Reusable automation blocks for internal tools that work
Reusable automation blocks help teams build internal workflows faster with clear retries, approvals, notifications, and logs they can trust.
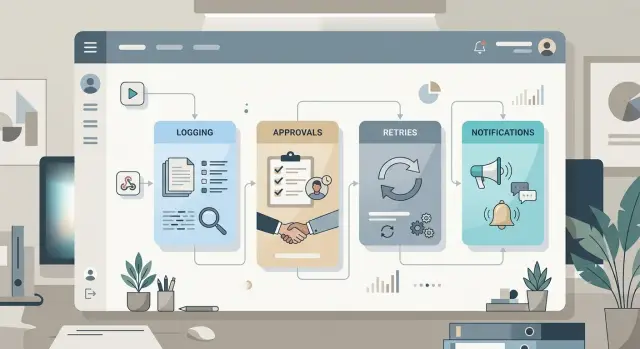
Table of Contents
Why one-off workflows keep causing rework
One-off workflows feel fast at first. A team copies an old flow, changes a few labels, swaps a form field, and ships it. That shortcut might save an hour today, then cost days later because the copied logic still carries old assumptions.
The trouble starts when each workflow drifts in its own direction. One request retries twice after a timeout. Another fails right away. A third sends alerts to Slack and email, while a similar flow stays silent until someone notices a stuck task. Those differences look small when you build them. They get expensive when support has to remember which flow behaves which way.
Approval rules create the same kind of mess. People stop trusting the process when they have to ask, "Who signs off on this one?" every time. A manager approves one type of purchase, finance approves another, and a copied workflow may still point to last quarter's rule. Someone fixes one flow and forgets the three others built from it.
Logs are usually where the damage becomes obvious. If one workflow records every step and another stores almost nothing, a simple issue turns into a slow investigation. You can't tell whether a request failed, waited for approval, retried in a loop, or sent the notice to the wrong person. Two engineers can burn 40 minutes comparing screenshots just to answer a basic question.
Without reusable automation blocks, every internal tool workflow becomes its own little rulebook. Teams debug the same problem more than once. Approval disputes keep coming back. Notifications annoy people in one flow and go missing in another. New workflows take longer because nobody fully trusts the last version.
A shared pattern won't remove every exception. It does stop teams from rebuilding retries, approvals, notifications, and logging from scratch each time. That's where most rework starts.
What belongs in a shared block library
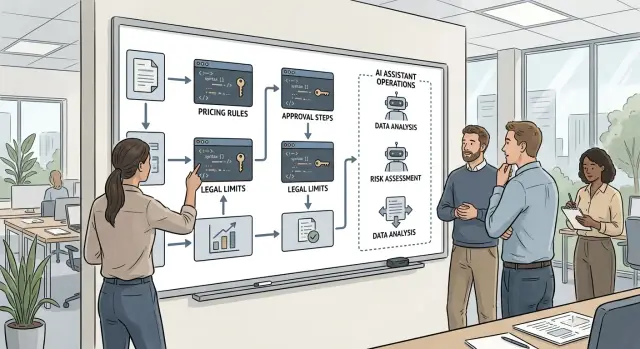
Most teams don't need a huge library. They need the parts that repeat in almost every internal workflow and fail in the same familiar ways. That's where reusable automation blocks pay off. They remove guesswork from work that nobody wants to rebuild every month.
Put retry logic near the top of the list. APIs stall, background jobs run long, and third-party tools return random errors even when nothing is wrong on your side. A good retry block decides how many times to try again, how long to wait, which errors deserve another attempt, and when to stop and alert a person. If the block also prevents duplicate actions, you avoid one of the worst bugs: a workflow that retries and creates two tickets, two invoices, or two user accounts.
Approval blocks belong in the library too, because people change roles faster than workflows change. The block should route by role instead of by one named person, set a response deadline, send a reminder before the deadline, and hand the task to a fallback owner if nobody answers. Silence needs a rule. Rejection needs a rule too. When every workflow uses the same approval pattern, managers know what to expect and teams stop arguing about edge cases.
Notification blocks should cover the channels your company already uses, usually email, chat, and a visible status update inside the tool. Keep them separate from the business logic. When the message format changes, you can update one block instead of touching ten workflows. Good notification blocks also know when to stay quiet. A short status update for routine events is enough. People tune out a workflow that sends five messages for one small request.
