REST hooks vs polling for customer integrations explained
REST hooks vs polling affects delivery speed, retries, firewall setup, and support work. Use this guide to choose the right interface.
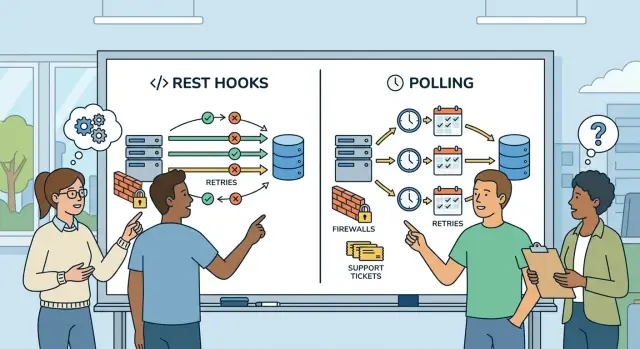
Table of Contents
What problem this choice actually solves
Choosing between REST hooks and polling comes down to three things: who needs to act, how quickly they need to act, and how much setup work your team and your customer can handle.
Some updates matter the moment they happen. A failed payment, a fraud alert, a shipment problem, or an account lockout often needs a quick response. If a support team or customer ops team must react right away, waiting for the next scheduled check feels broken even if the data is technically correct.
Other updates can wait. Dashboard totals, nightly syncs, exports, and low-risk status changes usually do not need instant delivery. If a five minute delay changes nothing, that tells you something useful. It often points to a simpler interface and less setup for customers.
Control matters too. If you own both the sender and the receiver, you can shape the whole flow and fix rough edges quickly. If your customer owns one side, the choice gets harder. Their hosting rules, security reviews, and team skills matter as much as the API design.
Support effort changes the answer again. One customer with a strong engineer can set up a webhook quickly. Forty customers with different firewall rules, staging setups, and approval steps can turn the same choice into a steady stream of tickets. Polling often asks less from customers on day one, but it can create more questions later when people notice delays or missed checks.
A simple way to frame the decision is to write down which events customers truly need right away, which updates can wait a few minutes, who controls each side of the connection, and how many customers will need hands-on setup help.
That usually clears up the real issue. REST hooks vs polling is not just a technical choice. It is often a product and support decision with technical consequences.
How fresh the data needs to be
Start with a plain question: what breaks if the update arrives 30 seconds late, 5 minutes late, or an hour late? If users expect a screen, alert, or workflow to change almost at once, hooks usually fit better. They push the event out as it happens, so people do not sit there refreshing and guessing.
That matters for payment status, fraud checks, shipment updates, or anything that changes what a user can do next. If an action should unlock, block, or notify someone right away, a slow sync feels wrong even when the data is accurate.
Polling is often fine when a short delay changes nothing. Daily reports, back-office syncs, billing summaries, and low-risk status checks usually work well on a schedule. If nobody cares whether the update lands in 20 seconds or 10 minutes, polling is easier to reason about.
The practical test is frequency. Ask how often the receiving system would need to call your API to feel current enough. Every 5 seconds sounds fresh, but it adds requests quickly. Every 15 minutes cuts load, but users may notice stale data. The right interval is the shortest one that does not create waste.
Bursty traffic changes the picture. Ten events per day are easy to poll around. Ten thousand events in five minutes are not. A polling job can miss short-lived changes between runs, or pull the same records again and again if it uses overlapping time windows to stay safe.
Hooks have their own failure modes. If the receiver is slow or briefly offline, events can arrive late, out of order, or more than once after retries. That is normal. The receiver needs a way to detect duplicates and process the same event safely.
Most of the time, the choice is simple: use hooks when the product feels wrong without near-real-time updates, and use polling when a small delay does not change the outcome.
What retries and failures look like
Failures are part of normal operation. In the REST hooks vs polling choice, most of the hard work is deciding who notices a failure, who retries, and when they stop.
Polling keeps retry logic on the customer side. If their last request times out, they ask again on the next cycle. That is easy to explain, but it can hide short outages because nobody sees a failed delivery. The customer just gets the latest state later.
Hooks move that burden to the sender. If the destination times out, returns a 500, or goes offline for a few minutes, your system needs a retry policy before you send real traffic. That policy should say which errors count as temporary, how often you retry, and when you mark an event as failed. A 429 often deserves another try. A 404 usually does not.
Idempotency matters more than many teams expect. A receiver can process an event, then fail before sending back a 200. The sender thinks delivery failed and sends the same event again. If the receiver creates a second invoice, sends a second email, or changes the order twice, support gets pulled into a mess the code should have prevented.
