Runtime validation in TypeScript for safer API edges
Runtime validation in TypeScript stops bad API input before it spreads. See where Zod or Valibot fits, what to validate first, and common mistakes.
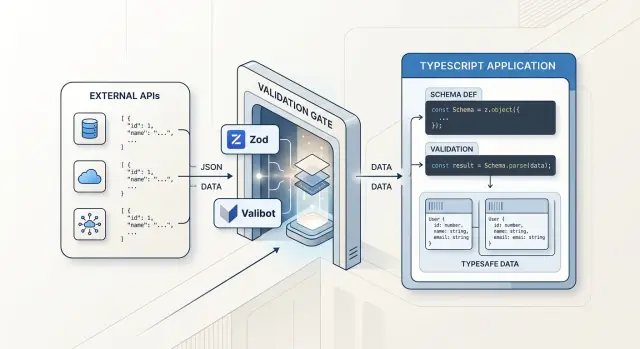
Table of Contents
Where TypeScript stops protecting you
TypeScript helps while you write code. It checks shapes, warns about missing fields, and catches a lot of mistakes before you ship. Once the app is running, those checks do not protect incoming data anymore.
A real API request does not care what your types say. An old mobile app, a broken form, a script, or a third-party service can send null where you expected text. It can send "42" instead of 42, or include extra fields your code never planned to handle.
Browser forms cause more of these problems than teams expect. Many inputs arrive as strings even when they look like numbers, dates, or booleans on the screen. A price field, user ID, or checkbox often needs parsing before your app can trust it.
That gap is why runtime validation in TypeScript matters. Your editor may say age is a number and email is required. The real payload can still contain "", null, "twelve", or a whole nested object where a simple value should be.
The first failure often shows up far away from the request. One unchecked payload can pollute logs with odd shapes, push the wrong values into billing, or skew reports for weeks. The bug feels random later, but it usually started at the edge where untrusted data entered the system.
A small example makes this clear. A signup form posts planId: "3" and marketingOptIn: "on". TypeScript does not stop those values at runtime. If your code accepts them without checking, that mismatch can spread into database rows, analytics events, and admin screens before anyone notices.
TypeScript is still worth using. It catches developer mistakes very well. It just cannot inspect live input on its own, and API boundaries are where that limit shows up fast.
How bad data gets in
Most broken payloads do not come from your own code. They come from places where your types do not travel: HTTP requests, webhooks, queues, scheduled jobs, and config loaded from the environment.
A public API is open to code you did not write. Maybe it is a mobile app on an old version, a script made by a customer, or someone testing your endpoint with hand-written JSON. Your TypeScript types do not stop any of them from sending age: "unknown", email: null, or a missing userId.
Third party systems add another layer of risk. An API can rename a field, stop sending one, or change a number into a string without much warning. Webhooks are even rougher. They often arrive late, out of order, or with optional properties missing. If your code assumes the old shape, bad data slips in and then spreads to logs, queues, and the database.
Two sources catch teams off guard more often than they should:
- Queue messages and cron jobs often carry old payload shapes long after the app changed.
- Environment variables always arrive as strings, even when you expect a number, boolean, or JSON object.
A small example makes this clear. Say your signup flow expects planId as a number and marketingOptIn as a boolean. The browser sends "2" and "true", a webhook later omits marketingOptIn, and a retry job replays last week's payload with plan instead of planId. Each input looks close enough to pass casual checks. A few hours later, you have users on the wrong plan and no easy way to trace why.
This is why runtime validation in TypeScript matters at the edge. Treat every outside input as untrusted until you parse it and prove its shape. After that, the rest of your app stays much more predictable.
What runtime validation does
TypeScript checks code you write. It does not check the JSON that just arrived from a browser, webhook, or third-party API. At that moment, the safe type is not UserSignup or Invoice. It is unknown.
runtime validation in TypeScript closes that gap. A schema defines what the app will accept: required fields, allowed formats, number ranges, string length, enum values, and nested objects. The app then parses the input against that schema once, right at the boundary where data enters.
If parsing fails, the request stops there. You return a clear error, log what went wrong, and keep bad input away from the rest of the code. Your business logic never has to deal with email: 42, an empty password, or surprise fields that should not exist.
If parsing succeeds, the result is much better than "probably correct" data. You now have clean, typed data that the rest of the app can trust. That matters because it removes defensive checks from every service and handler. Instead of repeating typeof, null checks, and fallback logic all over the codebase, you do the hard check once.
A signup request is a simple example. The API receives a body from the client. The schema checks that email is a string in the right format, name is present, and age is a number if the field exists. It can also reject or strip fields like isAdmin that the client should never control. After that, the user creation code gets only the fields it expects.
That is where tools like Zod or Valibot fit. They do not replace TypeScript. They protect the place where TypeScript cannot see the real data yet, then hand a safe shape back to the rest of the app.
Where Zod or Valibot belongs
TypeScript stops at the network boundary. When data comes from a browser, another service, a webhook, or a queue, your types do not check the real payload. You need runtime validation in TypeScript at the moment that unknown data enters the app.
