Transaction boundaries before message queues: commit rules
Transaction boundaries before message queues decide which writes must succeed together, which work can wait, and how to avoid broken orders and stale jobs.
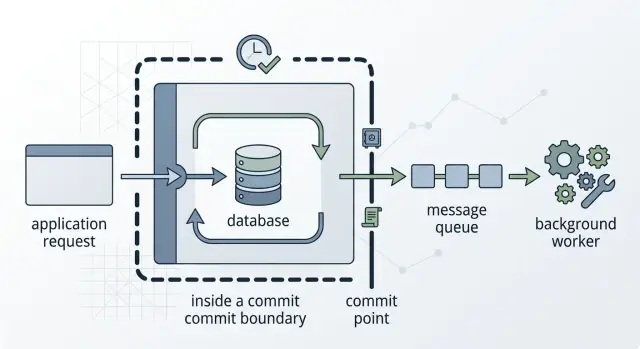
Table of Contents
Why this breaks so often
Teams usually add queues and background workers before they decide where the real commit line is.
A request saves one row, plans to save another, publishes an event, and returns success. That often looks fine in local testing. It starts to fail when one step is slow, crashes, or runs out of order.
The trouble lives in the gaps. A request might create an order record, then fail before it writes the order items. A worker may see the new order ID right away and look for data that is still missing. One part of the system says "done" while another says "not found."
That is why the boundary between a database commit and message publishing matters so much. If your write and your event do not follow one clear rule, you can send "order paid" even though the payment write rolls back a second later. The event is already out. Other systems trust it and act on something that never really committed.
Users do not experience this as a technical bug. They see a success screen, then support finds records that disagree. One table shows a new account. Another has no profile. A confirmation email went out, but shipping never started. Small timing mistakes turn into expensive business problems.
Production makes all of this worse. Networks time out. Workers pick up the same job twice. App servers crash after one write and before the next. None of that looks dramatic in code review, which is exactly why teams miss it.
A lot of startup code drifts into this shape one small change at a time. One person adds a save. Another adds a worker. Someone else adds an event for analytics or billing. Each step looks reasonable on its own. The full flow ends up with no single source of truth for what must commit together, and the data starts to drift.
Draw the commit line first
Start with one user action, not the queue. A customer clicks "Place order," a manager approves a refund, or a user changes a password. Ask one plain question: what facts must be true before you can safely return success?
Those facts define the commit line. If the app says "order placed," the database should already contain the order, the final price, and any stock reservation you promised right away. Put only those row changes inside one transaction.
This is where teams need to be strict. Many bugs appear when people mix must-have facts with side effects that can wait. Sending an email, updating a cache, writing analytics, and posting to a queue can all be related to the order, but they do not need the same guarantee. If any of them fails, the user should still have a real order in the database.
Pick one record as the source of truth for the action. In many flows, that is the main order, invoice, or account row. Give it a clear status and let other records point back to it. Then workers can read that record later and decide what still needs to happen.
Take a simple payment flow. Inside the transaction, create the order, store the final total, mark payment as received if you already have that confirmation, and reserve stock if your product promises that stock is held now. After the transaction commits, send the receipt email, refresh cache entries, write analytics, and publish an event for shipping.
That split keeps failures boring. If email stalls or the queue is down for five minutes, support can still open the order and see the truth. That is the whole point: commit the facts people depend on, then let workers handle the rest.
What must commit together
A transaction should hold only the facts that decide whether the request succeeded. If those facts split across separate commits, your system can tell two different stories at once.
Start with the status change that defines the result. If an order moved from "pending" to "confirmed," that status should commit with the rows that make the confirmation real.
That usually includes the records that prevent double booking or double spending. Think seat reservations, inventory deductions, ledger entries, or a unique claim on a coupon code. If the status says "done" but those guard rows are missing, the work is not really done.
