Service boundaries: use support pain to split wisely
Service boundaries work best when you study support pain, repeated incidents, and unclear ownership before you split systems for the wrong reasons.
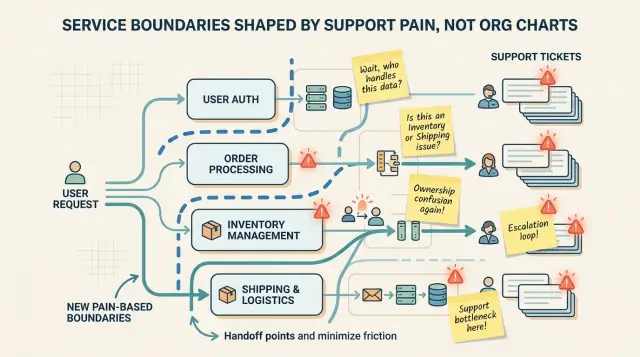
Table of Contents
What problem are you trying to fix
A bad boundary rarely shows up in a diagram first. It shows up on a normal workday when support gets a simple ticket and nobody can answer one basic question: who owns this?
The customer sees one broken flow. The company sees three teams, four services, and a thread full of guesses. Support asks for logs. One engineer checks billing. Another checks auth. A third says the notification service only sends what it receives. Two hours pass before anyone looks at the full path.
That is what this looks like in real life. Tickets bounce. Customers repeat themselves. Small issues turn into long chats because each team sees only its own part. People usually do not design this on purpose. They inherit it.
Org charts make the problem harder to spot. Teams often line up around history, reporting lines, or who built something first. Customers do not care about any of that. They click one button and expect one result. If your internal map splits that action across too many owners, the chart can hide the real product problem.
A fuzzy boundary usually leaves the same traces:
- support cannot tell where the failure starts
- engineers argue about ownership before they debug
- one customer issue needs changes in several services
- each team says, "our part works"
None of those signs proves you need a split on its own. The pattern matters. One messy incident might be bad luck. The same messy incident every week is evidence.
Unclear ownership slows fixes in boring, expensive ways. Every handoff adds waiting time. Each team asks for a different log or screenshot. Temporary patches pile up because nobody owns the whole journey long enough to clean it up. Customers feel the delay, and support absorbs the stress.
That is why boundaries should come from repeated incidents, not architecture taste. If the same ownership confusion shows up across bugs, refunds, failed signups, or missing emails, the split is probably fighting the product.
A good split reduces questions during an incident. Support knows where to send the case. Engineers know where to look first. One team can fix the problem without pulling half the company into a call.
Signs the boundary is blurry
A blurry boundary shows up in support long before it shows up in architecture diagrams. Users report one problem, but your team handles it as three different issues. That gap tells you more than any org chart when you are deciding where to draw the line.
The first clue is ticket ping-pong. Support sends a case to billing, billing sends it to auth, auth sends it to the API team, and the customer waits while everyone checks logs. One handoff is normal. Three or four handoffs for the same kind of problem is not. When that pattern repeats, the split is forcing people to work around the system instead of through it.
Another clue is simple confusion about ownership. If people keep asking "Who owns this?" in chat or incident notes, the boundary is too abstract or too narrow. Good ownership feels almost boring. The team that owns the problem knows it, takes the first look, and pulls others in only when needed.
You should also pay attention when one customer issue crosses too many systems before anyone can fix it. A failed signup might touch the web app, identity, email delivery, CRM sync, and analytics. If support needs five teams just to explain why a user never got access, the customer journey is split in a place that does not match how the problem happens.
The most expensive sign is a bug that keeps coming back with a new name. Last month it was "missing invoice email." This month it is "account not activated." Next month it is "trial ended early." If the same messy handoff sits underneath all of them, you do not have separate problems. You have one broken boundary wearing different labels.
Lean teams feel this faster because there are fewer places to hide vague ownership. That is one reason experienced CTOs often start with incident history instead of diagrams. Repeated support trouble usually tells the truth faster.
Which incidents count as real signals
One ugly outage can push a team toward a split too early. A real signal shows up again and again. If the same customer problem returns over several weeks or months, you are probably seeing a boundary problem, not just a rough patch.
