Tokio task patterns to avoid hidden contention in Rust
Tokio task patterns for shared state, channel backpressure, and cancellation that keep async Rust responsive under mixed CPU and I/O work.
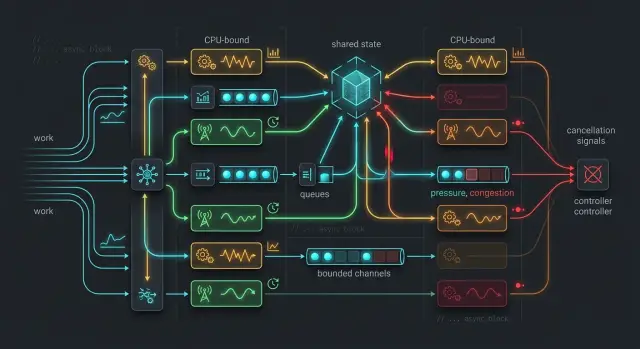
Table of Contents
Why async Rust slows down in real workloads
An async Rust service can look healthy right up to the moment users feel it slow down. CPU use stays moderate, tasks keep polling, logs keep flowing, yet one busy mutex or one full queue makes everything wait in line.
That is why these problems hide so well. Nothing has to crash. Requests still finish. But latency creeps up from 20 ms to 200 ms, queue depth grows, and throughput gets uneven. One worker looks overloaded while others spend time waiting.
Mixed CPU and I/O work exposes small bottlenecks very fast. A task might read from the network, parse a payload, update shared state, and write to storage. Each step seems cheap alone. Under load, the pauses stack up. A short lock hold turns into a line of waiting tasks. A bounded channel fills. A slow downstream consumer makes upstream tasks look busy even when they are mostly blocked.
A common case looks harmless at first. A request handler records metrics in shared state, pushes a job into a channel, then waits for a database response. If the metrics lock stays busy for a little too long, the send happens later. If the channel is near capacity, the send waits. While that request waits, more requests arrive and repeat the same pattern. The app still does work, but it now moves at the pace of the slowest shared point.
The symptoms usually show up together:
- latency rises before CPU maxes out
- queues grow even though tasks seem active
- some requests finish quickly while others stall
- throughput comes in bursts instead of staying steady
Good Tokio task patterns keep work moving without turning the code into a science project. The goal is simple: keep shared sections short, keep queues honest, and stop work early when nobody needs the result anymore. That is often enough to make async Rust feel fast again under real traffic.
Where hidden contention starts
Hidden contention usually starts in code that looks harmless. A single Mutex around a map, cache, or connection registry feels simple, and it often works fine in light traffic. Then one task holds that lock a little too long while it reads, updates, or waits on something else. Other tasks pile up behind it, and latency jumps even though CPU use looks normal.
This happens a lot with shared state in Tokio. A request handler checks a cache, updates connection state, writes metrics, and touches a session map. Each step is small on its own. Put them behind one hot lock, and dozens of tasks start waiting for the same narrow gate.
A few places this shows up often:
- a shared hash map for per-user state
- a cache that mixes reads, writes, and eviction under one lock
- a connection manager that tracks sockets, retries, and heartbeats together
- a task that locks state, then does async work before releasing it
Channels create a different kind of traffic jam. One slow receiver can back up many fast senders, especially when producers run in parallel. The senders keep doing work, pushing messages, and waking each other up. Throughput looks busy, but useful work drops because the queue becomes the bottleneck.
Unbounded channels make this worse because they hide the problem for a while. Nothing blocks, so the system seems healthy. Then memory grows, queue delay grows, and old messages stay relevant for less and less time. By the time you notice, the backlog has already changed system behavior.
Cancellation bugs add another layer. A long task that ignores shutdown keeps running after the rest of the system wants to stop, reload, or shed load. It may keep holding a permit, filling a queue, or retrying work nobody needs anymore. In mixed workloads, that stale work steals time from fresh requests.
If you see random stalls under load, look for places where many tasks must wait for one shared thing: one lock, one receiver, one queue, or one task that refuses to quit. That is usually where hidden contention starts.
Shared state without a traffic jam
Most slow Tokio code does not fail because async is "slow." It slows down because too many tasks touch the same data in the same way.
A common mistake is to put everything into one shared Arc<Mutex<AppState>> and let every task grab it. That feels tidy at first. Under load, it turns into a line at the door.
