Rust error types for teams: model failures clearly
Rust error types help teams separate retryable, user-facing, and internal failures, keep context intact, and make debugging much easier.
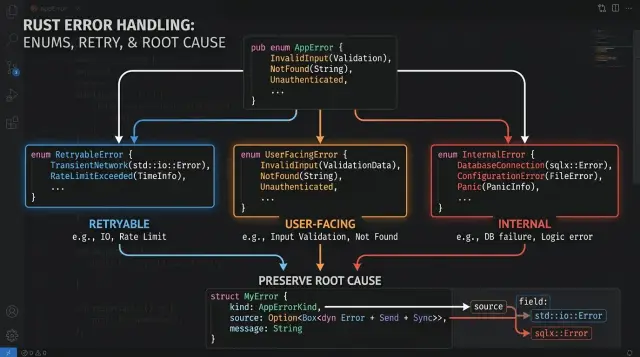
Table of Contents
Why teams lose the real error
Teams usually lose the real cause when they turn every failure into one bucket like AppError::Internal or a plain "something went wrong" message. That feels tidy for a week or two. Then a password reset fails, support cannot tell the user what to try next, and the engineer who debugs it no longer sees whether the mail service timed out, the token expired, or the database rejected the write.
This is not just a coding problem. Different people need different signals from the same failure. Support needs a message they can act on. Product needs to see patterns, like whether users hit validation issues or outside service outages. Engineers need the original cause, with enough context to reproduce it. If one generic error replaces all of that, every team works slower.
Wrappers often cause the damage. A helper function catches an error and returns RequestFailed. Another layer catches that and returns Internal. The top level now knows a request failed, but not which request, why it failed, or whether retrying would help. The code looks clean, but the failure got flattened.
Rust error types help when they describe the shape of the problem instead of hiding it. A timeout, bad user input, and a bug in your own code should not look identical. They lead to different actions:
- retry the operation
- show a clear message to the user
- alert the team and log full details
The hard part is keeping both views at once. You want a simple error enum that the whole team understands, but you also want to preserve the lower level cause. That means adding context without throwing away the source error.
A small example makes the cost obvious. If the mail provider returns "429 rate limit", and your app converts it to "reset failed", you lose the only clue that tells you to back off and retry later. Good Rust error types keep that clue visible. The goal is simple: one error should tell each reader what happened, what to do next, and what actually broke under the hood.
Pick your error audiences
Teams usually get stuck on error design because they group failures by source too early. Database, HTTP, cache, parser - that tells you where the problem happened, but not who needs to react. Good Rust error types start with audience first.
A simple rule helps: every error should tell one person what to do next. Sometimes the system should try again. Sometimes the caller should change input. Sometimes your team needs to fix code, config, or an assumption that broke.
Retryable errors describe temporary trouble. Think of a timeout to another service, a short network drop, or a rate limit from an upstream API. Your program can often retry these with backoff or queue the work for later. The response should say the request failed for now, not forever. Logs should capture the operation, attempt number, and the real cause. The owner is usually the team watching service health or the engineer who owns that integration.
User-facing errors are different. The caller can act on them. Bad input, an expired token, or missing permission fits here. These errors need plain messages like "reset code expired" or "email format is invalid". They should not leak internals such as SQL details or stack traces. Logs can keep a little more detail, but they should still stay clean and safe. The owner is the team that defines the API or product rules.
Internal errors are the ones you never want users to see directly. A missing environment variable, a broken invariant, or code that reached an impossible state belongs here. Blind retries rarely help. Return a generic failure, log the full context, and keep the cause chain intact so someone can fix it fast. The owner is the engineer or team responsible for the code path or deployment setup.
A shared enum gets easier to shape when each variant answers the same four questions:
- Can the system retry this?
- What should the caller see?
- What should the logs include?
- Who owns the fix?
If a variant cannot answer those four, it is probably too vague. "OperationFailed" hides more than it explains.
Shape a shared error enum
Start at the service boundary, not deep inside every helper. That boundary is where your handler, job, or command decides what the rest of the system should know. In many teams, three or four variants are enough at first.
The point is not to describe every low-level failure. The point is to make the next action obvious. Can the caller retry? Should the user fix input? Or did your code hit an internal problem that needs logging and an alert?
A small enum forces that decision early:
#[derive(Debug, thiserror::Error)]
pub enum ServiceError {
#[error("temporary failure")]
Retryable {
code: &'static str,
source: anyhow::Error,
},
#[error("invalid request")]
User {
code: &'static str,
details: Vec<FieldIssue>,
},
#[error("internal failure")]
Internal {
code: &'static str,
source: anyhow::Error,
},
}
Each variant should mean one thing. Teams get into trouble when they add buckets like Other, External, or RequestFailed. Those names look flexible, but they hide the real decision. A timeout from another service, a bad email address, and a bug in your own code should not land in the same bucket.
Good variants describe behavior, not origin. Retryable tells the caller what to do next. User tells the API layer it can return a clear message. Internal tells your team to inspect logs and the root cause.
