State machines for approval workflows teams can trust
State machines for approval workflows make approvals easier to trace, test, and change. Learn how to model steps, retries, exceptions, and rollbacks clearly.
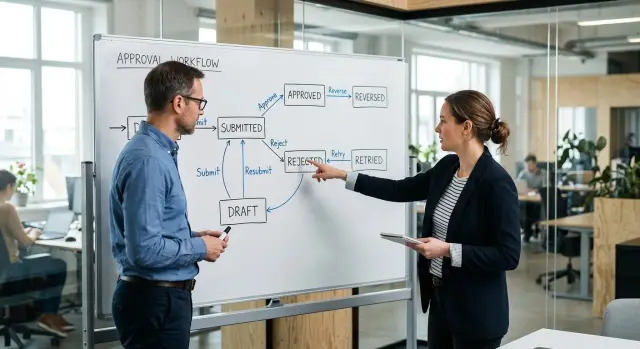
Table of Contents
Why approval logic gets messy fast
Approval flows usually start small. One person submits a request, one manager approves it, and the team moves on.
Then real work gets in the way. Finance needs to review anything above a certain amount. Legal has to check some contracts. A request can expire, get sent back for edits, or reopen after someone changes the budget. Before long, the rules live in five different places.
One controller blocks an action. A background job sends reminders after two days. A nightly script closes old requests. An admin tool lets support "fix" stuck records by hand. Each part makes sense on its own, but the full process stops being clear.
That is when edge cases show up. Two people click at the same time and a request gets approved twice. A retry sends the same email again after the record already moved forward. A rejected item gets edited and lands in a state nobody planned for. The team did not set out to build chaos. The rules just spread out quietly.
Audits get messy too. When someone asks, "Why did this payment go through?" the answer often lives in old logs, queue history, and a few guesses from the team. The database may show the current status, but not what happened before, which rule allowed the move, or who reversed it.
This gets worse when the business changes the process every month. Each quick fix adds another condition somewhere in the code. After a while, even a small change feels risky because nobody trusts what will happen next.
A state machine solves that by putting the process into one clear model. Instead of hunting through controllers, jobs, and scripts, the team can see every allowed state, every transition, and every exception in one place.
What a state machine means in plain language
A state machine is a simple way to describe a process so everyone can see where something is, where it can go next, and what must be true before it moves.
A state is just a named moment in the process. For an approval request, that might be draft, submitted, approved, rejected, canceled, or paid. Each state answers one basic question: "What is the status right now?"
A transition is an allowed move from one state to another. A request can move from draft to submitted. It can move from submitted to approved or rejected. It should not jump from draft straight to paid unless your rules allow that.
Guards are the checks that allow or block a move. They are not magic. A move from submitted to approved might require manager review, a limit on the amount, or all required fields to be filled in.
A simple way to think about it is this:
- States are the places where the request can sit.
- Transitions are the doors between those places.
- Guards are the locks on those doors.
This structure makes the process much easier to reason about. When someone asks, "Why did this request move?" or "Why was this blocked?" the answer lives in the model, not in five different code paths.
Scattered if statements usually turn into a mess because every exception lands in a different file. One rule lives in the API, another in the admin panel, and a third in a background worker. After a few months, nobody can explain the full process with confidence.
A state machine fixes that by making the rules visible and testable.
Map the states before you write code
Most teams start with screens, buttons, or API names. That feels practical, but it hides the real process. Start with a plain list of states. If two people cannot agree on the current state of a request, the code will get messy fast.
A state is a business fact, not a label on the screen. "Waiting for manager review" is a state. "Needs attention" is just interface text. You can change the wording in the app later without changing the rules.
Write down every state that can exist in real life, including the awkward ones people usually skip. Teams remember approved and rejected, but often forget the dull middle states and failure cases that create support tickets.
A useful first pass might include draft, waiting_for_review, waiting_for_more_information, failed, and closed. The exact names will vary, but the pattern matters. Include waiting states, failure states, and final states such as approved, rejected, canceled, or expired.