Start with the customer-facing issue, not the internal error. Group tickets into buckets like "payment failed after upgrade," "order status never updated," or "login worked but account data was wrong." Those buckets tell you more than logs that mention five different services.
A fuzzy boundary usually shows up in the path a ticket takes. Support opens a case, one team says "not ours," another team checks one slice of the flow, and the customer waits while people debate ownership. That handoff trail matters.
These patterns are worth tracking over time:
- the same customer problem appears in different queues with slightly different labels
- support cannot name a clear owner without asking several engineers
- two teams fix their own parts, but the whole flow still breaks
- delays come from handoffs more than from the code change itself
- the fix often needs coordinated releases across services
One bad week does not prove much. A cloud outage, a messy launch, or a broken third-party tool can flood support and make everything look like a design issue. Wait for repeat evidence. Six or seven incidents in two months with the same path means more than one noisy weekend.
A simple rule helps: count incidents that expose confusion, not just failure. If checkout breaks and everyone agrees who owns it, you may need better testing or alerts. If checkout breaks and three teams each own one slice of the answer, that points to the boundary.
Support notes help a lot here. Read the ticket comments, handoff history, and incident chat. The strongest signal is often not the outage itself. It is the moment support asks, "Who owns this?" and nobody can answer quickly.
Map the pain before you split anything
Start with evidence from the last 30 to 60 days. Pull support tickets, incident reports, and on-call notes into one place. You want real support trouble, not a theory from a planning session.
Then build a short timeline for each recurring issue. Note the customer action, when support picked it up, when engineering got involved, and every team handoff after that. If the same ticket keeps bouncing between checkout, auth, and billing, that bounce is part of the problem.
For each incident, capture a few facts:
- what the user tried to do
- which team got the ticket first
- where the first wrong guess about ownership happened
- which teams touched the issue after that
- where the bug actually lived
That first wrong guess tells you a lot. It shows where the system feels like one thing to support and customers, but behaves like several loosely connected parts inside the product.
Now compare those timelines with your current service map. If the same incidents keep crossing the same line between services, your system probably mirrors team structure more than user flow. That creates confusing ownership, slower triage, and longer outages than the code alone would cause.
Picture a familiar case. A customer cannot finish payment, so support opens a checkout ticket. Checkout looks fine, so the ticket moves to auth because the session expired. Auth finds no issue and sends it to billing, where someone finally spots stale customer state. The bug matters, but the larger problem is that nobody could name the owner early.
Do not let one loud outage drive a split. Look for repeats: the same handoff, the same wrong first guess, the same delay before the right team takes over. Three smaller incidents with the same pattern usually tell you more than one dramatic failure.
If the map shows a repeated detour, fix that boundary. If it does not, you may not need a split yet. You may just need clearer ownership for the full flow, better alerts, or one team to stay with the issue until it is fully resolved.
A simple way to draw a better boundary
Start with one area that keeps creating support trouble. Maybe refunds fail, users get charged twice, and support keeps bouncing the case between billing, checkout, and account teams. That mess is a better signal than any org chart.
Write down what that area must own from the user's point of view. Keep it end to end. For a billing problem, that might mean creating the charge, confirming the result, storing the receipt, handling retries, and giving support one place to check status.
Good boundaries usually come from one clear promise, not a technical layer. If the promise sounds vague, the line is still fuzzy.
A quick exercise helps. Separate the area into four plain questions: what this service decides, what data it owns, what outside calls it makes, and what support needs to see when something breaks.
This exposes overlap fast. If two services both decide whether a payment succeeded, you have an ownership problem. If one service stores the truth but another service answers support questions, you have another one.
Now replay a few real incidents against the draft boundary. Pick recent tickets, not imagined edge cases. Ask who would have owned the first reply, who could have fixed the problem without waiting on another team, and where support would have checked the status.
Take a subscription example. A customer updates a plan, but the seat count changes in one place and the invoice changes in another. Support sees the mismatch, product says billing owns it, and billing says subscriptions owns it. A better split either gives one service the full job of subscription changes and billing effects, or makes one service the source of truth and the other a simple follower. Shared control is usually where the pain starts.