Duplicate requests belong in the same conversation. If a client retries because the network timed out, your app needs an idempotency record in the same transaction. That gives you a clear answer to "did we already handle this request?" Without it, a harmless retry can create a second order, second charge, or second reservation.
If you plan to publish an event later, add an outbox row in that same commit. That is the safe form of the outbox pattern. Your app commits the business result and the instruction to publish later together. A worker can read the outbox after commit and retry until it succeeds.
In practice, a good transaction often includes just four things:
- The row whose status defines success.
- The rows that prevent duplicate use of money, stock, seats, or credits.
- The idempotency record for the request.
- The outbox row for later event publishing.
Keep slow network calls out of that transaction. Do not wait on email, a queue broker, a payment API, or a webhook while database locks are still open. That makes failures harder to reason about and increases the chance of contention.
The rule is simple: commit the truth first, then tell the outside world. If the commit finishes, retries are safe. If the commit fails, no worker should act like it succeeded.
What can wait until after commit
If the database row is correct and the user can move on, the rest can usually happen later. That includes work that informs people, speeds up reads, or feeds other systems.
A receipt email is the obvious example. If a customer places an order, the order and payment record need to commit together. The email does not. If your mail provider slows down for 20 seconds, you should still keep the order and send the receipt later.
Search index updates usually belong after commit too. Your main database is the source of truth. Search helps people find data faster, but a stale result for a minute is usually better than a failed checkout or a broken signup. The same logic applies to cache refreshes. If the cache misses for a while, the app can read from the database and rebuild it.
Webhooks should also wait. Another company's endpoint is outside your control. If their outage becomes part of your commit path, their downtime becomes your downtime. Record the event, commit your own data, and let a worker deliver the webhook with retries and backoff.
Reporting and analytics almost never belong in the main transaction. Dashboards and counters help later. They should not decide whether an order exists, whether a refund was stored, or whether an account was created.
A good rule of thumb is this: if users would still want to keep the successful action when this side effect fails, move that side effect after commit. The outbox pattern is a clean way to do it. Commit the business data and the outgoing event together, then let a worker handle email, webhooks, analytics, search updates, or cache refreshes once the commit is done.
Use a five-step test
Teams often make this harder than it is. Most arguments about commit boundaries happen because people mix the business action with the extra work around it.
A quick test clears that up.
- Write the action as one short sentence. "Customer places an order" or "admin approves a refund" is enough. If you need three sentences, the transaction is probably trying to do too much.
- Mark the rows that make the action true. For an order, that might be the order row, payment status, and inventory reservation. If those rows commit, the action happened. If one is missing, it did not.
- Pull slow side effects out of the transaction. Emails, webhooks, search indexing, cache warming, PDF generation, and calls to other services should wait.
- Add an outbox row in the same commit for anything that must happen next. That gives your worker a durable "do this later" record instead of a guess.
- Test the ugliest crash point. Commit the transaction, then pretend the app dies before it sends the message, email, or webhook. If the system can recover by reading the outbox and retrying, the boundary is solid. If work disappears, the design still has a hole.
This test forces one useful question: what must be true the moment the commit succeeds?
If you cannot answer that in plain language, stop before adding queues or workers. Draw the line again, make it smaller, and keep only the rows that make the user action real.
A simple order flow
An order flow gets much easier to reason about when you draw one hard line at the database commit. Everything that makes the purchase real should cross that line together. Everything else can wait.
Picture a customer clicking Buy in a small online store. The app opens one transaction and writes three records inside it: the order, the stock change, and an outbox row that says "send receipt for order 4821." Then it commits.
That commit is the moment the business action becomes true. Before it, nothing counts. After it, the order exists, the stock is reduced, and the system has a durable note that follow-up work still needs to run.
The flow is short:
- The customer submits the order.
- The app saves the order, stock update, and outbox row in one transaction.
- The database commits.
- A worker reads the outbox and sends the receipt.
