Replace auth, billing, and data flows without a rewrite
Learn how to replace auth, billing, and data flows in small slices, keep your prototype live, and lower risk during a core rebuild.
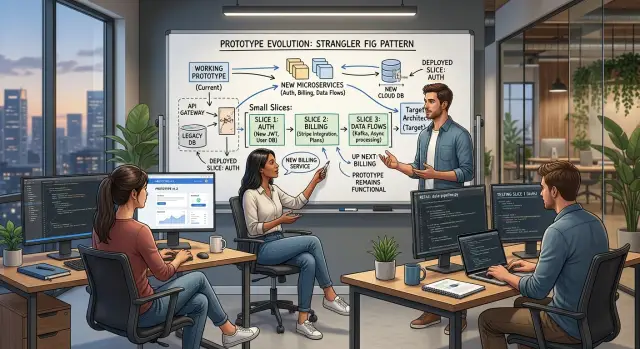
Table of Contents
Why teams get stuck after the prototype works
A prototype can survive far longer than anyone planned. It starts getting real users, real payments, and real deadlines, so the team keeps patching it instead of pulling it apart. After a while, the product still works on the surface, but the core becomes a knot.
That knot usually starts with convenience. Login logic ends up inside account pages. Payment checks leak into feature flags. Data rules get buried in handlers that already do five other jobs. Then one small change breaks something far away. A fix in access control suddenly touches checkout, reporting, and background jobs in the same week.
Teams feel trapped because both options look bad. A full rewrite can burn months, introduce new bugs, and stop product work. Doing nothing is not safe either. Costs rise, release speed drops, and every change feels risky.
The pressure gets worse once customers depend on the product every day. You cannot pause sign-ins for a month. You cannot ask paying users to wait while billing changes. You also cannot freeze reports or internal workflows just because the data flow needs cleanup.
A few warning signs show up again and again:
- One bug fix spreads across many files
- New engineers need days to trace a simple user action
- The team avoids auth or billing unless something is already on fire
Replacing auth, billing, and data flows feels dangerous because those parts sit under everything else. They are woven through the app, admin tools, reports, and often the team's habits too.
That is why so many teams get stuck after the prototype stage. The product is alive, users need it now, and the code no longer offers clean places to work. The issue is not laziness. The system grew in a way that makes every important change feel bigger than it should.
What to keep and what to rebuild
The first mistake in a rebuild is throwing out parts that already work for users. If customers can sign in, finish checkout, and find what they need, keep those screens and steps familiar. People notice broken habits much faster than cleaner backend code.
Start with pain, not pride. Write down the parts that fail most often, create support tickets, or force manual fixes. That list usually points to the real rebuild target: duplicate charges, messy user roles, or data that lands in three places and matches nowhere.
Some systems will stay in place for a while whether you like it or not. Your payment processor, ERP, CRM, app store billing, or partner API may be locked by contracts, compliance rules, or plain business risk. Mark those limits early. A staged rebuild works around fixed systems instead of pretending they do not exist.
Pick one goal for the first round and make it concrete. "Safer billing" is clear enough. "Cleaner data writes" is clear enough. "Modernize the platform" is too vague and usually turns into an expensive detour.
A simple filter works well here: keep what users already understand, rebuild what breaks often or slows the team down, delay changes to outside systems you cannot control, and judge each step by one business goal.
Oleg Sotnikov often advises companies at exactly this point, before any code moves. The calm approach is usually the right one: protect the customer experience, fix the risky core, and leave nice-to-have cleanup for later.
If your prototype grew into a real product, that tells you something useful. The front end may be rough, but it already taught users how the product should feel. Keep that lesson. Rebuild the pieces underneath that keep waking your team up at night.
Find the seams before you touch code
If you want to replace core systems without a rewrite, start with behavior, not code.
Pick three everyday actions: a user signs in, a customer pays, and someone creates or updates data. Then trace each step from the browser or app to the last database write. Most teams think they know these flows. Once they put them on paper, they usually find surprises.
