SQLAlchemy 2.0 patterns that prevent hidden query bugs
SQLAlchemy 2.0 patterns help growing services avoid hidden query bugs with explicit sessions, typed models, and clearer read and write flow.
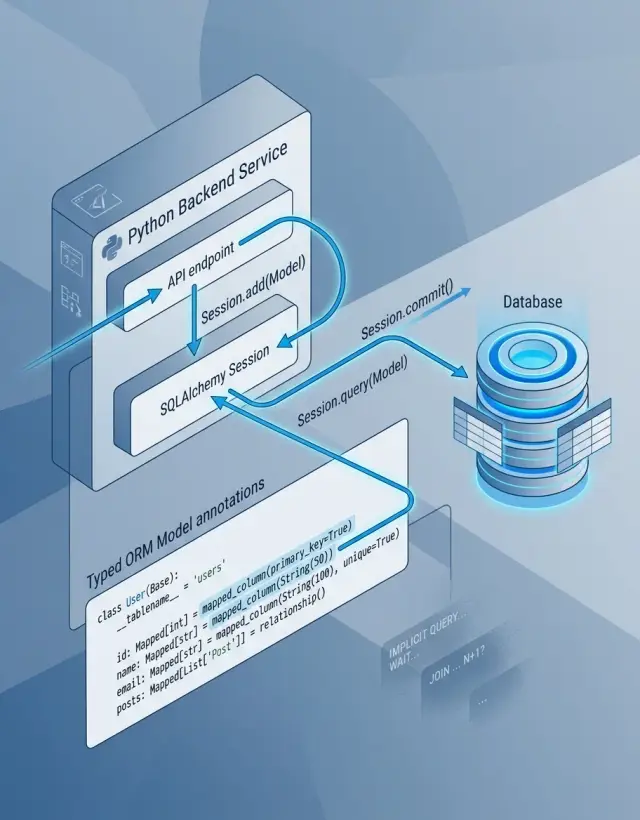
Table of Contents
Why query bugs show up after the prototype stage
A prototype usually has one request path, one database session, and just enough code to make the happy path work. Then the app grows. A single file turns into API handlers, background jobs, admin scripts, import tasks, and scheduled workers. The database code still works, but now it runs in many places with different timing, different lifecycles, and different assumptions.
That is where quiet bugs start. A handler reads an order and returns JSON. During serialization, code touches order.customer or order.items, and SQLAlchemy fires extra queries through lazy loading. Nobody asked for more database work in that moment, yet it happens anyway. On a laptop, it looks harmless. Under real traffic, those surprise queries pile up fast.
Shared sessions make this worse because ownership gets blurry. One helper opens a session, another reuses it, and a third commits or rolls back without making that clear. After a few months, nobody knows which function owns the transaction boundary. A normal read can leave dirty state behind. A write can happen earlier than expected. Bugs feel random because the session lives longer than the developer thinks.
Old helper functions often hide the database work that matters most. A function named get_current_account() sounds harmless, but it may issue a query, trigger lazy loads, and attach objects to a long-lived session. Another helper may return a model that looks safe to pass around, even though touching one attribute later can hit the database again. The call site looks clean. The behavior is not.
Small services also collect one-off shortcuts. A CLI script imports app code and reuses web request session logic. A cron job calls the same helper stack but runs outside the request flow. Test fixtures keep sessions open longer than production code should. Each shortcut makes the code a little harder to reason about.
This is why teams hit odd query behavior after the prototype stage, not during it. The database layer stops being a single clear path and becomes a web of hidden reads, unclear ownership, and helpers that do more than their names admit. That is exactly the mess a Python backend refactor should cut first.
What SQLAlchemy 2.0 changes in daily code
SQLAlchemy 2.0 feels stricter at first. That is usually a good trade. Older ORM code often packed too much behavior into session.query(...), then hid more work inside helper methods and lazy relationships. A prototype can survive that. A growing service usually cannot.
# old style
user = session.query(User).filter(User.email == email).one()
# 2.0 style
stmt = select(User).where(User.email == email)
user = session.scalars(stmt).one()
That shift matters more than it looks. select() gives you a query object you can read before it runs. scalars() makes the result shape obvious: you expect model objects, not a row tuple that changes after someone adds one more column. Many SQLAlchemy 2.0 patterns are really about this one idea: make intent visible.
