Zustand stores vs state machines for workflow screens
Zustand stores vs state machines fit different workflow UI needs. Use rule count, retries, and failure paths to choose the simpler option.
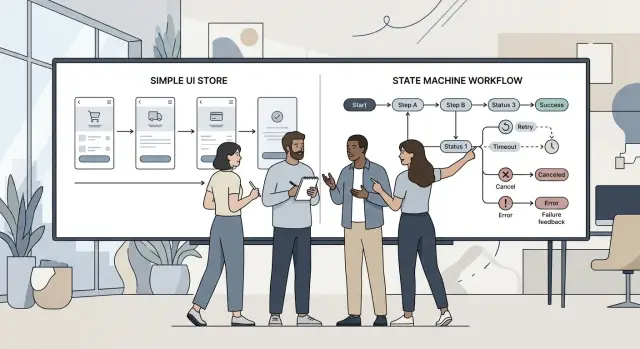
Table of Contents
Why this choice gets messy fast
Most workflow screens do not look hard at first. You have a form, a submit button, a loading state, and one response from the server. A simple store feels fine.
Then the rules pile up. Product adds retries. Support wants a manual override. The backend returns "try again later" instead of a clean success or failure. Someone asks for cancel, timeout handling, and a warning when the user leaves halfway through.
That is where the store versus machine question stops being a style debate and turns into a modeling problem. The issue is not state by itself. The issue is how many rules control that state, and how many failure paths branch off the main flow.
A store makes it easy to add one more flag, then another. Soon you have isLoading, isRetrying, hasTimedOut, canCancel, showError, and a few derived checks spread across components. The code still runs, but it no longer shows which combinations are valid. That gap matters.
Miss one state and the UI starts acting strangely. A screen can show stale success after a failed retry. A cancel button can stay active after the request already ended. An error banner can survive into the next attempt because nobody reset one field at the right moment.
Users do not call these "state modeling issues." They say the screen feels weird. They click once and nothing happens. They see the wrong message. They refresh because they do not trust what they see.
Teams usually react by patching the store. They add another condition, another reset, another small fix in the component. That works for a week. It rarely makes the flow clearer.
A refund screen shows the pattern well. At first it has three outcomes: pending, approved, rejected. Later it gets document upload, review hold, timeout, retry after a network failure, and cancel during upload. The original store still handles the easy path, which is why the mess sneaks up on teams. The broken parts live in the branches nobody mapped clearly.
What a simple store handles well
A plain Zustand store works well when a screen has only a few moving parts. If the user fills out a small form, taps save, and sees either success or one clear error, you usually do not need a state machine. The logic stays easy to read, and one developer can change it without tracing a long chain of events.
A profile edit modal is a good example. You might keep name, email, isOpen, isSaving, and saveError in one store, plus actions like updateField and saveProfile. That is easy to follow and quick to build.
Short lived UI flags also fit this model. A panel is open or closed. A request is loading or done. A toast is visible or hidden. When those flags barely affect each other, a store feels natural because each piece of state has one job.
Small local edits belong here too. Think about a settings page where a user changes a toggle, picks a tab, or edits a draft note before leaving the screen. If those edits do not branch into many paths, a store keeps the code close to the UI instead of turning it into a diagram.
Typical examples are a search filter panel with a few controls, a modal with one submit action, a checkout step with basic field validation, or a dashboard widget with loading and refresh state.
Speed matters as well. If one person owns the screen, a store lets that person set up the state in minutes, test the obvious cases, and move on. Early product work often needs that tradeoff.
The rule of thumb is intentionally plain. If you can explain the screen state on a sticky note, a store is probably enough. Once you need a whiteboard to track what can happen next, simple stores start losing their edge.
What state machines add
A state machine starts with a stricter idea: the screen can only be in one of a small number of named states. Instead of juggling booleans like isLoading, hasError, canRetry, and isLocked, you write down the states first: editing, submitting, waiting for review, failed, canceled, done.
That sounds fussy. It saves a lot of confusion once the flow grows past a few easy steps.
