Use case handlers for smaller, clearer backend code
Use case handlers give each backend action one clear home, so teams can cut service sprawl, name things plainly, and test rules without guesswork.
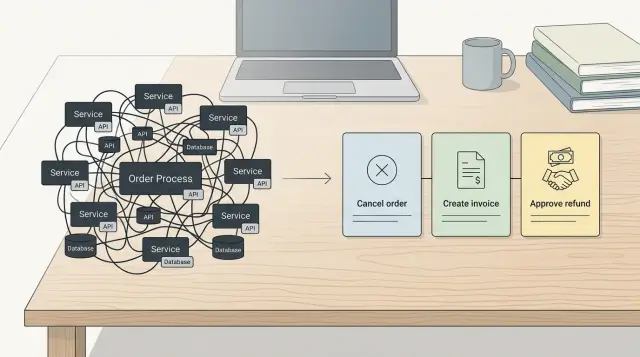
Table of Contents
Why service classes turn into a mess
A service class rarely starts out bad. It begins with one job, often something small like OrderService.cancel() or UserService.updateProfile(). Then a new rule shows up, then another, and the class becomes the default place for every extra condition.
That growth feels harmless at first. One more flag, one more dependency, one more helper call. A few months later, the same class checks permissions, updates records, sends emails, writes logs, touches billing, and decides which side effects should run.
The name often makes it worse. OrderService says almost nothing about what the code actually does. When a class has a generic name, people keep adding behavior because almost any change seems to belong there. A vague name creates vague boundaries.
The real trouble starts when the same rule appears in three places. A controller blocks one case early. The service blocks another case later. A helper adds its own version because someone needed the same check in a background job. Now the rule exists, but nobody can point to one clear home for it.
That is how application rules get lost. A developer needs to add a new condition for canceled orders, opens the code, and finds controller logic, service logic, repository checks, and a helper called validateOrderState(). Each piece looks half right. None feels safe to change.
Teams react by coding defensively. They copy checks instead of moving them. They add a boolean because they do not trust the old flow. Dependencies spread for the same reason. A class that once needed a database client now also pulls in billing, notifications, audit logging, and feature flags.
The result is not just bigger files. Decisions slow down. People hesitate because they cannot tell where one action begins and another ends. That is usually the point where use case handlers start to look a lot cleaner.
What a use case handler does
A use case handler owns one action that a user or system wants to complete. That action is narrow and clear: create an invoice, reset a password, approve a refund, invite a team member. One class, one job.
That small scope changes how the code reads. Instead of opening a vague UserService or OrderManager and guessing where the rule lives, you open a class whose name tells you the outcome. InviteTeamMember is easier to trust than TeamService because the class name already tells you why it exists.
Inputs and outputs stay easier to follow too. A handler usually takes a small command or request object, does the work, and returns a simple result. When someone asks, "What happens when a customer changes their plan?" you can trace that flow without jumping through five generic classes.
Why this feels simpler in practice
Business rules stay close to the action instead of getting spread across helpers, services, and controllers. That matters more than most teams admit. When rules live next to the use case, you can change them with less fear.
A good handler makes four things obvious: what action is happening, what data it needs, which rules must pass, and what result it returns. If a developer can read one file and answer those questions, the code is probably in decent shape.
This style also makes dependency cleanup easier. A handler depends on the few things it needs for that action, not every tool the whole module ever used. Oleg Sotnikov often works this way at the architecture level too: cut waste, shrink the moving parts, and keep each piece small enough that its purpose stays obvious.
When a backend uses use case handlers well, the code stops looking like a bucket of utility methods and starts looking like a list of real business actions.
How to spot service sprawl
Service sprawl usually starts with harmless names. You add OrderService, then PaymentService, then UserService, and each one keeps absorbing work. After a while, the class name tells you almost nothing.
A bloated service often mixes several jobs in one place. It loads data, checks permissions, applies business rules, calls other services, sends emails, and writes logs. If a class called OrderService can cancel an order, refund a payment, restock items, notify support, and update analytics, the problem is not size alone. Nobody can tell where one rule starts and another ends.
