Repo ownership for AI coding: who owns what in the repo
Repo ownership for AI coding helps teams stop cleanup loops, assign maintainers by module, and let AI assistants support faster, safer changes.
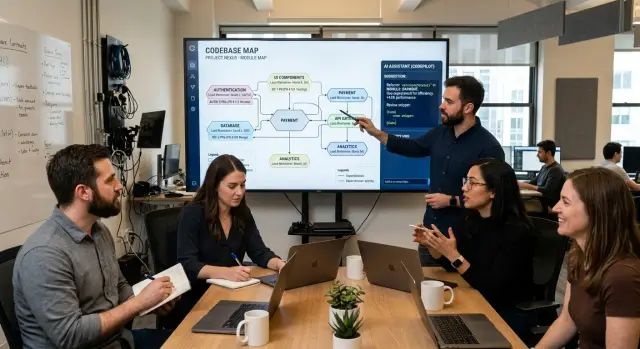
Table of Contents
Why fuzzy ownership slows the whole repo
A shared repo slows down when whole folders feel "owned by everyone" and, in practice, by no one. One person changes an auth helper, another edits the API layer, and a third tweaks tests. Each change looks small. Put together, they create a review nobody really wants to own.
AI makes that worse. Ask an assistant to fix a bug inside a module with weak boundaries and it often wanders into nearby files. It updates types, refactors helpers, rewrites tests, and renames things that were never part of the task. Some of those edits are fine. The real problem is speed: nobody can say, quickly and with confidence, which changes belong in the module and which ones cross a line.
When ownership is vague, cleanup falls to the first person who notices trouble. That is usually the reviewer with the most context, not the person who opened the pull request. So the team pays twice: once for the AI-assisted edit, then again for sorting, reverting, and fixing the extra damage.
You can spot the slowdown pretty easily. Reviews sit because people ask who decides. The same comments come back on naming, structure, and test scope. Small bugs survive because every reviewer assumes someone else knows the area better. Decisions stay half-made, so the next task opens the same debate again.
That is why ownership matters so much when AI helps write code. This is less about control than speed. Clear maintainers give the team a fast answer when code crosses boundaries. They cut drift, stop repeat fixes, and keep AI work focused on the files that actually belong to the task.
What ownership means in a shared codebase
In practice, ownership is simple: one named person decides what good looks like for a module, reviews changes that affect it, and keeps it healthy over time. That does not mean they write every line. It means they notice when tests drift, docs go stale, or quick fixes start to pile up.
Teams often confuse ownership with rank. They are different. The most senior engineer does not need to own everything, and a title does not decide who should own a module. A midlevel engineer can own a stable service they know well. A founder can own product logic if they still make product calls.
Writing code and owning code are different jobs. Anyone on the team might open a pull request for the billing module. The owner decides whether the change fits the module, asks for fixes when needed, and keeps the long view in mind. When behavior is unclear, the team knows who answers.
That difference matters even more when AI writes part of the code. An assistant can help many people move faster, but it cannot carry responsibility after the merge. If nobody owns a module, the repo fills up with mixed patterns, odd shortcuts, and cleanup work that lands on everyone.
Small teams do not need a perfect map. One person can own several small modules, and that is normal. What matters is that names are clear. If everyone knows who decides, who reviews, and who keeps each part healthy, the codebase stays calmer.
Why AI coding gets messy without clear maintainers
AI assistants copy what they see nearby. That sounds harmless until one repo holds three different ways to name handlers, structure tests, or pass data between layers. The assistant does not stop to ask which pattern is current. It extends the local style, even when that style clashes with the next module over.
That is why clear ownership matters more than many teams expect. When nobody owns a module, prompts stay vague: "fix this flow," "clean up the API," "add retries." The assistant crosses file boundaries too easily. A small request turns into a wide diff that touches helpers, tests, config, and naming in places nobody meant to change.
Review gets slow for a simple reason. Nobody can say yes or no with confidence. One engineer knows the billing rules, another knows the job runner, and a third wrote the shared utils six months ago. The AI may produce decent code, but the team still spends an hour figuring out who should approve it, which parts are safe, and whether the new pattern belongs there at all.
A small example makes it obvious. Say the assistant adds caching to one service and copies the same cache style into another module with different failure rules. The diff looks tidy. The bug shows up later, when stale data reaches users because that second module needed strict freshness.