Finish by naming one team that answers for the result. That team can depend on others, but it owns the customer outcome, the alerts, and the support path. If nobody is willing to take full responsibility, the boundary is not clear enough yet.
A realistic example from a customer flow
A common support ticket looks harmless at first: a customer pays for an upgrade, sees the charge on their card, and still cannot use the paid feature.
Support opens the account record. The plan still says "free." They send the case to the accounts team.
Accounts checks the user profile and finds nothing broken there. The email is correct, the workspace is active, and the customer exists in the system. They move the ticket to billing because the payment may not have gone through.
Billing finds a successful charge in seconds. The invoice exists, the payment cleared, and the refund risk is low. From their side, everything worked. They hand the case to the product team because access did not update.
Now the customer has waited hours, sometimes a full day, while three teams each prove their own part is fine.
The deeper problem is ownership. Nobody owns the full path from "money received" to "access granted." One team owns charges, another owns account records, and another owns feature flags or entitlements. Each team fixes its own piece, but the gap between those pieces stays open.
That gap often comes from small choices that pile up. Billing sends an event. Product reads a cache. Accounts stores plan data in a separate table. A retry fails once and nobody notices because each service reports healthy status inside its own box.
This is where the split starts to matter. If payment rules and access rules keep colliding in tickets, on-call alerts, and manual fixes, the current setup is probably wrong.
A cleaner boundary gives each part of the system one clear job. Billing decides whether money moved. Access decides what the customer can use. The contract between them stays small and boring: payment confirmed, subscription active, subscription canceled, refund issued.
That will not remove every bug. It will make failure easier to spot and give one owner a full customer outcome to watch. When the same ticket keeps bouncing between support, billing, and product, that is not bad luck. It is a map of where the boundary should move.
Mistakes that make support worse
A split can calm support down, or it can turn one messy issue into three separate tickets. The difference usually has little to do with architecture style. It depends on whether the new boundary matches the problem that users and support teams deal with every week.
One common mistake is splitting a system because another company did it. That is how teams copy shapes without copying the reason. A business with millions of orders, strict regional rules, or dozens of product lines may need a separate service where you do not. If your own incidents still point to one simple flow, a split often adds more chasing, more logs, and more blame.
Another mistake is drawing lines around teams instead of user problems. If support keeps seeing one issue across signup, billing, and account access, those parts may need tighter ownership, not separate boxes that mirror the org chart. Users do not care which team owns what. They care that one broken step stops the whole job.
Tiny services with shared ownership are worse than a larger service with one clear owner. When two or three teams can change the same flow, support loses time fast. Nobody knows who should investigate first, and everyone assumes the problem started somewhere else.
Old handoffs often survive after the split, and that creates a hidden tax. Support still sends the ticket to Team A, Team A asks Team B for logs, Team B asks the data team for context, and the customer waits. If the split is real, the handoff model has to change too.
Opinions also do damage when teams ignore support data. The loudest engineer in the room may want cleaner boxes on paper, but repeated incidents tell a better story. Look at reopen rates, time to first useful response, routes between teams, and how often one customer issue touches multiple repos.
Ask a few plain questions before you commit. Does one customer problem still bounce across more than one team? Can support name a clear owner without asking around? Does the split remove a handoff, or create a new one? Do incident notes show the same confusion more than once? If those answers are weak, the split will probably make support worse before it makes anything better.
Quick checks before you commit
A split should make life simpler for customers and for the people who support them. If support still has to guess, chase three teams, and bounce the ticket around, the new boundary did not fix much.
Before you change anything, test the idea against real support trouble. Old incident notes are better than architecture opinions because they show where work actually gets stuck.
A few checks catch bad splits early. Ask support to describe ownership in one sentence. If they cannot say "Billing owns failed charges" or "Identity owns login recovery" without adding exceptions, the line is still fuzzy. Check whether one team can control the full customer outcome. If a password reset needs changes from identity, messaging, and profile teams every time, customers will still feel the gap.
Look for repeated incidents that fail at the same seam. One messy week can be random. The same handoff breaking again and again is usually real evidence. Count handoffs after the split, not just services on the diagram. A good split removes coordination for common issues. A bad one turns one ticket into three.
