Rust and C++ FFI: safe boundaries for gradual rewrites
Rust and C++ FFI needs clear ownership, narrow APIs, solid tests, and safe release steps when teams replace one module at a time.
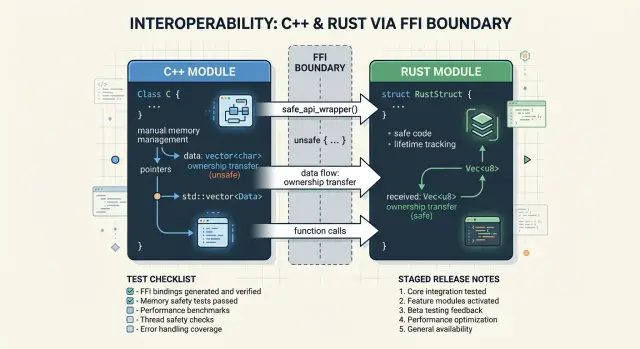
Table of Contents
Where memory traps start
Rust and C++ can work well together, but the trouble starts where one side stops understanding who owns a value. Rust frees memory when the owner goes out of scope. C++ may copy, move, share, or delete that same kind of value in a different way. If both sides think they should clean it up, you get a crash. If neither side does, you get a leak.
That mismatch is easy to miss because each language looks correct on its own. The Rust code can pass the borrow checker. The C++ code can compile cleanly and even survive code review. The bug lives in the handoff.
A common example is a Rust function that returns a pointer to data, while C++ treats that pointer like it owns the memory forever. Another one is C++ creating an object, passing it into Rust, then deleting it while Rust still holds a reference. Both cases may work in light testing, then fail under load or days later.
Why mixed rewrites are risky
Teams often hit this during gradual Rust migration. They replace one module, keep the rest in C++, and assume the new boundary is a thin technical detail. It is not. The boundary is where two memory models meet, and small assumptions turn into expensive bugs.
These mistakes show up a lot:
- Rust allocates, but C++ frees with
delete - C++ passes a borrowed buffer, but Rust stores it past the call
- One side moves a value, while the other still uses the old handle
- Error paths skip cleanup on one side only
- Strings or structs cross the boundary with different layout assumptions
One wrong cleanup rule is enough. A double free may crash fast. A leak may sit quietly in production and grow for weeks. A use-after-free is worse because it can look random. The team blames the new Rust module, then wastes time searching in the wrong place.
The real source is usually simpler: the contract was never written down. If a boundary does not say who allocates, who frees, how long a pointer stays valid, and whether a value can move or be copied, the code is running on luck.
That is why memory traps start early, even in small rewrites. The first safe step is not new code. It is a clear rule for ownership on every value that crosses the line.
Set ownership rules before you write code
With Rust and C++ FFI, memory bugs usually come from one simple problem: both sides think the other side owns the value, or neither side does. Fix that before you write wrappers, structs, or error paths.
For every value that crosses the boundary, write down two facts: who allocates it, and who frees it. Do this for strings, buffers, structs, callbacks, and error objects. If Rust creates a string and C++ reads it, Rust should also expose the function that frees it. If C++ passes in a buffer for Rust to fill, C++ keeps ownership unless the API says otherwise.
Shared access needs a different rule. If one call creates data and several later calls read or update it, pass a handle instead of a raw pointer to internal memory. A handle can map to a Rust struct, a C++ object, or a boxed state object, but the contract stays simple: create, use, destroy. That is much easier to review than a pointer whose lifetime depends on five call sites.
Comments matter here more than people like to admit. Put the lifetime rule next to every exported function, in plain words. A short note is enough:
// Returns a newly allocated result. Rust owns allocation.
// Caller must free with pricing_result_free().
PricingResult* pricing_calculate(const PricingInput* input);
Do the same for borrowed data. Say whether the pointer must stay valid only for the call, until a callback finishes, or until an explicit destroy function runs. If a function keeps a pointer after return, say that plainly.
A small team can keep this sane with one rule table in the repo:
- value type
- allocated by
- freed by
- borrowed or owned
- valid until
It feels boring. Good. Boring FFI code leaks less, crashes less, and gives you a boundary people can change one module at a time without guessing who cleans up the mess.