AI works best when rules stay local. A maintainer for each module gives the assistant a narrow target: use these conventions, touch these files, and stop at this boundary. That usually leads to smaller diffs, faster review, and less cleanup after the merge.
How to assign maintainers by module
Start with product areas people already talk about every day. Good module names sound like real work: signup, billing, reporting, admin, mobile app, data import. That makes ownership easier to follow because the folder names match the team's language.
Give each module one main maintainer. That person decides whether a change fits the module, whether the tests are enough, and whether the assistant made the code harder to live with. Add one backup if you need coverage for time off or urgent fixes. Once you name three or four owners for one area, ownership turns into a group shrug.
Keep modules small enough that one person can review changes without rebuilding the whole product in their head. If one area mixes API routes, background jobs, and two unrelated features, split it. A maintainer should understand the module well enough to spot bad AI output in a few minutes.
Draw the boundary once
Write down the edges of each module in plain language. A short note in the repo is enough if the rules are clear.
For each module, note the main maintainer and backup, the folders and tests it includes, which shared libraries it can use, what should stay outside the module, and who reviews changes that touch more than one area.
Shared libraries need a hard line too. Put common auth helpers, design tokens, logging, and low-level utilities in shared space. Put product behavior in app modules. A billing module can call a shared payment client, but pricing rules and invoice flows still belong to billing, not the shared folder.
On small teams, this split works because it follows how people already think about the product. When an AI assistant edits code inside clear boundaries, the maintainer can approve it fast. When the boundaries are vague, everyone inherits the cleanup.
A simple way to map the repo
A good ownership map should fit on one screen. If it turns into a big document, people stop reading it and assistants stop following it.
Start with the top folders or modules. For each one, write a single owner. One person can still ask for help, but one name removes doubt when an AI draft touches a file that might break tests, deployments, or shared logic.
A simple map might read like this:
/api- Sam owns billing and auth. Risky files include payment flows. Tests run in the backend suite. Deploy changes affect the main service./web- Nina owns the customer UI. Risky files include checkout and account settings. Tests run in the frontend suite. Deploy changes affect the public app./infra- Leo owns CI, secrets setup, and deployments. Risky files include build pipelines and environment config. Changes can affect every release./data- Priya owns schema changes and reporting jobs. Risky files include migrations. Tests run in the data suite. Deploy changes can block writes.
Those notes do not need to be perfect. They just need to answer four questions fast: what this area does, which files need extra care, how to test it, and what happens if it goes live.
Then review the map with the team right away. A quick 20-minute pass usually exposes the gaps. You will find folders with no owner, two people claiming the same area, or old modules that nobody wants to touch.
Store the map where contributors see it before they open a pull request. Put it in the contribution guide, mention it in the pull request flow, and keep it close to the repo instead of hiding it in a slide deck. If people can find it in five seconds, they will use it.
How to use AI inside those boundaries
AI works better when every request starts with a clear home. Before anyone opens a chat or runs a coding agent, they should name the target module in one line: billing, auth, admin UI, or whatever area the team already uses. That small habit cuts down drift fast. The assistant stops guessing, and the rest of the repo stays out of scope.
Each module maintainer should give the assistant a short rule set. Keep it plain: which files define the module, which patterns to copy, which tests must pass, and which files are off limits.
Prompts need hard edges. "Add retry logic to the billing webhook handler and update its tests" works well. "Improve payment reliability across the app" is how teams end up with surprise edits in six folders.
A useful prompt template is short: name the target module, define the exact task, list the files allowed to change, list the files that must not change, and say what test or output you expect.
Cross-module changes need a human checkpoint. If the AI touches code outside the named module, the maintainer for each affected area should review it before merge. That may feel strict, but it prevents a familiar mess: someone asks for a quick fix, the assistant rewrites shared code, and everyone else inherits the cleanup.
A small team can apply this without much ceremony. If a developer works in auth, the auth maintainer can share a few accepted examples, note that session code is fair game, and mark shared middleware as off limits unless another maintainer joins the review. That keeps the AI useful without giving it silent permission to roam.
How review and handoff should work
Most teams review the wrong things. They spend too much time on small edits inside one module, then rush through shared changes that affect other parts of the repo. Clear ownership fixes that by matching review rules to the blast radius of the change.
