Repository context packs for faster onboarding and fewer handoff gaps
Repository context packs help new hires and AI agents find commands, service maps, and common failures without chasing docs across fifteen tabs.

Table of Contents
Why people lose time in a new repo
Most onboarding delays start before anyone writes code. A new person opens the repo and sees ten folders, three Docker files, and two READMEs that disagree with each other. They can't tell where the app starts, which folder matters for the first task, or whether they need the web app, the API, or both.
That confusion spreads fast. If the frontend calls one API, that API calls a worker, and the worker depends on Redis or a queue, people start guessing instead of following a clear path. They read source files, trace imports by hand, and burn half a day on something that should take twenty minutes.
Commands make the next mess. Teams often keep the real setup steps in Slack, old tickets, shell history, or one engineer's memory. A new hire copies a command from a six-month-old chat thread, runs it, and gets the wrong env file, stale seed data, or a broken local database. The command used to be right. The repo moved on.
Small setup errors block work earlier than most teams expect. One missing secret, one port conflict, one job queue left off, or one skipped migration can stop the first simple ticket. People then start changing random settings just to get unstuck, and that usually creates a second problem.
It happens in ordinary bug fixes. A developer joins on Monday and tries to fix a small checkout issue. They start the frontend, but the checkout button fails because the billing service is down. They start billing, but billing needs a local webhook stub and a seeded database. By lunch, they still haven't touched the bug.
The same thing happens with AI agent onboarding. An agent can read code fast, but it still needs the repo's real entry points, service map, and working commands. Without that context, it makes the same bad guesses a person makes, just faster.
A context pack cuts out that guesswork. It gives people enough context to do useful work on day one instead of spending the day reconstructing how the repo works.
What a context pack should include
A good pack answers the questions people ask in the first hour, not the first month. If someone opens the repo and still needs ten messages to get started, the pack is too thin.
Keep it short, but include the parts that usually block progress:
- a short summary of what the repo does and where it fits in the product
- a service map that shows the main apps, workers, databases, queues, and outside services
- the exact commands for setup, local runs, tests, resets, and seed data
- a short list of common failures, with the first fix to try
- a small glossary for internal terms and acronyms
The summary should stay plain and boring. One paragraph is enough. Say whether the repo is a customer app, an internal tool, a shared backend, or something else. If it talks to three other services, name them.
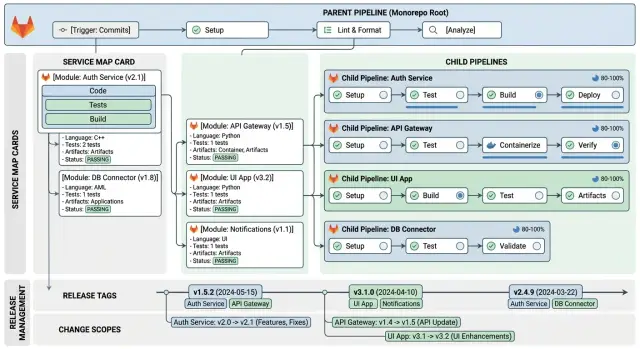
The service map matters more than most teams think. New people rarely get stuck on code first. They get stuck on boundaries. They don't know which service sends the webhook, where auth lives, or who can answer a database question. Even in a small team where one person owns half the stack, it helps to write that down.
Commands need real copy-and-paste examples. Don't write run the usual dev script. Write the exact command. If people need Docker, a local env file, or seed data before the app starts, say so in order.
Failure notes save an absurd amount of time. Port 3000 is busy and migrations fail if Postgres is old sound minor, but both can waste an afternoon. Add the first fix that usually works.
A short glossary closes the last gap. Teams forget how much private language builds up around a repo. A dozen clear definitions can remove a lot of guessing.
Start with a simple repo map
People get lost in a new repo for a simple reason: they don't know where to look first. A plain repo map fixes that fast. It gives one clear view of the codebase, the starting files, and the areas that matter on day one.
Keep the map short. One screen is enough for most teams. Show the top folders and add one note for each. Skip deep detail. If someone opens a context pack and sees a wall of text, they'll ignore it.