The naming matters because different people read the same screen in different ways. A designer thinks about what the user sees. An engineer thinks about events and side effects. A product manager thinks about rules. A machine gives them one shared map. When someone asks, "What happens if the user closes the modal after a failed submit and comes back later?", the team can point to the current state and the allowed next move instead of guessing.
The next benefit is stricter movement. In a store, almost any part of the app can set almost any value unless your team stays very disciplined. A state machine narrows that down. The flow moves through explicit transitions such as submit, fail, retry, cancel, or timeout. If a screen should never jump from "draft" straight to "approved," the machine blocks that jump by design.
This is where impossible states start to disappear. You stop seeing combinations like loading = true and error = true and success = true at the same time. You stop patching odd bugs with extra flags. The model carries the rule for you: one state now, one allowed next step from here.
For workflow UI state management, that clarity matters most when failure paths pile up. A happy path is easy to hold in your head. Add retries, partial saves, expired tokens, duplicate clicks, and user cancellation, and a plain store starts to feel slippery.
Teams often notice one benefit right away: code review gets easier. The logic reads more like a map and less like a pile of updates. State machines are not better for every screen. They are easier to trust when a flow has many rules and several ways to go wrong.
How to decide with rule count and failure paths
Start with the flow itself, not the tool. Write the user journey as plain steps from the first screen to the last confirmation. If the path reads like a short checklist, a store often works fine. If it already looks like a decision tree on paper, pay attention.
Next, count the rules on each step. A rule is anything that changes what the user can do or see: age limits, missing documents, expired codes, locked accounts, rate limits, admin review, or country based checks. One or two rules per step is usually manageable in a simple store. When several steps each carry four or five rules, the logic starts spreading across flags, effects, and conditionals.
Then write every failure path, not just the happy path. Teams often miss how much complexity hides in retry, cancel, timeout, partial save, refresh, and back button behavior. A flow with one error message is still simple. A flow where users can fail in different ways and recover in different ways is where a machine starts to make sense.
A quick test helps:
- List each step in order.
- Write the rules attached to that step.
- Add every fail, retry, cancel, and timeout branch.
- Mark states that cannot exist at the same time.
- Count how many branches reconnect later.
That fourth point matters more than most teams expect. If your UI can be "submitting" and "editable" at once, or "verified" and "needs more documents" because two async calls race each other, the model is already weak. A state machine forces you to say which states are valid and which ones are impossible.
Picture a five step account check. The user enters details, uploads an ID, waits for review, gets a result, then either finishes or retries. If review can time out, upload can fail, the user can cancel, support can request more files, and some countries need an extra check, a store can still hold the data. It struggles to explain the allowed transitions.
That is the practical line. Use a store when the flow is short, rules stay local, and failures are rare. Use a machine when branches multiply, invalid combinations appear, and recovery paths matter as much as the main path.
A real example: account verification flow
An account verification screen looks simple on day one. A user enters an email, gets a code, types it in, and picks a backup option if the email does not arrive. Most teams start with a small Zustand store, and that choice makes sense.
The store might hold fields like email, code, step, attemptsLeft, resendAt, and error. At first, you only switch between a few views: enter email, enter code, verified.
Then the real rules show up. The backend may take a few seconds to send the code. The user may ask for a resend. The code may expire after 10 minutes. Too many failed tries may lock the attempt. A backup option, such as a second email or support review, may reopen the flow later.
That is where a plain store starts to get awkward. Teams add flags like isSending, isWaiting, canResend, isExpired, isLocked, needsReview, and reviewReopened. None of those flags are wrong on their own. The problem is that they start to overlap.
The screen can end up in states like these:
- the resend timer reaches zero after the attempt is already locked
- support reopens the case, but an old timeout still marks the code as expired
- the UI shows an error banner and a success step at the same time
- a backup option appears before the first send attempt actually fails
A state machine handles the same flow more cleanly because it keeps states separate. "Waiting for code" is different from "expired." "Locked" is different from "under review." "Reopened" is a fresh state with its own rules, not just another boolean added to the pile.