Keep the boundary small and boring
The safest FFI code usually looks a little dull. That is a good sign. If your border between Rust and C++ needs templates, inheritance, exceptions, custom allocators, and callbacks at the same time, that border is carrying too much risk.
For Rust and C++ FFI, a tiny C-style layer is often the least painful choice. Export a small set of functions with narrow jobs. Pass plain structs with fixed fields. Keep Rust types inside Rust, and keep C++ classes inside C++.
Good boundaries tend to follow a few simple rules:
- Use plain data, not class hierarchies or virtual methods.
- Convert strings at the edge instead of sharing native string types.
- Turn enums and errors into small values both sides can read.
- Use opaque handles if one side needs to hold state between calls.
This feels old-school, but it prevents a lot of memory trouble. If Rust returns a String, Vec, or Box straight into C++, someone has to free it later. If that rule is even a little fuzzy, leaks and crashes show up fast. A thin wrapper removes that guesswork.
The same goes for errors. Do not let a Rust panic cross into C++. Do not throw a C++ exception through Rust. Catch problems on the side where they happen, then convert them into a status code or a small error struct.
Thin wrappers also make rewrites easier. Suppose you replace one pricing or parsing module in Rust while the rest of the product stays in C++. If the border only exposes functions like create, run, and free, the rest of the program barely notices the change. If the border exposes internal classes, shared containers, and language-specific strings, every small update turns into a negotiation.
A boring boundary gives each language room to change on its own. That is what you want when you modernize one module at a time.
Move one module in clear steps
Choose a module that already behaves in a predictable way. Good candidates take clear inputs, return clear outputs, and do not reach into half the codebase through shared globals. If the module changes every week, skip it for now. You want something boring.
A parser, scoring function, billing rule engine, or file conversion step often works well. The team already knows what "correct" looks like, which cuts down arguments during the rewrite.
Before you touch Rust, lock down today’s behavior with tests. Add examples that cover normal cases, ugly edge cases, empty input, bad input, and large input. If the current C++ code has quirks that users depend on, capture them too. A rewrite that fixes hidden bugs can still break production.
Then keep the boundary exactly the same. If C++ calls a function with a plain struct and gets back a result code plus data, make the Rust side match that contract. Do not redesign the API in the middle of the migration. That is where memory traps and schedule slips show up.
A simple sequence works well:
- pick one low-churn module with stable behavior
- write tests against the current C++ output
- add a Rust implementation behind the same FFI boundary
- route one call path to Rust and compare both results
- expand traffic only after the numbers match
That comparison step matters more than teams expect. Run both versions for a while if you can. Let the C++ path stay live, but send the same input to Rust in shadow mode and log any mismatch. If Rust and C++ disagree on one case out of ten thousand, you just found a release blocker before users do.
Once the outputs match, widen the rollout in small slices. Start with internal users, one customer group, or one worker process. Watch error counts, memory use, and latency. If anything drifts, flip that path back to C++ and inspect the boundary first.
This one-module rhythm feels slow, but it usually moves faster than a broad rewrite. Teams keep shipping, users see fewer surprises, and the Rust and C++ FFI layer stays small enough to reason about.
Example: swapping a pricing module
A pricing module is a smart place to start because the input and output are usually clear. The C++ app already asks a simple question: given this cart, customer, and region, what price should we show? Keep that call unchanged in the first pass.
The C++ caller should still build the same request and call one exported function. Rust takes over only behind that boundary. This cuts risk fast because the rest of the codebase does not need to care which language calculates the answer.
On the boundary, use plain request and response structs. Think simple fields such as item_count, subtotal_cents, region_id, and customer_tier, plus explicit lengths for any text data. Skip C++ classes, Rust Vec, and anything that hides allocation rules.
The Rust side should fill an output struct and return a small status code. Keep the meaning boring and fixed:
0for success1for bad input2for missing pricing rule3for internal error
That pattern keeps ownership clear. C++ owns the input memory it sends. C++ also owns the output buffer it provides. Rust reads the request, writes the result, and gives control back without asking either side to guess who frees what.
A small example helps. Say the old C++ module calculates discounts for wholesale buyers. You can leave the checkout flow alone, send the cart data into Rust, and ask Rust to return final_price_cents, discount_cents, and tax_cents. If the call fails, C++ can fall back to the old logic.