A small product team might write it like this:
/apps user-facing app and admin UI
/api HTTP routes, auth, business logic
/jobs scheduled tasks, queues, imports
/scripts local setup, data fixes, one-off tasks
/packages shared code used by app and API
/infra deployment, Docker, CI settings
/docs product notes and internal runbooks
Then mark the entry points people ask about most. Name the file or command that starts the app, the API, the background jobs, and the common scripts. If the app starts in apps/web, say that. If scheduled work runs from jobs/worker.ts, say that too. New people should not need to search five folders just to run the product.
It also helps to say what they can ignore at first. Most repos have areas that matter later, not today. Old migration files, infra templates, billing edge cases, or archived tools often distract more than they help. Call those out so a new engineer or an AI agent stays focused.
Add ownership next to the parts that break often. This can be as simple as API auth flow - Elena, billing jobs - Marco, deploy scripts - Priya, and shared types - Dan. That isn't org-chart trivia. It saves time when something fails and nobody knows who has the history.
Write down the commands people actually use
A context pack becomes useful when it saves someone from asking what to run first. Most teams have a pile of commands scattered across old docs, shell history, and chat threads. New people don't need all of them. They need the small set that gets the repo installed, running, checked, and unstuck.
Start with setup. Put the install and bootstrap commands near the top, in the order people run them. If the repo needs language versions, package managers, environment files, seed data, or local secrets, say that in plain words right above the command. A new hire should not have to guess whether make setup also creates the database or whether they still need npm install.
Then group run commands by service, not by tool. People think in terms of API, worker, and web app, not package managers and shell wrappers. For each service, give one normal local start command and one short note about what it does. If the team usually starts several services together, include that command too.
Make sure the pack covers four basic jobs: installing and bootstrapping the repo, starting each service locally, running the checks people trust before a commit, and resetting local state when the app breaks.
Reset commands matter more than teams think. Local state breaks all the time: stale containers, bad cache, half-applied migrations, wrong generated files. If people often fix this with docker compose down -v, make reset, or a script that rebuilds the database, write it down. Also say what the reset deletes. Nobody wants to wipe sample data by accident.
Tests and lint commands should be the exact ones the team actually uses, not every option the tool offers. If engineers usually run one fast unit test command before pushing and a fuller suite before merging, show both. That small detail saves time and cuts noisy handoffs.
If the team allows production checks, keep them safe and read-only. Good examples include fetching logs, inspecting job queues, checking app health, or comparing config values. Mark those commands clearly and say who can run them.
A context pack works when a new person can copy the commands, paste them, and get useful output in ten minutes. If that doesn't happen, trim the list and rewrite the notes until it does.
List the failures that happen every week
The fastest way to cut onboarding time is to write down the problems that keep coming back. Most teams do not lose hours on rare bugs. They lose them on the same small setup issues, over and over.
Start each note with the symptom people see first. App won't start because port 3000 is busy is much better than a vague note about local setup. Add the one command that shows which process owns the port, then the safe fix.
Environment problems deserve their own space because they waste so much time. A missing .env file, one wrong variable name, or a copied value from another project can break login, payments, email, or third-party APIs. Write the exact variable names people often miss, where the sample file lives, and which values must never be faked.
Database drift is another weekly problem. If the schema is behind, people see confusing errors and assume the code is broken. Say when they need to run migrations, how to seed test data, and how to tell whether their local database matches the current branch.
Some failures look like app bugs but are really missing background jobs. If the worker isn't running, emails don't send, imports stall, and webhooks sit in a queue. Spell out which process handles jobs, how to start it, and how to confirm it is alive.
Caches and queues also trip people up. Old state can make a fixed bug look unfixed. Note when it is safe to clear Redis, reset a local queue, or restart a dev service.
Each failure note should fit on a few lines:
- what it looks like
- the usual cause
- the first check
- the fix that works most often
- when to ask for help
That format also works well for AI agents because it gives them a clear path instead of sending them through old docs and chat threads.
Build the pack step by step
A useful context pack starts with observation, not guesswork. Ask one person who has never used the repo to set it up from zero. Stay nearby, but don't rescue them too quickly. Every pause, wrong command, and side search tells you what the pack is missing.