Map every part that joins the path: screens, API endpoints, auth providers, session storage, billing services, webhooks, retry logic, tables, queues, scheduled jobs, and any report or downstream system that reads the same data.
This is where the real risk shows up. A sign-in flow may look like one login form, but it often touches email delivery, token refresh, user tables, role checks, audit logs, and support tools. Billing is usually worse. Failed payments, refunds, and duplicate webhook events leave traces in more than one place.
Once you can see the full path, look for seams. A seam is a place where you can insert a wrapper, adapter, or thin internal API without changing the whole product at once. For auth, that might be a session service that talks to both the old provider and the new one. For billing, it may be an internal payments layer that keeps order creation stable while you swap the provider behind it.
Good boundaries let old and new code run side by side for a while. That matters more than a neat diagram. If both paths can work at the same time, you can move one user group, one plan, or one event type first, watch what happens, and keep going.
If a boundary forces a same-day cutover for every user, it is probably the wrong boundary. Pick seams that give you overlap, logs, and an easy rollback.
Replace one slice at a time
Do not move everything in one release. Pick one boundary people already understand, like sign-in, invoice creation, or the step that writes order data after checkout. A clear boundary gives the team one place to test, measure, and roll back.
Before you build the new path, wrap the old one in simple checks. Log who entered the flow, whether it finished, how long it took, and what error the user saw. Keep the checks plain: "login succeeded," "invoice saved," "payment matched order." If you cannot see current behavior, you will waste time arguing about what broke.
Build the replacement behind a switch the team can turn off fast. That switch can be a feature flag, a header, or a config rule. The exact mechanism matters less than the response time. If support starts seeing failed logins or missing invoices, the team should disable the new slice in seconds, not after a full deploy.
A careful rollout usually follows a short path:
- Send internal users through the new slice first
- Route a small share of real traffic next
- Compare success rate, errors, support tickets, and payment events
- Increase traffic only when the numbers stay stable
This matters most in flows that touch money or identity. If you are replacing invoice creation, test totals and tax lines before the new path creates live charges. If you are changing sign-in, watch password resets and session creation as closely as successful logins.
Small cutovers feel slower on day one. They save weeks later. Once one slice works, the team has a repeatable way to move the next boundary without freezing the whole product.
A simple example from a live product
Picture a SaaS app that grew out of a prototype. Customers use it every day, the screens feel familiar, and the team does not want to throw that away. So they keep the UI and rebuild the parts that cause pain: login, payments, and reporting.
They move in a fixed order, and each step has a narrow goal.
First, they switch login to a new auth service. Users still see the same sign-in page, but the app checks identity through the new system. The team maps old user accounts to new IDs and keeps current sessions alive so people do not get locked out.
Next, they change billing for new sales only. Anyone who starts a new subscription goes through the new checkout and payment flow. Existing subscribers stay where they are for now.
Then they wait for renewals. As each old subscription reaches its normal renewal date, the team moves that customer to the new billing path. They avoid a risky mass migration and give support time to catch edge cases.
Last, they move report data to a new pipeline. The reports page does not change. People keep opening the same screen, but the numbers now come from the new data flow behind it.
This works because it limits blast radius. If login has a problem, billing and reporting still run. If billing has an issue, old subscribers still renew on the old path until the team fixes it.
For a while, the app may write data to both old and new systems so the team can compare totals and spot gaps. That extra work is worth it. You can replace core systems without freezing product work or asking customers to relearn the app.
Swap auth without locking users out
Auth is often the riskiest cut. One bad release can block every user at once. The safest move is to keep the old login system alive long enough for people to pass through the change without noticing.
Do not force every account into the new identity system on day one. Let existing sessions keep working until they expire. If someone logged in yesterday, they should still reach the app today even if you switched the backend overnight. That buys time and cuts support tickets fast.
You also need a clean map between the old user ID and the new identity record. Store both IDs in one place and treat that mapping as part of the migration, not a side note. If billing, permissions, audit logs, or reports still point to the old ID, this map keeps those parts attached to the right person.