Decide how you will measure the result before you ship the change. Fewer bounced tickets, fewer reopened cases, and less time spent figuring out ownership are solid signs that the change helped.
A small test often tells you more than a big rewrite. Pick one high-volume issue, such as failed checkout confirmations, and trace who touches it from first alert to customer reply. If the answer includes several teams but no clear owner, you found a seam worth fixing.
Be strict about what "owner" means. The owner is not the team that wrote most of the code years ago. The owner is the team that can diagnose the problem, change the code, ship the fix, and answer support without waiting on two more groups.
If you cannot predict a drop in bounced tickets, stop and rethink the split. A clean design on paper is not enough. Support should feel the difference within a few weeks.
What to do next
Do not redraw half the system. Pick the one boundary that keeps creating repeat tickets, slow handoffs, or the same ownership argument every week. That is usually where a better split helps first.
Keep the first change small. Move one part of the flow under one clear owner, and write down what that owner controls, what they do not control, and when another team steps in. If nobody can explain that in plain language, the boundary is still fuzzy.
Run it as a short trial, not a grand redesign. Two to four weeks is often enough to see whether support gets simpler or the pain just moves somewhere else. During that trial, make one team the first stop for incidents in that area so support does not bounce between inboxes.
Then review what changed. Count how many incidents hit that boundary before and after the change. Track how long support spends finding the right owner. Note how many teams join each incident. Check how often tickets reopen because the first fix missed the real cause.
Numbers help, but read a few incident notes too. A drop in ticket count looks good, yet one messy outage can show that the split is still wrong. If support agents still ask, "Who owns this part?", you still have work to do.
Do not let the org chart decide the result. A clean box on a diagram can still create daily confusion for customers and support. If one team can fix a problem end to end, that is often better than a neat but brittle handoff.
Sometimes an outside review saves time. If the discussion keeps turning into team politics, Oleg Sotnikov at oleg.is can review the incident trail, test the proposed boundary against real support issues, and give a Fractional CTO view without getting pulled into internal turf wars.
If the trial reduces confusion, keep it and document it. If it does not, roll it back, keep the notes, and test the next boundary with the same discipline.
Frequently Asked Questions
How do I know a boundary problem is real and not just a bad incident?
Look at repeated support trouble, not one ugly outage. If the same issue keeps bouncing across teams, support keeps asking who owns it, and fixes need several services at once, your boundary likely fights the customer flow.
Which incidents should I count when I review support pain?
Count incidents that expose ownership confusion. A checkout bug with one clear owner points to testing or alerts. A checkout bug that sends support through billing, auth, and product points to a split problem.
How many repeated incidents do I need before I change a boundary?
Wait for a pattern. Six or seven similar incidents over a month or two usually tell you more than one noisy weekend. Repeats matter most when they follow the same handoff path.
Should I design service boundaries around teams or the org chart?
No. Start with the user action that breaks, then trace who touches the ticket from first report to final fix. Org charts explain history; they rarely explain why support gets stuck.
What does clear ownership actually look like?
An owner should handle the result from end to end. That team should diagnose the issue, change the code, ship the fix, and answer support without waiting on two other groups for every common case.
Should one team own the full customer outcome?
Yes, in most cases. One team should answer for the customer result even if other systems support the flow. That cuts handoffs and gives support one place to start.
Can I test a new boundary without a big rewrite?
Run a small trial first. Pick one high-volume issue, give one team first ownership for two to four weeks, and track whether support spends less time finding the right owner and whether fewer tickets bounce.
What mistakes usually make support worse after a split?
Teams often copy another company's split, mirror the org chart, or keep old handoffs after the change. Support then chases more people, not fewer. Shared control over one flow also creates trouble fast.
What should I measure after I change a boundary?
Watch bounced tickets, reopen rates, time to first useful response, and how many teams join one incident. Read a few ticket notes too. If support still asks who owns this, the change did not go far enough.
When does it make sense to ask an outside expert for help?
Bring in outside help when the discussion turns into team politics or nobody agrees on ownership. A Fractional CTO can review the incident trail, test the proposed split against real support cases, and give you a clear call without internal bias.