Second integration problems start when demos become real
Second integration problems start when custom field mapping, retries, and client rules stack up. Learn what changes after the first demo.
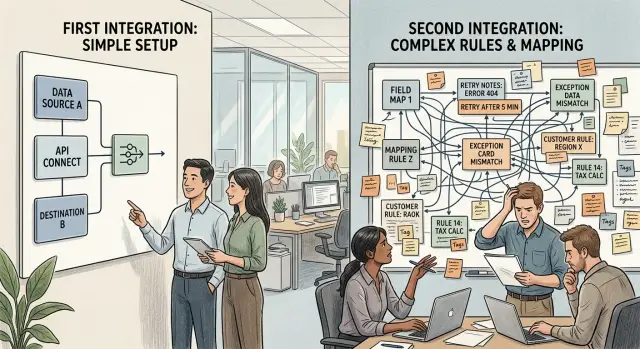
Table of Contents
What changes after the first integration
The first integration often feels easy because you build around one clean example, not a week of real traffic. One customer sends one kind of record in one format and expects one result. You move data from one app to another, see it work, and call it done.
That is the happy path. A new order arrives, your system reads it, sends the right fields to the other tool, gets a success response, and marks the job complete. Nothing is missing, nothing is duplicated, and nobody changes the data halfway through.
Daily use is rougher. People rename fields, leave blanks, resend the same request, or expect old data to stay in sync after an update. APIs slow down. Temporary failures happen. Each side has its own idea of what counts as valid.
The code that looked tiny in a demo starts collecting checks, exceptions, and "just for this customer" logic. The work stops being about one successful flow and starts being about all the ways that flow can bend without breaking.
The first customer often hides that mess. Their process may be simpler than average, their data may be cleaner, and their team may be willing to work around your limits. The integration works, but part of that success comes from a lucky match between their process and your assumptions.
The second customer breaks those assumptions fast. They use different field names, different statuses, different timing, and a different idea of what "done" means. What looked like one reusable integration turns into a shared base with a growing layer of custom mapping, retry rules, and customer exceptions.
That shift changes the workload more than most teams expect. You are no longer building a demo flow. You are supporting a living process with edge cases, support tickets, and exceptions that keep coming back. Each one sounds small. Together, they change estimates, testing time, and day to day maintenance.
Where the extra work comes from
The first version of an integration usually follows the clean path. One record comes in, one record goes out, and both systems agree enough to make the demo work. The extra work appears when real data shows up and the systems stop speaking the same language.
The code still moves data, but now it has to translate, guess, delay, retry, and sometimes refuse to sync at all.
Fields are usually the first problem. One app stores a full name in one field, while the other splits it into first and last name. One system allows several phone numbers, while the other accepts one. A sales tool may keep a single "owner" field, while the billing tool wants both an account manager and a finance contact.
That mismatch creates mapping work. Someone has to decide what goes where, what gets dropped, and what happens when the source data does not fit.
Status values add another layer. A lead can be "new" in one system, "open" in another, and "pending review" somewhere else. Those labels look close, but teams often use them differently.
Once you map statuses, edge cases show up fast. Does "inactive" mean closed, paused, or deleted? If one tool has five stages and the other has three, you either lose detail or add rules to preserve it.
Blank values look harmless until they start driving behavior. If a customer record has no country, should the integration use a default, leave it empty, or block the sync? Each choice can affect taxes, routing, notifications, or reporting.
Defaults turn into customer rules almost immediately. One customer wants blank values rejected. Another wants the system to fill in "United States" and keep moving. A third wants that rule only for one business unit.
Timing problems make everything worse because they stay hidden until traffic grows. An update can arrive twice. A webhook can arrive before the related record exists. Two systems can edit the same record within seconds and overwrite each other.
That is why retry logic needs more than "try again in 30 seconds." If the integration retries without checking whether it already created the record, you get duplicates. If it gives up too early, you miss updates and nobody notices until support tickets pile up.
Most integration complexity does not come from moving data. It comes from deciding what the data means, what to do when it is incomplete, and which system wins when timing gets messy.
A simple example with two customers
Customer A looks easy at first. They send one contact record with a name, email, phone number, and company. Your app maps those fields, saves one contact, and sends the result back. They want instant sync because their sales team expects new records to appear right away.
That version feels clean. One event comes in, one record goes out, and the team can explain the whole flow on a whiteboard in two minutes.