If you send the email first, or start a worker before the commit, you can end up with a receipt for an order that never finished. Customers notice that fast.
The outbox pattern fixes this without adding much complexity. The worker does not decide whether the order is real. The commit already decided that. The worker handles only work that can happen later.
Now imagine the email provider times out. That is annoying, but it is a smaller problem. The order still stands because the business data already committed. The worker can retry later when the mail service recovers.
That is the whole point. Order data and stock changes need one database commit. Sending a receipt does not. When teams mix those up, they create support tickets, duplicate sends, and strange stock counts.
Where queues and workers fit
Queues belong after the database commit, not inside the part that decides whether the main change is valid. If your app creates a message from in-memory data and the transaction rolls back, the queue still says the change happened. Now the database and the worker disagree.
A safer setup writes committed data first, then publishes from that saved state. The outbox pattern does exactly that. The app saves the main record and an outbox row in the same transaction. If the transaction fails, both disappear. If it commits, a sender process can publish the event later without guessing what happened.
The practical flow is straightforward. Save the main record and any required child records. Save an outbox entry in the same transaction. Commit. Then let a sender read the outbox and push a job or event.
That last step matters more than it seems. Workers should read the final saved state, not trust whatever object the app had in memory a few milliseconds earlier. A message can carry the record ID, event type, and maybe a version number. The worker can fetch the real row and act on what actually committed.
Each job also needs a stable ID. Use the outbox ID, or combine the record ID with the task type. That gives you safe retries. If a worker crashes after sending an email or calling a payment gateway, you can retry the side effect without rewriting the main order, invoice, or user record.
Keep workers narrow. One worker sends the receipt. Another syncs data to a billing system. Another writes an audit entry. Small workers fail in smaller ways, and they are easier to retry, monitor, and replace.
Mistakes that split your data
Most consistency bugs are not queue bugs. They are commit design bugs.
One common mistake is publishing to the queue before the transaction commits. The worker wakes up fast, looks for the new order or payment row, and finds nothing or half-written data. Now you have an event that says "done" while the database still says "maybe." If you need to publish after commit, write an outbox row in the same transaction and send it only after the commit succeeds.
Another mistake is holding the transaction open while the app waits on an API call. A payment gateway, email service, or fraud check can take seconds. During that time, locks stay open, other requests pile up, and timeouts become more likely. Keep the transaction short. Commit your local facts first, then call outside services in a separate step when that makes sense.
Teams also split data when they shove every follow-up task into the same commit. Creating the order and reserving stock may belong together. Sending a receipt, updating analytics, and pushing a CRM event usually do not. When you force all of that into one transaction, one slow side task can stall the whole request.
Retries can turn a small design flaw into an expensive one. If a worker retries a charge or an email without an idempotency check, customers get billed twice or receive the same message three times. Every retry path needs a stable ID, a clear status, and one place to record "already done."
Workers also fail in quieter ways. Some read a partial row and try to guess the missing state. That guesswork spreads bugs. A worker should either see enough committed data to act with confidence or wait until it does.
A simple smell test helps. If the worker needs to guess, the commit happened too early. If the transaction waits on the network, it is too long. If retries can repeat money movement or messages, the job is not safe. If the queue can run before the row exists, the flow can split.
Quick checks before you add a worker
A background worker only helps after you decide what must already be true when the request ends. Most consistency bugs start earlier than the queue.
Start with the rows, not the worker. If a user places an order, maybe the order row and the inventory reservation must change in one transaction. The email log does not. If you cannot point to the exact records that rise or fall together, the commit line is still fuzzy.
Then look at retries. Workers retry because servers crash, networks time out, and jobs get picked up twice. If the same job can create a second refund, ship a second package, or subtract stock again, it is not ready. You need idempotent behavior or at least a clear guard in the database.
Ask one more question: can you rebuild the event from committed data alone? If the event depends on an in-memory object that disappears when the process dies, you still have a gap. That is why the outbox pattern is often the safer choice. You commit the business data and the event record together, then publish from that committed state.
