Rust serde for unstable APIs: patterns that survive change
Rust serde for unstable APIs helps you parse partial fields, keep unknown values, and stay calm when vendors add, rename, or change JSON.
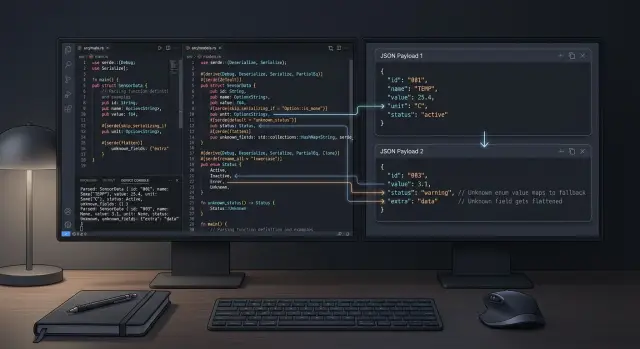
Table of Contents
Why vendor payloads break
A client can work for months, then fail because one upstream team made a "small" change. Maybe amount used to be a number and now arrives as a string. Maybe customer_email disappears when the vendor adds privacy rules. Maybe a field that always held a value suddenly comes back as null for old records.
None of those changes look dramatic in the vendor dashboard. In your Rust code, they can stop deserialization at once.
This happens because API payloads change in messy ways:
- fields go missing
- fields become
null - numbers turn into strings
- enums get new values
- extra objects appear without warning
A strict model is nice when you control both sides. At the API edge, it can be too fragile. If your struct says a field must exist and must be an integer, serde will reject the whole payload when the vendor sends anything else. That is often correct inside your own system. It is often too rigid for outside data.
A common failure looks like this: you only need id, status, and created_at, but your model tries to map the full response because it feels neat. Later, the vendor changes an unrelated nested field from an object to an array. Your code breaks even though the three fields you care about still arrive exactly as before.
That is why Rust serde for unstable APIs needs a different mindset. The goal is not "accept everything". That hides real bugs. The goal is narrower: accept harmless change, reject real contract violations, and keep enough raw data to inspect new cases later.
Good API clients draw that line on purpose. They stay strict about fields that drive business logic, like an event type or payment status. They stay flexible about everything else, especially optional metadata and vendor-owned extras.
That balance keeps your client alive when payloads drift, but still lets you catch the changes that would corrupt state or trigger the wrong action.
Decide what must stay strict
When a vendor payload shifts every few weeks, do not make every field equally strict. Save strict parsing for the fields that control behavior. IDs, stable references, and status values usually belong in that group. If id is missing, or a billing status arrives in a shape your app does not understand, failing early is often the safer choice.
Everything else can stay loose for a while. Labels, notes, display names, tags, and random metadata often change first. Those fields rarely need to block the whole request. In practice, Option<T>, default values, or a catch-all JSON field give you room to keep shipping while the vendor keeps changing things.
That is the practical side of Rust serde for unstable APIs. Strictness should follow business impact, not personal preference.
A good pattern is to keep two models. The first model mirrors the vendor payload as raw input. The second model is your app's cleaned-up view of that data. This split matters. Your raw model can accept missing notes, unknown extras, and odd formatting. Your app model can still say, "we only process records with a valid internal ID and a supported status."
#[derive(serde::Deserialize)]
struct VendorOrder {
id: String,
status: String,
label: Option<String>,
note: Option<String>,
#[serde(default)]
extra: serde_json::Value,
}
That raw struct does not decide whether an order is payable, active, or safe to show. Your own code decides that later. This keeps vendor noise out of your business rules.
A simple test helps:
- If the field changes app behavior, keep it strict.
- If the field only changes display text, make it optional.
- If you do not use the field today, store it or ignore it.
- If a new field might matter soon, keep the raw value for one release.
That last point saves a lot of pain. Say a vendor adds review_note or priority_label. You may not need either field today. Still, if you preserve the raw payload or collect unknown fields, you can inspect real data later without rushing a hotfix. Strict where the app can break, loose where the app can adapt. That balance makes clients last longer.
Parse partial fields on purpose
Most vendor payloads do not stay neat for long. A field disappears, a number turns into a string, or one endpoint returns a slimmer version of the same object. If your Rust types mirror the full JSON too closely, small upstream changes can break code that only needed two fields.