The fix is simple in concept. Give each event a stable ID, and make the receiver treat that ID as already handled. Store the result long enough to cover your retry window.
Order breaks in small, annoying ways too. A newer update can arrive before an older one if a retry delays the first message. If the receiver applies events in arrival order only, data can move backward. Add a sequence number, version, or event timestamp, and make the receiver ignore older state.
You also need a replay policy. Keep failed events long enough for a customer to fix credentials, adjust a firewall rule, or bring a service back online. A few hours is often too short. Forever is usually wasteful. Pick a retention period that matches real support work, then make replay a controlled action.
Support teams need a delivery trail they can read fast. For each attempt, record the event ID, the time, the destination, the response code, whether the request timed out or connected cleanly, and what the system plans to do next.
That log turns a vague ticket like "we never got the update" into something you can answer in minutes. Without it, every failure turns into guesswork.
Where firewalls and network rules block you
With REST hooks vs polling, network policy often settles the choice faster than feature comparisons do. A webhook sounds simple until you learn the customer cannot accept inbound HTTPS traffic at all. If their network blocks public callbacks, your clean event flow stops before the first test.
Ask one direct question early: can their system receive inbound requests from the internet, or can it only make outbound calls? Many companies allow outbound API requests but block inbound traffic by default. In that setup, polling usually gets approved with less debate.
Security teams often add more limits after they approve the general idea. They may want fixed source IPs to allowlist, a VPN tunnel, a private network path, or traffic routed through a proxy. Each extra rule adds setup time and more ways for tests to fail.
A short call with the customer's security or IT team can save days of back and forth. Ask about inbound HTTPS access, source IP allowlists on both sides, VPN or private network requirements, proxy rules, TLS inspection, custom certificates, and separate test and production endpoints.
Certificates, DNS, and test endpoints sound minor, but they often slow teams down more than the integration code. Someone has to create the hostname, issue the certificate, confirm the chain works, and make sure the test environment matches production closely enough to trust the result. If any one of those steps drifts, webhook delivery fails and people blame the API.
Polling fits locked-down networks more easily because the customer system starts the connection. That model works well when security rules are strict, or when nobody wants to open a public endpoint for a single integration. You trade some freshness for easier approval and less network setup.
If the customer can receive inbound traffic and already runs public APIs, webhooks may still be the better fit. If every firewall change needs a ticket, two reviews, and a maintenance window, polling often wins on practicality alone.
What support work each option creates
Support load often decides REST hooks vs polling more than the transport itself. Both can work, but they fail in different ways, and your team gets different tickets.
Hooks usually create setup tickets first. A customer gives you an endpoint, but it rejects your test call, times out, fails TLS checks, or returns a 401 because someone copied the wrong secret. Your team then needs the exact request timestamp, the response code, a payload sample, and a delivery log that shows every attempt. Without that record, both sides guess.
Polling shifts the pain after launch. The integration looks fine at first, then users ask why an order still shows the old status 15 minutes later. Support also gets rate-limit questions when a customer shortens the poll interval to "fix" stale data. One quiet integration can turn into a steady stream of small complaints.
Schema changes cause trouble with both options. A customer hard-codes field names, assumes a field will never be null, or ignores unknown fields until a small API change breaks parsing. Support moves faster when the team can compare an old payload sample with a new one and point to the exact field that changed.
A lean team should collect the same basics for every case: the request or delivery timestamp, the customer account or integration ID, a sample payload, the response code or error text, and the retry history or poll interval.
Clear setup steps cut a lot of back and forth. Tell customers how to validate their endpoint, which status code you expect, how request signing works if you use it, how often polling makes sense, and who should get alerts when delivery fails.
If you support many small customers, polling can feel easier at first because it avoids inbound endpoint setup. Hooks often create less noise later if you give customers good logs, sample payloads, and a retry policy they can actually understand.
A simple example with order status updates
A small online store needs to tell its shipping partner when an order moves from "paid" to "packed" and then to "shipped". That sounds minor, but this one choice affects how fast labels get created, how often support gets confused, and how much cleanup the team does later.
With hooks, the store sends an event as soon as the status changes. If warehouse staff pack an order at 10:02 and mark it shipped at 10:04, the shipping partner gets both updates within seconds. The partner can print the label, reserve pickup, and show the customer a fresh tracking view almost right away.
Polling feels calmer at first. The shipping partner asks the store's API for changes every five minutes. That works if they only care about the latest status, but it gets messy when states change fast.