Transaction flow also reads better. In older code, a session often stayed alive across too much application code. Someone added a write in one helper, a flush in another, and a commit near the edge of the request. When a bug showed up, you had to trace half the call stack.
with Session(engine) as session:
with session.begin():
session.add(order)
session.add(audit_log)
Now the boundary is plain. You can see where database work starts, where it ends, and which actions belong to one transaction. That makes review faster and rollback behavior less surprising.
Typed models help in a quieter way. When a reviewer sees Mapped[int], Mapped[str | None], or Mapped[list[OrderItem]], they can spot the model's shape without guessing from column names alone. Nullability, collection fields, and relationships stop being hidden details. Small mismatches show up earlier, before they turn into odd queries or wrong joins in production.
The daily win is simple. A handler builds a select(), executes it in an explicit session, and commits inside a clear block. The code says what it does. That does not make bugs disappear, but it cuts the weird ones that waste an afternoon.
Set a clear session boundary
Most odd ORM behavior starts when a session lives longer than the work itself. One of the most useful SQLAlchemy 2.0 patterns is to create one session for one unit of work, then end it fast.
That unit of work is usually one web request, one CLI command, or one background job. If you keep a session around across multiple actions, old state leaks into new code. You get stale objects, surprise flushes, and writes that happen earlier than you meant.
Pass the session into the function that needs it. Do not let helpers open their own session behind the scenes. When the session enters through the function arguments, you can see who owns the transaction and where data changes actually happen.
from sqlalchemy.orm import Session
def create_order(session: Session, data: dict) -> int:
order = Order(customer_id=data["customer_id"], status="new")
session.add(order)
return order.id
def handle_request(session: Session, data: dict) -> int:
try:
order_id = create_order(session, data)
session.commit()
return order_id
except Exception:
session.rollback()
raise
The commit belongs in the write path, near the top level, not inside small helper functions. If a helper commits early and the next step fails, you save half the change and leave the system in a messy state. A single commit makes the transaction easy to reason about.
Roll back on errors every time. Then close the session. Fast cleanup matters because a session is not just a nice Python object. It holds transaction state, tracks loaded rows, and may keep a database connection busy longer than needed.
Background workers need the same rule, but with their own lifecycle. A worker should open a fresh session for each job, finish the job, then commit or roll back and close. Do not pass a request session into a queue task, and do not keep one global session for a long-running worker.
Teams that refactor Python services after the prototype stage usually see this change pay off quickly. Bugs get easier to reproduce because each request or job has a clear start and end.
Define models with types, not guesses
Quick prototypes often treat models like loose containers. That works for a while, then one nullable field, one wrong relationship, or one hidden default starts feeding odd queries into a growing service.
SQLAlchemy 2.0 pushes you toward a stricter model shape, and that is a good thing. With DeclarativeBase, Mapped[...], and mapped_column(...), your model tells readers, editors, and tests what the database can actually hold.
A model should say what can go wrong
If a column can be empty, type it that way. A field like shipped_at: Mapped[datetime | None] tells the next person they must handle the missing case. If you hide that risk and type it as always present, the bug moves downstream into query filters, serializers, or billing logic.
The same rule applies to relationships. A one-to-many relation should look like a list. A many-to-one relation should look like a single object, or None if it may be missing. That sounds small, but it lets your editor catch mistakes before runtime, like treating order.items as one row or assuming order.customer always exists.
from datetime import datetime
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship
from sqlalchemy import ForeignKey, String
class Base(DeclarativeBase):
pass
class Order(Base):
__tablename__ = "orders"
id: Mapped[int] = mapped_column(primary_key=True)
status: Mapped[str] = mapped_column(String(20), default="new")
shipped_at: Mapped[datetime | None] = mapped_column(nullable=True)
customer_id: Mapped[int | None] = mapped_column(ForeignKey("customers.id"), nullable=True)
customer: Mapped["Customer | None"] = relationship(back_populates="orders")
items: Mapped[list["OrderItem"]] = relationship(back_populates="order")
Keep defaults and column rules next to the field. If status defaults to new, put that in mapped_column. If a column allows NULL, say so there too. When rules live in helpers, events, or scattered service code, people miss them and write queries on bad assumptions.