A few warning signs show up again and again. Methods bounce between services and then call back into the first one. A small rule change forces edits in controllers, services, and repository code. Tests need mocks for half the app just to cover one action. Review comments keep asking where a rule lives. New developers read three files before they trust a single change.
Circular calls are a strong warning. If OrderService calls PaymentService, which calls InventoryService, which then calls OrderService again, the code stops reading like a business action and starts reading like plumbing.
Another clue is fear. When developers avoid touching a class because every edit breaks something far away, the service has become a grab bag. Tests usually show this first. A simple case like "cancel one order" should not need fake payment gateways, mailers, stock updates, feature flags, and user sessions unless the action truly needs them.
Names tell on you too. Methods like process(), handle(), executeTask(), or updateEverything() hide intent. If the code cannot answer "where does order cancellation happen?" with a single file, service sprawl has already arrived.
How to move one flow step by step
Do not start with a grand rewrite. Pick one action that people hit every day. Frequent code paths reveal problems quickly and give you useful feedback. A good candidate is something plain and common, like changing a billing email, approving a request, or creating a draft.
Then write the rules in normal sentences before you touch the code. Keep them boring and direct: who can do it, what must already exist, what changes, and which side effects must happen after the change. If you cannot explain the flow without class names, the code already hides too much.
For most flows, the rule list is short. The user must have permission. The record must exist and be in the right state. The system changes one clear piece of data. Then it records an audit entry or sends a follow-up event. Finally, it returns one simple result.
Now create one handler with one entry method. Name it after the action, not after a vague role. ChangeBillingEmailHandler.handle(...) tells the truth faster than AccountService.update(...).
Move the flow into that handler in small cuts. Start with the checks. Then move the state change. After that, move side effects such as email, logging, or event publishing. Keep the order easy to follow. When a teammate opens the file, they should see the whole action from top to bottom without jumping through generic services.
Do not rip out the old code on day one. Let the old service stay in place for a while and make it call the new handler through the same public method. That keeps callers stable while you prove the new path works. It is a little ugly, but short-term duplication is cheaper than a broken rewrite.
Tests decide when you can cut over. Add or update tests around behavior, not around the old class shape. When the handler passes those tests and the old entry point only forwards the call, switch the callers, remove the wrapper, and delete the dead branches. That is usually enough to clean up one messy flow without turning it into a team-wide argument.
A simple example: cancel an order
Imagine a customer asks to cancel an order ten minutes after paying. The package has not shipped yet. This should be easy, but it often gets buried inside a huge OrderService with vague methods like updateOrder() or handleChange().
A use case handler keeps that flow in one place. CancelOrderHandler has one job: decide whether cancellation is allowed, make the change, and return a clear result.
The checks read like plain business rules. Is the order still in a state that allows cancellation? Was the payment already captured? Is the request still inside the allowed time window? If any answer is no, the handler stops and returns the reason.
If all checks pass, the handler updates the order status to cancelled, records who asked for it, and starts the refund. That refund might run right away or go to a payment worker, but the handler still owns the decision to start it.
CancelOrderHandler(orderId, customerId, requestedAt):
load order
if order not found -> return NotFound
if order already cancelled -> return AlreadyCancelled
if order already shipped -> return TooLate
if requestedAt is outside cancellation window -> return TooLate
if payment exists -> start refund
mark order as cancelled
return Cancelled
The API does not need to inspect half the system to guess what happened. It gets one result and maps it to a response: Cancelled means show success, TooLate means shipping already started or the window closed, AlreadyCancelled means show the current status, and NotFound means return a missing order response.
That is the appeal of use case handlers. A developer can open one file and see the full rule set for one user action. The names are plain, the dependencies stay local, and the API layer stays thin.
Names that make sense on sight
Bad names make small code feel bigger than it is. When someone opens a file called OrderService, they still have to read half the class to learn what it does. A name like CancelOrder tells the story before the first line of code.
The name should match the action people already say out loud in planning, support chats, and bug reports. Teams say "cancel the order," "send the invoice," and "approve the refund." They almost never say "run the order service."
Plain verbs keep code honest. They also make reviews faster, because the reader can compare the class name with the rule inside it. If CancelOrder also sends marketing email, updates warehouse stock, and recalculates loyalty points, the mismatch is obvious.
