Rust sidecars for hot paths in Go and Python systems
Rust sidecars for hot paths can cut latency and CPU cost in Go or Python systems without a full rewrite. Learn when the tradeoff makes sense.
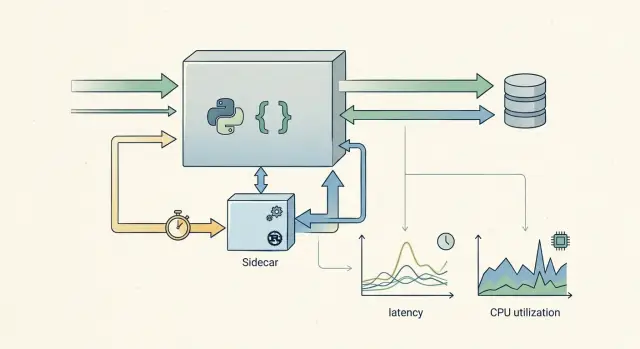
Table of Contents
Why teams reach for a rewrite too early
A rewrite often starts with a real pain point, but the pain is usually smaller than it looks. One API endpoint pushes most of the p95 latency up, or one background job eats CPU for minutes at a time. The rest of the app may be boring and fine. Users can log in, billing works, deploys are stable, and most requests finish fast.
Still, teams see a slow path and assume the whole stack is wrong. That is a costly jump. If a Python worker spends 80 percent of its time in one parsing step, rewriting the web app, admin panel, and support tools will not fix the actual choke point any faster. It just makes the project bigger.
The pressure is easy to understand. A slow path hurts every day. It can delay a checkout, hold up a report, jam a queue, or force you to pay for larger servers than you really need. When cloud spend climbs or customers feel lag, a rewrite sounds clean. It feels like a once-and-for-all fix.
But full rewrites drag in parts that were never the problem:
- auth and session handling
- billing flows and edge cases
- deployment scripts and runbooks
- test suites and monitoring
- old integrations nobody wants to touch
That is where months disappear. The team stops working on the bottleneck and starts rebuilding the plumbing around it.
A small example is enough. Say a Go service is quick on almost every route, but one endpoint does heavy document conversion and drives most tail latency. Rewriting the whole backend in Rust means rebuilding many stable parts just to speed up one path. A focused service for that conversion job can cut latency and CPU use much sooner.
Teams reach for a rewrite early because the slow part is loud. The rest of the system is quiet, so people stop seeing it. Quiet, stable code has value. If most of your backend already works, treat the hotspot like a hotspot, not like a reason to rebuild everything.
What a Rust sidecar actually does
A Rust sidecar is a small service that handles one expensive job while the main app stays in Go or Python. You do not replace your API, worker stack, admin tools, or database code. You carve out one narrow task that burns too much CPU, too much memory, or too much time.
That task is usually easy to name. It might be document parsing, image processing, log filtering, rules evaluation, tokenization, or a ranking step that runs on every request. If one part of the system is slow and the rest is fine, Rust sidecars for hot paths make more sense than a full rewrite.
The shape should stay simple. The Go or Python app sends a small request with the data the Rust service needs. The Rust service does the heavy work and returns a clear response. No shared business logic, no hidden state, no giant protocol if a plain JSON or gRPC call does the job.
Good sidecars usually have a few traits:
- They solve one problem, not five.
- They run only where the slow path needs help.
- They have clear input and output.
- They can fail without taking down the whole app.
That last point matters. If the sidecar is down, your main system should still know what to do. Maybe it falls back to the slower code path, skips an optional step, or queues the work for later. A sidecar is a targeted speed tool, not a new single point of failure.
Release cadence is another big part of the win. You can ship fixes to the Rust service without touching the rest of the backend. That keeps risk low. A Python team can keep moving in Python, while one engineer improves the bottleneck in Rust and measures the result.
Think of it like this: your main app stays the front desk, the scheduler, and the manager. The Rust service becomes the specialist in the back room. It handles the one hard job quickly, then gets out of the way.
When the small service pays off fast
A small Rust service pays off when one narrow part of the system runs so often that even a modest speedup changes the bill, the queue length, or the user experience. You do not need a whole backend in trouble. You need one path that gets hit all day and wastes enough CPU to matter.
Frequency matters more than drama. A request that is 300 ms too slow but runs ten times a day is annoying, not urgent. The same request on every API call, report build, or file upload is different. Save 80 ms on a path that runs a million times a month, and the gain adds up fast.
Rust sidecars for hot paths work best when profiling shows local compute is the problem. Think image processing, ranking, parsing, rule evaluation, encryption, deduplication, or heavy JSON work. If the delay mostly comes from PostgreSQL, Redis, or an outside API, a faster language will not fix much. The database or network still sets the pace.
Stable inputs and outputs matter just as much as raw speed. If the request shape changes every sprint, the glue code will cost more than the runtime win. If the contract stays mostly fixed for a few months, a sidecar is much easier to own. The Rust code can stay small, tested, and boring.
A quick gut check helps:
- The same path runs often enough that small savings stack up.
- Profiling points to CPU work, memory churn, or serialization.