With a machine, the screen moves through named states such as sending, waiting, resend ready, expired, locked, under review, reopened, and verified. Each event has a clear result. A timeout cannot quietly live beside success. A resend button cannot stay active inside a locked flow unless you allow it on purpose.
This is why workflow UI state management gets harder than it first looks. If the flow can wait, fail, retry, expire, and reopen later, a store often turns into a bag of flags. A machine gives those failure paths a shape you can reason about.
Signs your Zustand store is running out of room
A simple Zustand store often starts clean. You keep a few fields, add a couple of actions, and the screen feels easy to reason about. Then the workflow grows. A retry path appears, one step can expire, another can be skipped, and the store starts collecting small fixes.
One of the first warning signs is boolean creep. You add isLoading, then isRetrying, then hasError, then needsReview, then one more flag to stop a broken edge case. After a while, the screen can be "loading" and "failed" and "ready" in combinations that do not make sense. Tests usually catch this before people do, because mixed states create odd screens: a spinner stays on while an error banner shows, or the next button unlocks before the current check finishes.
Another sign is repeated rule checking. If several handlers ask the same questions - "is the code expired?", "did the user already submit?", "can they retry now?" - the rules no longer live in one clear place. They leak into click handlers, effects, API callbacks, and component guards. Small edits start feeling risky because one missed condition creates a branch nobody expected.
Teams usually feel the next symptom before they can name it: people get nervous about touching the flow. A developer changes one branch and worries about four others. Code review slows down. Nobody feels sure which states are valid anymore.
A store is probably running out of room when you see flags that exist only to block impossible combinations, actions that reset three or four unrelated fields, the same business rules copied into multiple handlers, bug reports that mention "sometimes" or "only after going back," and tests that pass on easy paths but fail on retries, timeouts, or partial success.
A simple rule helps. If your store mostly describes data, Zustand is often enough. If your store also has to describe allowed transitions, blocked transitions, and failure paths, you are already near the point where a machine is the better fit.
Mistakes teams make
Teams often pick the wrong tool because they judge the screen by how it starts, not by how it fails. A two step form with one submit button does not need a machine. A small Zustand store is usually enough when the user can move forward, go back, and see one or two error states.
The opposite mistake is just as common. A team starts with a simple store, then keeps patching it after rules spread across several screens. Soon one flag controls another flag, one action resets three fields, and nobody can say which states are valid. That is usually the point where the store stopped being simple, even if the code still looks short.
A lot of confusion starts when workflow rules live inside component effects. One screen redirects if a request fails. Another reopens a modal after a retry. A third clears local state when the user cancels. Each effect makes sense alone. Together they form a hidden workflow, and hidden workflows are hard to debug.
One missed step causes more trouble than teams expect: they never draw the retry and cancel paths. They map the happy path, then fill in the rest during development. That is where bugs show up. Users retry after a timeout. They close the tab and come back. They cancel halfway through, then restart with partial data still hanging around.
A quick check helps. Count how many business rules decide the next UI state, how many failure paths need their own response, how many screens can change the same workflow, and how often users can retry, cancel, pause, or resume.
If those counts stay low, a store is fine. If they keep growing, a machine usually gives you clearer limits and fewer surprises.
Another common mistake is mixing server state with UI flow state as if they were the same thing. Query results, cache freshness, and request status belong to server state tools. Things like "user is waiting for code," "user can retry in 30 seconds," or "verification is locked after three failures" belong to the workflow itself. When teams blend those together in one store, the UI starts reacting to network details instead of business rules.
Keep Zustand for local app state that stays simple. Move to a machine when the team needs an explicit map of what can happen next, especially when failure paths matter as much as the happy path.
Quick checks before you commit
Most bad state decisions happen before anyone writes code. The tool is rarely the first problem. The bigger problem is that the team has not made the workflow clear enough to see where it can break.
Start with paper or a whiteboard. If you cannot draw the full flow on one page, including the happy path and the ugly parts, slow down. That usually means the rules are still fuzzy, and fuzzy rules turn into messy stores, messy machines, or both.