Customer B changes the shape of the work. They do not send one contact. They split the same real world person into several records: a primary contact, a billing contact, and a shipping contact. Those records may share a company, but they do not always share the same email, phone, or address.
Now the team has to answer questions that never came up with Customer A. Should the app merge those records into one profile? Should billing and shipping stay separate? If two records disagree, which one wins?
The sync timing changes too. Customer A wants updates right away. Customer B wants one batch job at night because their staff reviews changes before import. So the team no longer supports "contact sync" as one feature. They support two rule sets for what sounds like the same feature.
The difference is simple on paper. Customer A sends one record and expects one result. Customer B sends several related records and expects the app to sort them out. Customer A wants changes in seconds. Customer B wants a scheduled import after business hours.
The code still sounds simple when people describe it out loud, but the behavior is no longer simple.
The team now needs custom mapping, merge rules, batch scheduling, duplicate checks, and better logs so support can explain why one company ended up with three contacts instead of one. Even the test cases multiply fast. A bug fix for Customer A can break Customer B, even though both customers asked for what looked like the same integration.
After two customers, the job is no longer "connect system X to system Y." The job is "keep two different business processes working without mixing them up." That is the point where demos stop helping and real integration complexity shows up.
How to map data without losing track
Field mapping fails when nobody decides what each value means, who owns it, and how it should change on the way through. The first demo often skips that work because both sides use neat sample data. Real systems do not.
Start with a plain list of every field you send and receive. Put both systems side by side, and do not stop at the obvious ones like name, email, and status. Small fields cause just as many problems: middle name, country code, tax ID, opt in flag, archived state, and internal notes.
Keep one mapping table
Use one shared table for the integration and update it when rules change. A spreadsheet is fine if the team actually maintains it.
For each field, record the source name, the destination name, which system owns the value, the conversion rule, and what happens if the value is blank or wrong.
Ownership matters more than people expect. If the CRM owns the company name, the support tool should not send it back later and overwrite it. If both systems can edit the same field, you need a clear tie breaker or the data will drift.
Write conversion rules in plain language. Do not leave them in someone's head. "CA" might need to become "California." "Active" in one system might mean "Paying" in another. Dates, currencies, status labels, and phone numbers often need cleanup before they can land safely.
Blanks need rules too. An empty value can mean three different things: clear the field, leave the old value alone, or reject the record. Pick one behavior for each field. Bad input needs the same treatment. If a postal code is malformed, decide whether you skip that field, block the whole record, or send it to review.
Test the mapping with real records, even if they are messy. Sample data rarely includes duplicate contacts, missing addresses, odd status values, or names with extra spaces. One batch of real records will usually expose more problems than a week of clean demos.
A mapping document should feel boring. That is a good sign. Boring means fewer surprises later.
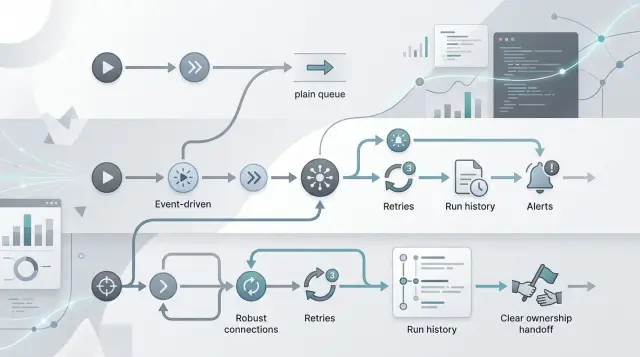
How retries add hidden behavior
A retry changes more than timing. It changes what your integration does after the first failure, and that can turn a simple sync into a messy chain of side effects.
In a demo, a failed request looks obvious. In production, a timeout, a rate limit, and a bad payload can all look like the same red error badge, even though only some of them deserve another attempt.
Retry only when the failure might clear on its own. Short network drops, temporary 502 errors, and rate limits usually fit. Bad input, missing permissions, and rejected business rules do not. If a customer record misses a required field, five more attempts will not fix it.
The first version often assumes that "try again" is harmless. It is not harmless when the first request may have worked and only the response got lost.
A common example is contact creation. Your app sends "create contact," the other system saves it, but the connection drops before your app gets the success response. If you retry without a stable ID, you may create the same contact twice. Use an idempotency key, an external record ID, or another unique reference that stays the same across attempts.