Clear ownership works better. If one task updates a job queue, let that task own the queue. If another task only needs config, give it a cheap clone of the config instead of access to the whole state object. Good Tokio task patterns usually start by asking who should own each piece of data, not how to share all of it.
Split busy mutable data from cold data. For example, a request counter, active sessions map, and work queue change all the time. Static config, feature flags, and templates rarely change. Keep those in separate structures so a hot lock does not block reads that should be cheap.
Lock scope matters just as much as lock choice. Take the lock, copy or update what you need, and drop the guard before any await. If you hold a guard across network I/O, disk I/O, or a channel send that can wait, other tasks sit still for no good reason.
A small pattern works well in practice:
- one owner task handles writes for a shared resource
- other tasks send requests over a channel
- readers get snapshots or cloned read-only data
- atomics track simple counts and stop flags
Message passing is often simpler than a shared lock when writes should happen in order. A single writer task can update state, batch work, and keep consistency without many tasks fighting over a mutex.
Atomics help, but only for small jobs. Use them for counters, health flags, or a shutdown signal. Do not build a large state machine out of atomics unless you enjoy debugging weird races at 2 a.m.
A good test is simple: if ten busy tasks all wake up at once, can they do most of their work without waiting on the same guard? If the answer is no, split the state again.
Step by step: refactor a hot path
A hot path usually slows down for a simple reason: too many tasks touch the same state, and one slow step makes the rest wait. Good Tokio task patterns start with ownership, not with more tasks.
Take one request and trace it from start to finish. Write down each task that runs, what data it reads, and which task is allowed to write each piece of state. If two or three tasks can all mutate the same map, cache, or counter set, you have a traffic jam already.
Then inspect every lock with a harsh rule: no parsing, no network call, and no disk I/O while the lock is held. Those steps can pause for much longer than you think. A mutex around a tiny map update is fine. A mutex around "parse, fetch, update, save" is where throughput falls apart.
A simple refactor often looks like this:
- Keep parsing on owned data outside the lock.
- Move shared writes into one owner task that receives commands.
- If one owner becomes too busy, shard the state by user ID, tenant ID, or another stable field.
- Put a bounded channel between fast producers and the slower writer.
- Treat a full channel as a signal, not as something to hide.
Imagine an API worker that accepts payloads, parses JSON, updates an in-memory map, and writes an audit record. In the slow version, each worker locks the map, parses inside the critical section, then waits on disk I/O before it unlocks. In the better version, the worker parses first, creates a small update message, and sends it to a dedicated task that owns the map and audit writes. Other workers stay free to handle new requests.
A bounded channel matters because it turns overload into visible pressure. If producers can push forever, memory grows and latency gets weird. If the channel has a fixed size, producers slow down when consumers fall behind. That is easier to reason about, and much easier to fix.
Measure before and after, or you are guessing. Two numbers tell the story fast:
- queue depth over time
- lock wait time under load
- send delay on the bounded channel
- request latency at p95 or p99
If the refactor worked, lock waits shrink, queue depth stops climbing without limit, and latency spikes get shorter. If the queue still grows, the owner task is still too broad. Split it again, or reduce the work each message triggers.
How to handle channel pressure
A channel that never pushes back can hide overload for a long time. The app still "works," but memory grows, latency gets weird, and workers spend more time catching up than doing useful work. In Tokio, bounded channels are usually the safer default when producers can outrun consumers.
A small buffer forces you to choose a policy early. That feels strict, but it is better than finding out under load that one fast producer can flood the whole process.
Pick a policy before the queue fills
When a bounded channel gets full, your code needs a clear rule.
- Wait if every item matters and short delays are fine.
- Drop if newer data makes older data useless, like frequent UI or metric updates.
- Merge if you can combine many small updates into one batch.
- Shed work if the system is already late and extra jobs would only make recovery slower.
Different workloads need different choices. A billing event should probably wait. A stream of "user is typing" updates should probably drop or merge.
Control messages deserve their own lane. If stop, reload, or health signals sit behind thousands of bulk jobs, the system feels stuck even when the code is correct. Use one channel for control and another for data so small signals stay fast.
Payload size matters more than many teams expect. If each message carries a big struct or cloned data blob, the queue gets expensive before it gets long. Send a job ID, a small command, or a shared pointer such as Arc<T> when that fits. Let the worker fetch the full data only when it starts the job.