Start smaller. Parse only the fields your code actually uses, and make missing data explicit with Option<T>. If phone, middle_name, or deleted_at can come and go, Option tells Serde to accept both cases without guessing.
use serde::Deserialize;
#[derive(Deserialize)]
struct CustomerSummary {
id: String,
email: Option<String>,
deleted_at: Option<String>,
}
Defaults need more care. #[serde(default)] is fine when the fallback matches reality. An empty list often makes sense. A missing status, price, or timestamp usually does not. If you silently turn missing data into 0 or "active", you hide a vendor change and make bugs harder to spot.
Type drift is common too. One day an API sends "42", the next day it sends 42. Instead of spreading special cases across your app, parse both into one local type near the edge.
use serde::Deserialize;
#[derive(Deserialize)]
#[serde(untagged)]
enum StringOrInt {
Str(String),
Int(i64),
}
That wrapper keeps the rest of your code calm. You can add a small method to normalize it into a string or integer once, then use that everywhere else.
It also helps to keep one small struct per payload shape. A list endpoint, a detail endpoint, and a webhook may all describe the same customer, but they often do it differently. Separate structs are less clever, and that is a good thing. When the vendor changes one response, you only touch one parser.
A small model at the boundary usually lasts longer than one giant shared struct. It also makes breakage obvious when it matters, and flexible where it should be.
Keep unknown data for later
Vendors add fields all the time. If your client only keeps the fields it knows, you lose useful clues the first time the payload changes.
A simple fix is to keep the known fields typed and collect everything else in a map. serde makes that easy with flatten.
use serde::Deserialize;
use serde_json::Value;
use std::collections::HashMap;
#[derive(Debug, Deserialize)]
struct Customer {
id: String,
#[serde(default)]
email: Option<String>,
#[serde(flatten)]
extra: HashMap<String, Value>,
}
This gives you a stable model for the fields you use today, while extra keeps new fields alive for tomorrow. That is one of the safest Rust serde for unstable APIs patterns because you do not need to redeploy the moment a vendor adds region, tags, or a nested preferences object.
Sometimes a map is not enough. If a vendor keeps moving fields around, store the full raw JSON too. Parse the typed struct from a cloned Value, then save the original payload for review. That helps when support tickets show up three days later and you need to see exactly what the vendor sent.
Logging matters here, but keep it narrow. Log unknown field names, counts, and maybe a small redacted sample. Do not crash the request just because the payload has a surprise.
A small routine like this works well:
- parse the payload into your typed struct
- if
extrais not empty, log the field names - attach the raw JSON to debug output or store it for later review
- redact personal data before writing logs
Comparing unknown fields across sample payloads is even better. Take ten or twenty real responses from the same endpoint, collect the names from extra, and look for patterns. One field may appear only for enterprise accounts. Another may flip from string to object during a rollout. You catch those changes early, without breaking production.
If you build API clients for startups or small teams, this approach saves real time. You stay strict where your app depends on the data, but you still keep the parts you do not understand yet.
Accept new enum values safely
Enums break fast when a vendor adds one more status than you expected. If your client treats the vendor list as closed, one new value can turn a harmless payload change into a parse error.
A safer pattern is simple: keep a real enum for the cases you know, and add an Unknown variant that stores the raw value. That way, your code keeps working, logs stay useful, and you can inspect new cases later instead of losing them.
A small enum pattern that lasts
use serde::{Deserialize, Deserializer};
use serde_json::Value;
#[derive(Debug, Clone)]
pub enum VendorStatus {
Active,
Paused,
Unknown(String),
}
impl<'de> Deserialize<'de> for VendorStatus {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: Deserializer<'de>,
{
let raw = Value::deserialize(deserializer)?;
match raw {
Value::String(s) => match s.as_str() {
"active" => Ok(VendorStatus::Active),
"paused" => Ok(VendorStatus::Paused),
other => Ok(VendorStatus::Unknown(other.to_owned())),
},
Value::Number(n) => Ok(VendorStatus::Unknown(n.to_string())),
other => Ok(VendorStatus::Unknown(other.to_string())),
}
}
}
This handles both strings and numbers, which matters more than many teams expect. A vendor might send "active" today and 1 tomorrow for one partner feed. You do not need to like that choice. You do need to survive it.