Keep caller messages short and steady. If your API returns "Please try again later" today, it should not change to "Transient dependency outage detected" next month. Stable wording helps client apps, support teams, and tests. Save the detailed explanation for logs, traces, and debug views.
That is why codes and details should live apart from display text. A code like auth.reset_token_expired or billing.provider_timeout is easy to match in dashboards and client logic. Structured details, such as which field failed validation, belong in a separate payload. The Display text on the Rust error can stay plain and boring.
Plain is good here. When a teammate reads the enum, they should know what each variant means without opening five files. If they cannot tell whether an error should be retried, shown to a user, or paged to the team, the enum is still doing too much.
Keep the cause and add context
A vague error slows everyone down. If a database timeout turns into InternalError, the team loses the part that matters most: what actually failed. You still want a clean app-level error, but you do not want to throw away the lower-level cause.
Wrap the original error instead of replacing it. In Rust error types, that usually means an enum variant that carries both your own context and the source error. Your app can then say "password reset is temporarily unavailable" to the user while logs still show the real chain, such as a network timeout or a failed SQL query.
A small pattern
#[derive(Debug, thiserror::Error)]
pub enum ResetPasswordError {
#[error("password reset is temporarily unavailable")]
Retryable {
op: &'static str,
account_id: String,
timeout_ms: u64,
#[source]
source: reqwest::Error,
},
#[error("we could not reset that password")]
User {
op: &'static str,
account_id: String,
},
#[error("internal error during {op} for account {account_id}")]
Internal {
op: &'static str,
account_id: String,
#[source]
source: sqlx::Error,
},
}
This pattern keeps two layers separate. The Display text stays short and safe. The source field keeps the real cause attached for logs, alerts, and debugging tools. When someone checks an incident, they can see both the business meaning and the original failure without guessing.
Context matters just as much as the source. Add fields like the operation name, an input ID, a timeout value, or a request ID. Those small details answer basic questions fast: which step failed, for which record, and under what limit. A good error often saves 20 minutes of digging.
Be strict about secrets. Do not copy raw tokens, passwords, API keys, full emails, or provider responses into user messages. Do not dump them into log fields either. Keep user text plain, and keep log context boring: operation name, account ID, request ID, timeout, and the error chain. That gives the team enough to fix the problem without creating a new one.
Build one request flow step by step
Start with one real request and draw its failure map in order. Good Rust error types usually come from the path the request already takes, not from a big enum you invent first.
A simple flow often fails in four places:
- input parsing or validation
- a network call to another service
- a domain rule inside your app
- a storage read or write
That order helps because each step answers a different question. Did the caller send bad data? Did another system fail for a moment? Did your business rule reject the action? Did the database break?
Once you have that map, convert errors when they cross a boundary. Keep reqwest::Error inside the HTTP client layer. Keep sqlx::Error inside storage. The request handler should see your app's meaning, plus the original cause.
#[derive(Debug, thiserror::Error)]
pub enum RequestError {
#[error("invalid input: {0}")]
InvalidInput(String),
#[error("temporary upstream failure")]
RetryableUpstream(#[source] reqwest::Error),
#[error("email already exists")]
EmailTaken,
#[error("storage failure")]
Storage(#[source] sqlx::Error),
}
In the request flow, call validate first and fail fast on bad input. Then make the network call. If it times out or returns a temporary failure, map it to RetryableUpstream. If the app hits a rule like EmailTaken, stop and return a clear user message. If the database write fails, keep the sqlx::Error as the source so logs still show the real problem.
Retry rules should stay boring and strict. Timeouts, connection resets, and temporary upstream outages often deserve a retry. Bad input, missing permissions, and broken business rules do not. A team wastes time when every error looks retryable just because it came from a library.
Before you add more variants, test one failing path for each one. A short set is enough:
- invalid email returns
InvalidInput - upstream timeout becomes
RetryableUpstream - duplicate email becomes
EmailTaken - database failure becomes
Storage
If one test cannot tell you whether the caller should retry, fix the enum before the code grows.
A password reset example
Password reset is a good test for Rust error types because one simple action can fail for very different reasons. The user might type a broken email address. The mail provider might time out. Your app might fail to load the email template from disk.
Those failures should not look the same.
#[derive(Debug, thiserror::Error)]
pub enum ResetPasswordError {
#[error("Enter a valid email address")]
InvalidEmail,
#[error("Email service timed out")]
MailTimeout {
#[source]
source: reqwest::Error,
},
#[error("Password reset is unavailable right now")]
MissingTemplate {
#[source]
source: std::io::Error,
},
}
InvalidEmail is a user-facing error. It gives a clear fix: the person can correct the address and try again. You do not need a vague message like "Something went wrong." That only creates support work.
MailTimeout is different. The user may have done nothing wrong. The app should treat this as retryable, return a temporary failure, and keep the timeout from the mail client as the source. When a teammate checks the logs, they should see the real provider error, not just a flat "send failed" message.
MissingTemplate is an internal error. The user cannot fix it, so the public message should stay plain and calm. Your logs still need the file error as the source, because "template missing" tells the team where to look, while the std::io::Error tells them what actually broke.