Put Zod API validation or Valibot schemas in the first handler that receives input. Parse before you call business logic, touch the database, or publish an event. If a request includes a JSON body, a route param, and query params, check all three. Teams often validate the body and forget the id, page, or sort values that can break just as easily.
A good rule is simple: raw input stays at the edge. Parsed data moves inward.
That applies to more than user requests. Third-party APIs can send missing fields, wrong types, or shape changes you did not expect. If a billing service returns a plan object, validate that response before your app updates access, stores it, or shows it to users. Do not let "trusted" external data skip the same checks.
Webhooks need the same treatment. Parse the payload as soon as it arrives, then decide whether to accept it, reject it, or park it for review. If a worker stores or forwards raw webhook data first, one bad event can spread into your database, analytics, and downstream jobs.
These are the usual places where schemas belong:
- HTTP handlers for request bodies
- Route params and query params
- Third-party client wrappers
- Webhook receivers
- Consumers of external messages or jobs
Keep validation close to each entry point instead of building one shared parser far away from the source. That makes failures easier to trace. A signup handler should own signup parsing. A billing webhook should own billing event parsing.
This setup keeps bad data small and contained. One request fails early, with a clear error, instead of leaving you to clean up half-correct records later.
How to add validation at an API edge
Teams often make the same mistake first: they add schemas deep inside the app, after bad input has already touched business logic. Put the check at the door instead. If raw data comes from outside your code, validate it before anything else reads it.
Start by listing every place where outside data enters the system. That usually includes more than public API routes.
- JSON requests from web or mobile clients
- Webhooks from payment, auth, or email providers
- Admin forms and internal tools
- CSV imports, message queues, and scheduled jobs
After that, pick one entry point. Choose the endpoint that breaks most often, creates support work, or sends messy records into the database. A small win on one noisy route is better than a big plan that never ships.
Use Zod or Valibot to describe the payload you expect today, not the perfect payload you might want later. Keep the first schema narrow and honest. If a field is optional right now, mark it optional. If a number arrives as a string and you truly accept that, say so in the schema instead of pretending the input is cleaner than it is.
Then parse the raw input before you call services, helper functions, or the database. In practice, runtime validation in TypeScript should happen at the top of the handler, right after you read the request body. If parsing fails, stop there.
A simple flow looks like this:
- Read the raw request body.
- Parse it with one schema.
- Return a clear 400 error if parsing fails.
- Pass only parsed data to the rest of the app.
Keep error responses plain. Tell the client which fields are wrong and why, but do not dump stack traces or secret values. In logs, keep enough detail to debug safely: request id, route, field names, and the validation error. Skip passwords, tokens, and full personal data.
This approach is boring on purpose. That is why it works. One validated edge can stop a long chain of bad data, weird bugs, and late database cleanup.
A simple example with a signup request
A signup endpoint looks harmless until the browser sends a value your code did not expect. A common one is age: "27". The form sent a string, but your TypeScript type still says age is a number.
That gap matters because TypeScript checks your code, not the raw request coming from the network. If someone writes const input: SignupInput = req.body, the editor stays quiet. Your service then acts as if age is already clean.
type SignupInput = {
name: string;
email: string;
age: number;
};
const body = {
name: "Maya",
email: "[email protected]",
age: "27",
};
const result = SignupSchema.safeParse(body);
if (!result.success) {
return { status: 400, errors: result.error.flatten() };
}
createUser(result.data);
With Zod, SignupSchema can reject the request if age must be a real number at the API boundary. It can also convert the value on purpose if that matches your rules. For example, you might accept form input as text, coerce it to a number, and then check that it is an integer and old enough for signup.
Valibot does the same job with a slightly different style. The point is not the library name. The point is that the schema decides what enters your app.
After parsing, the service layer gets clean fields: name, email, and age in the shape you expect. That is where runtime validation in TypeScript earns its keep. The weird input stops at the edge.
Without that step, bad data keeps moving. Analytics may count "27" and 27 as different values. Billing or pricing rules may compare strings instead of numbers. A small form mistake turns into a bug in three places.
A schema at the request boundary is cheaper. One check, one clear rule, and the rest of the code can stay simple.
Choosing between Zod and Valibot
Most teams do fine with either library. The better choice depends on what hurts more: slower onboarding or extra bundle size.
Zod is usually the easy pick when a team wants to move fast. It has more examples, more tutorials, and a style many TypeScript developers already know. If a new hire joins next week, they can usually read a Zod schema and start working without much setup.
Valibot makes more sense when browser weight matters. If you validate a lot of form data on the client, smaller bundles can help pages load faster and keep interactions snappy on weaker devices. That difference may not matter much on a server, but it can matter in a user-facing app.
A simple rule works well:
- Pick Zod when team speed and easy onboarding matter most.
- Pick Valibot when client bundle size is a real concern.
- Stick with one library across the codebase unless you have a strong reason to split.
That last point saves more trouble than people expect. When one team uses Zod in the API and another uses Valibot in the frontend, small differences in parsing rules start to creep in. A field that trims spaces in one place may fail in another. That is how runtime validation in TypeScript turns messy instead of helpful.