A few rules keep retries under control:
- Retry temporary failures, not data or permission errors.
- Set a hard limit on attempts.
- Add delays between attempts instead of retrying in a tight loop.
- Store a unique ID so repeated attempts do not create duplicates.
- Send repeated failures to a person after the limit.
Logging matters as much as the retry itself. Record the attempt number, the record ID, the error code, and a plain reason such as "missing customer tax ID" or "partner API timeout." Clear logs save hours when support asks why one customer synced and another did not.
You also need a human handoff point. After two or three failed attempts, move the record to a review queue or alert the team. That gives someone a chance to fix the mapping, reconnect the account, or correct the data before the integration keeps making the same mistake.
How customer rules pile up quietly
Most integration code starts clean. Then sales promises that one customer can keep an old status name, another needs blank phone numbers turned into "N/A," and support asks for a manual resend button because one account imports late every Friday.
None of those requests looks risky on its own. The trouble starts when each one lands as a tiny exception in a different place. One rule sits in a mapper, another in a background job, another in an admin script.
After a few months, nobody can answer a basic question: why does this customer behave differently? At that point, the problem stops looking like a bug and starts looking like team memory loss.
Picture a simple order sync. Customer A wants canceled orders skipped. Customer B wants canceled orders sent with a special code because their finance team still checks them by hand. Later, support adds a one click retry for B only because their ERP locks records for ten minutes at midnight. Now one order sync has three versions.
These rules usually hide in sales notes, onboarding docs, support playbooks, late hotfixes, admin toggles with unclear names, and one time scripts nobody owns anymore.
That spread makes testing hard fast. A small change to one status map can break one customer on retries, another on backfills, and a third only on partial updates. The team feels it as random regressions, even when the code change looked small.
Old exceptions rarely leave. The customer may not need them anymore, but nobody wants to remove code tied to billing, orders, or account data without proof. So the rule stays, then someone copies it into the next service "just to be safe."
If you keep only one habit, make it this: track every special rule in one plain list with the customer name, the reason, the owner, and the date you last checked it. Hidden behavior becomes visible, testable, and easier to delete.
Mistakes that make integrations harder
Most second integration problems do not start with the API. They start with shortcuts that feel harmless when one customer is live and nobody is under pressure yet.
The first mistake is scattering special cases across the codebase. One if customer == X in a mapper turns into another in the webhook handler, another in retries, and another in reporting. After a month, nobody knows which rule wins. Keep customer rules in one place, even if that place is boring to build.
Another common mistake is mixing business rules with sync code. If the same function decides both how to call an external API and whether a customer can send partial orders, changes get risky fast. A small policy change now means touching transport code, tests, and error handling at the same time.
Skipping logs until launch week is another classic mess. When a sync fails, teams need to see what they sent, what they got back, which mapping version ran, and whether the retry changed anything. Without that, people guess. Guessing burns days.
A short checklist helps:
- Keep customer rules in config or one rule layer, not in random files.
- Separate transport code from business decisions.
- Log failed payloads, response codes, retry count, and mapping version.
- Test with ugly data, not just clean sample records.
- Write a note every time a mapping changes.
Test data causes more pain than most teams expect. Demo records are tidy. Production records are not. Names arrive too long, required fields are blank, dates use the wrong format, and two systems disagree on what "active" means. If a team tests only with perfect data, launch week turns into cleanup week.
Mapping changes also need version notes. This sounds dull, but it saves real time. If Customer B starts sending account_owner instead of owner_name, someone should record when the change happened, why it changed, and which customers use it. Otherwise an old retry can replay data with yesterday's rules.
That kind of discipline is cheap early and expensive later. Clean boundaries, plain logs, and dated mapping notes do not look impressive. They keep integrations from turning into a pile of exceptions.
A quick check before the next integration
Before you agree to the next build, stop and count the parts that make it different. Teams usually get in trouble when they say, "This one is almost the same," and skip the count.
Count every field mapping, not just the obvious ones. Include renamed fields, default values, status conversions, and any data the team must split or combine. Count every retry path too. Timeouts, rate limits, duplicate requests, partial success, and out of order updates all need a decision.
List each exception in plain language. If one customer wants a special rule, write down the rule and why it exists. Then decide how the team will find and fix failures. They need request IDs, clear logs, the last retry reason, and a way to see what data changed.