Give each state one short sentence. Keep it strict. "Submitted and maybe waiting for finance unless the amount is low" is not one state. That is two or three ideas jammed together. Split it until each state is easy to test.
A good rule of thumb helps here. If someone can ask, "What can happen next?" and get one clear set of answers, you probably have a real state. If the answer changes because of hidden conditions, you probably skipped a state.
Do this before you name endpoints, database fields, or page tabs. Once the states are clear, the rest gets much easier because every action has a clear start and end.
Define transitions, rules, and side effects
A state machine starts to pay off when each transition reads like a small contract. draft -> submitted is only the label. The useful part is everything around it: who started the move, what must already be true, what the system changes, and what evidence stays in the record.
Start with the trigger. Name the actor in plain language. A user clicks approve. A finance system confirms payment. A scheduled job marks a request as expired. If you leave the trigger vague, the rules drift back into random controller checks and one-off scripts.
Then write the guard rule for the move. Keep it short and testable. For example: "A manager can approve only if the amount is within limit, the request has all required documents, and the request is still in submitted." If the rule fails, keep the current state and store the reason.
Side effects belong next to the transition, not hidden somewhere else. When a request moves, the system might send a notice, create an accounting entry, assign the next reviewer, or unlock a payment step. Put those actions in the transition definition so one place tells the whole story.
A simple transition spec usually needs four things:
- who or what starts the move
- what must be true first
- what the system does during the move
- what you store for audit and support
Audit data matters more than most teams expect. Save the old state, the new state, the time, the actor, the reason, and any business values that explain the decision, such as amount, department, or approval limit. If a side effect fails, record that too.
That history saves time later. When someone asks why a request changed status at 4:12 PM, support should not read code or search logs across three systems. They should open one clear transition history and get the answer in seconds.
Model retries, timeouts, and reversals
Approval flows fall apart when the system quietly retries, waits forever, or acts like an earlier decision never happened. Each of those cases needs its own state or transition.
Retries should never feel invisible. If an approval email fails to send, or a downstream system rejects an update, move the item into a retry state and record why. Count the attempts. Set the next retry time. Stop after a clear limit. That gives support something real to inspect instead of a vague "it should have worked" story.
Timeouts need the same treatment. A request that sits in pending_approval for 12 days is not healthy just because nobody touched it. Move it to timed_out or overdue after a set window. Then decide what happens next: send a reminder, escalate to another approver, or close it.
Reversals need just as much care. Budgets change. Compliance rules shift. Someone approves the wrong request. Do not overwrite approved with rejected and call it fixed. Add a real transition such as approved -> revoked or approved -> returned_for_review. The history stays clear, and audits stop turning into detective work.
A few decisions remove most of the confusion:
- Set a maximum retry count for each failure type.
- Define the timeout window for every waiting state.
- Limit who can reverse a decision.
- Decide which reversals require a reason.
- Separate final rejection from send-back-for-edits.
That last point matters. Some rejections should end the flow right away, like a policy violation or missing legal approval. Others should loop back so the requester can fix the issue and submit again. Those are different paths and should stay separate.
A simple example: purchase request approval
A purchase request is a good test case because money, policy, and exceptions all meet in one flow.
Say an employee wants to buy a laptop. Every request starts in draft, then moves to submitted when the employee sends it. From there, the manager reviews it first.
If the request is for $800, the manager can approve it and move it straight to approved. If the request is for $4,500, the manager can approve it, but the request does not end there. It moves to finance_review because it crossed the company threshold.
A simple model might look like this:
draft->submittedsubmitted->manager_reviewmanager_review->approvedwhen the amount is under $2,000manager_review->finance_reviewwhen the amount is $2,000 or morefinance_review->approvedorrejected
Now add a common problem: missing information. The employee forgot to attach a vendor quote. The manager should not reject the whole request if the purchase still makes sense. Move it to needs_info instead.
That creates a clean retry path. The employee adds the quote, then sends the request back to submitted or directly to manager_review, depending on your rules. What used to be a vague "send it back and try again" habit becomes a clear transition.
