Self-hosted GitLab for startups: when it pays off
Considering self-hosted GitLab for startups? Learn when one tool for code, CI, and registry saves time, and when admin work costs more.
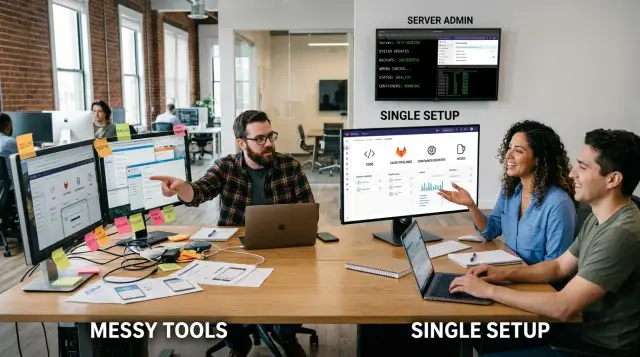
Table of Contents
Why teams end up with too many tools
Most teams do not choose tool sprawl on purpose. It builds up one small decision at a time.
One tool hosts Git. Another runs CI. A third stores container images. A fourth tracks tasks. Each choice feels reasonable on its own, so nobody stops to ask what the full setup will feel like six months later.
The pain rarely appears on day one. It shows up when work crosses tool boundaries. A developer pushes code in one place, a pipeline runs somewhere else, the built image lands in a registry with its own access rules, and the ticket sits on a separate board. Now one broken deploy means checking four places.
Those extra handoffs create a lot of tiny jobs: more logins, more permission rules, more tokens and webhooks, and more settings pages that only one person understands. None of that sounds serious. Together, it eats hours every week.
Build failures also get slower to debug when the evidence lives in different systems. You might see the commit in one tab, CI logs in another, and the missing image tag in a registry nobody opened last week. The fix is often simple. Finding the problem is the hard part.
Small teams feel this faster than large ones. They usually do not have a separate DevOps group to absorb the mess. The same two or three people write code, fix pipelines, manage secrets, and answer product questions. If one engineer becomes the only person who understands the setup, every vacation and every sick day becomes a risk.
That is why self-hosted GitLab starts to look attractive for startups. The appeal is not just fewer vendors. It is fewer gaps between steps, fewer places where context gets lost, and fewer admin chores that slowly become normal. If your team keeps saying, "I know the build passed somewhere, I just need to find it," you are already paying the price.
What GitLab puts in one place
A lot of startup friction comes from a boring problem: the work lives in too many systems. Code is in one app, pull requests in another, CI logs somewhere else, and container images sit in a registry with its own rules. People spend time just reconstructing what happened.
GitLab pulls several of those jobs into one system. The repo, merge requests, CI pipelines, package and container registry, issues, and basic access control can all live under the same project. For a small team, that often matters more than any advanced feature.
When someone pushes code, the rest of the flow can stay in the same place. The branch already belongs to the project. The merge request shows the review. The pipeline runs against that repo. The image lands in the project registry. A teammate can trace the change without hopping across tabs and trying to match names by memory.
That shared context matters more than people expect. You need less glue code, fewer webhook chains, and fewer one-off fixes to keep names, tokens, and permissions in sync across products. A startup usually feels that gain right away.
Access control gets simpler too. One user directory and one permission model means fewer small mistakes, like giving image access to the wrong person or forgetting to remove CI access after a contractor leaves. Those errors sound minor until they pile up.
The other gain is focus. If a deploy fails, a developer can open the merge request, inspect the pipeline, check the artifact, and look at the image tag from the same project view. That saves real time. Even five minutes per change adds up fast over a week.
That is the real draw of GitLab CI and container registry in one place. It is not only about subscription costs. It is about keeping code, pipelines, images, and permissions close enough that a six-person company can follow a change from commit to deploy without playing detective in ten browser tabs.
When self-hosting makes sense
Self-hosted GitLab works best when your team already treats infrastructure as normal work. If you run Linux servers, patch them on schedule, keep backups, and know who wakes up when a disk fills up, adding GitLab is a practical extension of what you already do. It is much less attractive when every server issue turns into a fire drill.