Do not forget support after release. Manual fixes, customer questions, replaying failed jobs, and backfilling missing records are part of the cost.
Ownership matters as much as the code. Every customer rule needs a name next to it. Who approved it? Who can change it? Who will say no when the next customer asks for the same thing with one small twist? If nobody owns the rule, it usually stays forever.
You should also ask one awkward question early: can the customer use the standard option instead? Many custom requests sound harmless because they arrive one at a time. A special status label, a custom date format, a different retry delay. Each one looks small. Together they make the integration harder to test, explain, and support.
A simple estimate shows the gap. If the team expects two hours of coding and ignores six mappings, three exception rules, and support tickets after release, the estimate is fiction. If they count those items first, they can price the work honestly or trim the scope before it turns messy.
If the answer to any of these checks is "we'll decide later," the project is already bigger than it looks.
What to do if the stack already feels messy
Messy integration code rarely means the team is careless. It usually means small fixes kept piling up until nobody could see the whole shape anymore.
The first fix is not more code. The first fix is drawing a line between shared behavior and customer behavior. If one customer needs a field renamed, another needs a delayed retry, and a third needs a special tax rule, those rules should live in a clear config or one shared rule layer. They should not sit half in the API client, half in background jobs, and half in a helper file.
A cleanup usually starts with a few simple moves. Put mapping rules in one place with names people can read. Send logs, retries, and failed events to one system instead of scattering them across tools. Review what sales or account teams promised before building the next exception. Remove custom behavior that nobody uses or that saves almost no time for the customer.
That review matters more than teams expect. A lot of mess starts before engineering writes anything. Someone says yes to a special export, a custom status, or a one time sync rule. Six months later, the team still supports it. If a promise adds maintenance every week but gives the customer little real benefit, push back early.
Centralized failure tracking also changes daily work. When logs live in one place and failed events follow one format, support gets faster and engineers stop guessing. A single failed order, invoice, or contact sync should be easy to find without checking three dashboards and two inboxes.
If the stack already feels tangled, an outside reviewer can help. Oleg Sotnikov at oleg.is works with startups and small teams on architecture, infrastructure, and Fractional CTO problems, and this kind of integration cleanup is often easier once someone maps the shared rules, customer exceptions, and support burden in one place.
The goal is modest: fewer hidden rules, fewer surprise failures, and fewer customer requests that turn into permanent code.
Frequently Asked Questions
Why does the first integration feel easy?
The first build usually follows one clean path with tidy sample data and one customer process. Real traffic adds missing fields, duplicate requests, slow APIs, and people who change data in the middle of the flow.
Why does the second customer create so much more work?
The second customer exposes assumptions you did not know you made. They use different field names, statuses, timing, and approval steps, so your team stops building one flow and starts supporting several versions of the same flow.
What usually breaks first when real data shows up?
Field mapping usually breaks first. Two systems store the same real thing in different shapes, so your team has to decide how to split, merge, clean, or reject data instead of just moving it across.
How should I map data so the team does not lose track?
Start with one shared mapping table that shows every field in both systems. For each field, write the source, destination, owner, conversion rule, and what your app should do when the value is blank or wrong.
How do I decide which system owns a field?
Pick one owner for each field and write that down. If both systems can overwrite the same value without a clear rule, the data will drift and support will spend time fixing the same records again and again.
When should I retry a failed sync?
Retry only when the problem might clear on its own, like a timeout, rate limit, or short API outage. Do not retry bad input or permission errors, because your app will just repeat the same failure.
How do I prevent duplicate records during retries?
Give every create or update attempt a stable unique reference. If the first request succeeds but your app loses the response, that reference lets the next attempt find the same record instead of creating another one.
How do customer-specific rules get out of control?
They pile up when each customer request lands in a different file, job, or admin tool. Keep every exception in one plain record with the customer name, reason, owner, and review date so your team can test it, explain it, and delete it later.
What should I log for an integration?
Log the record ID, attempt number, mapping version, request result, and a plain reason for the failure. Clear logs let support answer simple questions fast, like why one order synced and another stopped.
What should I do if my integration stack already feels messy?
First, separate shared behavior from customer rules. Then move mappings, retries, and failure tracking into clear places, remove old exceptions nobody uses, and review every new promise before you add more custom code.