If a change stays inside one module, let that module maintainer handle it. One reviewer is often enough when the edit does not touch public interfaces, shared types, database shape, or deployment settings. Simple work should move quickly.
If a change crosses module boundaries, slow it down on purpose. Ask the maintainers of every affected module to agree on the interface first, before anyone asks an assistant to write code. A quick approval on the contract can save hours of cleanup later.
A good rule is simple. One module with no interface change can be reviewed and merged by that module's maintainer. One module with an interface change should also be reviewed by the owner of the calling code. If multiple modules are involved, the affected maintainers should agree on the design before coding starts. Database migrations, config edits, and infra changes also need signoff from the person who owns that area.
This matters even more with AI help. Assistants are fast at filling in code once the boundaries are clear. They are much worse at guessing who should approve a migration, whether a config tweak is safe, or how a shared API should evolve.
Handoffs should stay short. The next reviewer does not need a diary. They need a clean note that says what changed, why it changed, what needs special attention, and which tests, migrations, or config edits still need signoff.
That is enough context for the next maintainer to spot bad assumptions before they spread.
A realistic example from a small team
Three developers run a small SaaS product with one shared repo. Mia owns billing. Dan owns onboarding. Lena owns internal tools such as admin scripts, support panels, and small ops utilities.
A customer asks for a change to prorated refunds when a company downgrades its plan mid-cycle. Mia uses an AI assistant to draft the update. The first result looks fine at a glance, but the diff is wider than it should be. It changes billing logic, then reaches into shared helpers for date math, money formatting, and event naming.
This is where ownership either helps or falls apart. Dan and Lena now have to read code outside billing, even though the original request had nothing to do with onboarding or internal tools.
Mia cuts the scope before anyone burns an hour in review. She reverts most of the helper edits and keeps the pull request focused on the billing module. Then she asks for one small interface change first: add a shared helper that returns the billing period boundary in a stable format. Billing can use that interface, and the rest of the refund rules stay inside Mia's module.
The second pull request is much cleaner. It adds one interface in shared helpers, updates billing calculations inside billing, and avoids unrelated renames or test rewrites in other areas.
Dan gives the helper a quick review because onboarding also uses billing dates. Lena does not need to review the rest. Mia checks the business logic herself and merges it the same day.
The team ships faster because ownership kept the assistant inside clear lines. The code changed less, the review stayed short, and nobody had to clean up a broad diff a week later.
Mistakes that create cleanup for everyone
Cleanup usually starts with a small shortcut. A team says "backend owns this" or "platform owns that," but no single person can approve, reject, or defer a change. Departments do not review code. People do.
When ownership stays vague, AI tools make the mess bigger. The assistant touches a module, suggests a few nearby edits, and suddenly nobody feels responsible for the final result. It works much better when each module has one named maintainer and one backup.
Another common mistake is adding every senior engineer to every review. That feels safe for a few days, then the queue fills up and people skim. Reviews get slower, comments get weaker, and bugs slip through because each person assumes someone else checked the risky part.
The quietest problem is the "neutral" module. Shared utils, CI scripts, auth glue, prompts, and internal libraries often end up ownerless because several teams use them. Those files need owners more than feature code does, because one bad change can spread pain across the repo.
AI refactors create a different kind of cleanup. A tool sees a naming pattern, updates nearby files, and turns a small fix into a broad rewrite. If nobody set boundaries, that extra work lands on people who were never part of the task. If the ticket is local, keep the AI local too.
Another failure happens in chat. Someone writes, "Maya owns billing now," in a busy thread, and everyone assumes the message was seen. Two weeks later, three engineers review the same file and none of them agree on who decides. Put ownership changes in the repo, the docs, or the review rules where people can find them later.
A few warning signs usually show up before the cleanup starts: pull requests include unrelated files because the assistant kept editing, shared modules have many reviewers but no final approver, senior engineers get tagged by default even for small changes, and ownership changes live in chat instead of a durable record.
Small teams feel these mistakes fast. A five-person startup can lose half a day sorting out one noisy pull request. Clear names, narrow file boundaries, and written ownership rules save more time than tweaking AI settings again.
A quick checklist for your repo
A repo with clear owners feels boring in a good way. People know where to ask, what they can change, and when to slow down. That matters even more with AI, because assistants can produce a lot of edits before anyone notices they crossed a line.
Use this as a quick test:
- A new engineer can open the repo and find module owners in a few minutes without asking in chat.