Imagine this timeline:
- 10:02: order becomes "packed"
- 10:04: order becomes "shipped"
- 10:05: partner polls and only sees "shipped"
Now the "packed" step never shows up on the partner's side. If nobody needs that step, this is fine. If the partner uses "packed" to trigger label creation or warehouse prep, the delay causes trouble.
Network rules can flip the decision. Some partners do not allow inbound traffic from outside systems, so a webhook endpoint is not an option without extra firewall work. In that case, polling is often the practical choice, even if it is less fresh.
The store may still prefer hooks because support is easier. Each event can have its own delivery record, timestamp, and retry history. When a partner says, "We never got the shipped update," the store can check one event and answer with something concrete.
Polling gives a fuzzier trail. Support usually has to ask when the partner polled, which page of results they fetched, and whether their job skipped that order because of a timeout. That does not make polling bad. It just means the option that looks simpler on day one can create more back and forth once real orders start moving.
How to choose step by step
Start with the business action, not the transport. In the REST hooks vs polling debate, teams often argue about architecture before they agree on what the integration must actually send. That is how simple work turns into cleanup later.
A short decision path keeps the choice practical.
- Write down the exact events you need, plus the fields each event must include. "Order updated" is too vague. "Order shipped" with order ID, status, timestamp, and carrier code is clear enough to build and test.
- Set the maximum delay a user can live with. If a 10 minute lag is fine, polling may be good enough. If users expect changes almost right away, hooks usually fit better.
- Check network limits on both sides before anyone writes code. Some customers can receive inbound requests without trouble. Others sit behind strict firewall rules or approval steps that make webhooks painful from day one.
- Decide how failures work in plain language. Pick retry timing, how long you keep events for replay, and how the receiver should handle duplicates. If you skip this, support tickets will define the rules for you.
- Test with one noisy customer before a broad rollout. Use a customer with real traffic, occasional failures, and messy edge cases. Quiet test data hides weak spots.
One detail gets missed a lot: make someone own the delivery log. When a customer says, "We never got the update," your team needs a fast way to check what was sent, when it was retried, and whether the receiver answered.
If the customer has tight network rules, weak ops support, or no appetite for replay logic, polling is often the safer first version. If freshness matters and both sides can support retries and monitoring, hooks usually save time for users. The best interface is the one your team can explain, test, and support without guesswork.
Mistakes that create rework later
Teams often treat the interface choice as a small plumbing decision. It is not. In REST hooks vs polling, one shortcut early on can turn into months of support tickets, missed updates, and manual fixes.
A common mistake is choosing hooks before you have delivery logs. When a customer says they never received an event, your team needs facts, not guesses. You should be able to see when you sent it, which endpoint you called, what response came back, and whether you tried again.
Polling creates a different kind of pain when teams run it on a rigid schedule and never slow down. If the customer API starts failing, a fixed one minute loop can keep hammering it and make recovery harder. Backoff matters because it gives the other side room to recover and keeps your own error queue under control.
Another expensive mistake is sending tiny events that force the receiver to fetch more data every time. If you send only "order updated" with an ID, the customer may need several extra API calls just to learn the new status, amount, or timestamp. That adds delay, more failure points, and more support work. Most events should carry enough detail for the receiving system to act right away.
Duplicates cause some of the worst rework because they look harmless at first. A second "payment captured" event can create a duplicate ledger entry. A second "stock reduced" event can throw inventory off by one, and nobody notices until the weekly count. Give each event a unique ID and make receivers ignore repeats.
Offering both hooks and polling sounds friendly, but it doubles edge cases, docs, and troubleshooting paths. If your team cannot test, monitor, and support both well, one solid option is usually better than two half-finished ones.
Before launch, test a few ugly cases. Post the same event twice. Return a 500 from the receiver. Let the receiver time out for ten minutes. Make the polling client hit rate limits.
If those cases already look messy in staging, they will cost real time and money in production.
A short checklist before you decide
Most teams decide too early. They pick the interface they prefer, then learn the customer network blocks it or nobody can explain where a missed event went. A short review now can save a rebuild later.
Use these five checks before you commit to REST hooks vs polling.
- Ask if the customer can receive inbound HTTPS requests on a public endpoint. If they cannot, hooks will be hard to run in practice. Polling is less elegant, but it usually survives stricter network rules.
- Put a real number on delay. Do not settle for "fast" or "near real time." If the workflow can wait 60 or 120 seconds, polling may be fine. If even a 5 second delay hurts the business, hooks make more sense.
- Decide who owns retries and replay before the first failure happens. With hooks, the sender often retries failed deliveries. With polling, the receiver often owns the logic to catch up after downtime. Write down time limits, retry gaps, and how someone can request a missed event again.