A request flow can map them like this:
InvalidEmail-> show a form error and ask for a valid addressMailTimeout-> return a temporary error and allow retryMissingTemplate-> return a generic server error and alert the team
That split helps everyone. Support can tell whether the user needs to change input. Product can see whether retries matter. Engineers can trace the original timeout or file failure without guessing.
This is why error enums in Rust work well for teams. One endpoint can speak clearly to three audiences at once: the user, the app, and the people reading logs at 2 a.m.
Mistakes that blur failure
Teams get into trouble when every failure starts to look the same. The code still compiles, logs still fill up, and users still see an error. But nobody can tell what should be retried, what should be shown to a user, and what needs an engineer right away.
A common mistake is the catch-all variant. Names like Other, Unknown, or Failed feel safe when you write them, then turn useless a month later. If a database timeout, a bad email address, and a missing record all land in the same bucket, your team has to read logs and guess.
Some names are warning signs on their own:
OtherUnknownFailedMessage(String)
Those variants usually mean the type stopped carrying meaning.
Another mistake is passing raw library text straight to the user. A message from a SQL driver or HTTP client may mention table names, internal hosts, or low-level parser details. That helps during local development. It is a poor user message in production. Users need plain language such as "That reset link is expired" or "Please enter a valid email address." Engineers still need the original cause, but they need it in logs and error chains, not in the UI.
Retries cause damage when the error type does not separate temporary failure from bad input. If a user enters an invalid promo code, retrying three times will not fix it. You only add delay, extra load, and noisy alerts. Save retries for things that may succeed on the next attempt, such as timeouts, rate limits, or a short network break.
The last mistake usually shows up at boundaries. One layer gets a real error, then turns it into a string, or maps everything to InternalError without keeping the source. That single line can wipe out the trail you need during an incident. When you add context, keep the cause attached. "Failed to send reset email" is useful. "Failed to send reset email" plus the mail provider timeout is what lets somebody fix it fast.
Good Rust error types do one simple job: they keep meaning close to the failure instead of flattening everything into noise.
Quick checks before you merge
Good Rust error types save time only when people can act on them fast. Read the diff like someone on call at 2 a.m., not like the person who wrote it.
Use four checks before you approve a pull request:
- For each user-facing variant, can support tell the person what to do next? "Try again later" is weak. "Request a new reset link" or "Check whether the link expired" gives the user a clear next step.
- Can the service decide to retry without guessing? A timeout, a rate limit, and a bad email address should not look the same in code. If the caller has to inspect a string message, the type is doing too little.
- Can an engineer follow one log trail from the top-level error to the original cause? Extra context should say where the failure happened, but the wrapped source error should still keep the database, network, or parsing detail.
- Did you test at least one real case for each variant? Teams often define six variants and only see two in normal work. The unused ones break first because nobody exercises them.
A small rule helps during review: every variant should answer a simple question. What should the user do now? Should the code retry? What should the engineer inspect first? If a variant answers none of these, it may not deserve its own branch in the enum.
Names matter more than many teams admit. InvalidToken, EmailProviderTimeout, and AuditWriteFailed tell three different stories. OperationFailed tells almost nothing. Vague names make people read logs, scan call sites, and guess intent under pressure.
The test can stay small. Drive one real request flow and trigger one user mistake, one temporary failure, and one internal fault. Then check the match branch, the user message, and the preserved source. If the real cause disappears anywhere along that path, fix it before you ship.
What to do next as a team
For most teams, Rust error types stop being a style debate when on-call pain starts. The fix is rarely a big rewrite. A short team rule and one focused cleanup usually change more than another long design talk.
Write down the rules you expect everyone to follow. Keep them small enough to fit in a pull request template or team doc.
- Name variants by what happened, not by where they came from.
EmailInvalidis clearer thanValidationFailed. - Write caller text in plain language. Users need a next step, not raw internals.
- Keep log fields consistent across services. A few stable fields beat a different format in every crate.
- Preserve the source error every time you add context. If the root cause disappears, debugging slows down fast.
Then pick one code path that fails often and clean that first. Password reset, login, webhook handling, and payment retries are good choices because vague error buckets pile up there. Replace catch-all names like Internal, Unknown, or RequestFailed with variants that show whether the caller can retry, fix input, or stop and alert someone.
Add a simple review habit for pull requests. It does not need to be fancy, but it should be hard to skip.
- Can another engineer tell if this error is retryable without reading the whole function?
- Does the user-facing message stay safe and clear?
- Can logs still show the original source error?
- Do the variant names mean the same thing in every service?
This kind of review catches small mistakes before they spread through the codebase. One lost source error in a shared client can hide the real problem for weeks.
If your team wants an outside review, Oleg Sotnikov can look at Rust service boundaries and help set a steady error model as a fractional CTO. That is most useful when several services already exist, people use different error enums, and no one trusts what Internal means anymore.
A good target is simple: when a request fails, support can explain it, engineers can trace it, and the code makes the retry choice obvious.