- The input and output format stays mostly unchanged week to week.
- Faster execution saves enough time or cloud spend within a few months.
- One engineer can own the Rust code without stalling product work.
That last point decides a lot of projects. Benchmarks look nice in a slide deck, but ownership decides whether the win lasts. If the team can keep one small Rust codebase healthy, a sidecar is often the cheaper move. If the new service needs shared business logic, constant protocol changes, and half the team to maintain it, you are already drifting toward a rewrite.
Pick the hot path before you pick Rust
Teams often pick Rust because the whole system feels slow. That is usually the wrong starting point. Pick one endpoint, one queue worker, or one batch job, then measure that unit on its own.
Look at three numbers first: CPU use, memory use, and p95 latency. Do this per endpoint or per job, not for the whole app. Averages hide the pain. One noisy path can eat most of your compute while the rest of the service is fine.
Then split the time inside that path. Ask how much time goes to the network, how much goes to the database, and how much is pure compute. If a request spends 280 ms waiting on Postgres and 40 ms doing work in Python, a Rust sidecar will not fix the real problem. If the same request burns 180 ms on parsing, scoring, compression, or hashing, that is a better target.
Serialization is another common trap. Before moving code, check the cost of JSON encoding, protobuf work, and plain data copying between processes. Sometimes the slow part is not business logic at all. It is turning large objects into bytes, then turning them back again.
Small, busy paths win first. Cold admin screens and low volume reports rarely pay back the extra service, deployment, and monitoring work.
A good target usually looks like this:
- it runs often enough to matter
- it does heavy compute in a small area of code
- it has clear inputs and outputs
- it can fail without taking down the whole app
- it can show a speed or cost win by itself
That last point matters most. Rust sidecars for hot paths pay off when the unit is small and the result is easy to measure.
A simple example: a Go API has a search ranking step with p95 at 220 ms. Database time is 25 ms, network time is 15 ms, and the rest is scoring and filtering in memory. That scoring step is a clean candidate. A monthly export job that runs for six minutes but only twice a month is not.
Pick the bottleneck that can win alone. Leave the rest of the backend where it is.
A simple rollout plan
Start with a baseline, or you will end up arguing from gut feeling. Write down the numbers for the slow path today: p95 latency, CPU use on the busy service, error rate, and the monthly cost tied to that path. If the path runs in a worker, track queue time too.
A small table is enough:
- How long the request or job takes at p50 and p95
- How much CPU and memory the current code burns under normal load
- How often it fails, times out, or retries
- What that traffic costs in compute each month
Then keep the first Rust change boring and narrow. Do not rebuild the whole request chain. Move one function, parser, matching step, image transform, or scoring routine into a sidecar and leave the rest of the flow alone.
That choice matters more than language purity. A Go API with a Python worker can still get a real win if only one heavy step moves to Rust.
Set a hard timeout around the sidecar call from day one. If the call fails, return to the old code path or skip the optimization and finish the request the old way. The fallback protects users while you learn how the new piece behaves under real traffic.
Keep the boundary simple. Pass a small payload, return a small result, and log both timing and errors on each side. If the sidecar needs five network calls and three shared caches, the rollout will drag.
Release it in small slices. Start with internal traffic, then a tiny share of production, often 1 to 5 percent. If that looks clean, raise it in steps while you watch the same baseline numbers you captured at the start.
A mixed stack example makes this concrete. Say a Python service spends 40 percent of its time on text parsing before a Go API returns a result. Rewriting both services is months of risk. Pulling only the parsing step into a Rust sidecar can take days, and the comparison is easy to see.
Give the test one or two weeks. Compare before and after numbers, not just speed on a laptop. If latency drops, CPU falls, and on-call noise stays flat, Rust sidecars for hot paths are paying for themselves. If the gains are small or the new service adds too much operational work, stop there and keep the old path.
A realistic example in a mixed stack
A small startup has a familiar setup. Its public API runs in Go because the team wants simple deployment and steady request handling. Its document pipeline runs in Python because the team already uses Python libraries for AI calls, prompt logic, and business rules.
The trouble starts on every file upload. Before the model does anything useful, the system has to clean raw text, strip broken formatting, split content into chunks, and prepare metadata for search or retrieval. None of that work is glamorous, but it burns CPU on every request.
At first, the team talks about a full rewrite. That sounds clean on paper. In practice, it means touching the API, the worker queue, the model layer, and a pile of tests that already work well enough.
They take a smaller path instead. They keep Go for the API. They keep Python for model calls, document rules, and post-processing. They move only parsing and chunk preparation into a Rust sidecar.
The request flow barely changes. Go still accepts the upload and stores the file. Python workers still decide which model to call and what to do with the result. When a worker needs clean text and chunks, it sends the raw document to the Rust service and gets back a compact response with normalized text, chunk boundaries, and token estimates.
That one move can cut CPU load fast because the expensive loop sits in one place. The team does not retrain everyone. They do not replace working code. They improve the part that repeats thousands of times a day.
The gain is not magic. Rust will not fix slow prompts, bad queue settings, or oversized files. But for text parsing and chunk prep, it often wins because those steps are predictable, CPU-heavy, and easy to isolate behind a small API.
