AI-first architecture: почему скучные решения снижают риск
AI-first architecture начинается с прав доступа, состояния и четких границ между системами. Узнайте, где риск накапливается еще до того, как выбор модели вообще становится важным.
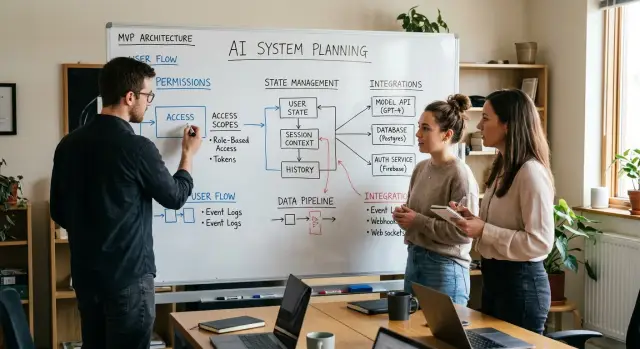
Содержание
Почему модель — не первое решение
Команды часто начинают с модели, потому что ее проще всего сравнивать. Один демо-вариант кажется лучше другого. Таблицы с ценами выглядят просто. Бенчмарки дают оценку.
Это кажется конкретным, но за этим скрывается то, что обычно ломается первым. Первые сбои редко происходят потому, что одна модель чуть хуже другой. Обычно проблемы начинаются потому, что никто не воспринял права доступа, состояние и границы системы как продуктовые решения.
Это особенно видно на примере support-бота. Если он видит все записи клиентов, одна ошибка в правилах доступа может раскрыть приватные данные в одном ответе. Если он может оформлять возвраты, а система плохо отслеживает состояние, повторный запрос может провести один и тот же возврат дважды. Если он может писать в CRM, billing-систему и email-сервис без четких ограничений, одно неверное действие быстро разнесет проблему дальше.
Поэтому AI-first architecture начинается с простых вопросов. Кто что может делать? Что система помнит? Какой инструмент может менять какие данные? Именно эти решения определяют, насколько большой станет ошибка еще до того, как модель ответит на первый запрос.
Небольшие решения в дизайне создают большие проблемы:
- Общий admin token дает каждому процессу больше доступа, чем нужно.
- Отсутствие request ID превращает безобидный повторный запрос в дублированные заказы или сообщения.
- Прямые записи сразу в несколько инструментов делают плохие действия трудноостанавливаемыми и труднооткатываемыми.
Ни одна из этих вещей не выглядит впечатляюще в демо. Но важнее, чем выбор между двумя сильными моделями с небольшой разницей в качестве.
И живет это дольше. Модели быстро меняются. Цены снижаются, провайдеры меняют условия, а новые релизы появляются каждые несколько месяцев. А вот проектирование прав доступа, управление состоянием и границы интеграций остаются с вами гораздо дольше. Если эти части продуманы, позже сменить модель обычно несложно. Если все сделано неаккуратно, каждая смена модели превращается в событие риска.
Скучные решения не тормозят команду. Они не дают маленькой ошибке превратиться в проблемы для клиентов, ошибки в billing или неделю исправлений.
Права доступа решают, кто что может делать
Права доступа отвечают на простой вопрос: кто может читать, изменять, подтверждать или удалять каждую часть системы?
Если пропустить этот вопрос, модель становится намного менее важной. Умный ассистент с плохими правилами доступа все равно может наделать дорогих ошибок.
Команды часто дают новому AI-инструменту слишком широкий доступ, потому что так кажется быстрее. Они подключают inbox, billing-систему, CRM, документы и admin-панель, а потом позволяют боту действовать везде. Это работает до тех пор, пока он не оформит возврат не тому заказу, не покажет внутренние заметки или не удалит запись из-за убедительно сформулированного запроса пользователя.
Хорошее проектирование прав доступа начинается с малого. Каждой роли — только тот доступ, который нужен для одной задачи. Сотрудники могут видеть историю клиента, обновлять статус тикета и подтверждать чувствительные действия. Клиенты должны видеть только свои данные и подтверждать только собственные изменения. Автоматизациям обычно нужно еще меньше: получать данные, готовить ответы и собирать задачи на проверку.
Именно последняя роль важнее всего. Во многих системах автоматизация должна предлагать, а не решать. Support-ассистент может подготовить текст возврата. Обычно он не должен сам отправлять деньги, если только правила не очень узкие и сумма не маленькая.
Рискованные действия должны проходить подтверждение. Возвраты, удаления, закрытие аккаунта, смена тарифа и сброс доступа — самые частые примеры. Система может собрать факты, заполнить форму и передать ее нужному человеку. Но финальную кнопку должен нажимать человек, когда на кону реальные деньги.
