User correction loops for AI products that improve fast
User correction loops help AI teams catch real mistakes, sort edits by cause, and turn them into evals, prompts, and product rules.
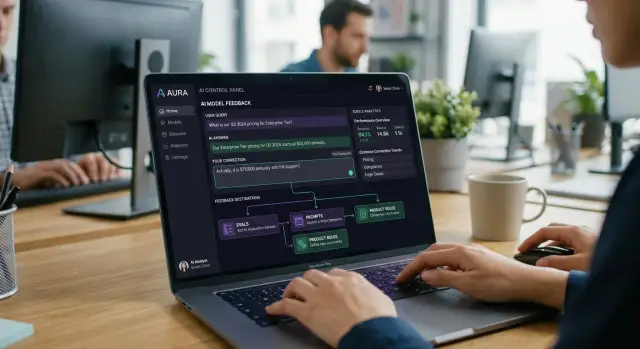
Table of Contents
Why dead feedback forms fail
People rarely stop to explain a bad AI answer in a form. They fix it and move on.
That moment matters most. The user is already showing you what went wrong by deleting a sentence, changing a name, or rewriting the whole output. If your product doesn't capture that edit, you lose the clearest signal you'll get.
Most teams ask for feedback too late. A survey shows up after the task, or a thumbs up or down sits in the corner. By then, the user has finished the job and forgotten the exact problem. Memory gets fuzzy fast, especially when the mistake was small but annoying.
A simple rating hides the reason behind the fix. Two users can give the same low score for completely different problems. One saw a wrong fact. Another got the right facts in the wrong format. A third had to remove a pushy sentence that didn't fit their tone. The score looks clean in a dashboard, but it doesn't tell the team what to change.
A concrete edit does. If users keep replacing formal language with plain language, that's a prompt issue. If they keep fixing the same field value, that's often a product rule or data problem. That's why user correction loops beat generic AI product feedback.
Dead forms fail for a simpler reason too: nobody owns them. Comments pile up in a queue, spreadsheet, or support tool and sit there until someone has spare time. Most teams never turn them into evals, prompt updates, or product rules.
The result is predictable. The model makes the same mistake next week. The user fixes it again. The team gets another low rating with no useful detail.
Good products learn at the moment of friction. They capture user edits, keep the original output next to the final version, and send that difference to the person or system that can fix it. That's how AI starts improving from real use instead of from a dead form.
What to capture at the moment of friction
A useful correction starts before the user forgets why they changed the answer. If someone rewrites a draft, fixes a field, or retries with different wording, save that moment. Good user correction loops depend on raw evidence, not vague comments sent hours later.
Keep the full before-and-after trail: the original prompt, the AI answer, and the final version the user changed it to. If you only store the edited result, your team loses the gap between what the model did and what the user actually needed.
Context matters just as much. Record the screen, page, or task where the edit happened. A wrong answer inside a support reply, a CRM note, or a contract summary can look similar in text while needing very different fixes.
In practice, a small set of fields is enough: the user's request, the AI response, the exact edit or replacement text, the task or screen where the edit happened, and one short reason in the user's own words.
That reason has to be fast. One plain question works better than a survey: "What was wrong?" or "Why did you change this?" People will answer if it takes three seconds. They'll skip it if you ask them to classify the mistake for you.
Keep the raw text next to a short internal label. The label helps your team sort patterns later, such as "wrong tone," "missed fact," or "bad format." The raw text keeps you honest. Labels alone often hide the real problem.
One more detail saves a lot of wasted work: record what happened on the next turn. If the user accepts the next answer after a retry, that usually points to a prompt or instruction issue. If they keep fixing the result by hand, you may need an eval, a product rule, or a stronger workflow.
This data should take almost no effort to collect. If users have to fill out a form, most of your best training signal disappears.
How to sort each correction by cause
If you want user correction loops to teach the right lesson, don't start with a long taxonomy. Start with four buckets and use them on every correction for a few weeks. A small set makes patterns easy to spot.
Most teams can sort almost every correction into one of these buckets:
- factual miss: the assistant didn't have the right information, used stale data, or pulled the wrong source
- prompt issue: the answer had enough information, but the tone, format, length, or wording was off
- product rule gap: the assistant needed a hard rule, step, or permission check outside the prompt
- one-off preference: the user wanted a personal style choice that shouldn't change the product for everyone
A factual miss usually points to retrieval or data. Check whether the system indexed the right documents, filtered the right records, or exposed fresh enough data. If a support bot says a refund takes 30 days when the policy changed last week, a new prompt won't fix that for long.