This is usually where rewrite vs sidecar becomes obvious. If 80 percent of the slowdown comes from one narrow stage, a Rust service for bottlenecks pays off sooner than a language migration. The backend stays familiar, incidents stay easier to manage, and the next upload no longer pegs every worker at once.
Mistakes that erase the win
A Rust sidecar helps when you isolate a small, expensive part of the system. The win disappears when teams move the wrong work.
The most common miss is moving code that mostly waits on the database. If a handler spends 40 milliseconds on SQL and 3 milliseconds on app logic, Rust will not rescue it. You just add another service hop, another deployment, and another place to debug. Fix the query, index, cache, or data shape first.
Another mistake is starting with a sidecar that tries to do everything. A wide API with many routes looks tidy on a diagram, but it turns a small experiment into a second backend. Now the team has two auth paths, two release cycles, two sets of client code, and twice the odds of subtle bugs. A sidecar should do one narrow job well, such as scoring, parsing, image work, or a tight compute loop.
Teams also lose weeks by changing too much at once. If you switch language, alter schemas, replace queue behavior, and change service boundaries in one release, nobody knows what caused the gain or the outage. Keep the rest of the system boring. Let the sidecar speak a simple contract and return one result your current app already understands.
Operations mistakes hurt just as much as code mistakes. If you skip logs, traces, basic metrics, and a rollback path, you are guessing in production. That gets expensive fast. A sidecar needs:
- request and error logs that match the caller
- latency and timeout metrics
- tracing across the app and the sidecar
- a feature flag or fallback path
- a simple way to turn it off
One more trap is chasing tiny speedups on paths users barely hit. Saving 8 milliseconds on a once-a-day admin task is not a win. Saving 300 milliseconds on checkout, search, or a heavily used API often is. Measure traffic first. Then pick the path that burns the most CPU time or delays the most real users.
Small sidecars work best when they stay small. The moment the sidecar starts attracting unrelated work, the rewrite you avoided sneaks back in through a side door.
A quick yes-no check
A Rust sidecar makes sense when one narrow problem causes most of the pain. If the whole app feels slow, but no single endpoint or job clearly dominates CPU time or tail latency, a split usually adds work without much gain.
Ask five plain questions.
- Does one request path, background job, or parsing step eat a big share of CPU time or p95 latency? If the answer is no, keep profiling. Rust helps most when the bottleneck is obvious.
- Can you describe the handoff in a small, stable contract? A sidecar works best when input and output fit into a few fields, such as text in, score out, or batch in, normalized records out.
- Will the main Go or Python app stay easy to read after the split? If the old code turns into a thin wrapper around five remote calls, you moved complexity instead of removing it.
- Can your team ship the sidecar, add metrics, and turn it off the same day if it misbehaves? If rollback needs a week of coordination, the risk is too high for a small performance project.
- Will traffic volume pay for the extra moving part? Saving 40 ms on a path hit ten times a day is nice, but it will not cover the cost of another deploy, monitor, and on-call surface.
Most teams should want at least four yes answers before they build anything. Three yes answers can still work, but only if the bottleneck is expensive enough to hurt users or cloud spend every day.
A simple example: a Python API handles uploads well, but one image transformation step burns most of the CPU. The request shape is fixed, the Rust service can expose one endpoint, and the team can measure success in a few hours. That is a good sidecar case. Rewriting the full API is not.
If the check fails, stay boring. Tune queries, cache the result, batch the work, or fix waste in the current code first. A sidecar should remove pain, not create a new hobby.
What to do next
Start with evidence, not gut feel. Spend a week profiling the system in production or a close copy of it. Rank the hottest paths by real cost: CPU time, memory pressure, queue buildup, timeout rate, and p95 or p99 latency. A slow endpoint that runs twice a day is rarely worth a new service. A small function that runs on every request often is.
Once you have that list, pick one path and draw the smallest contract that could pay off. Keep it boring. One request shape, one response shape, clear error handling, and a strict timeout. If the sidecar needs five network calls and shared state on day one, it is already too big.
A simple filter helps:
- Choose work that is easy to isolate, like parsing, scoring, compression, transformation, or a tight compute loop.
- Skip flows that depend on half your database schema or lots of cross-service chatter.
- Estimate the win in plain numbers, such as saving 40 ms on 30% of requests or cutting one worker pool in half.
- Set a stop rule before you start. If the prototype misses the target, keep the old path.
Plan operations before you write Rust. Decide how you will deploy it, who owns alerts, what metrics you will watch, and how you will roll back in minutes. That usually means a feature flag, shadow traffic or canary traffic, request tracing, and side-by-side measurements against the old path. If you cannot observe the new service, you cannot trust the result.
This is where Rust sidecars for hot paths usually win faster than a rewrite. You limit the blast radius, keep the rest of the Go or Python system stable, and learn from one narrow change instead of betting the whole backend.
If you want an outside review, Oleg Sotnikov can assess the hot path, the infra fit, and the rollout plan in a fractional CTO role. A good review should end with a short build list, a rollback path, and one metric that decides whether the sidecar stays.