A small test plan catches most ugly failures:
- Create a new account
- Sign in with an existing account
- Reset a password
- Accept an invite from another user
- Reuse an older session after the switch
Admin cases usually get messy. Some users will exist in both systems because they signed up twice, used a work email later, or arrived through an invite. Decide before launch who merges those records, what data wins, and what admins can edit by hand. If you leave this vague, support will make case-by-case choices and create more cleanup.
Write a rollback that takes minutes, not hours. If login errors jump, route new sign-ins back to the old system, keep the ID mapping table, and log every failed attempt with the email, provider, and step that broke. A good rollback does not fix the bug. It gives users a working door while the team fixes it.
The teams that handle auth well treat it like a border crossing. They keep both sides open for a while, check each traveler, and close the old gate only after traffic moves cleanly.
Change billing without losing orders
Billing usually goes wrong when teams try to move every charge, every subscription, and every invoice on the same day. That is how orders disappear, refunds get messy, and finance loses trust fast.
A safer move is to send only new purchases through the new billing path first. Leave past subscriptions where they are until you prove the new flow works. New checkout, new invoices, new payment events. Old renewals can keep running in the old system for a while. It is less elegant, but it cuts risk sharply.
A small daily check helps more than a big monthly audit. Compare totals from the old and new invoice streams every day: sales, taxes, discounts, and failed payments. If the new system is off by a few orders on day two, you can fix it before support gets flooded on day ten.
Refunds and charge disputes need one home. If customers and support have to guess where a payment lives, the billing change already failed. Keep one internal place where the team checks payment status, refund history, and dispute notes, even if two billing systems still run behind the scenes for a short period.
If pricing logic changed, freeze plan edits for a brief window. Upgrades, downgrades, proration, and coupon edge cases break more often than first-time purchases. A 24 to 72 hour pause on plan changes is usually easier than cleaning up bad invoices later.
Support also needs a short checklist when a payment looks wrong:
- Check which system created the invoice
- Check the plan, discount, and tax on that invoice
- Check whether the customer was charged once or twice
- Check where the refund must be issued
- Check whether the renewal date changed during migration
A simple example: if a SaaS product moves Stripe logic into a new service, route only brand-new customers there first. Watch the numbers each day. When totals match and support tickets stay quiet, move the next slice.
Move data flows without breaking reports
Reports usually fail for a simple reason: the team changes where data lives, but nobody tracks which numbers the business still trusts. Treat reporting as its own migration. Do not wait until the end to see whether totals still match.
Start by copying data into the new flow while the old one still feeds dashboards and exports. That gives you time to compare records, fix mapping errors, and spot missing events before anyone relies on the new numbers. After that, switch one read path or one report at a time. Move writes later, in small cuts.
A plain ownership table helps more than a fancy diagram. List every field that matters to reporting, such as customer ID, plan name, invoice status, refund amount, and renewal date. For each stage, mark one source as the owner. If two systems both write "subscription_status" and nobody knows which one wins, your reports will drift fast.
Check the numbers every day while both paths run. Compare row counts, money totals, status buckets such as paid, failed, and refunded, plus any missing or duplicated IDs.
Daily checks catch small gaps while logs are fresh and people still remember what changed. If yesterday's report shows 1,204 paid invoices and the new flow shows 1,191, stop and trace the missing 13 before you move anything else.
Keep the old exports for a while, even if the new reports look right. Finance and operations need repeated proof, not one clean test. Many teams relax after one good day and then hit trouble during payroll, month close, or refund review.
Remove duplicate writes last. Wait until the team sees stable numbers across normal days and busy days. It sounds slower, but it cuts rework and gives you a clean rollback if the new flow misses something.
Mistakes that create rework
Teams create rework when they treat a staged rebuild like a clean rewrite. The whole point is to reduce risk. If you change auth, billing, and data flows in the same release, you lose that safety.
One change can hide another. A login bug can look like a billing bug because users cannot reach checkout. A reporting gap can look like bad data when the real issue sits in a new event pipeline. When teams stack three big swaps together, they waste days untangling what actually broke.
