос.
Простой пример для SaaS-продукта
Представьте небольшую SaaS-команду с тремя основными частями, за которыми нужно следить: billing service, admin app для сотрудников поддержки и очередь worker, которая отправляет счета, повторяет неудачные списания и обновляет статус аккаунтов. Система не огромная, но релизы всё равно проходят напряжённо.
Billing service меняется почти каждую неделю. Логика цен пересматривается, налоговые правила обновляются, добавляются купоны, а edge cases у платёжного провайдера всё время всплывают снова. Команда знает, что billing — зона риска, но общее ревью лишь повторяет то, что и так известно, например «уменьшите связанность» или «улучшите надёжность».
Ревью по живой кодовой базе даёт им то, что можно использовать. Они передают карту зависимостей, недавние hotspots и реальный путь деплоя. Этого хватает, чтобы увидеть, откуда берётся напряжение.
Одна проблема проявляется быстро. Billing service и admin app оба зависят от одного общего пакета. Сначала пакет казался полезным, потому что хранил статус клиента, правила цен и настройки повторных попыток в одном месте. Со временем он стал ловушкой. Теперь небольшое изменение в admin может повлиять на поведение billing, даже если никто не собирался трогать логику платежей.
Путь деплоя показывает вторую проблему. Один шаг релиза всё ещё зависит от того, что человек вручную проверит всё перед перезапуском worker. Звучит мелко, но именно такие шаги и создают реальные проблемы. Кто-то отвлёкся, пропустил его, и после деплоя очередь начинает накапливаться.
Команда делает две небольшие правки вместо того, чтобы планировать полную перепись. Сначала они разделяют общий пакет так, чтобы у billing осталась своя логика. Затем оставляют admin app более тонкий пакет, который отдаёт только нужные данные. Ещё они автоматизируют проверку релиза, чтобы деплой останавливался сам, если настройка очереди неверна.
Вот такого результата и стоит добиваться. Совет остаётся коротким, потому что он указывает на одну общую зависимость и один шаг деплоя, а не на десять абстрактных best practices.
Как выглядит хороший результат ревью
Полезная заметка по архитектуре указывает на один реальный риск в одном реальном месте. Она не говорит в общем про «backend» или «процесс деплоя». Она называет конкретный модуль, путь к файлу, запрос, очередь или шаг деплоя, который может сломаться.
Такой уровень детализации меняет разговор. Команда может открыть код, проверить утверждение и решить, что делать, за минуты. Общие советы превращаются в спор. Конкретные советы превращаются в действие.
Лучший результат короткий и основан на фактах. Он должен объяснять, что не так, почему это важно и какую маленькую правку команда может попробовать уже на этой неделе.
Заметка ревью, которую люди действительно используют
Хорошая заметка выглядит так:
billing/invoice_sync.tsповторяет неудачные sync jobs без ограничения, из-за чего очередь может переполниться во время сбоя у платёжного провайдера.- Это важно, потому что checkout может выглядеть здоровым, пока invoice jobs накапливаются и задерживают обновление аккаунтов на часы.
- Добавьте лимит повторов и отправляйте неудачные задачи в dead-letter queue после третьей попытки.
- Проверьте шаг в deploy pipeline, который запускает migrations для worker перед выкладкой app, чтобы старые workers не продолжали поддерживать плохой цикл повторов.
Этого достаточно для одной встречи. Люди понимают, куда смотреть, что может сломаться и что тестировать дальше. Никому не нужна лекция о «resilience patterns».
Простые слова важны не меньше технической точности. «Это может удвоить cloud costs во время всплеска трафика» лучше, чем «это создаёт усиление нагрузки на ресурсы при пиковых условиях». Большинство команд двигаются быстрее, когда ревью звучит как коллега, а не как доклад на конференции.
Хороший результат ещё и остаётся узким. Одна заметка должна описывать одну проблему. Если ревью находит пять проблем, дайте пять отдельных заметок. Когда один комментарий смешивает caching, permissions, порядок деплоя и schema drift, люди теряют главный риск.
Полезная проверка простая: может ли человек прочитать заметку вслух меньше чем за минуту и сразу назначить владельца? Если да, ревью, скорее всего, делает свою работу.
Ошибки, из-за которых ревью превращается в шум
Большая часть плохого результата начинается ещё до того, как модель увидела хоть один файл. Если вы скармливаете ей весь репозиторий и просите «сделать architecture review», обычно получаются общие советы, которые подойдут почти любому продукту. Модель видит слишком много путей, слишком много шаблонов и не видит приоритета.
Лучший запрос даёт ей одну задачу. Спросите про медленный релиз, рискованную цепочку зависимостей, хрупкую границу сервиса или hotspot, который постоянно ломается.