Возьмем простой support-кейс. Клиент говорит, что его списали дважды, и просит возврат. При широком доступе бот может сразу оформить возврат, закрыть тикет и оставить finance разбираться с ошибкой позже. При понятных правах доступа бот проверяет списание, готовит ответ, отмечает возможное дублирование платежа и просит сотрудника подтвердить возврат.
В этом и смысл скучного дизайна. Четкие роли, узкий доступ и шаги подтверждения не дают маленькой ошибке превратиться в проблему безопасности, потерю денег или недовольных клиентов.
Состояние решает, что система помнит
AI-ассистент может звучать умно и все равно ошибаться простыми и дорогими способами. Проблема часто не в модели. Она в состоянии: в фактах, которые ваша система хранит и которым может доверять позже.
В AI-first architecture состояние — это сохраненная правда о том, что произошло, что существует сейчас и что система должна делать дальше. Сюда входят статус заказа, статус аккаунта, запрос на возврат, история задач и последнее подтвержденное действие. Если эти факты живут только внутри чата, они ненадежны.
Временная память чата и сохраненные бизнес-записи — это не одно и то же. Память чата помогает ассистенту удерживать разговор связным несколько реплик подряд. Сохраненные записи показывают бизнесу, что действительно является правдой после завершения чата, закрытия браузера или передачи задачи другому сотруднику.
Это различие быстро становится важным. Support-бот может сказать: «Ваш заказ уже в пути», потому что раньше ему так сообщили. Но если в реальной записи заказа видно, что платеж не прошел, бот дает уверенный, но все равно неправильный ответ. То же самое происходит с заблокированными аккаунтами, отмененными подписками или просроченными согласованиями.
Отсутствие состояния также создает циклы. Клиент просит возврат, бот говорит, что открыл тикет, но ничего не сохраняется. Через десять минут клиент спрашивает снова, и бот открывает еще один тикет. Или он дважды задает один и тот же вопрос для подтверждения, потому что забыл первый ответ. Люди замечают это сразу.
История задач тоже важна. Если ассистент говорит sales-менеджеру, что follow-up письмо отправлено, должен быть способ проверить, когда именно оно ушло, какой draft использовался и ответил ли клиент.
Простое правило помогает: держите память разговора короткой, а бизнес-состояние — явным. Если человек ожидает, что компания что-то запомнит завтра, ваша система должна хранить это в реальном месте.
Границы помогают не дать проблемам расползтись
AI-система становится рискованной, когда каждая часть может трогать все остальное. Приложения, агенты и базы данных нуждаются в четких границах. У каждой части должна быть одна узкая задача, и у каждой задачи должны быть пределы.
Хорошо работает простое разделение. Приложение управляет пользовательскими сценариями и проверяет правила. Агент читает контекст, готовит ответы или предлагает действия. База данных хранит факты, которым остальная система может доверять. Если агент сделал плохое предположение, это предположение должно остановиться на уровне приложения, а не попасть в базу как будто это правда.
Одна плохая интеграция может быстро разнести ошибки. Представьте support-агента, который через одно широкое подключение может читать тикеты, обновлять billing, оформлять возвраты и отправлять письма. Неверный customer ID, ошибка в prompt или плохой вызов инструмента за несколько секунд могут изменить статус аккаунта, запустить возврат и отправить неверное сообщение. Это не модель создала весь ущерб сама по себе. Это сделали размытые границы.
Хорошая AI-first architecture держит права на запись в жестких рамках. Пусть агент читает больше, чем может менять. Пусть он готовит действия, а приложение проверяет их перед тем, как что-то станет необратимым.
Несколько правил предотвращают большинство ранних ошибок:
- Для каждого типа данных — один владелец.
- Пусть агенты предлагают действия, а не выполняют их без проверок.
- Передавайте только те поля, которые реально нужны другой системе.
- Блокируйте прямые записи в core tables из инструментов агента.
- Деньги, права доступа и удаление — только через явное подтверждение.
Команды часто передают слишком много данных, потому что сначала так проще. Но это создает скрытую связанность. Support-агенту может быть нужен customer ID, название тарифа, последние заказы и открытые проблемы. Обычно ему не нужны сырые платежные записи, внутренние заметки админов или полный доступ к базе данных. Если другая система не может объяснить, зачем ей какое-то поле, не отправляйте его.
Владение данными не менее важно, чем доступ к ним. Одна система должна владеть статусом подписки. Другая может читать его, кэшировать или показывать, но не должна придумывать вторую версию. То же самое касается действий. Если billing владеет возвратами, support-агент должен просить billing оформить возврат, а не писать строки возврата сам.
Четкие границы делают сбои маленькими и аудиты простыми. И они снижают startup technical risk еще до того, как вы вообще начнете выбирать модель.