Prompt issues look different. The facts are mostly right, but the answer feels wrong. Maybe it rambles, sounds too stiff, ignores the requested format, or answers in five paragraphs when the user wanted two lines. Route those edits to prompt work, then add an eval that checks the same style constraint.
Some corrections aren't about the model at all. They're about boundaries. If the assistant should never send a discount above a set amount, skip legal language, or approve a customer change without a human, put that in product rules and workflow logic. Prompts help, but rules carry the weight.
One-off preferences need discipline. If one account manager likes bullets and another likes short paragraphs, don't retrain the product around both opinions. Mark those edits as personal unless you see the same request across many users.
Teams get into trouble when they treat every correction as a prompt problem. That leads to bloated prompts, weak evals, and the same bug coming back in a new form. Sorting by cause keeps the fix smaller and makes the next release easier to judge.
A simple routing flow your team can run
Start small. Pick one task where users already make lots of edits, such as rewriting AI email drafts or fixing extracted fields before they save a record. If you start with five tasks at once, your team will drown in messy feedback and guesswork.
Then wait a bit. Collect one full week of corrections before you change prompts, swap models, or add rules. A week usually gives you enough volume to spot repeats instead of reacting to one loud complaint.
Use a simple flow:
- Save the original output, the user edit, and the surrounding context.
- Tag each corrected case with one cause only.
- Group similar cases and count how often each group appears.
- Turn repeated cases into evals your team can rerun after every change.
- Fix the cause in the right place: prompt, product rule, retrieval, or workflow.
The one-cause rule matters more than it seems. If a case gets tagged as both a prompt issue and a policy failure, nobody knows who owns the fix. Pick the main cause first. If a second issue shows up later, handle it in a separate pass.
A realistic example from a sales assistant
A sales rep writes good emails, but she rarely sends the AI draft as-is. One afternoon, the assistant suggests a follow-up to a prospect who asked about pricing. The rep changes one sentence before sending: she adds that the annual plan gets a discount and asks whether the buyer wants monthly or annual billing.
On its own, that edit looks personal. Maybe she just prefers that wording. If the team only reads one edited draft, they can file it under style preference and move on.
The pattern shows up when the product stores the exact before-and-after change at send time. Over a week, five reps make the same fix in similar emails. The assistant keeps talking about price, but it skips the rule that annual plans need specific language and a direct billing choice.
That changes the diagnosis. The team no longer treats it as a random rewrite. They tag those corrections as a policy miss, not a tone issue, because the rep is restoring a business rule.
Now they can route the lesson to the right place. First, they add an eval with real examples: when a prospect asks about pricing, does the draft mention the annual plan correctly and ask the right follow-up question? Then they update the prompt and product logic so the assistant checks plan rules before it generates a reply.
They also add a check at send time. If a reply mentions pricing but skips the annual plan rule, the product blocks the draft and asks the rep to fix it. That feels stricter, but it saves back-and-forth and keeps reps from sending mixed messages.
This is what user correction loops look like when they work. A single edit is weak evidence. Ten similar edits, tied to the same step and customer context, can teach the system something clear: this is a rule, not taste.
Common mistakes that teach the wrong lesson
Teams often blame the prompt first. That feels easy, so they keep rewriting instructions and hope the model settles down. Many corrections don't start there. The model may have missed context, the UI may have hidden a needed field, or the product may have asked the user to fix something the system should have caught.
One loud complaint can send a team in the wrong direction too. A single angry user leaves a strong impression, but volume isn't the same as pattern. If you change prompts after one bad case, you can make the next ten answers worse. Wait for a small cluster of similar corrections, then inspect them together.
Personal taste causes trouble as well. Some users edit because they prefer a shorter tone, different phrasing, or a favorite format. That doesn't always mean the first answer failed. If you mix style preference with real failure, your evals get noisy and your product starts chasing whatever the last reviewer liked.
A simple rule helps: separate corrections into two buckets. Either the answer broke the task, facts, policy, or structure the product promised, or the answer was acceptable and the user just wanted a different style.
Those buckets shouldn't feed the same fix. Real failures may need a prompt change, a product rule, a retrieval fix, or an eval. Style edits may belong in user settings, templates, or saved preferences.
Another common mistake happens outside the model. Teams study the edited sentence and ignore the screen where the edit happened. That misses the cause. If users keep correcting dates after a summary step, maybe the date picker is confusing. If they rewrite outreach messages after selecting the wrong audience, maybe the form asked the wrong question first.
The worst data loss is simple: the team saves only the final edited text. Then nobody can compare the first answer with the changed one. You need the full chain - the user goal, the original output, the exact edits, and the screen state at that moment. Without that, you can't tell whether the model failed, the product nudged the user into extra work, or the user just had a different preference.