Control is another good reason. Some teams want their code, container images, runners, and access rules under one roof. That matters more when you handle client data, use private networks, or need stricter limits on who can reach build machines. In that setup, keeping GitLab close to the rest of your stack can make daily work simpler.
It also pays off when your builds follow a repeatable pattern. A startup with a few services, one deployment flow, and stable test steps can get a lot from shared runners, shared templates, and one registry. You spend less time stitching tools together and less time asking where a failed build, image, or permission setting lives.
A simple test helps. Self-hosting usually fits when most of these are true:
- Your team already manages updates, backups, and monitoring for other systems.
- Your repos use similar build and deploy steps.
- You want one access model for code, CI, and images.
- You expect to keep this setup for at least a year.
That last point matters more than many founders expect. Moving into GitLab and then moving out again six months later burns time twice. The gain shows up when the team keeps one workflow long enough to standardize it.
A six-person product team is a good example. If they already host staging and production, build Docker images the same way across services, and need private runners for internal deployments, self-hosting can remove a lot of small annoyances. One place for repos, pipelines, and images is easier to manage than five separate tools with five different permission models.
When admin work cancels out the gain
GitLab can replace a pile of separate tools. The catch is simple: someone has to keep it healthy every week. If nobody owns upgrades, backups, storage, access, and runner failures, small problems stack up until they block real work.
Startups usually feel this first when founders become the default admins. A founder fixes one broken runner, then spends Friday night clearing disk space, checking logs, and rerunning jobs. That trade gets bad quickly if sales, hiring, or product work starts slipping because the server keeps asking for attention.
The pain gets worse when your pipelines depend on too many outside parts. Maybe builds pull from a private package mirror, push images to a separate registry, fetch secrets from another service, and rely on custom scripts that only one engineer understands. GitLab still sits in the middle, but every failed pipeline sends the team across four systems to find the cause. You did not really reduce tool sprawl. You just hid it behind one login.
Short outages also hit harder than many teams expect. If GitLab goes down, code review can stop, builds can stop, and deploys can stop at the same time. Even a 20-minute outage can freeze a release or leave engineers waiting to merge work they already finished.
A few warning signs usually appear early:
- No one has a written plan for backups, restore tests, or upgrades.
- Runner health depends on one person noticing failures in chat.
- The team keeps adding one-off fixes to make pipelines pass.
- Founders spend more time on server chores than on product decisions.
Self-hosted GitLab pays off when the admin work stays boring and predictable. If it keeps turning into emergency work, the math changes fast. In that case, a simpler hosted setup or help from someone who already runs GitLab at scale often costs less than the hours your team keeps losing.
How to decide step by step
Start with a time audit, not a feature list. Self-hosted GitLab is worth it when it removes daily friction, not when it simply looks cleaner on a diagram.
Write down every tool your team touches for code, CI, container images, secrets, and access control. Include the small stuff people forget, like a separate runner host, a password vault, or the script someone uses to move images between registries.
Then check where the handoffs fail. If pull requests live in one place, pipelines in another, and images in a third, count the real breakpoints: failed webhooks, permission issues, duplicate users, broken tokens, slow context switching, and time lost during releases.
- List each tool and who owns it.
- Note the failures between tools over the last month.
- Estimate admin time for updates, backups, storage growth, runner care, and user access.
- Move one non-critical project first.
- Compare hours saved against hours spent running GitLab.
Be blunt with the admin estimate. A self-hosted setup needs patching, backups you actually test, disk planning for artifacts and images, runner maintenance, and some security work. If nobody on the team can handle that calmly in a couple of hours a week, the math changes fast.
A pilot will tell you more than a long debate. Pick one active project with normal commits, a small pipeline, and a container build. Run it for a few weeks. Watch how often the team asks for help, how long pipelines take, and whether releases feel simpler or just different.
Plain hours make the decision easier. If the team saves 12 hours a month by cutting tool sprawl but one founder now spends 10 hours on GitLab admin work, that is barely a win. If a capable engineer can keep that admin load near two or three hours, the trade looks much better.
Choose the setup that gives your team fewer moving parts without creating a new part-time job.
A six-person team example
Take a small SaaS team with six people. They ship one main product, push fixes every week, and already feel the drag of using separate tools for repos, builds, and container images. Nothing looks broken on paper. In practice, people keep losing time on small messes.