You should also watch pressure during load tests, not just after release. Two numbers tell a lot: how long send() waits, and how deep the queue gets during bursts. If you already track runtime metrics with Prometheus and Grafana, graph both. A queue that sits near full for minutes is not a buffer anymore. It is a delay line.
Good Tokio task patterns make overload visible early. That gives you room to slow producers down, trim work, or split busy paths before users feel the stall.
Cancellation that actually stops work
Cancellation fails when it only stops the parent task. Child tasks keep polling, retry loops keep waking up, and shutdown drags on. One of the most useful Tokio task patterns is simple: create one cancellation token near the top, then pass it through every spawned task.
A shared token gives every task the same stop signal. If you only cancel the request handler, a background worker may still hold a lock or keep reading from a queue. That kind of half-shutdown causes the stalls people blame on async Rust.
use tokio::select;
use tokio_util::sync::CancellationToken;
async fn worker(token: CancellationToken) {
loop {
select! {
_ = token.cancelled() => break,
_ = do_one_unit_of_work() => {}
}
}
}
Checking once per loop is a good start, but it is often not enough. If one loop body does three expensive things, check between them. A task that fetches data, parses it, and writes it out should stop between each step. That can cut shutdown time from seconds to a few milliseconds.
Retry code needs the same treatment. A common bug looks harmless: on error, sleep for 5 seconds and try again. During shutdown, that task still waits out the full sleep unless you race the sleep against cancellation. Background polls have the same problem. If shutdown starts, stop polling right away.
Order matters too. This sequence is usually safe:
- cancel the root token
- stop new input by closing senders or listeners
- let workers finish any tiny in-flight unit they already started
- join child tasks
- give up fast on cleanup that is not required for correctness
If you join tasks before you close their queues, they may sit on recv() forever. If you run heavy cleanup after cancellation, shutdown becomes another bottleneck. Save only what you must keep consistent. Skip cache flushes, large batch writes, and anything you can rebuild later.
This shows up a lot in small production teams. A service can handle traffic well all day, then stall during deploys because old tasks never really stop. Fast shutdown is part of runtime performance, not a separate concern.
A realistic mixed-workload example
Picture a Tokio service that takes incoming requests, fetches extra data from an external API, parses the response, updates a cache, and writes the final record to storage. On paper, each step looks fine. Under load, this kind of service often slows down in ways that do not show up in small tests.
A common mistake is to keep both the cache and the writer behind shared locks. One request gets enriched quickly, then hits a slow write. While that task waits on storage, it still holds the lock longer than it should. A few more requests pile up behind it. Soon, fast requests start waiting for slow ones, even when the cache lookup itself takes almost no time.
The fix is to give ownership to the tasks that need it most. Keep the cache lock short and narrow: read from it, copy what you need, and drop the lock right away. Do not let a storage write sit behind the same shared state.
A better layout looks like this:
- request tasks read or update a small cache with very short lock times
- request tasks send completed records into a bounded channel
- one writer task owns the storage client and performs writes in order
- a small worker pool handles CPU heavy parsing
That bounded channel matters. If storage slows down, the queue fills up and pushes back on the callers. That is much better than letting memory grow without a limit or spawning more work than the machine can finish.
Parsing deserves its own limit too. If every request parses a large payload on the async executor, latency gets jagged fast. Use a fixed worker pool, or gate parsing with a semaphore, so only a small number of parse jobs run at once. Other requests can still make progress while those workers stay busy.
Cancellation needs the same level of care. During a deploy, you want in-flight work to stop cleanly instead of hanging until every queue drains by accident. Give request tasks and worker tasks a cancellation token. If shutdown starts, stop accepting new requests, stop sending new items to the writer, and let the writer finish only the records it already owns. Drop the rest explicitly.
This pattern is simple, but it holds up well under mixed workloads. Slow writes stay isolated, parsing stays capped, and cancellation does real work instead of being an afterthought.
Mistakes that cause stalls
Bad Tokio task patterns often look harmless in review because each one seems small. Under mixed traffic, they stack up and turn short waits into queues.
One mistake shows up all the time: a request handler grabs a lock, then hits an await before it releases that lock. While that task waits on a database call or another service, every other task that needs the same state sits in line. Keep the locked part short. Copy what you need, drop the guard, then await.