Do not flip all traffic at once. Run the old C++ pricing code and the new Rust code side by side for a while. Compare both outputs for the same request and log mismatches with the request ID and a short reason, such as rounding drift or missing rule data.
Once mismatches drop to an acceptable level, start with a small share of live traffic. That gives the team proof that the Rust module works in production before they touch the next module.
Test the boundary, not just the Rust code
Rust code can look clean and still fail the moment C++ calls it the wrong way. In Rust and C++ FFI, most bugs do not start in business logic. They start when one side sends data the other side does not expect, frees memory too early, or keeps using a pointer after the owner changed.
A good test setup runs the same input through both implementations and compares the result. If you are replacing one module at a time, this gives you a plain baseline. Feed the old C++ function and the new Rust function the same strings, numbers, and buffers. Then compare output, error codes, and any state changes.
Small edge cases catch a surprising number of bugs:
- empty strings and zero-length buffers
- null pointers where the API allows them
- very large buffers and long strings
- invalid UTF-8 if text crosses the boundary
- repeated allocate/free cycles
Do not stop at one clean call. FFI bugs often show up on the 5,000th call, not the first. Write stress tests that call the boundary in a loop and confirm memory stays stable. Then run parallel calls from several threads if your API claims thread safety. If it is not thread safe, test that your wrapper rejects that use instead of failing in random ways.
CI should run these tests with sanitizers on the C++ side and Rust debug checks on the Rust side. AddressSanitizer and UndefinedBehaviorSanitizer catch many pointer mistakes fast. Rust debug builds help expose bounds errors, invalid assumptions, and panics that release builds might hide. Run both sides together in the same pipeline, not as separate worlds.
One practical habit helps a lot: keep a shared corpus of tricky inputs. When a bug appears in production, turn that exact input into a boundary test before you fix the code. Over time, the suite stops simple regressions and the messy ones too.
Teams that do this well treat the boundary like a contract. They do not just ask, "does the Rust code work?" They ask, "does this call stay correct when C++ passes bad input, large input, or ten calls at once?" That question prevents the leaks and crashes users actually notice.
Mistakes that cause leaks and crashes
Most bugs at a Rust and C++ FFI boundary are not clever. They happen because one side guesses about ownership, error handling, or data layout.
Rust and C++ FFI gets safer when the boundary acts like a strict contract. If the contract is fuzzy, leaks and crashes show up fast.
One common failure is double free. C++ deletes a buffer, then Rust drops the same allocation later, or the reverse. That usually starts with an API that returns a raw pointer but never states who must release it.
Keep the rule blunt: the side that allocates memory frees it. If Rust creates the object, Rust also exposes the destroy function. If C++ creates it, C++ owns cleanup.
Another classic bug is returning a pointer after the owner is gone. A Rust function may hand C++ a pointer into a String or Vec, then the function ends and the buffer disappears. C++ can do the same with a temporary object whose lifetime ends before Rust uses it.
If the caller needs data after the function returns, give it owned memory, copy into a caller-provided buffer, or return an opaque handle. Do not return pointers to stack data, temporary containers, or fields inside objects that may move.
Exceptions cause a different kind of failure. If C++ throws across the FFI boundary into Rust, the process may abort or corrupt state. The same warning applies to Rust panics going into C++.
Catch errors before they cross the line. Turn them into error codes, tagged result structs, or nullable handles with a separate error message function.
Struct layout changes are quieter, but just as dangerous. A field reorder, a new enum value, or a different alignment rule can make the other side read garbage without any compiler warning.
A few habits prevent that:
- Use
#[repr(C)]for shared Rust structs. - Prefer opaque handles over large shared structs.
- Add an API version and bump it when layout changes.
- Check struct size and field assumptions in tests on both sides.
Small example: version 1 of a pricing struct has price then currency. Someone inserts discount in the middle for version 2, ships only the Rust side, and C++ still reads the old layout. The result is not a neat error. It is bad data, random crashes, or both.
Before release, every boundary type should answer three questions in one sentence each: who owns it, who frees it, and what happens on error. If any answer is vague, the bug is already there.
Release without big-bang risk
A mixed C++ and Rust release should feel boring. If a launch depends on one perfect cutover, the plan is too fragile.
Start by shipping the wrapper layer before you switch any real logic. Keep the old C++ path active, and make the new Rust code return the same shapes, error codes, and edge case behavior. That gives your team time to watch logs, timings, and memory use while production still runs on the old path.