A few checks make the choice easier:
- Count how many business rules change what the user can do next.
- Mark every point where one action can end in two or more outcomes.
- Write down what happens after an error: retry, rollback, wait, or manual review.
- Ask a teammate to read the flow and explain it back to you a week later.
That last check matters more than people think. If another developer cannot understand the rules next month, your future self will not enjoy this code either. A small Zustand store can stay clean when state changes are direct and easy to trace. Once actions branch in several directions, hidden assumptions pile up fast.
Errors are a strong signal. A login form with one error message is simple. An account verification flow with resend limits, expired tokens, fraud checks, and manual review is not. When failures have their own paths, not just their own messages, a state machine often gives you cleaner boundaries.
The same goes for actions that can lead to different next states. If clicking "Submit" always moves to one known result, a store may be enough. If "Submit" can move to success, pending review, partial success, blocked, or retry, you are already describing a machine whether you use one or not.
If the flow still feels vague after this exercise, do not code it yet. Review the workflow, tighten the rules, and remove guesswork first.
What to do next
Start on paper. A flow map tells you more than a new file in your codebase ever will. Draw the states a user can enter, the events that move them forward, and every place they can get stuck, retry, wait, or time out.
That exercise usually makes the choice clearer. In a small flow, a store feels natural because the state is mostly data plus a few UI flags. Once the map fills with rejection cases, cooldowns, manual review, partial success, and recovery steps, the problem stops being about storage and starts being about control.
A practical way to decide is simple: count distinct business rules, count failure and recovery paths separately, mark timers, polling, retries, and external callbacks, and circle any state combination that should never happen.
If your team keeps running into this on product heavy screens, it can help to get an outside review before the code gets harder to unwind. Oleg Sotnikov at oleg.is does that kind of Fractional CTO and product architecture work, especially for teams cleaning up messy workflows and moving toward clearer, more AI assisted development processes.
If you sketch an account verification flow and the branching already looks busy on paper, that is your answer. The workflow is asking for stronger rules, not more flags.
Frequently Asked Questions
When is a plain Zustand store enough?
Use Zustand when the screen has a short path, a few fields, and one clear submit result. A modal form, a small settings panel, or a simple save flow usually fits well because the state mostly tracks data and a couple of UI flags.
When should I use a state machine instead?
Switch when rules and failure paths start driving the screen more than the data does. If the flow includes retries, timeouts, cancel, manual review, reopen, or locked states, a machine gives you named states and clear moves between them.
Can I use Zustand and a state machine together?
Yes. That split often works well. Keep local form data or shared app data in Zustand, and let the machine control the workflow states like editing, submitting, failed, or done.
What are the warning signs that my store is getting messy?
Watch for boolean creep. If you keep adding flags like isLoading, isRetrying, isExpired, and needsReview, the store starts hiding invalid combinations instead of preventing them.
Do retries and timeouts change the tool choice?
They usually do. A retry path means the user can leave the happy path and come back later. Timeouts, cooldowns, and cancel actions add more branches, and those branches often break simple flag-based stores first.
Are state machines overkill for small forms?
Yes, for small screens they often are. If the user fills a form, submits once, and sees success or one error, a machine adds structure you may not need yet. Start simple when the rules stay simple.
How do I decide before I write code?
Write the flow on paper first. Count the steps, then count the business rules and every fail, retry, cancel, timeout, and resume path. If the sketch already looks like a decision tree, use a machine.
What kinds of bugs do state machines prevent?
They stop impossible screen states. You avoid bugs like showing success and error together, keeping a cancel button active after the request ends, or leaving an old timeout flag alive after a retry.
What should stay out of my workflow store?
Do not mix server state and workflow state into one bag. Query status, cache freshness, and fetched data belong with your server data tools, while user flow states like waiting for code or locked after three tries belong in the workflow model.
Can I start with Zustand and move to a machine later?
You can, but do it before the store turns into a pile of patches. Migration gets easier when you already know the real states, events, and blocked transitions. Map those first, then move the flow logic step by step.