A few naming swaps clean things up fast: OrderService becomes CancelOrder, PaymentProcessor becomes CapturePayment, UserManager becomes SuspendUser, and NotificationUtility becomes SendPasswordResetEmail.
Helper names need the same treatment. OrderCancellationPolicy is clear if it checks whether an order can be canceled. DateHelper is not clear, because it could hide anything.
Words like Manager, Processor, Handler, and Utility often blur the real job. Sometimes Handler is fine if your project uses it for every use case. Even then, the action should carry the meaning. CancelOrderHandler is still better than OrderHandler.
A simple test helps. Say the name in a sentence you would use with a teammate: "The bug is probably in CancelOrder." If that sounds natural, the name is probably good. If you would never say "Check OrderManager" in a real discussion, the code is asking readers to translate vague labels into real actions.
Clear names do not fix bad design on their own. They do make bad design easier to spot, and that is usually where the cleanup starts.
How to trim dependencies
Most bloated service classes have the same smell: one constructor, ten arguments, and half of them sit there just in case. A use case handler should take only what one action needs. If a cancel-order flow touches orders, payments, and time, pass those three things. Leave email, search indexing, and reporting out until the handler truly uses them.
A harsh test works well here: remove one dependency and ask whether the handler can still do its job. If the answer is yes, cut it. Small constructors force honest code. They also make tests shorter because you stop mocking objects that never take part in the action.
Split reads from writes as soon as you can. Reading an order summary for a screen and canceling an order are different jobs. The screen query can use a read model shaped for display. The cancel action can use the write side with the checks and updates it needs. When one class tries to do both, dependencies pile up fast.
Shared application rules create the next mess. Teams often keep them inside a large service because many flows need them. Move those rules into tiny policy objects instead. A CancellationPolicy can answer one question: "Can this order be canceled right now?" The handler calls the policy, then performs the action. You get reuse without dragging a whole service into every flow.
One habit causes more damage than it seems: passing a giant service container around. It feels convenient because every tool is available. It also hides the real cost of each action. A handler that accepts AppServices tells you nothing. A handler that accepts OrderRepo, PaymentGateway, Clock, and CancellationPolicy tells you almost everything on sight.
A quick check helps when trimming dependencies. Ask whether the handler calls the dependency directly, whether it supports the single action in the class, whether a policy object should own that rule instead, whether it is only needed for reads, and whether removing it would make tests simpler. If a dependency fails two of those checks, cut it.
Backend code gets smaller when each action owns less. That is why use case handlers stay readable as the codebase grows.
Mistakes that make the rewrite harder
A rewrite goes off track when the code changes shape, but not meaning. Teams move files from services/ to use-cases/, keep names like OrderService, and call it done. The dependencies stay tangled, the methods stay vague, and nobody can tell where a rule actually lives.
Another mistake is rebuilding the old layer in smaller boxes. A handler should do one job, such as CancelOrder or ApproveRefund. If each handler grows its own helper classes, shared coordinators, and generic processors, you made the same mess again with shorter files.
Hidden database writes make this worse fast. A helper called prepareOrder() sounds harmless. If it also updates stock, saves a refund record, and writes an audit row, the next reader has no chance. Keep writes close to the use case. When someone opens the handler, they should see what changes and in what order.
Teams also mix technical concerns into the same class as business rules. Then one file decides whether a refund is allowed, retries a network call, writes logs, and reports metrics. That class gets hard to test because every change touches everything.
The split is simpler than it sounds. Put the rule in the handler. Put retries next to the external call that can fail. Put logging and metrics around the handler, not inside every branch. Keep helper methods small and boring.
The biggest mistake is rewriting the whole backend at once. That looks neat on a planning board and awful in real life. You lose a clear before-and-after view, reviews get messy, and bugs spread across unrelated flows.
Pick one path and finish it. CancelOrder is a good example because it usually touches rules, writes, and outside systems. Move that flow, keep the names direct, and stop when the result reads better than before. If the new handler still hides side effects or pulls in half the codebase, pause and trim again before you copy the pattern anywhere else.
Quick checks before you merge
A rewrite can look tidy in the diff and still leave the same old mess behind. Before you merge, read the new code like a stranger would. If the flow still needs guesswork, the cleanup is not finished.