Write down every command they run in the order they run it. That includes install steps, local start commands, test commands, database setup, seed scripts, and any login or token setup. If they copy a command from an old Slack message or shell history, put that in the pack too. Hidden tribal knowledge is still knowledge.
- Watch a clean setup on a fresh machine, container, or VM. Old local state often hides broken instructions.
- Record each command exactly as used. Add one short note about what it does and when to run it.
- Remove anything they do not need on day one. Most new hires do not need deployment steps, admin scripts, or rare debug tools yet.
- Give the draft to a second person and ask them to follow it alone. Their confusion becomes your edit list.
- Keep the file in the repo, close to the code, and update it when commands, ports, env vars, or service names change.
This works because it stays close to real behavior. People rarely fail on the big ideas. They fail on small gaps: which service starts first, which .env file matters, why migrations fail, or why the app runs but the worker does not.
When the second person tests the draft, pay attention to where they stop asking about setup and start asking about the system. That is usually where a simple service map and a short common failures section help most.
Treat the pack like code. When someone changes Docker, auth, local scripts, or app startup, they should update the pack in the same pull request. If updates happen later, they usually never happen.
A simple example from a small product team
Maya joins a five-person product team on Monday morning. Her first task is small but real: users fill out the signup form, click submit, and never get the confirmation email. Without a clear starting point, she could lose half the day opening random folders and asking where the bug lives.
A good context pack cuts that down fast. On the first page, Maya sees a simple service map: the web app handles the form, the API creates the account, and the mail worker sends the confirmation message. She knows where to look before she reads a long doc.
The pack also gives her the exact setup steps the team actually uses: pnpm install, docker compose up -d, pnpm dev, and pnpm db:seed. That is enough to get the app running with test data. No digging through old chat threads. No guessing which script still works.
When she starts the project, she hits an error the team already knows well: the mail worker logs ECONNREFUSED because the local mail service is not up yet. The context pack lists that under common local issues and explains the fix in one line. Maya starts the missing container, reruns the worker, and moves on.
By late morning, she can reproduce the bug. The web app sends the form correctly. The API creates the user. The mail worker rejects the job because the signup payload misses a field the worker expects for new accounts. She makes a small fix in the API, runs the happy-path test, and tries signup again. This time the message goes through.
She opens a pull request before the day ends.
That is the real job of a context pack. It doesn't explain every corner of the codebase. It gives a new hire, contractor, or AI agent enough context to start useful work right away.
Mistakes that make the pack useless
A context pack stops helping when it turns into a storage closet. If a new developer opens it and sees fifty scripts, ten diagrams, and no clue what matters first, they will still ask the same questions in Slack.
One common mistake is dumping every command from the repo onto one page. Most teams do not need every script. They need the few commands that get the app running, run tests, seed data, and check logs when something breaks. Five clear commands beat a giant paste of package scripts.
Another problem is the dead service map. Teams draw it once, feel good about it, and never touch it again. A wrong map wastes more time than no map because people trust it. Keep the map small. If the repo has four moving parts, show four. If ownership changes, update the map that day.
Some packs fail because the best notes live somewhere else. The fix for a flaky worker sits in an old wiki page. The real deploy warning is buried in a chat thread from six months ago. Pull those repeat problems into the pack and write them in plain language. New people should not have to go on a scavenger hunt.
Writing for experts is another quiet failure. Phrases like just run the usual migration flow mean nothing to a new hire. They confuse AI agents too, because the agent cannot guess your team's habits. Write one level simpler than feels necessary.
And always add owners. A short note like billing service - ask Ana saves real time. A context pack should reduce guessing, not collect trivia.
Quick check before you share it
A pack feels finished when the author can follow it. That is not a real test. Ask someone who did not write it to use the notes with no extra help. If they still need a trail of chat messages to get the app running, the pack has holes.
A few plain checks usually tell you the truth:
- Time the first setup. A new teammate should be able to clone the repo, install what they need, add local config, and start the app in under an hour on a normal laptop.
- Give them one small task. They should see which services matter without reading every repo and every doc.
- Put one familiar local problem in front of them, such as a busy port, missing seed data, stale migrations, or a broken env value. They should be able to fix at least one of these alone by following the notes.