Logging blocks look boring until something breaks. Then they save hours. Every workflow should record who triggered it, what it tried to do, what decision it made, and why it failed if it failed. Use the same fields every time so support, finance, or ops can read one log and understand the story without opening three systems.
Teams moving internal work into AI-assisted tools often spend too much time on prompts and too little time on these basics. The plain blocks usually matter more. If retries, approvals, notifications, and logs already work, new workflows start from solid ground instead of from scratch.
How to design a block people will reuse
People stop trusting shared blocks when one block tries to do four jobs at once. Keep each block narrow. A retry block should retry. A notification block should send messages. An approval block should collect a decision and return the result.
The name needs to be just as clear. Use plain words that tell people what happens, such as "Retry failed API call" or "Send manager approval reminder." If someone has to open the block to understand it, the name is too vague.
Good defaults save more time than extra features. Most teams want to drop a block into a workflow, change one or two fields, and keep moving. A retry block can start with three attempts, a short delay, and one final log entry. An approval block can start with one approver, one reminder, and a clear timeout.
That doesn't mean you should expose every setting. Reusable automation blocks work best when they hide the noise. Show the options teams actually change, like retry count, approver role, message text, or timeout. Keep the rest inside the block unless people ask for it again and again.
Each block also needs a small contract that anyone can scan in under a minute. Spell out what goes in, what comes out, what counts as success, what happens on failure, and which fields people can change. If the failure behavior is fuzzy, people will build their own version just to feel safe.
One small example next to the block definition helps more than a paragraph of theory. Show a real input and output. A notification block might take a request ID and owner name, then return "sent" or "failed" with a timestamp. That removes guesswork fast.
The best shared blocks feel boring in a good way. They're easy to read, hard to misuse, and fast to plug into a new workflow.
How to build a workflow from proven blocks
Start with one plain sentence that defines the finish line. For example: "An employee requests access, the manager approves or rejects it, the employee gets a clear response, and the system keeps a record." If you can't write that sentence in simple words, the workflow is still too vague.
Next, map the steps in the order people actually see them. Begin with the trigger, then the form or request, then the approval, then the notification, and only after that the audit log or follow-up tasks. Teams often design from the system view first, but internal tool workflows make more sense when you follow the user path.
Once the flow is on paper, look for repeated work. You shouldn't rebuild retries, approvals, notifications, or logging every time. Keep custom logic only where the business rule is unique. If a step already exists in your shared library, drop it in and move on.
A simple process works well. Write the outcome in one sentence. Sketch each user-facing step in order. Replace repeated steps with shared blocks. Add only the custom rule that makes this workflow different. Then save a short version note before anyone else copies it.
That version note matters more than most teams expect. A line like "v1.3 adds manager timeout after 48 hours and prevents duplicate requests" saves a lot of guessing later. When another team reuses the flow, they can see what changed and whether the block still fits their case.
Don't stop at the happy path. Test what happens when an approver does nothing, when someone rejects the request, and when the same person submits it twice. A timeout should trigger the right reminder or fallback. A rejection should stop later steps cleanly. A duplicate request should not open two approval chains unless you want that on purpose.
This is where workflow retry rules often fail. Teams add retries to everything, including steps that should never repeat, such as sending a final approval twice. Retry only the parts that are safe to run again, and log every retry so support can see what happened without digging through raw events.
A simple example from an access request flow
Access requests look simple until money, permissions, and slow systems get involved. An employee asks for access to a paid tool. Maybe a designer needs one more seat in Figma, or a salesperson needs a license for a prospecting app. If every team builds this flow from scratch, they keep solving the same small problems again.
A reusable block setup makes this flow predictable. The request starts with a form that captures the tool name, business reason, team, and how long the access is needed. That part stays simple. The shared blocks handle the work that repeats in almost every request.
A common flow starts with the manager checking whether the person actually needs the tool for their job. If the tool costs money, the budget owner checks whether the team should pay for another seat. After approval, the system tries to add the user through the identity system or vendor API. The requester gets status updates instead of wondering what happened, and the log records each decision and each system event.
The retry block matters more than most teams expect. Identity systems and vendor APIs often fail for boring reasons: rate limits, slow responses, or a temporary timeout. Instead of marking the whole request as failed, the block can retry after 30 seconds, then again after 2 minutes, then send it to a person if the call still doesn't work. That saves people from resubmitting the same request three times.