Sharing the same schema on server and client can be smart, but only when both sides truly need the same rules. A signup form is a good example. You can share checks for email format, password length, and required fields. Server-only checks should stay on the server, though. Database lookups, fraud rules, rate limits, and permission checks do not belong in a shared client package.
If your team is still unsure, pick the tool people will actually use every day without complaint. A slightly larger bundle is often a fair trade for fewer mistakes and faster reviews. On the other hand, if you build a frontend-heavy product and watch every kilobyte, Valibot is a sensible choice.
Mistakes that let bad data spread
A lot of teams validate in the UI and then trust everything that reaches the server. That works right up until someone bypasses the form, sends a direct request, or an older client keeps posting the wrong shape. TypeScript cannot protect that boundary on its own because the network sends plain input, not trusted types.
Query params often get ignored because they look tiny. They are still input. A value like ?page=abc, ?limit=-1, or ?sort=[object Object] can slip into database queries, logs, caching rules, or analytics. Small fields cause very real bugs.
Another common mistake is transforming data before validation. Teams trim, coerce, rename, or merge fields first, then validate the cleaned result. That hides the original problem. If age arrives as "twelve" and your code turns it into NaN before the schema runs, you lost the clearest error message and made debugging harder.
Unknown fields cause quiet damage too. A request may include extra properties that nobody asked for, like role, debug, or an old client flag. If your parser accepts them, that junk can end up in storage, event payloads, or internal function calls. Later, someone sees the field and assumes it is supported.
These mistakes show up a lot:
- validating only the browser form
- skipping headers and query params
- coercing values before checking them
- allowing extra fields by default
- keeping one huge schema that nobody wants to touch
That last one is more serious than it looks. Teams start with a giant schema meant to cover every request shape. After a few changes, people stop updating it because it feels risky and slow. Then the schema becomes theater. It exists, but it no longer matches what the code accepts.
A better habit is boring and strict. Validate raw input at every API edge. Keep schemas small and close to the route or handler that uses them. Reject unknown fields unless you have a clear reason not to. In practice, runtime validation in TypeScript works best when it catches bad input early, before parsing, mapping, and storage make the source of the bug hard to find.
Quick checks before you ship
Most bugs from bad input feel small at first. A missing field, an extra property, a number sent as a string. Then that payload slips past the API edge, reaches business logic, and turns into a harder problem to trace.
A short pre-release review catches a lot of this. It also tells you whether your runtime validation in TypeScript actually protects the places where TypeScript cannot.
Use this checklist against every request handler, webhook, queue consumer, and third-party callback:
- Parse every external payload as
unknownfirst. Do not trust request bodies, query params, headers, or partner data just because your editor shows a type. - Decide what to do with fields you do not support. Reject them when strict input matters, or strip them when extra data is harmless.
- Return error messages that help the caller fix the request. Say which field failed and why, but do not dump stack traces or internal schema details.
- Test broken payloads on purpose. Send empty bodies, wrong types, extra fields, malformed JSON, and values that almost look valid.
- Log validation failures in a way your team can use. Capture the route, request ID, and field path, but never log passwords, tokens, or full personal records.
One detail teams often skip is consistency. If one endpoint strips unknown fields and another rejects them, clients get confused fast. Pick a rule for each class of endpoint and stick to it.
Error handling deserves a second look too. "Invalid input" is too vague. "email must be a valid email address" gives the caller something they can fix in one try.
If your team ships quickly or uses AI-assisted code, these checks matter even more. Fast code generation can produce correct types and still miss ugly real-world input.
Before release, run one last manual test with a bad payload. If the schema catches it, the API returns a clean error, the test covers it, and the log stays useful without leaking private data, you are in good shape.
What to do next
Most teams do not need a big rewrite. They need a map. Put every place where outside data enters your system on one page: public API routes, webhooks, admin forms, CSV imports, queue consumers, and jobs that pull from other services. Then mark the few edges that create the most support work or the ugliest bugs.
Start with one of those, not all of them. A signup request is a good first pick if bad input creates duplicate accounts, broken emails, or messy user records. If a partner API keeps changing field types, start there instead. The best first schema is the one tied to a real, annoying problem.
If you already use Zod or Valibot schemas, move them as close to the boundary as possible. Parse the payload before your app logic touches it. That is where runtime validation in TypeScript pays off. It stops bad data at the door instead of forcing the rest of the code to guess.
A simple rollout looks like this:
- choose one risky endpoint or webhook
- add a schema next to the handler
- reject or clean the payload right away
- log the reason when parsing fails
- check those failures after a few days
Those logs tell you more than team guesses do. You will see patterns fast. Maybe users keep sending blank names, an old client still posts strings instead of numbers, or one field arrives as null more often than expected. When the same payload keeps failing, tighten the schema, improve the error message, or support that older format on purpose.
Do that once, then repeat at the next risky edge. Small steps work better than a broad cleanup plan that nobody finishes.
If data moves through several services and the boundary lines are blurry, an outside review can help. Oleg Sotnikov does that work as a Fractional CTO and startup advisor, helping teams place validation, reduce support churn, and keep bad data from spreading across the stack.
A practical target for this week: ship one schema, collect rejected payloads, and use them to decide the second schema.