This is one of the most useful SQLAlchemy 2.0 patterns because it cuts guesswork. A typed model does not just document the schema. It also shows where a service can break, which branches need tests, and which queries need extra care during a Python backend refactor.
Split reads from writes
When one function both fetches data and changes it, bugs hide in normal code paths. A read endpoint calls a helper to "get order", that helper touches a lazy relation, triggers a flush, and a half-finished change reaches the database.
A cleaner pattern is boring on purpose. Read functions fetch data and return it. Write functions change rows and return the result of that change. They do not mix jobs.
Among SQLAlchemy 2.0 patterns, this one pays off fast in services that started as quick prototypes. The code gets easier to predict, and the query log stops looking random.
Read code should load only what the endpoint uses. If an order list shows id, status, total, and customer name, load those fields and only the relation needed for the customer name. Do not pull line items, payments, and shipment events just because another screen might need them later. Extra data costs memory, and extra relations often trigger lazy loads at the worst time.
Write code should make the change plain. A function like cancel_order(session, order_id, reason) can load one order, update its status, and leave commit control to the caller. That keeps transaction timing in one place. Tests also get simpler, because the test decides when changes hit the database.
The trouble usually starts with helpers that look harmless:
get_or_create(...)touch_last_seen(...)ensure_customer(...)load_order_context(...)
If a helper can flush or commit, treat it as write code and keep it out of read paths. Hidden commits are worse than slow queries because they change data when nobody expects it.
This split also helps with response shaping. A read function can return a small typed result for an API response. A write function can return the updated entity or just the new status. Each path stays short, and each query has a clear reason to exist.
In an order service, that often removes the weirdest bugs first. Read handlers stop firing update statements. Write handlers stop loading huge object graphs. When something breaks, you know where to look.
A small order service before and after
A prototype order route often looks fine in a quick test. It loads one order, returns a few fields, and nobody notices that the response code quietly asks the database for more data after the first query.
from sqlalchemy import select
def get_order(order_id: int, session: Session) -> dict:
order = session.scalar(
select(Order).where(Order.id == order_id)
)
if order is None:
raise NotFoundError()
return {
"id": order.id,
"status": order.status,
"items": [
{"sku": item.sku, "qty": item.qty}
for item in order.items
],
"total": sum(item.price_cents * item.qty for item in order.items),
}
That route starts with one query for Order. Then the trouble begins. When the code touches order.items, SQLAlchemy may fire another query to lazy-load the relation. If another part of the response touches a different relation, you get one more. A small response builder can turn into a pile of hidden round trips.
This gets worse when the route grows. A serializer, logger, or template can touch attributes far away from the original query. You read the function top to bottom, but the actual database work happens in scattered places.
The cleaner version loads what it needs up front and keeps the work inside one session boundary.
from sqlalchemy import select
from sqlalchemy.orm import selectinload
def get_order(order_id: int, session: Session) -> dict:
stmt = (
select(Order)
.options(selectinload(Order.items))
.where(Order.id == order_id)
)
order = session.scalar(stmt)
if order is None:
raise NotFoundError()
items = [
{"sku": item.sku, "qty": item.qty}
for item in order.items
]
total = sum(item.price_cents * item.qty for item in order.items)
return {
"id": order.id,
"status": order.status,
"items": items,
"total": total,
}
Now the route says what it needs before it builds the response. The session stays explicit, the relation loads on purpose, and the returned data does not trigger surprise queries later.
This style matters more as a service grows. It is easier to test, easier to review, and much easier to reason about when a slow endpoint shows up in production. For teams cleaning up an old Python backend refactor, this sort of change removes a lot of confusion without changing the business logic.
Mistakes that still cause odd queries
Even after you adopt cleaner SQLAlchemy 2.0 patterns, a few habits can still produce strange database traffic. These bugs often hide in code that looks harmless, then show up as random slowdowns, stale data, or writes that happen earlier than you expected.
A common one is reusing the same session across many requests. A session keeps object state in memory. If request A loads an order and request B touches that same session later, you can get old data, unexpected updates, or confusing reads from the identity map instead of the database. In a web service, one request should own one session.