The notification block keeps the process calm. After the manager approves, the employee can get a message that says the request is now waiting for budget approval. If the budget owner rejects it, the message can explain that the request stopped because no seat is available or the spend wasn't approved.
The logging block gives the team a record they can trust. It stores who approved, who rejected, when the system timed out, and when access was finally granted. Later, if finance or IT asks what happened, nobody has to piece it together from chat messages.
How to name, own, and version blocks
Reusable automation blocks stay reusable only if people can find them, trust them, and know when they changed. That starts with dull, direct names. "retry-payment-api-call" or "request-manager-approval" tells people what the block does. "finance-team-flow" or "ops-helper" tells them almost nothing.
If a block fits only one policy, say that in the name. Specific beats vague. A person building a workflow should know in five seconds whether the block fits, without opening the code or asking around.
One owner matters just as much as a good name. Let many people suggest changes, but give one person or one team the final call. That owner keeps behavior consistent, rejects duplicate blocks, and decides when a change is big enough for a new version. On a small team, this role can sit with the engineering lead, operations lead, or a fractional CTO.
Keep the change record short. Usually a few lines are enough: the date, what changed, who approved it, and whether existing workflows need updates. That note saves a lot of time six months later when someone asks why a retry rule changed or why an approval block now needs one more field.
Start at v1 and stay there until you make a real breaking change. A typo fix, a clearer log message, or a faster query shouldn't force every workflow owner to update references. Create v2 when you change inputs, outputs, timing, or approval logic in a way that can break existing use.
Old versions need an end date. If you keep "approval-request.v1" forever, teams will keep using it forever. Set a retirement date, name the replacement, and give people enough time to move. If v2 adds an audit field the company now requires, keep v1 open for a month, then remove it on the published date. People usually accept change when the rule is simple and the deadline is real.
Mistakes that turn the library into a mess
A shared library breaks down when each block tries to do too much. The usual bad example is one block that handles retries, approvals, special customer tiers, emergency bypasses, and three different notification paths. It looks flexible for a week, then nobody trusts it. People stop reusing it because one small change can break four unrelated cases.
A block should do one job well. If the rule changes by team, region, or risk level, keep that logic outside the block or pass it in as clear input. That makes shared blocks easier to test, easier to explain, and safer to change.
Cloning is the next thing that ruins the library. A team copies a block, tweaks one step, and ships fast. Two months later, the shared block gets a bug fix, but the copy never gets it. Now you have three versions of the same thing with different behavior, and nobody knows which one is right.
Most clones happen because fixing the shared block feels slow or political. If a block has an owner and a simple change process, teams are much more likely to improve the original instead of forking it in secret.
Order matters too. Notifications shouldn't go out before the main action succeeds. If a workflow emails "access granted" and the permission update fails a second later, support gets dragged into a mess the workflow created. Send messages after success, or make it clear that the request is still pending.
Approvals often fail for a simpler reason: the approver has no context. A request that says only "please approve" forces someone to guess. They need enough detail to decide fast, such as who asked, what they want, why they need it, and what risk it carries.
Logs can cause a quieter problem. Teams often dump full request payloads into logs because it helps during early testing. Later, those logs hold passwords, tokens, salary data, or private user details that nobody needed to keep.
A clean library follows a few plain rules. Each block has one clear purpose. Teams fix shared blocks instead of cloning them. Workflows notify people after the action succeeds. Approval steps include enough context to decide. Logs keep useful facts, not secrets or extra personal data.
Ignore those basics and the library will still grow. It just grows into something people work around instead of use.
Quick checks before you ship a new block
A shared block can save a team a lot of repeated work, but only if people trust it on day one. A block that retries forever, sends vague alerts, or logs secrets will create more cleanup than it saves. Before you add anything to your library, review the boring parts. Those are usually the ones that break in production.
Reusable automation blocks work best when they feel familiar. If one block expects request_id and another expects ticketId, people will guess, map fields by hand, and make mistakes. Keep input and output names aligned with the rest of the library so someone can swap one block for another without stopping to decode it.
The release check itself is simple. Match input and output names to the pattern your library already uses. Set retry rules with a clear stop point, backoff, and an error path after the last attempt. Show approvers enough context to act fast: the request, who owns it, and when it needs a decision. Write notifications that tell people the next action, not just that something happened. Capture logs for failures and edge cases, but strip passwords, tokens, API keys, and private data before writing anything.