- Check whether support can trace one event from start to finish. A good test is simple: can someone follow one order update from send to receipt to processing, using logs or IDs? If the answer is no, support work will get messy fast.
- Test the design against your largest customer, not your easiest one. Big customers often have tighter firewalls, longer review cycles, and stricter audit needs. If the setup breaks there, you will redo it later.
A small example makes this real. If an order status change must reach a warehouse in 10 seconds, polling every 5 minutes is already wrong. If finance only needs synced data every few minutes, polling may be the safer and cheaper choice.
If one answer still feels vague, stop and run a small test first. That is usually cheaper than arguing about architecture on a whiteboard.
What to do next
Pick one interface as the default for most customers, and make that path feel complete. Write the docs for it first, test it first, and make support expect it first. Teams get into trouble when they treat REST hooks vs polling as two equal tracks from day one, then end up maintaining twice the docs, twice the test cases, and twice the support questions.
Your default should match the customers you already sell to. If customers need near-real-time updates and can accept inbound requests, hooks usually make more sense. If customers work behind tight network rules or have slower approval processes, polling is often easier to get live.
Keep the second option, but treat it as an exception path. That gives sales a way to handle unusual cases without making product and support carry extra work for every customer.
A practical next move is simple. Choose one default interface for most new integrations. Define clear reasons to allow the second option. Ask support how many tickets each mode is likely to create. Ask infra who will monitor failures, retries, and delivery gaps. Then put the rule in your customer-facing docs.
Before you promise both modes widely, review the support cost in plain numbers. Count setup time, ticket volume, log review, retry debugging, and customer education. A design that looks flexible on a roadmap can turn into a weekly drain on engineering and support.
If product, infra, and support each want something different, an outside review can help. Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor, and this is the kind of trade-off he helps teams sort out early, before it turns into a support problem.
Frequently Asked Questions
When should I choose hooks instead of polling?
Use hooks when users or ops teams need the update almost at once. Payment failures, fraud checks, account lockouts, and shipping changes usually fit that pattern.
Pick polling when a short delay changes nothing. Reports, summaries, and back office syncs often work fine on a schedule.
When is polling the better default?
Polling works well when customers sit behind strict network rules or cannot expose a public endpoint. It also gives you a simpler first setup for many small customers.
Just set an interval that matches the business need. If you poll too slowly, users see stale data. If you poll too often, you waste requests and hit limits.
How much delay is too much for polling?
Start with a blunt test: what actually breaks at 30 seconds, 5 minutes, or 1 hour? If nothing breaks for a few minutes, polling likely fits.
If a user cannot move to the next step without fresh data, use hooks instead of trying to hide the delay with frequent polling.
What usually goes wrong with hooks?
Retries and duplicates cause most of the pain. A receiver can handle an event, fail before it returns 200, and then get the same event again on retry.
Give every event a stable ID and make the receiver ignore repeats. Also protect against out of order events so older data does not overwrite newer state.
Do hooks always need retries and idempotency?
Yes. If you send hooks, you need a retry policy before launch. Decide which errors deserve another attempt, how long you keep failed events, and when you stop.
You also need idempotency on the receiver side. Without it, one timeout can turn into duplicate invoices, emails, or order changes.
How do firewall rules change the decision?
They often decide the answer before the API does. Many customers allow outbound API calls but block inbound HTTPS traffic from the internet.
If they cannot accept inbound requests, polling wins on practicality. If they already run public APIs and can allowlist your traffic, hooks may still fit better.
Which option creates more support work?
Hooks usually create setup tickets first. Teams run into bad secrets, TLS problems, timeouts, and endpoint mistakes during launch.
Polling shifts the pain later. Users start asking why data still looks old, or customers shrink the interval until they hit rate limits.
Should I support both hooks and polling?
Only offer both if your team can explain, test, monitor, and support both well. For many teams, one solid default beats two half done paths.
Keep the second option for exceptions if real customer needs justify it. That keeps docs, testing, and support simpler.
What should I log so support can debug missed updates?
Log enough detail to answer a ticket fast. Store the event ID or request ID, timestamp, destination, response code, timeout details, retry history, and the next planned action.
For polling, record the poll interval, the time window, and what the client fetched. Those details turn guesswork into a direct answer.
What is the simple rule for order status updates?
If the partner needs every step right away, use hooks. If they only need the latest state every few minutes, polling often works.
For order updates, ask one thing first: does the receiving side need each state change, or only the newest status? That answer usually makes the choice clear.