A useful review is short. Read the class name without opening the file. A new teammate should guess the job right away. Run one test that covers the happy path from the entry point to the final saved result. Check whether error names match real cases people understand, such as OrderAlreadyShipped or PaymentProviderUnavailable. See whether you can delete one old service after the change. Count constructor dependencies too. A shorter list usually means the class owns one job.
One example makes this concrete. Suppose you replaced OrderService.cancel() with a CancelOrder handler. After the change, the handler should depend on the order store, a payment gateway if refunds matter, and maybe a clock or event bus. It should not also need pricing rules, email templates, shipping calculators, and admin search tools just because the old service used them.
This review also catches fake progress. Teams often rename service classes to use case handlers but keep the same calls, the same shared helpers, and the same hidden rules. That rewrite costs time and changes little.
Merge when the job is obvious, one full test proves the main flow, error names sound real, at least one old piece can disappear, and the dependency list got shorter. If you still need three old services to cancel one order, keep cutting.
What to do next
Pick one backend flow your team touches every week. Do not start with the messiest part of the codebase. Start with a flow people know well, such as canceling an order, issuing a refund, or sending an invoice, and rewrite that flow with clear use case handlers.
Then measure something small and real. Track how long reviewers spend on the pull request, how many files they open, and how many follow-up questions they ask. If review time drops from 35 minutes to 15, the team will trust the change more than they would after a long architecture debate.
A short team rule helps more than a long document: name handlers after the action they perform, give each handler one job, keep business checks in the handler instead of a generic service, and inject only the dependencies that flow actually uses.
Use that rule for new work first. Teams often try to fix old code everywhere, get tired, and stop halfway. A better approach is simpler: every new feature and every changed flow follows the new style, while old code changes only when someone already needs to touch it.
That also keeps arguments short. When a developer adds a new generic service class, the team can ask one direct question: "What use case does this code handle?" If the answer is vague, the name is probably vague too.
If your team feels stuck between a full rewrite and doing nothing, a second opinion can help. Oleg Sotnikov at oleg.is often works with startups and small teams as a Fractional CTO, reviewing architecture one flow at a time and cutting unnecessary complexity before it spreads.
You do not need a grand cleanup plan. One common flow, one naming rule, and one consistent pattern for new code is enough to change the shape of a backend.
Frequently Asked Questions
How do I know a service class has become too big?
A service class turns messy when it keeps absorbing unrelated work. If one class checks rules, saves data, sends emails, starts refunds, and writes logs, people stop knowing where a change belongs.
When should I use a use case handler instead of a service?
Use case handlers work best when one action has clear rules and a clear result. Flows like canceling an order, approving a refund, or inviting a user usually fit well because each one has one outcome people can name.
Where should business rules live?
Keep the rules close to the action that uses them. Put the checks inside the use case handler, and move shared decisions into small policy objects only when several flows truly need the same rule.
What is the safest way to replace one service method?
Start with one common flow that your team understands well. Write the rules in plain sentences, build one action-focused class, let the old service call it for a while, and switch callers after tests prove the new path works.
How should I name a use case handler?
Name the class after the action it performs. CancelOrder, ApproveRefund, and SendInvoice tell the truth faster than OrderService or PaymentManager because the reader knows the goal before reading the code.
How do I cut down dependencies in a handler?
Give the handler only what that one action needs. If canceling an order only needs orders, payments, and time, inject those things and leave everything else out. Smaller constructors usually mean clearer code and simpler tests.
Should controllers still contain some business logic?
Keep controllers thin. Let the controller parse the request, call one use case handler, and map the result to an HTTP response. Do not spread business checks across the controller and the handler.
What should I test after moving code into a handler?
Test behavior from the entry point of the action. Cover the normal path and the real failure cases, such as order not found, already canceled, or too late to cancel. Do not tie tests to the old service shape.
What do I do with logic that several flows share?
Do not force every shared rule into one giant service. If several actions need the same decision, extract a small object with one clear job, such as checking whether an order can be canceled right now.
Do I need to rewrite every service class?
No. If a small service still owns one clear action and stays easy to read, you can keep it. Change the parts that hide rules, grow too many dependencies, or make people afraid to edit them.


