Repository pattern for testing without a heavy abstraction wall
Repository pattern for testing gives you clean seams for unit tests without wrapping every query in boilerplate. Learn when to add it and when to stop.
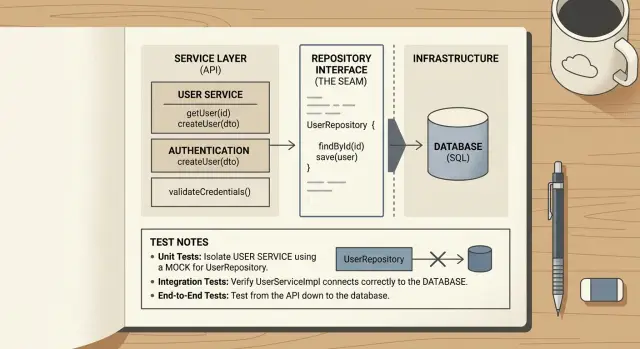
Table of Contents
Why data access gets messy fast
Most codebases do not get tangled because someone planned it that way. It usually starts with one service method that loads a record, checks a few fields, updates something, and sends a response. A week later, that same method has SQL, retry logic, null checks, pricing rules, and a special case for one customer.
That mix is the real problem. Query code and business rules end up in the same place, so every change feels larger than it is. If you want to test a discount rule, you often need a real database row, the right joins, and a lot of setup that has nothing to do with the rule itself.
Schema changes make it worse. Rename one column, split one table, or change how a relation loads, and tests fail across several services. The business action did not change, but the tests know too much about storage details. You fix one query, then spend the next hour fixing fixtures, mocks, and repeated setup.
Copied queries spread quietly too. One query works, so someone pastes it into another service with a small tweak. Then it happens again. Soon you have four versions of the same lookup, each with slightly different filters or selected fields. When the query needs to change, nobody feels sure which version is safe.
Small teams feel this early. You move fast, so you put data access wherever the work is happening. That is normal. Trouble starts when one business rule shows up in several places and each place talks to the database a little differently.
A small seam starts paying off at a very specific moment: when you want to test behavior without caring how the data was fetched. That is often the first sign you need a thin boundary. Not a giant data access layer. Not a wall of interfaces. Just one place where a service asks for data in a stable way.
That is why a thin repository can help, even if you plan to delete it later. The seam gives you one spot to adjust when tables change and one simple dependency to replace in tests. Sometimes that is enough to stop the mess from spreading.
What a thin repository should do
A thin repository gives you one clean seam between your app code and the database. It should not become a second app inside your app. The goal is simple: make database access easy to replace in tests and easy to read in production.
Keep query code close to the database client. The repository should know how to call the ORM, build SQL, bind parameters, and map rows. That work belongs near the tool doing it.
Business decisions should stay out of it. The repository should not decide whether an order can ship, whether a payment should retry, or whether a customer gets a refund. Put those choices in a service or use case layer, where the rules already live.
A good thin repository returns plain app data. That might be a small struct, a record, or a plain object with the fields your app actually uses. Tests get easier when they work with simple data instead of ORM objects with lazy loading, hidden state, and surprise database calls.
That plain return shape also makes refactoring less painful. If you switch ORMs, rewrite a query, or move one read to raw SQL, the rest of the app does not need to care. The seam stays the same.
Thin repositories also keep a small promise. A method like findOrderById(id) or savePayment(payment) is easy to understand. A method like processOverdueInvoicesAndNotifyUsers() has already crossed the line. It mixes storage with app behavior, and it is hard to test for the right reason.
One more rule matters: stop early. You do not need a full data access layer for every table on day one. Build one repository where tests hurt, where query code repeats, or where the ORM leaks into too many files.
If that first seam saves time, keep it. If the rest of the code is still clear, leave it alone. A repository you can delete later is usually better than a grand abstraction layer you have to defend for years.
Pick one seam and leave the rest alone
When tests hurt, the answer is rarely
Frequently Asked Questions
Do I need a repository for every table?
No. Start with the part that causes test pain, repeated queries, or ORM code spread across several files. If the rest of the code is still easy to read, leave it alone.
What makes a repository thin?
A thin repository only handles data access. It builds queries, talks to the database client, and maps results into simple app data. Once it starts making product decisions, it stopped being thin.
Where should business logic go?
Keep business rules in services or use case code. That is where you decide things like refunds, retries, or whether an order can ship. The repository should only fetch and save the data those rules need.
What should a repository return?
Return plain data your app already understands, like a small object or record with the fields you use. That keeps tests simple and stops ORM state or lazy loading from leaking into the rest of the app.
How does a repository help with testing?
You can swap the repository with a fake or stub and test behavior without setting up real tables, joins, and fixtures. That lets you test the rule you care about instead of your storage setup.
When should I add the first repository?
Add one when a service mixes SQL with business rules, when the same query appears in several places, or when schema changes break too many tests. Those are good signs that one small seam will save time.
Can I still use my ORM directly?
Yes. If a direct ORM call stays clear and local, keep it simple. Use a repository where you need a stable seam, not as a rule for every read and write.
Can I delete the repository later?
Yes, and that is often a good sign. If the seam stops paying for itself, remove it. A small repository should make change easier, not become something you keep just because it exists.
What happens when the schema changes?
It gives you one place to update when tables, columns, or relations change. Your service code and many of your tests can stay the same because they depend on the repository shape, not the storage details.
How do I know a repository got too big?
Watch for methods that do more than load or save data. If a repository starts sending emails, applying pricing rules, or chaining several business actions, split that work back into a service and keep the repository small.