Put the Rust path behind a feature flag that you can change without a rebuild. For Rust and C++ FFI work, this matters more than people expect. If the new module hits an ownership bug under real load, you want one fast switch back to the C++ implementation, not a late-night patch release.
A small rollout beats a dramatic one. Send the Rust path to internal traffic first, or to one low-risk customer group if you have clear isolation. A pricing module is a good example. You can mirror requests, compare outputs, and confirm that both sides agree before the Rust result affects billing.
This release flow works well:
- Ship the boundary code and keep it inactive.
- Turn on the Rust path for staff accounts or test tenants.
- Expand to a small percentage of traffic and watch errors, latency, and memory.
- Increase slowly only after the team reviews diffs and incident logs.
Rollback needs practice, not hope. Before the first launch, run a drill in staging that simulates a bad Rust release. Flip the feature flag off, confirm the C++ path still works, and check that data formats, caches, and metrics stay consistent. Teams often skip this because the old code is still there. Then they learn too late that a config change, schema tweak, or API shape quietly tied them to the new path.
One rule helps most: never let the release plan depend on Rust owning anything the old system cannot safely ignore. Shared files, caches, and message formats should stay stable until the Rust module has survived real traffic for a while. That is how gradual Rust migration stays gradual, instead of turning into a forced rewrite under pressure.
Quick checks before each release
A mixed build can pass normal tests and still break on one bad pointer. With Rust and C++ FFI, a short release checklist saves more pain than a long postmortem.
Start with ownership. Every exported function needs one clear rule for memory: who allocates, who frees, whether the caller owns the result, and what happens with null or empty input. Put that rule in the C++ header and the Rust wrapper comments. If someone on the team has to guess who frees a buffer, do not ship yet.
Then pressure-test the boundary itself. Happy-path tests are not enough. Send invalid enums, null pointers where the API allows them, empty strings, oversized buffers, zero lengths, and mismatched pointer-length pairs. Test the exact size limit, then one step past it. Most crashes hide in inputs that look almost valid.
A fast pre-release pass should confirm a few things:
- Every exported function says who frees memory and how.
- Tests cover invalid input, empty input, boundary sizes, and length mismatches.
- Logs mark whether Rust or C++ produced each result.
- The team can switch off the Rust path quickly with a flag or config setting.
That logging point matters more than people think. If support reports wrong output after release, you need to know which side produced it without reading raw traces for an hour. A simple field like engine=rust or engine=cpp can cut debugging time fast.
The rollback path matters just as much. Do not tie the new Rust module to a full redeploy if you can avoid it. A feature flag, version switch, or runtime config lets the team fall back to the old C++ path in minutes while they inspect the problem.
If one of these checks fails, keep the old path live and fix the wrapper first. Boundary bugs get expensive once real traffic finds them.
What to do next
Pick one module that already has a narrow API and clear tests. A pricing engine, parser, or rules evaluator usually works better than a shared utility layer. If the code touches global state, custom allocators, or callback chains in five places, skip it for now.
This week, write a one-page ownership table before anyone writes Rust. Keep it plain:
- which side allocates each object
- which side frees it
- whether data crosses as a copy, borrow, or opaque handle
- what thread may touch it
- what error value comes back when something fails
That table prevents many Rust and C++ FFI bugs before they start. It also gives reviewers something concrete to challenge instead of arguing from memory.
After that, pick one boundary style and keep it for the whole module. If you use opaque handles with a C ABI, keep using them. If you pass copied buffers in and out, do not mix that with borrowed pointers unless the team has a very clear reason.
If the team feels unsure, bring in an outside review before release. A fresh reviewer can catch lifetime mistakes, exception leaks, ABI mismatches, and shortcuts that look harmless during a sprint but turn into crash reports later. In mixed-language code, a short review often saves more time than another week of coding.
Oleg Sotnikov can help with that planning work as a Fractional CTO or advisor. He works with teams on AI-first software development, architecture, infrastructure, and gradual modernization, so he can help set FFI rules, shape the test plan, and stage a rollout one module at a time.
Keep the first release small. Put the new path behind a flag, compare outputs against the old module, and watch memory use, crashes, and error rates in production. If that stays stable, move the next module with the same template. Reuse the ownership table, reuse the tests, and keep the boundary boring.