Keep vendor enums near the API boundary. Then map them into your own internal states as soon as possible. For example, Active can become Enabled, Paused can become Suspended, and Unknown(_) can become NeedsReview or a safe default that does not trigger risky behavior.
That mapping step keeps the rest of the app calm. Business logic should not match every vendor case all over the codebase. It is better to centralize the match once and expose a smaller internal enum that reflects your rules, not the vendor's changing vocabulary.
A good fallback is boring on purpose. If billing status is unknown, do not charge. If fulfillment status is unknown, do not ship. Preserve the raw value, record it, and keep moving.
Build the model step by step
Start with payloads you actually got from production. Docs are often late, examples are too clean, and test fixtures miss the odd cases that break real clients. Save a small set of raw responses from different dates, accounts, and error states.
Then build a small strict struct for the fields your code truly needs. If your app only needs id, status, and created_at, model those first and stop there. A small model is easier to trust, and it gives you a stable base when the vendor adds noise around it.
When samples disagree, make the field optional before you write custom parsing. That keeps the model readable and usually solves more cases than people expect. In Rust serde for unstable APIs, Option<T> is often the first tool to reach for, not a custom deserializer.
use serde::Deserialize;
use serde_json::Value;
use std::collections::HashMap;
#[derive(Debug, Deserialize)]
struct VendorEvent {
id: String,
status: String,
created_at: Option<String>,
amount: Option<i64>,
#[serde(flatten)]
extra: HashMap<String, Value>,
}
That extra field matters. Add it before you write manual parsing code. You will often learn that you do not need custom logic at all. Unknown fields stay available for logging, debugging, or a later rollout, and new vendor fields stop breaking your client.
A good workflow is simple:
- collect 5 to 10 real payloads
- build the smallest strict struct that fits all of them
- turn differing fields into
Option<T> - capture the rest with
#[serde(flatten)] - only then add custom parsing for fields that are truly messy
Test the same model against old and new samples every time you change it. One fixture from last month and one from this week can catch most regressions. If both deserialize and your core fields still behave the same, you are in much better shape than a client that mirrors the whole vendor schema and hopes it stays still.
This step-by-step approach is boring, which is why it works. It keeps your client small, gives you room for vendor changes, and avoids the trap of over-modeling fields your code does not even use.
A real payload that keeps changing
A common vendor payload change looks harmless until it hits production. The API sends "price": "19.95" for months, then switches to "price": 19.95. Later, during a delayed sync, it sends "price": null and adds "status": "pending".
{"price":"19.95","status":"ready"}
{"price":19.95,"status":"ready"}
{"price":null,"status":"pending"}
If your Rust model expects only String or only f64, your client fails for a change users may never notice. A steadier pattern is to deserialize the raw field as serde_json::Value, keep the sibling status, and normalize both into one wrapper type.
use rust_decimal::Decimal;
use serde_json::Value;
use std::str::FromStr;
#[derive(Debug, Clone)]
enum PriceField {
Amount(Decimal),
Pending(String),
Raw(Value),
}
fn parse_price(price: Value, status: Option<String>) -> PriceField {
match price {
Value::String(s) => Decimal::from_str(&s)
.map(PriceField::Amount)
.unwrap_or(PriceField::Raw(Value::String(s))),
Value::Number(n) => Decimal::from_str(&n.to_string())
.map(PriceField::Amount)
.unwrap_or(PriceField::Raw(Value::Number(n))),
Value::Null => PriceField::Pending(status.unwrap_or_else(|| "unknown".to_string())),
other => PriceField::Raw(other),
}
}
PriceField::Amount handles both the string and number forms, so the rest of your code sees one price type. PriceField::Pending gives null a real meaning when the vendor also sends a status. PriceField::Raw catches anything unexpected, like an object or array, without crashing the whole request.
That small enum does more than keep parsing alive. It stops vendor quirks from leaking into checkout logic, reporting, or caching. Those parts of the app only need to ask one question: do we have an amount, a pending state, or something we should log and inspect?
I prefer this over Option<String>. None hides too much. It could mean missing data, a temporary status, or a brand new vendor format. A wrapper type keeps those cases separate, and your Rust serde for unstable APIs stays calm when the payload changes again.
Mistakes that make clients brittle
A lot of Rust API clients break for boring reasons. The code assumes the vendor will keep sending the same shape forever, then one small payload change turns a harmless response into an error.