Cancellation after approval is another place where teams often cheat with custom scripts. It is better to model it directly. If the employee cancels after approval but before the order is placed, move the request to cancel_requested, run the reversal steps, then finish in canceled.
Those reversal steps matter. Finance may need to release a budget hold, and procurement may need to stop a purchase order. When you model that path as a real state change, the rules stay visible.
How to build it step by step
Start with one approval flow that already wastes time or causes mistakes. Pick the one people complain about most, such as purchase approvals or access requests. If you try to model every process at once, you will rebuild the same mess in a prettier diagram.
Put the whole workflow on one page before you write code. Name each state in plain words: draft, submitted, approved, rejected, canceled, failed. Then draw the allowed moves between them. If someone cannot point to a line and explain why it exists, that transition probably should not exist.
Keep the first version small. Many teams add too many states because they confuse state with side effects. Email_sent is usually not a state. Waiting_for_finance_review often is.
Turn rules into one model
Once the map looks right, move the rules out of controllers, scheduled jobs, and random scripts. Put them in one workflow model where each transition has clear checks and clear results. That model should answer simple questions quickly: who can approve, what happens after rejection, when a retry is allowed, and whether a reversal needs a reason.
Then test the paths that usually break in real life. The happy path is easy, so do not stop there. Run a few cases on purpose: successful approval, rejection, retry after a temporary failure, and reversal after someone approved by mistake. If your model handles those cleanly, it is strong enough for a first release.
Make state changes visible
Log every state change in the order it happens. Record the old state, the new state, who triggered it, and why. When support gets a ticket two months later, that audit trail saves hours.
Keep the first version boring. That is a good thing. A small, explicit model beats clever controller code every time, and it gives you one place to change business rules without digging through the whole app.
Common mistakes when modeling approvals
Teams usually break approval flows in boring ways. They treat the workflow like a few status fields and some if statements. That works for a week. Then exceptions pile up, people add manual fixes, and nobody can explain why one request moved forward while another got stuck.
One common mistake is skipping the in-between states. A request rarely jumps cleanly from draft to approved or rejected. It may wait for manager review, legal review, missing documents, or a second check after edits. If you leave out those states, people push the logic into comments, flags, and side scripts.
Another mistake is hiding approval rules inside background jobs. A nightly task quietly escalates requests. A queue worker auto-rejects stale items. A webhook changes status after a document arrives. Those actions may be fine, but the rules should still appear as explicit transitions. If the rule lives only in a worker, the workflow becomes a scavenger hunt.
Direct jumps cause even more trouble. Someone adds a shortcut from submitted to approved because "finance already checked it in another tool." Six months later, half the required checks get bypassed by accident. If a shortcut exists, name it and limit who can use it.
Teams also mix up technical failure and business rejection. Those are different events. If an email service fails, the request did not fail review. If a payment API times out, the approver did not reject the request. Put those cases in separate states or error paths. Otherwise reporting gets messy, retries behave badly, and users get the wrong message.
Reversals need the same care as approvals. Many teams add a reopen or undo action late and forget permissions. Can any reviewer reverse a final approval? Only the original approver? Only an admin with a reason? If you do not model that clearly, people start fixing records by hand.
A quick smell test helps:
- Users ask support why an item skipped review.
- Engineers need to read job code to explain a decision.
- Rejected items and failed jobs share the same status.
- Admins change database rows to reverse decisions.
- Reports cannot show where requests really wait.
If you see two or three of these, the model is probably too loose.
Checks before you ship
If your workflow still depends on tribal knowledge, it is not ready. A good state machine feels boring in production because everyone can tell what happened, why it happened, and what can happen next.
Run a short review before release.
Ask a few people to name every state from memory. If they argue about whether something is "pending review," "waiting," or "on hold," the model is still fuzzy.
Give support one stopped request and ask for the reason in plain English. They should find the state, the failed rule, and the next allowed action without reading code.