Another trap appears when response code touches lazy relationships after the session closes. Say your handler returns an order, and the serializer reads order.customer.name or loops over order.items. If those relations were not loaded on purpose, SQLAlchemy may try to fetch them at the worst moment, or it may fail because no live session exists. Load the needed relations in the query, then turn the result into plain data before you leave the request.
Long-lived caches cause similar trouble. Storing ORM objects in Redis, memory, or a module-level cache sounds convenient, but those objects carry session state and assumptions about what is loaded. Hours later, one attribute access can trigger a surprise query or return stale values. Cache IDs or plain dicts instead.
Implicit flushes also bite teams that mix business rules with database objects. A query can trigger an autoflush before you mean to save anything. That gets messy fast when a rule checks stock, creates an item, then runs another query in the same block. Keep rule checks separate from writes, and call flush() only when you want pending changes to hit the database.
Default relationship loading is another quiet source of odd behavior. If your API code loops through 50 orders and reads order.items one by one, you get the classic N+1 problem.
Watch for these signs:
- A list endpoint gets slower as rows grow
- A serializer crashes outside the request scope
- A cache returns objects with missing fields
- A read-only check writes data by accident
Most hidden query bugs come from one rule: the query should say what it needs. Response code should not decide later.
Quick review checks
When a Python service starts acting strange, the fix often comes from a short code review, not a bigger rewrite. Most hidden ORM bugs come from unclear ownership: one function opens the session, another commits, a third triggers a lazy load, and nobody notices until production traffic hits.
Use a small checklist and run it on one request path at a time.
- Follow the write path and find the single commit. If you cannot point to one clear place where the transaction ends, the flow is still fuzzy. Two commits in one service call often mean partial updates and hard-to-replay failures.
- Compare model types with the database rules. If a column can be null, the Python type should say so. If the database fills a default, the model should not pretend the app always sets it first.
- Look at every service function that touches the database. It should either accept a session from its caller or create and close one itself in plain sight. Hidden session creation inside helpers is a common source of odd state and surprise queries.
- Check tests on busy paths and count queries, not just results. A test that proves "this endpoint runs in 3 queries" catches lazy loads before users do.
- Read the query and ask which relations load up front. A new teammate should see that from the code without guessing. If the answer depends on ORM defaults, the code is still too implicit.
This review works well because it stays concrete. You are not asking whether the code "looks clean." You are asking whether a person can trace one session, one transaction, and one loading plan without reading five files.
That is where SQLAlchemy 2.0 patterns help most. They make the right shape of code easier to review. If a teammate can open one service function and tell you where the session starts, where it ends, and which rows it will load, you cut a lot of future bugs before they ship.
What to clean up next
Do not start with a full rewrite. Pick one endpoint that already causes pain: a slow order page, a background job with odd duplicate queries, or a handler that sometimes returns stale data. One noisy path teaches you more than a week of abstract cleanup tickets.
Before you refactor that path, add a small test that counts queries for one normal request and one edge case. That sounds boring, but it saves hours later. When query counts jump after a change, you catch hidden lazy loads and extra refreshes before they reach production.
A simple cleanup order works well:
- choose one endpoint with visible query noise
- add query count tests around its main flow
- make the session boundary obvious in that flow
- replace guessed model fields with typed ones where the query touches them
After that, write a short team rule and keep it close to the code review checklist. It does not need to be fancy. One page is enough if it answers three things clearly: who creates the session, who can commit, and when code may load related rows.
For many teams, the rule looks something like this in plain English: one request or job gets one session, service code owns the commit, and relationships load only when the query asks for them. That alone cuts a lot of accidental behavior. It also makes SQLAlchemy 2.0 patterns feel consistent instead of strict for no reason.
If your service grew through quick fixes, do not assume the cleanup must happen all at once. A staged plan usually works better. Fix the busiest path, copy the pattern to two or three similar handlers, then remove the old shortcuts.
Sometimes an outside review helps, especially when the team can feel the mess but cannot agree on the first move. Oleg Sotnikov works with startups and small teams on practical backend and architecture cleanup, so a short review can turn a vague refactor into a small plan with clear steps, owners, and limits.
That kind of plan is easier to finish, and finished cleanup beats perfect cleanup every time.