The first common mistake is building one giant struct for every endpoint. That looks neat at first, but it ties unrelated responses together. When one field changes on one endpoint, you end up touching models that had no problem before. Small, endpoint-specific structs are usually easier to read and much safer to change.
Missing data and empty data also need different treatment. If a vendor omits a field, that often means something different from sending an empty string, an empty array, or null. If you collapse all of that into one state, you lose meaning and make debugging harder. Option<T> plus a careful deserializer is often better than trying to force everything into a default.
Where serde gets overused
Another mistake is reaching for untagged enums every time payloads do not match. They can help in narrow cases, but they also make parsing ambiguous and errors harder to understand. If a field changes shape often, parse that field separately or keep it as serde_json::Value until you know what you actually need.
Teams also drop unknown fields too early. That is a waste. If the vendor adds status_details tomorrow, you may not need it yet, but keeping it can save a production incident next week. A common pattern is to flatten extra fields into a map and log them when they first appear.
Be strict where it matters
One bad field should not always kill the whole response. If you care about id, status, and created_at, parse those strictly. If notes or metadata comes in malformed, keep the rest and mark that field as raw or missing.
A simple rule works well:
- keep critical fields typed
- keep unstable fields flexible
- preserve unknown fields
- model each endpoint on its own
- inspect surprises before deleting them
That approach gives you a client that bends when the vendor changes something small, instead of snapping on the first mismatch.
Quick checks before release
Before shipping a client, run a few checks that catch the quiet failures. Most breakage does not come from a dramatic schema rewrite. It comes from one new enum value, one missing field, or one default that turns bad input into fake success.
For Rust serde for unstable APIs, old payloads matter as much as fresh ones. Save real responses from different dates and run the same tests against all of them. A vendor may change a field in April, then partially roll it back in June. If you only test the latest sample, you miss that mess.
A short release checklist works well:
- Re-run parsing tests on fixture files captured at different times.
- Check every
#[serde(default)]and ask what bad input it might hide. - Scan logs or stored samples for fields and enum values your code does not handle yet.
- Keep fixture JSON files next to the structs and tests that use them.
- Make sure parse errors name the field path that failed.
Defaults need extra suspicion. If count becomes a string and your model falls back to 0, the program keeps running but the data is wrong. That is worse than a clean failure. Use defaults for truly optional data, not to paper over fields you depend on.
Logs help you catch vendor changes early. If you preserve unknown fields, inspect them now and then instead of ignoring them forever. One new field might not matter. Ten new fields usually mean the payload is drifting and your model needs another pass.
Error messages deserve a quick test too. If a fixture fails to parse, the message should point to something like items[3].status, not force you to guess. That saves time later, especially when a production payload breaks at 2 a.m. and you need to fix one field, not read the whole JSON by hand.
What to do next
If your client already depends on a vendor API that changes without warning, put a hard boundary between that payload and your own app. Parse the vendor response in an adapter layer, then map it into your domain types. That keeps serde tricks, fallback enums, and raw JSON storage out of the rest of the codebase.
This is where Rust serde for unstable APIs pays off. You stop treating the vendor schema like a promise, and start treating it like input that needs checking.
Write down what each field means to your system. A short note in the repo is enough. For every field you accept, decide whether you:
- trust it and fail if it is wrong
- use it when present, but can live without it
- store it for later without relying on it
- ignore it on purpose
That small list saves time during reviews. It also stops slow drift, where a field starts as "nice to have" and quietly becomes required without anyone noticing.
When the vendor changes shape, schedule a quick review instead of waiting for a bug report. Twenty or thirty minutes is often enough. Compare one new payload sample with an older fixture, run adapter tests, and check the places that usually break first: enum values, nulls, renamed keys, nested objects, and timestamps.
If the API changes often, keep sample payloads in tests and update them on purpose. One real example from last month and one from this week will tell you more than a long comment.
A second opinion can help when the adapter layer has already grown messy. Oleg Sotnikov does this kind of work from a practical Fractional CTO angle: review the Rust boundary, trim brittle code, and decide where AI-assisted delivery helps the team move faster without making the parser harder to trust.
Start with one endpoint, not the whole client. Split the adapter from the domain model, capture unknown fields, and write down the trust level of each field you use. That habit makes the next vendor change annoying, not expensive.