- Try the same pack with an AI agent. If the agent cannot tell which command to run, where logs live, or which service owns a feature, the writing is still too vague.
- Name one owner and put a monthly review on the calendar. Commands change. Services move. Error notes age even faster.
The first two checks tell you whether the pack helps people start work. The third shows whether it helps them recover from the first bump. The fourth is more useful than it sounds. Notes that work for an agent usually work better for humans too.
The last check matters most over time. Teams often build a solid pack once, then let it drift for six months. After that, people stop trusting it. One owner does not need to rewrite everything each month. They just need to run the setup, remove dead commands, and update the failure notes that changed.
If a new person can start the app, trace a small change, solve one normal error, and do it from the same page an agent can use, the pack is ready to share.
What to do next
Pick one repo that changes every week and start there. Don't begin with the oldest, messiest codebase just because it feels more serious. You want fast feedback from real work, and an active repo gives you that.
Keep the first draft small. One page of plain notes plus a few command blocks is enough for version one. If someone can read it in ten minutes and get the app running, you're on the right track.
A good first draft usually covers four things: what the repo does and which services it talks to, the commands people use to install, run, test, and reset it, the failures that happen all the time and how to fix them, and any setup step people forget, such as seed data, env vars, or local ports.
Don't polish it for weeks. Put it in front of the next new hire, contractor, or AI task and watch where progress stops. If they ask where the worker runs, why tests fail on first setup, or which service owns a certain table, add that answer to the pack.
That review loop matters more than perfect writing. Most teams already know the rough spots in a repo, but the knowledge lives in chat threads, old tickets, and one person's memory. A context pack starts paying off when those rough spots move into one place and stay easy to update.
If you want outside help, Oleg Sotnikov at oleg.is works with startups and small teams as a Fractional CTO and advisor. His focus on lean engineering, AI-first development, and practical automation fits this kind of onboarding work well.
Start with one repo this week. Ship the first version while it still feels a little plain, then improve it after the next real handoff.
Frequently Asked Questions
What is a repository context pack?
A repository context pack is a short guide that helps someone start useful work in a repo without digging through chat, old tickets, or source files first.
It should tell them what the repo does, which services connect to it, which commands to run, and what usually breaks during setup.
What should I include in the first version?
Start small. Put in a one-paragraph repo summary, a simple folder map, a service map, the exact setup and run commands, and a few setup problems that happen all the time.
If a new person can clone the repo, start the app, and fix one normal local issue with that page alone, version one is good enough.
How long should the pack be?
Keep it to one page if you can. Most people need answers for the first hour, not a full system manual.
When the file gets too long, people stop using it. Trim anything they do not need on day one.
Where should I keep the context pack?
Store it in the repo, close to the code. That keeps it visible during normal work and makes updates easier.
When someone changes startup scripts, ports, env vars, or service names, they should update the pack in the same pull request.
Which commands belong in the pack?
Write the commands people actually use to install dependencies, create local config, start each service, run tests, seed data, and reset local state.
Use exact copy-and-paste commands. Replace vague notes like run the usual script with the real command.
Do AI coding agents need the same context pack as new hires?
Yes. An agent reads code fast, but it still needs the repo's entry points, service boundaries, and working commands.
If you skip that context, the agent guesses just like a new developer does. It just makes the wrong move faster.
How detailed should the service map be?
Keep the service map plain. Show the main app, API, worker, database, queue, and outside services, then note how they connect.
You do not need a huge diagram. A small text map often works better because people can scan it fast.
What setup problems should I document?
Document the problems that waste time every week. Busy ports, missing .env files, stale migrations, down workers, bad seed data, and old cache usually matter more than rare bugs.
For each one, write the symptom, the usual cause, the first check, and the fix that works most often.
How do I know if the pack is actually useful?
Ask someone who has never used the repo to follow the pack on a clean machine. Watch where they stop, guess, or ask for help.
If they can get the app running, trace a small change, and recover from one normal local issue, the pack works.
What makes a context pack useless?
Teams often ruin the pack by dumping every script, every doc, and every old note into one file. That creates another place to get lost.
A stale service map also hurts. If people stop trusting the page, they go back to Slack and shell history.