Pick one real request ID and replay its path from start to finish. You want a clean history: who triggered each transition, when it happened, and what rule allowed it.
Test each transition by itself. A request moving from submitted to approved should pass or fail for clear reasons, without depending on side effects from earlier steps.
Change one business rule in a safe branch. If that small change sends you into controllers, jobs, database triggers, and helper files, the workflow is still too scattered.
A small example makes this obvious. Say a purchase request stops after finance review because the amount crossed a limit. Support should see that it entered needs_director_approval and stayed there because no director acted yet. They should not need to inspect logs from three services or guess which script ran overnight.
One more check matters: can you explain reversals clearly? If an approval gets revoked, the workflow should show the exact backward move or compensating step. "We just reset it" is a warning sign.
What to do next
Start small. Pick one approval flow your team uses every week and map it on paper before you touch the code. Expense approvals, purchase requests, and refund requests work well because the path is easy to recognize, but the exceptions usually are not.
Write down the real states first. Then add every allowed move between them, who can trigger each move, and what must be true before it happens. If two people on the team describe the same step differently, you probably found a bug before it reached production.
A good first pass is simple:
- choose one live workflow, not a theoretical one
- find old scripts, controller branches, and manual steps around it
- mark every hidden decision, retry, timeout, and reversal
- add an audit note to each transition, not just the final approval
- test a few messy cases, like duplicate submissions or late rejections
Those audit notes matter more than many teams expect. When someone asks, "Why did this request move back to review?" the answer should sit on the transition itself, with a timestamp and actor. That saves hours later.
It also helps to review the glue code around the process. Approval diagrams often look clean while production systems stay messy because the real rules live in scheduled jobs, admin panels, and one-off scripts. Pull those decisions into the model so the workflow lives in one place.
If your team wants a second opinion before building too much around it, Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor and helps companies turn scattered business rules into systems that are easier to maintain. Sometimes a short review is enough to spot edge cases your team has learned to ignore.
One mapped flow this week is enough. If that model is clear, the next one gets much easier.
Frequently Asked Questions
What problem does a state machine solve in an approval flow?
It puts the whole approval process in one model. Your team can see every allowed state, every move, and every rule without digging through controllers, jobs, and manual scripts.
Do I need a state machine for a small workflow?
Not always. If one person submits and one person approves, simple code may work. Once you add finance checks, retries, timeouts, or reversals, a state machine usually saves time and prevents messy fixes later.
What counts as a real state?
A real state describes a clear business fact, like draft, manager_review, or needs_info. If people can name one clear set of next actions from that point, you likely have a real state.
How is a state different from a side effect?
A state tells you where the request sits right now. A side effect is something the system does during a move, like sending an email, creating an accounting entry, or assigning the next reviewer.
Should retries and timeouts be explicit in the model?
Yes, when they change how the team handles the request. If a failed delivery needs another attempt, store that as an explicit retry path. If a request waits too long, move it to overdue or timed_out instead of leaving it stuck in a vague pending status.
How should I handle rejection versus send back for edits?
Treat them as different paths. A final rejection ends the flow. A return for edits sends the request back so the user can fix something and submit again. If you merge those into one status, support and reporting get messy fast.
What should I store for audit history?
Save the old state, the new state, who triggered the move, when it happened, and why it happened. Store business details that explain the decision too, such as amount, approval limit, or missing documents.
How do I stop double approvals and duplicate side effects?
Put every state change behind one transition rule and check the current state before you move it. Add idempotent actions for things like emails and payments so a retry does not repeat work after the request already moved forward.
What is the best way to start without rebuilding everything?
Start with one workflow that already causes mistakes or delays. Map the states on one page, add the allowed moves, then pull hidden rules out of controllers, jobs, and scripts into one model. Test the awkward cases first, not just the happy path.
When should a team ask for outside help with approval workflows?
Bring in help when small rule changes feel risky, support cannot explain why requests moved, or admins fix records by hand. A short workflow review often finds missing states, hidden shortcuts, and audit gaps before they turn into bigger problems.