Как разложить все это до начала разработки
Начинайте со списка действий, а не с характеристик модели. Риск обычно проявляется в том, что система может делать, а не в том, какая модель пишет текст.
Используйте простые глаголы: прочитать тикет, подготовить ответ, обновить запись клиента, отправить счет, удалить файл, запустить возврат. Когда вы записываете действия именно так, опасные варианты быстро становятся заметны.
Потом отметьте, какой доступ нужен каждому действию. Чтение данных и изменение данных — это разные риски. Один инструмент читает историю заказов, чтобы предложить ответ. Другой редактирует заказ, отправляет сообщение или списывает деньги.
Небольшой планировочной таблицы достаточно:
- какое действие может выполнить AI
- какие системы оно затрагивает
- только чтение это или еще и запись
- кто должен это подтвердить, если вообще должен
- как это откатить, если что-то пошло не так
Затем для каждого фрагмента данных укажите источник истины. Выберите одно место, которое владеет статусом клиента, одно — billing, одно — заметками support и так далее. Если память чат-бота говорит одно, а CRM — другое, команда потратит часы на исправление ошибок, которых можно было избежать.
Команды часто слишком рано переходят к тестированию prompt-ов и слишком поздно понимают, что никто не решил, где живет история разговора и какое приложение владеет финальной версией записи.
Следом идут правила подтверждения. Некоторые действия могут выполняться сами. Другие каждый раз требуют человека. Подготовка ответа в support может быть автоматической. Оформление возврата — скорее всего, нет.
Добавьте логи и шаги отката, пока система еще маленькая. Вам нужна запись того, что AI прочитал, что изменил, кто это подтвердил и как вернуть предыдущее состояние. Если человек может нажать «undo», и старое состояние тикета возвращается за секунды, маленькие ошибки остаются маленькими.
Модель выбирайте последней. Когда права доступа, состояние и границы уже понятны, выбор модели превращается в практический компромисс между ценой, скоростью и качеством.
Простой пример из support-команды
Support-бот часто начинает с узкой задачи: проверить заказ, ответить клиенту и подготовить ответ для сотрудника. Это звучит безобидно, пока бот не начинает видеть запросы на возврат, смену адреса и злые сообщения от клиентов, которым нужно действие прямо сейчас.
Представьте магазин, которому весь день задают одни и те же вопросы: «Где мой заказ?» «Могу ли я вернуть это?» «Почему с меня списали дважды?» Бот читает систему заказов, обновления по доставке и правила возврата компании, а затем готовит ответ, который сотрудник может отправить или отредактировать.
Права доступа решают, где бот останавливается. Он может прочитать заказ #4817, увидеть, что доставка не удалась, и подготовить: «Ваша посылка уже возвращается к нам. Я могу попросить сотрудника сегодня проверить возврат». Но сам он не должен нажимать кнопку возврата.
Это ограничение особенно важно в пограничных случаях. Возможно, заказ был оплачен подарочной картой. Возможно, проверка на fraud пометила платеж. Возможно, клиент уже получил замену на прошлой неделе. Человек-сотрудник может проверить эти детали и одобрить или отклонить возврат. Бот экономит время, но тратить деньги он не должен.
Состояние защищает бота от очевидных ошибок. Система должна сохранять номер заказа, текущий статус доставки, прошлые запросы на возврат и последний ответ, отправленный клиенту. Если ничего этого не хранить, бот может снова спросить номер заказа, пообещать возврат дважды или ответить по устаревшим данным доставки.
Четкая граница защищает остальной бизнес. Бот может вызывать небольшой сервис, который возвращает факты вроде «возврат разрешен», «возврат заблокирован» или «отправить на проверку человеком». Этот же сервис может создать запрос на возврат, который сотрудник потом одобрит.
Бот не должен напрямую редактировать billing-данные. Он не должен писать в ledger, менять строки invoice или помечать возврат как выплаченный. Если бот подготовит плохой ответ, один клиент получит путаное сообщение. Если он тронет billing без границы, ошибка уйдет дальше в бухгалтерию.
Вот что такое AI-first architecture на практике. Модель помогает с языком, а права доступа, состояние и границы решают, сколько вреда может принести неверный ответ.
Ошибки, которые команды совершают в начале
На раннем этапе команды часто переживают из-за модели и игнорируют всю обвязку вокруг нее. Это наоборот.
Большая часть раннего ущерба начинается тогда, когда один агент может читать CRM, отправлять email, оформлять возвраты, редактировать тикеты и трогать code repo с одним и тем же широким доступом. Support-бот с доступом к help desk, возвратам и тегам клиентов может неверно понять расплывчатый запрос, вызвать не тот инструмент и устроить хаос и в support, и в finance. Обычно это ошибка прав доступа раньше, чем ошибка модели.