The approval step deserves extra care. If an approver opens a task and can't see who asked, what they want, and the deadline, the request will sit. People don't like chasing missing context. Put the needed details in the approval view and keep them in the same order across every workflow.
Notifications should be plain and specific. "Access request needs review by 3 PM" is enough. "An update has occurred in the system" is almost useless because it makes the person open the tool just to learn what changed.
Logs need the same discipline. Good logs help you find why a block failed in two minutes. Bad logs leak secrets into places they should never be. If you build internal tools for a small team, this final check isn't optional. It's what keeps a helpful block from turning into a quiet security problem.
Next steps for a small team
Start with what your team already repeats. Don't map every process in the company. Pick the workflows that show up every week and waste the same 10 to 20 minutes each time.
Write them down in plain language. A short table or shared doc is enough. Note the trigger, who acts next, what can fail, and who needs to know when it's done. Most small teams find the same pattern quickly: someone submits a request, someone approves or rejects it, the system retries a flaky step, a person gets a status update, and support needs a record of what happened.
That's your starting library. Turn one retry, one approval, and one notification into shared blocks before you build anything else. Keep the first version narrow. A retry block might handle only three attempts with a short delay and a clear error message. An approval block might support only one approver and a timeout. That's fine.
Then look at logging with support and audits in mind, not developer curiosity. Log the request ID, who approved it, when each step ran, why a retry happened, and the final result. Skip noisy logs nobody reads. If a support person can't answer "what happened to this request?" in under a minute, the logs need work.
For most teams, the first pass is simple. Pick two common workflows, extract three shared blocks from them, run those blocks in one live process, review failures after a week, and fix naming, inputs, and logs before adding more.
This is when reusable automation blocks start paying off. New workflows move faster because people stop rebuilding the same approval, retry, and notification logic from scratch.
If you want a second opinion before rollout, Oleg Sotnikov at oleg.is works as a fractional CTO for startups and small businesses. He helps teams review architecture, automation, and AI-first development setups so the workflow library stays simple enough to maintain.
Frequently Asked Questions
Why is copying an old workflow a bad idea?
Because copied workflows keep old rules you forgot to remove. One flow may retry, another may fail fast, and a third may notify the wrong people. Those small differences create support issues, approval confusion, and repeated debugging later.
Which shared blocks should we build first?
Start with retry, approval, notification, and logging blocks. Those four parts show up in most internal workflows, and teams often rebuild them badly. If you standardize them first, new flows start from something people already trust.
What makes a retry block actually useful?
A good retry block decides when to try again, how long to wait, and when to stop. It should retry only safe actions and prevent duplicate results like two tickets or two accounts. It should also log each attempt so support can see what happened fast.
How should an approval block work?
Route approvals by role, not by one named person. Add a deadline, a reminder, and a fallback owner if nobody answers. Show enough context to approve fast, including who asked, what they want, and why they need it.
What should notification blocks send?
Keep notifications separate from business logic and make them short. Tell people what changed and what happens next, not just that the system did something. Send updates after success or mark them clearly as pending so you do not create false certainty.
What should every workflow log?
Log who started the workflow, what action it tried, what decision it made, and why it failed if it failed. Use the same fields across workflows so support, ops, and finance can read one record and understand the story. Leave out passwords, tokens, and other private data.
How do we keep blocks reusable instead of bloated?
Keep each block narrow and give it a plain name. A retry block should retry, not handle approvals and custom customer rules too. Show only the settings people change often, and write a small contract that explains inputs, outputs, success, and failure.
When should a workflow retry and when should it stop?
Retry steps that fail for temporary reasons, like timeouts, rate limits, or slow APIs. Do not retry actions that create final results unless you built duplicate protection around them. Sending a final approval twice usually causes more trouble than a short delay.
How do we manage ownership and versions for shared blocks?
Give each block one owner and keep a short change record. Stay on the same version for small fixes, then create a new version only when you change inputs, outputs, timing, or decision rules. Set a retirement date for old versions so teams actually move.
What should a small team do first?
Pick two workflows your team repeats every week and extract three shared blocks from them. Run those blocks in one live process, watch failures for a week, then fix naming, inputs, and logs before you add more. That gives you a small library people will use instead of avoid.