Lag matters too. If the worker is late by five minutes, the user should still see the correct result on the screen. A welcome email can wait. Analytics can wait. Search indexing can wait. Account balance, access rights, and stock counts usually cannot.
One crash test tells you a lot: save the main transaction, fail before publish, kill the process, restart the worker path, and see whether the system can recover without guessing. If that test leaves missing events, duplicate work, or a user-facing lie, stop and redraw the boundary.
Next steps for your team
Start with one user flow your team touches every week, such as order placement, invoice creation, or account signup. Put it on paper. Draw a line between the work that must commit in one database transaction and the work that can happen later.
That exercise settles a lot of arguments fast. Teams often talk about queues first, but the commit rule comes first. If the line is fuzzy, retries and worker crashes will turn a small design mistake into bad data.
A good first pass is simple. Pick one flow and name the exact rows that must exist together after commit. Mark anything that sends email, calls another service, or updates search as after-commit work. If your request handler publishes events directly, move that write into an outbox table stored in the same transaction. Then write one short rule in your team docs that says what stays inside the transaction for that flow.
Keep the rule short enough that a new engineer can follow it without asking three people. For example: "Create the order, reserve stock, and write the outbox record in one transaction. Send the confirmation email after commit."
Then test the rule under failure, not just in happy-path demos. Kill the app after the database commit but before the worker runs. Retry the same job twice. Force a timeout during event publishing. Your team should know exactly what happens in each case.
This does not need a long process. One whiteboard session, one written rule, and one failure drill can clean up a messy flow quickly. After that, repeat the same review for the next flow.
If you want a second set of eyes before adding more queues and workers, Oleg Sotnikov at oleg.is helps startups and small teams as a Fractional CTO with architecture, infrastructure, and practical AI-assisted development. A short review is usually cheaper than cleaning up split data after release.
Frequently Asked Questions
What is a transaction boundary?
It is the point where your app decides, "this action is real now." Put the rows that make the user action true inside one database transaction, commit them together, and only then let emails, events, or workers run.
What should commit together in an order flow?
Commit the rows that define success. For an order, that usually means the order record, the final price or payment state you already know, any stock reservation you promise right away, and the idempotency and outbox records if you use them.
What can wait until after the commit?
Anything the user can live without for a few minutes can wait. Receipt emails, cache refreshes, search indexing, analytics, and webhooks usually belong after commit because the order still counts even if those steps fail for a while.
Why is publishing to a queue before commit risky?
Because the queue can race ahead of your database. A worker may pick up the job, look for the new row, and find missing or half-finished data, or worse, act on an event for a change that later rolls back.
When do I need the outbox pattern?
Use it when an event or job must follow a successful write, but you do not want message sending inside the transaction. You write the business rows and an outbox row in the same commit, then a worker publishes later from saved data.
Why does idempotency matter here?
It stops retries from creating the same result twice. Store a stable request or job ID with the main write so your app can answer, "we already handled this," instead of making a second order, refund, or charge.
Should I call external APIs inside the transaction?
Keep outside calls out of the transaction when you can. If you wait on email, webhooks, or another API while locks stay open, you make timeouts and contention more likely. Commit your local truth first, then call other services in a separate step.
What should a worker use as its source of truth?
Read committed state, not just the message body. A small message with the record ID and task type works well because the worker can fetch the final row from the database and act on what actually committed.
How do I test whether my commit line is correct?
Try one ugly failure on purpose. Commit the transaction, kill the app before publish, restart the worker path, and check whether the system finishes the missed work without guessing, losing data, or repeating money movement.
When should a small team get outside help with this design?
Ask for help when your team keeps seeing duplicate jobs, split data, strange status mismatches, or long arguments about what belongs in the transaction. A short architecture review can save a lot of cleanup later, especially before you add more workers and events.