Еще одна частая ошибка — считать историю чата системной записью. Чат — это неупорядоченная память, а не управление состоянием. Люди повторно запускают prompts, вставляют заметки и меняют инструкции прямо во время выполнения. Если единственный след одобрения или изменения клиента живет только в разговоре, никто не сможет это нормально проверить, повторить или исправить.
Команды также слишком рано смешивают тестовые и живые данные клиентов. Они запускают новый workflow на реальных аккаунтах, потому что построить безопасную sandbox кажется медленнее. Такой shortcut вызывает тихие проблемы: ложные уведомления, сломанные отчеты и приватные данные там, где их быть не должно.
Логи пропускают по той же причине. Процесс кажется маленьким, и команда думает, что сможет отслеживать его вручную. Это работает, пока инструмент не сломается в 2 часа ночи или клиент не спросит, почему вообще произошло то или иное действие. Вам нужна запись того, кто запустил процесс, какие данные видел агент, к каким инструментам он обращался и что вернул каждый шаг.
Еще есть tool creep. Команда продолжает добавлять интеграции быстрее, чем кто-либо успевает проверять доступ, владение и сценарии сбоев. Каждый новый инструмент ослабляет границы, если никто не режет scope. Пять узких инструментов с понятными правилами лучше, чем пятнадцать полу-проверенных.
Вот почему надежная AI-first architecture со стороны выглядит скучно. Скучные правила доступа, скучные записи состояния и скучные границы удерживают маленькую ошибку маленькой.
Короткий чеклист перед запуском
Команды часто неделями тестируют prompts и ответы модели, а потом торопятся с теми частями, которые и наносят реальный ущерб. Слабое правило доступа или неясный источник истины могут создать хаос гораздо быстрее, чем плохой ответ.
Перед запуском проверьте несколько базовых вещей:
- Ограничьте доступ по роли. Если support-инструменту нужен только статус заказа, не давайте ему полный billing-данные или admin-права.
- Для каждой бизнес-записи должен быть один дом. Если CRM владеет данными клиента, другие инструменты могут их читать или синхронизировать, но не должны тихо переписывать их заново.
- Поставьте человека перед рискованными действиями. Возвраты, правки контрактов, массовые письма и удаление аккаунтов должны ждать подтверждения.
- Ведите понятный журнал действий. Команда должна видеть, кто запустил действие, какой инструмент его выполнил, что изменилось и когда это произошло.
- Сделайте один понятный выключатель для каждой интеграции. Если синхронизация тикетов ломается, команда должна все равно работать в help desk, не ломая billing и отчеты.
Небольшая support-настройка хорошо показывает, почему это работает. Ассистент может читать прошлые тикеты и готовить ответ. Он может даже предлагать возврат. Но billing-система по-прежнему владеет записью о возврате, а финальное действие все равно подтверждает человек.
Если синхронизация CRM падает, команда продолжает отвечать клиентам, пока это одно подключение остается выключенным. Такая схема кажется менее магической, и именно этого вы и хотите. Когда что-то идет не так, команда может отследить это, остановить и исправить без гаданий, какой инструмент что изменил.
Что делать дальше
Выберите один workflow, который уже влияет на ежедневную работу. Очередь support, согласование счетов или follow-up по лидам подойдут. Реальная работа быстро показывает риск. Демо-задачи — нет.
Разложите весь процесс на одной странице, прежде чем добавлять новые модели или агентов. Пусть все будет просто. Кто запускает действие? Что система помнит? Где данные входят и где выходят? Эта простая схема расскажет вам об AI-first architecture больше, чем еще один раунд тестирования модели.
Хороший первый вариант должен включать четыре вещи:
- людей, ботов и инструменты, которые участвуют в процессе
- права доступа, которые получает каждый из них
- состояние, которое вы храните, обновляете или удаляете
- границы между внутренними системами и внешними сервисами
Затем честно проверьте слабые места. Если один агент может писать клиентам, редактировать записи и вызывать внешние инструменты, это слишком много власти в одном месте. Если состояние живет только в истории чата, вы потеряете контекст или сохраните неправильные данные. Если одна интеграция может упасть и заблокировать весь процесс, разделите ее до запуска.
Команды часто добавляют еще одну модель, когда первая версия кажется шаткой. Обычно это только увеличивает хаос. Сначала исправьте проектирование прав доступа, управление состоянием и границы интеграций. После этого выбор модели станет проще, потому что у системы появятся правила.
Если перед запуском вам нужен второй взгляд, ранний архитектурный review может сэкономить много переделок позже. Олег Сотников на oleg.is делает такую работу в формате Fractional CTO, с сильным фокусом на AI-first development, automation и lean production systems. Важен именно момент: гораздо дешевле исправить рискованные пробелы в правах доступа, состоянии и границах до того, как workflow разойдется по всей компании.