Ещё одна частая проблема — смешивать старые диаграммы с текущим кодом. Команды часто вставляют карту системы шестимесячной давности рядом с сегодняшним репозиторием и ждут один чистый ответ. Если диаграмма говорит одно, а imports, очереди или API-вызовы — другое, ревью начинает спорить само с собой.
Используйте код как источник истины. Подключайте диаграммы как вспомогательные заметки, а не как закон. Если они не совпадают, этот разрыв сам по себе полезен, потому что часто показывает дрейф, которого никто не заметил.
Команды ещё и забывают про шаги релиза, которые живут вне кода приложения. Сервис может выглядеть независимым в репозитории, но всё равно зависеть от миграции, job в GitLab pipeline, перезапуска worker, секрета в deploy system или инфраструктурного правила на границе. Если это не учесть, ревью может обвинить не тот слой.
Ещё одна ошибка — просить переписать всё заново. Это почти всегда уводит результат в сторону больших и расплывчатых планов. Вместо этого просите самые маленькие изменения, которые снизят риск уже в этом месяце.
Держите и результат под контролем. Длинные списки желаний звучат умно, но ими трудно пользоваться. Обычно ревью должно заканчиваться коротким набором действий с приоритетами: исправить сейчас, потому что это блокирует релизы; исправить следующим, потому что это вызывает повторяющиеся инциденты; наблюдать, потому что проблема может вырасти; или пока не трогать, потому что цена выше риска.
Если ревью не помещается в несколько ясных действий, вход всё ещё слишком расплывчатый.
Быстрые проверки перед тем, как доверять совету
Плохой совет по ревью обычно ломается по обычным причинам. Он указывает на файлы, которые никто не трогал, шаги деплоя, которыми никто не пользуется, и исправления, за которые никто не отвечает.
Начните с ветки, а не с отчёта. Если ревью называет payments/service.ts, а на вашей текущей ветке эта логика уже переехала в billing/renewal.ts, остальная часть совета может быть уже неверной. Ревью по живой кодовой базе помогает только тогда, когда названные файлы, модули и сервисы совпадают с тем, над чем команда работает сегодня.
Затем сравните указанные hotspots с реальной болью. Если ревью считает один пакет рискованным, вы должны увидеть это в недавних инцидентах, тикетах поддержки, шумных алертах или медленных исправлениях on-call. Когда hotspot никогда не проявляется в production, код всё ещё может быть грязным, но он не должен автоматически попадать в начало списка.
Несколько быстрых проверок ловят большую часть плохих советов:
- Подтвердите, что каждый названный файл и сервис всё ещё существует в текущей ветке.
- Сравните hotspots с недавними багами, болью поддержки и всплесками ошибок.
- Проверьте, что шаги релиза в ревью совпадают с тем, как команда деплоит сейчас.
- Поставьте одного владельца рядом с каждой предложенной задачей.
- Убедитесь, что командa может проверить изменение без ставки на весь релиз.
Третья проверка важнее, чем многим кажется. Если команда деплоит через GitLab CI/CD, а ревью предполагает ручной release script, предложенный путь исправления может съесть целый день. То же относится к runtime checks. Если вы отслеживаете ошибки в Sentry, а ревью не совпадает с тем, что показывает Sentry, притормозите, прежде чем доверять совету.
Владение — ещё один простой фильтр. «Переработайте auth boundary» звучит умно, пока три команды не думают, что это сделает кто-то другой. У каждого действия должен быть один человек, который сможет его взять, сделать изменения и ответить на вопросы.
Тестирование решает, полезен совет или просто рискован. Команда должна понимать, как проверить изменение в staging, за feature flag или через небольшой rollout с планом rollback. Если безопасно проверить нельзя, ревью всё ещё слишком широкое.
Когда две или больше таких проверок проваливаются, просите более узкое ревью. Короткий совет, привязанный к текущей ветке, лучше длинного отчёта, построенного на устаревшем контексте.
Следующие шаги для вашей команды
Не запускайте это сразу на весь продукт. Выберите одну область, которая уже болит: падающие checkout, медленные background jobs, хрупкий auth или путь релиза, который ломается под нагрузкой. Узкий тест даёт ревью реальную цель и делает плохие советы легко заметными.
Прогоните этот процесс на выбранном срезе неделю или две. Оставляйте входные данные привязанными к одной и той же области: карта зависимостей, недавние hotspots и путь деплоя. Когда эти части связаны между собой, ревью становится гораздо конкретнее. Вы получаете меньше общих мнений и больше комментариев, которые команда реально может использовать.