Bad lessons pile up quietly. After a few weeks, the product looks busier, but not smarter. Clean correction data keeps you from fixing the wrong thing.
A short checklist before each release
A release gets risky when your team changes prompts or rules without checking what users actually corrected. The fix doesn't start with a dashboard. It starts with a few habits that keep the signal clean.
If one of these checks fails, pause the change. Shipping fast is useful. Shipping a fix you can't measure usually creates a new mess.
- Save both versions of the interaction: the model's first answer and the user's final edit.
- Assign an owner to each cause bucket.
- Run an eval before and after every change, using the same test set both times.
- Ignore one-off style complaints unless they repeat.
- Review repeat edits every week.
This checklist keeps teams from learning the wrong lesson. Say users often rewrite a generated sales email. If the edits mostly add a missing price, that points to missing context or a product rule. If the edits mostly remove pushy language, that points to prompt tone. If both happen, treat them as two problems and test them separately.
The weekly review matters more than most teams think. Small errors feel harmless in isolation, but repeated edits often point to the part of the system that costs users the most time. Twenty seconds lost in one session doesn't sound serious. Across a few hundred sessions, it becomes a product issue.
A release is ready when you can answer three plain questions: what changed, why it changed, and how you'll know it worked. If you can't answer all three, wait one more day.
What to watch after you ship changes
User correction loops don't end at release. The useful part starts after the fix goes live, when you can see whether users need fewer rescues or just different ones.
One strong signal is repeat editing. If people keep fixing the same task in the same way, the lesson didn't stick. Maybe the prompt changed, but the product still sends weak context. Maybe the rule changed, but the model still guesses when it should ask a question.
Group every post-release failure by cause bucket and watch the count over time. Keep the buckets plain: bad prompt, missing context, wrong tool call, weak rule, or user interface issue. If one bucket keeps climbing, you know where to look first.
The acceptance gap tells you a lot. Compare first-try acceptance with second-try acceptance for the same task. If first-try acceptance goes up, the change likely helped. If second-try acceptance rises while first-try stays flat, users may still be doing repair work and saving the result themselves.
A small dashboard is enough. Track repeat edits per task type, failures by cause bucket, first-try acceptance rate, second-try acceptance rate, task time, and abandon rate.
Charts help, but charts can hide the real problem. Read a handful of raw cases every week. Look at the original request, the model output, the user edit, and what happened next. Ten messy examples often teach more than a clean graph.
Speed matters as much as output quality. Some changes make answers sound better but add one more turn, one more click, or one more review step. If the task takes longer, users will feel the drag even if your acceptance metric looks fine.
Trust breaks fast and returns slowly. Stop or roll back changes that add confident mistakes, hide uncertainty, or push users to double-check simple work. A slower task is annoying. A system that sounds sure and gets facts wrong is worse.
After each release, look for fewer repeated edits, fewer failures in the same bucket, and better first-try acceptance without extra time. If those numbers move in different directions, read the raw cases before you ship the next fix.
Next steps for a small team
Small teams usually have an edge here. Fewer people touch the product, so you can spot a bad pattern and fix it fast. The common mistake is trying to build user correction loops across the whole product at once. Start with one place where people already rewrite the AI often, such as a draft reply, a summary, or a suggested action.
Keep ownership simple. Give one person the routing job. They look at each correction and decide what caused it: a weak prompt, a missing product rule, an edge case for an eval, or a plain bug. Give a second person the eval job. They turn repeated corrections into a small test set and check whether each change actually helps.
A lightweight routine is enough. Capture the original output and the final user edit every time the user changes the answer. Add a short reason only if you can collect it without slowing the user down. Review a small batch once a week, even if the batch is tiny. Promote repeated patterns into evals, prompts, or product rules. Then check shipped fixes against the eval set before the next release.
That weekly review matters more than fancy tooling. If your team skips it for a few weeks, corrections pile up, context fades, and the feedback turns into noise. Twenty real edits reviewed on Friday beat two hundred ignored notes in a form nobody trusts.
Keep the loop small enough that people use it without being asked twice. If routing takes an hour a day, it's too big. If nobody can explain why a correction became a prompt change instead of a rule, it's too fuzzy.
If your team needs help setting up that flow, Oleg Sotnikov at oleg.is works with small companies on practical AI systems and can help map edits into evals, prompts, and product rules. A short outside review can save weeks of trial and error.
After a month, you should see the same mistakes less often. If you don't, shrink the scope again and make the loop tighter.