- Contributors can see which folders or files need extra care, such as auth, billing, migrations, or deployment config.
- A module maintainer can reject AI-generated changes that wander outside the task, and the team accepts that call.
- The pull request makes boundary jumps obvious, such as a change that starts in the UI and also touches API contracts or database schema.
- Reviewers can tell before merge which person must approve a risky change.
If one of those checks fails, the fix is usually simple. Put ownership in places people already read: a CODEOWNERS file, a short note in each module, and pull request templates that ask whether the change crosses into another area. Mark high-risk paths clearly. Keep the language plain.
A small team can do this without too much process. One maintainer might own payments, another owns onboarding, and both must approve a change that edits shared user models. That takes a few extra minutes, but it can save a week of cleanup.
Good maintainers do not slow work down. They stop random edits, reduce review noise, and keep AI output inside the right fence.
Next steps for a cleaner AI workflow
Start where reviews already hurt. Pick the modules that bounce between people, collect the same comments, or break after handoff. Those areas waste the most time, so they usually give you the fastest payoff.
Write down one maintainer and one backup for each of those modules before you add more automation. A short note in your repo docs is enough if it names the module, the owner, the review path, and what an AI assistant can change without extra approval. Clear code ownership beats another clever prompt.
Then make your prompts, review rules, and handoffs follow that same map. If a tool opens a change in billing, it should tag the billing maintainer, use the billing prompt, and go through the billing review check. If your map says frontend and API belong to different people, your workflow should respect that split every time.
A simple rollout is enough: choose the modules with the most review churn, assign one maintainer and one backup for each, add module-specific prompts and review rules, require handoff notes when work crosses module lines, and review the result after two weeks.
Once teams do this, the benefits are usually obvious. Reviews get shorter. Approval gets clearer. Fewer people waste time asking who owns the change.
If you want outside help setting this up, Oleg Sotnikov at oleg.is works with startups and smaller companies as a Fractional CTO and advisor. His work includes AI-augmented development environments, infrastructure, and practical team processes that keep automation useful without turning the repo into cleanup work.
Frequently Asked Questions
What does repo ownership actually mean?
Repo ownership means one named maintainer decides what good looks like for a module, reviews changes in that area, and keeps it healthy over time. That person does not need to write every line of code. They give the team a fast answer when a change fits the module or crosses a boundary.
Does the maintainer need to write all the code?
No. Anyone on the team can open a pull request. The maintainer just owns the decision on scope, quality, tests, and long term consistency for that module.
How do we assign maintainers without adding a lot of process?
Start with product areas your team already uses in daily work, like billing, signup, admin, or reporting. Pick one main maintainer for each module and one backup if you need coverage. Keep the first version simple so people can follow it without a long document.
How small should a module be?
Make the module small enough that one person can review a change in a few minutes without rebuilding the whole product in their head. If one area mixes unrelated features, jobs, and routes, split it. Smaller boundaries make AI edits easier to review and easier to reject when they drift.
Who should own shared utilities and common libraries?
Shared code needs an owner even more than feature code. Give shared helpers, auth glue, CI scripts, prompts, and internal libraries to named maintainers, because one bad edit there can spread pain across the repo. Keep product rules inside product modules instead of pushing them into shared folders.
What should an AI coding prompt include?
Use a short prompt that names the target module, the exact task, the files it may change, the files it must not touch, and the tests that must pass. That keeps the assistant local to the task. Vague requests invite wide diffs and cleanup.
What should we do when AI changes files outside the target module?
Stop and treat that as a boundary jump, not a small extra edit. Ask the maintainer for each affected area to review the change before merge, or split the work into separate pull requests. That saves time later because each owner checks the part they know best.
Where should we store the ownership map?
Put the map where contributors already look before they open a pull request. A CODEOWNERS file, a short note in each module, and the contribution guide usually work well. If people can find ownership in a few seconds, they will actually use it.
Should senior engineers review every AI generated change?
No. If a change stays inside one module and does not alter shared interfaces, one maintainer often gives enough review. Slow down only when the edit touches other modules, database shape, config, deployments, or public contracts.
How can we tell if clear ownership is working?
You will notice faster reviews, smaller diffs, and fewer comments about who decides. People stop tagging half the team for a small change, and maintainers reject AI edits that wander outside the task. Bugs from broad surprise refactors also drop.