Затем сравните результат с тем, что уже знают ваши senior engineers. Если ревью говорит «разделите этот сервис», а команда понимает, что настоящая проблема — рискованный шаг миграции, доверяйте тем, кто живёт с этой системой каждый день. Ревью должно подтверждать уже видимые закономерности, показывать одно-два слепых пятна и сокращать споры. Оно не должно перекрывать опыт.
После первого прохода оставляйте только те предложения, которые проходят простой тест. Команда должна уметь объяснить проблему простыми словами, назначить одного владельца, быстро внедрить изменение и измерить, помогло ли оно.
Превратите две лучшие идеи в задачи сразу. У каждой должен быть владелец, узкий scope и проверка успеха, например меньше rollback steps, ниже error rate или на 15 минут быстрее деплой. Два небольших успеха учат команду больше, чем бэклог из умных идей.
Это ещё и хороший способ понять, стоит ли вообще оставлять такой процесс ревью. Если он находит проблемы, которые команда и так знала, но описывает их быстрее и с меньшим количеством споров, это уже полезно. Если же он в основном выдаёт очевидные советы или фантазии о полной переписи, сузьте область и попробуйте снова.
Если вам нужна помощь с настройкой такого процесса ревью, Oleg Sotnikov на oleg.is работает как Fractional CTO и startup advisor по архитектуре, инфраструктуре и практическому внедрению AI. Такой внешний взгляд особенно полезен, когда команде нужна более точная техническая оценка, но нанимать CTO на полную ставку пока рано.
Часто задаваемые вопросы
Зачем делать ревью по живой кодовой базе, а не только по диаграмме?
Потому что диаграммы скрывают грязные детали. Ревью по живой кодовой базе видит реальные импорты, общие пакеты, churn и шаги релиза, поэтому может указать на модуль или шаг деплоя, которые постоянно создают проблемы, вместо общих советов.
Что нужно собрать перед запуском AI-assisted architecture review?
Начните с трёх вещей: простой карты зависимостей, недавних hotspots и пути деплоя для той области, которую вы хотите проверить. Этого достаточно, чтобы модель заметила рискованные связи и хрупкие шаги релиза, не перегружая себя всем репозиторием.
Насколько подробной должна быть карта зависимостей?
Сделайте её простой. Покажите сервисы, основные модули, общие пакеты и кто кого вызывает или импортирует. Не нужно перечислять каждый файл; нужно лишь достаточно деталей, чтобы увидеть, где один пакет или сервис затрагивает слишком много системы.
Как найти hotspots в кодовой базе?
Смотрите на недавний churn коммитов, повторные исправления багов, падающие тесты, заметки по инцидентам и боль поддержки. Если файл или модуль постоянно всплывает в этих сигналах, начните с него. Стабильный код важен меньше, чем код, который команда постоянно трогает под давлением.
Стоит ли проверять весь репозиторий сразу?
Нет. Выберите одну область продукта или одну группу сервисов, которые обычно релизятся вместе. Узкий срез даёт более короткие и точные советы, а ревью по всему репозиторию обычно превращается в общие комментарии.
Как должен выглядеть хороший запрос для ревью?
Задайте один понятный вопрос, связанный с одной проблемой. Например: Почему изменения в billing постоянно вызывают проблемы с релизами? — это хороший вариант, потому что он даёт ревью чёткую цель и отсекает шум из не связанных частей системы.
Как должен выглядеть результат ревью?
Хорошая заметка называет один реальный риск в одном реальном месте. Она должна объяснять, что ломается, почему это важно и какое небольшое исправление команда может попробовать уже на этой неделе, например добавить лимит повторов или убрать одну общую зависимость.
Как понять, стоит ли использовать этот совет?
Перед тем как доверять совету, сопоставьте названные файлы и сервисы с текущей веткой, сравните указанный hotspot с недавними инцидентами или всплесками ошибок и проверьте, что шаги деплоя всё ещё совпадают с тем, как команда релизится сейчас. Если факты не сходятся, запустите ревью заново с более точным входом.
Какие исправления обычно дают результат раньше всего?
Чаще всего быстрый эффект дают правки одного общего пакета, который заходит слишком далеко, удаление одного ручного шага релиза или явное закрепление владельца за запутанным модулем. Такие небольшие изменения снижают риск релиза быстрее, чем большой рефакторинг.
Когда имеет смысл привлечь Fractional CTO для этого?
Приглашайте его, когда релизы кажутся рискованными, команда спорит о том, где на самом деле проблема, или у вас нет времени выстроить нормальный процесс ревью. Опытный Fractional CTO поможет сузить фокус, быстро оценить компромиссы и превратить ревью в несколько действий, которые команда реально сможет внедрить.