A token expires, so builds stop. A webhook changes, so status checks stop showing up where people expect them. A build runs, but the image registry does not match the branch or commit the team thinks it does. Someone also breaks the build context, and now two developers spend half an hour guessing whether the problem lives in the repo, the pipeline, or the image step.
That friction does not sound dramatic, but it adds up fast. On a six-person team, losing even 20 minutes a day across a few people can eat a real chunk of a sprint.
So they make one small move. They do not migrate every product, every runner, and every old repo. They pick one active service and move only that service to self-hosted GitLab. The rest stays where it is until the trial proves itself.
The change is easy to feel. A merge request, the pipeline log, and the built image now live in one workflow. When a build fails, the team opens one place and sees the commit, the job output, and the image tag together. That alone cuts a lot of low-grade confusion.
Deploys also get easier to trace. If version 1.8.4 misbehaves in staging, the team can follow it back to the exact pipeline and image without jumping between tools or rechecking old notifications.
After a month, they do not ask, "Do we like GitLab more?" They ask a stricter question: can one person maintain this calmly?
If one engineer can handle updates, runner checks, backups, and disk cleanup without becoming the team's part-time admin, they keep the setup. If that same person spends every Friday fixing runners or reading upgrade notes, the gain is gone. For a small team, that is the line that matters.
Mistakes teams make early
Teams usually get into trouble when they treat self-hosted GitLab like a big switch instead of a gradual rollout. They move every repo in one week, change the release flow, and ask the whole team to adapt at once. That creates stress quickly. One broken pipeline or missing permission can stall work for everyone.
A calmer approach works better. Start with one active repo, one low-risk service, and one small group of developers. Let them find the rough edges first. Then copy what worked.
Backups are another blind spot. A fresh server can look stable for weeks, so teams assume backup jobs are fine. Then they learn too late that a backup file exists, but the restore process fails or takes far longer than expected. Backups only count when you test a restore.
Storage gets missed for the same reason. Repos are usually small. Build cache, job artifacts, and container images are not. A team that builds a few images on every branch can fill a disk much faster than expected, especially with GitLab CI and container registry turned on from day one. The result is messy: failed pushes, broken jobs, and late-night cleanup.
Runner setup also gets pushed into the "we'll do it later" pile. That sounds harmless until pipelines stack up and everyone waits ten minutes for a three-minute job to start. The GitLab server can be healthy while the team still feels slow because runners are underpowered, badly tagged, or too few.
A safer start
- Migrate one or two repos first.
- Test a full backup restore before the team depends on it.
- Estimate storage for images, cache, and artifacts, not just source code.
- Add enough runners for normal peak hours, not quiet days.
- Keep the default workflow until the team has used it for a while.
The last common mistake is over-customizing too early. Teams add custom templates, approval rules, branch tricks, and naming schemes before anyone learns the default flow. That usually makes training harder, not easier. Start with the boring setup. Change it only after the team has real pain to fix.
Quick checks before you move
Moving too early creates a new mess: fewer tools on paper, more work every week. A small team should treat a GitLab move like any other product change. If nobody owns it, it will drift.
Start with clear ownership. One person does not need to do all the work forever, but one person must own upgrades, backups, and restore tests. If a backup runs every night but nobody has tested a restore, you do not have a backup plan. You have a hope.
The same goes for runners. Decide where they will live before you migrate. A runner on a random VM often turns into a forgotten machine with old packages and broad access. Pick the host, decide who patches it, and set a simple schedule for updates.
A short pre-move check helps keep this honest:
- Name the person who owns upgrades, backup jobs, and one recovery drill.
- Decide where runners run and who patches the host and runner images.
- Set a limit for artifact and container image retention so storage does not grow without notice.
- Clean up pipelines until they pass in a repeatable way without manual fixes.
- Write down how you will roll back if the pilot adds work instead of removing it.
Storage is the part teams skip most often. Artifacts, logs, and container images pile up fast, especially when every branch builds an image. Set retention rules before the first busy month. Even a rough cap is better than waiting for the disk alert.