CPU work causes a different stall. If a task parses a large file, hashes a big payload, or runs a long loop on the async runtime, it steals time from tasks that only need a quick poll. Tokio can mask this in light testing. Production traffic will not. Move heavy work to spawn_blocking or a bounded worker pool, and cap how much can run at once.
Another easy mistake is spawning tiny tasks for work that fits in one function call. Every spawn adds scheduling overhead, more wakeups, and more places where cancellation gets messy. If the work is short and does not need its own lifetime, call the function directly.
A single global channel can hurt just as much. Teams often push logs, retries, background jobs, and user work through one queue because it feels simple. Then one burst fills the channel and unrelated work starts to wait. Separate traffic by purpose or priority, and prefer bounded channels so pressure shows up early.
Retries can quietly turn a slow dependency into a full service stall. If one downstream API starts lagging and your code retries without a cap, load multiplies fast. Add backoff, add a retry budget, and stop after a clear limit.
A quick check catches most of these problems:
- Look for any lock that stays alive across an
await - Find loops that burn CPU inside async tasks
- Remove spawns that only wrap a tiny helper call
- Split channels that carry unrelated traffic
- Cap retries before a slowdown turns into a retry storm
Most stalls start as "just one small shortcut." Under load, that shortcut becomes the queue everybody feels.
Quick checks before release
Before you ship, do one review pass that looks only for waiting, blocking, and work that never ends. Most async slowdowns do not come from a big design mistake. They come from one lock held too long, one channel with the wrong size, or one task that keeps running after the request is gone.
Good Tokio task patterns often look boring in code review. That is a good sign. The code should make it easy to answer simple questions about ownership, queue size, and shutdown.
Use this short checklist:
- Find every
awaitinside a locked section. If a task holds aMutexorRwLockand then waits on I/O, sleep, or another task, move thatawaitoutside the lock when you can. - Check every channel capacity on purpose. Unbounded channels can hide trouble until memory climbs. Tiny bounded channels can stall producers all day. Pick a size that matches real traffic, not a guess.
- Read every background loop and confirm it can stop. A loop that only waits on
recv()orsleep()needs a shutdown signal, a cancellation token, or a closed channel path. - Find CPU-heavy work and count how much you allow at once. Parsing large payloads, compression, image work, and big JSON transforms should not pile up on Tokio worker threads.
- Make sure you can see queue depth, lock wait, and task time in metrics. If latency jumps, you need to know whether tasks waited on a lock, sat in a queue, or ran too long.
A small release check like this can save hours of guesswork later. Picture a service that looks fine in staging, then slows down when a burst of uploads lands at the same time as normal API traffic. One bounded channel fills, workers wait on a shared map, and cancelled requests keep doing work in the background. The fix is usually not dramatic. You just need to spot the pressure points before users do.
If a team cannot answer these five checks in one meeting, the system is not ready yet.
Next steps for a production system
Production tuning goes better when you pick one hot path and fix one bottleneck first. Teams often change locks, channels, and task layout at the same time, then they cannot tell what helped. Start with the path that handles the most traffic or creates the worst tail latency.
A good first target is usually easy to spot. Maybe one mutex guards too much state. Maybe one worker receives every message through a single channel. Maybe cancelled requests still keep running for another second. Fix one of those, measure again, and keep the change if it moves the numbers.
Small load tests catch a lot of trouble before users do. Mix burst traffic with one slow downstream dependency, because real systems rarely fail in a clean lab setup. For example, send a short spike of requests while one database call or external API slows down, then watch queue depth, task count, memory use, and p95 latency.
A short written map of each task group helps more than most teams expect:
- Who owns each piece of shared state
- Which channels are bounded, and their limits
- What happens when a queue fills up
- How shutdown starts and who stops first
- When a task must drop work and exit
If that map feels fuzzy, hidden contention is probably still in the design. Tokio task patterns stay healthy when ownership is boring, queues are explicit, and cancellation has a clear path.
Write these rules in plain English next to the code. New teammates can then see why one task holds state, why another task only sends messages, and why a bounded queue exists at all. That cuts down on accidental regressions during later refactors.
If your team wants another set of eyes, Oleg Sotnikov can review Tokio architecture, backpressure, and runtime setup through Fractional CTO advisory. That kind of review is most useful after you collect a few traces, test results, and one clear pain point.