Pipeline quality matters just as much. If your current CI jobs depend on tribal knowledge, self-hosting will not fix that. It will make the problem easier to own, but it is still a problem. Get the pipeline down to a simple path: build, test, package, deploy. If people often rerun jobs by hand or edit variables in a rush, fix that first.
The safest move is a pilot with a rollback plan. Move one service, keep notes for two or three weeks, and count the extra admin time. If the team spends more time nursing the setup than using it, stop and reset.
What to do next
Keep the first move small. If self-hosted GitLab looks like a good fit, start with one active repo, one runner, and one number that tells you if the pilot worked. Pick something concrete, like deploy time, tools touched per release, or hours spent each week fixing CI.
That small test will show the trade-off quickly. If one repo can go from commit to pipeline to image storage in one place, the setup may earn its keep. If the runner fails twice a week and nobody wants to own it, that answer is useful too.
Before you spread it across the team, write down the parts people usually skip:
- how you back up GitLab data and where the backup goes
- how you restore it on a clean machine
- how you upgrade without breaking work in the middle of the week
- who handles runner, registry, or login problems
Keep those notes short, then test them once. A backup plan is only real if someone can restore from it.
Give the pilot a month. That is long enough to catch the boring problems: runner drift, storage growth, slow upgrades, and the small admin tasks that pile up. At the end of the month, compare the result with your starting number.
Keep only what saves real time or real money. If GitLab replaces two or three other services, daily work may get simpler. If the team still needs the old services anyway, hosting GitLab yourself may add more chores than it removes.
If you want a second opinion before you commit, Oleg Sotnikov at oleg.is advises startups on lean infrastructure, CI/CD, and AI-first software operations. He has run self-hosted GitLab, runners, and production observability at scale, so he can usually tell whether a setup fits a small team or whether a lighter option will be easier to live with.
A good pilot ends with a plain answer: expand it, keep it narrow, or drop it.
Frequently Asked Questions
Is self-hosted GitLab a good fit for a small startup?
Yes, if your team already runs servers without drama. Self-hosted GitLab helps most when the same people already handle Linux updates, backups, monitoring, and Docker builds. If every server issue turns into an emergency, a hosted setup usually makes more sense.
When does self-hosted GitLab actually save time?
It pays off when it cuts daily friction. If your team jumps between separate tools for repos, CI, image storage, and access rules, GitLab can save time by keeping that work in one place. The gain shows up in fewer handoffs, fewer broken tokens, and faster debugging.
What can GitLab replace for a startup team?
GitLab can cover your repo, merge requests, CI pipelines, container registry, issues, and user access in one system. That reduces the glue code and webhook chains many small teams build between separate products. You still may keep other tools for secrets, cloud hosting, or observability.
Should we migrate all repos at once?
Skip the big-bang move. Start with one active repo, one normal pipeline, and one runner. That gives your team a safe way to find rough edges before you change every project.
When does admin work cancel out the benefit?
Admin work wins when one person spends too much time on upgrades, backups, disk cleanup, runner failures, and access issues. If a founder loses Fridays to server chores, the setup costs more than it saves. A small team needs boring maintenance, not constant rescue work.
How long should we run a pilot before deciding?
Give it about a month. That usually exposes the boring problems people miss in week one, like storage growth, runner drift, slow upgrades, and restore gaps. A two-day test often looks fine because it misses normal team habits.
What should we measure during the pilot?
Track plain hours, not feature counts. Measure how many tools people touch per release, how long deploys take, how often CI fails for setup reasons, and how many hours someone spends running GitLab. If the pilot saves time without creating a part-time admin job, keep going.
Do we need a dedicated DevOps engineer to self-host GitLab?
No, but you do need clear ownership. One person must own upgrades, backups, restore tests, and runner health, even if others help. If nobody owns those jobs, the setup will drift fast.
What problems show up first after migration?
Storage and runners usually bite first. Artifacts, logs, caches, and container images grow faster than most teams expect, and underpowered runners make short jobs wait in line. Set retention rules early and size runners for busy hours, not quiet days.
When should we avoid self-hosted GitLab and keep a hosted setup?
Stay hosted when your team lacks time for maintenance, your pipelines change every week, or your setup still depends on too many outside systems. If GitLab only hides the sprawl behind one login, you will still chase failures across several tools. In that case, a lighter stack or outside help will cost less.