Another common trap sits in the data model. Teams redesign tables and fields before they map how people use the product. Then support asks for a refund history screen, finance needs old invoice states, and operations still rely on a strange export nobody documented. The new model looks cleaner on paper, but the team ends up adding patches to recover behavior the old system already handled.
Rollback drills matter more than most teams expect. If you cannot switch back fast, you are not ready to cut over. Run the drill before release day. Time it. Decide who makes the call, who flips the switch, and how you confirm that orders, sessions, and reports still work after rollback.
Small internal tools cause a surprising amount of damage. Background jobs, admin panels, manual refund flows, fraud checks, CSV exports, and support scripts often depend on the old auth or billing logic. Customers may never see those parts, but your team uses them every day. If they fail, work slows down right when you need clear thinking.
Teams also shut down the old system too early. Keep it alive until support closes open tickets, finance clears edge cases, and the team confirms that delayed jobs and late webhooks no longer rely on the old path.
A staged rebuild works best when each slice can stand on its own, fail on its own, and roll back on its own. If a change cannot meet that standard, it is probably too big.
Quick checks before each cutover
A cutover needs a clear pass or fail line. If the team cannot say what success looks like for this slice, wait. Vague goals hide small breaks until customers start sending angry emails.
Write down one or two numbers that prove the new path works. For auth, that might be login success rate and password reset completion. For billing, it could be paid orders created and refunds recorded correctly. Pick measures you can check the same day.
You also need an escape route. If the new flow starts failing, the team should turn it off in minutes. A config switch, feature flag, or traffic split is usually enough. If rollback needs code changes and a fresh deploy, the cutover is too risky.
Use a short preflight list:
- Name the success metric and the number that triggers rollback
- Test failure cases, not just the clean demo path
- Make sure support can see the right user, order, or event details
- Confirm who watches logs and business totals after launch
- Put a review time on the calendar before cutover starts
The unhappy paths deserve extra attention because they hurt real users first. Try expired tokens, duplicate charges, missing webhooks, partial imports, and retry storms. A slice can look perfect in staging and still fail on bad input, slow third-party responses, or older records with messy data.
Support teams need visibility too. If a customer cannot log in or an invoice disappears, support should see enough context to explain what happened and who owns the fix. A simple dashboard or admin note often saves hours.
Set a review date before launch, not after. Then check logs, totals, and user reports against the old system. A staged rebuild works because each cutover stays small, observable, and reversible.
Next steps for a staged rebuild
Most teams need one page, not a giant roadmap. Write down the slice order, who owns each cutover, what success looks like, and how you roll back if something goes wrong. Then share that page with product, support, and finance early. Support needs to know what customers may notice. Finance needs to know when invoices, refunds, or reports might look different.
Pick the first slice by risk, not curiosity. The most interesting part is often the wrong place to start. If login failures create support tickets every week, auth may deserve attention before a billing redesign. If duplicate charges or broken exports cause real damage, billing or data flow may need to go first.
A short planning list keeps the work honest:
- Name each slice in order
- Set one clear success metric for each cutover
- Define a rollback trigger and who can call it
- Note which teams need advance notice
- Leave room for product work between slices
That last point matters. A staged rebuild should not freeze the roadmap for three months. Small teams usually do better when they ship one slice, watch it in production, fix the rough edges, and then move to the next.
If the team feels unsure about slice order, rollback rules, infrastructure tradeoffs, or how to separate old and new systems safely, an outside review can save weeks of rework. Oleg Sotnikov at oleg.is works with startups and small businesses as a fractional CTO and advisor, helping teams plan migrations like this without stopping product work.
The plan does not need to look impressive. It needs to be clear enough that everyone knows what changes next Monday, what could break, and what you will do if it does.
Frequently Asked Questions
Do we really need a full rewrite to fix a messy prototype?
No. Keep the screens and steps users already know if they work well enough. Rebuild the parts that break often, slow the team down, or create money and access risk.
What should we map before we touch the code?
Start with behavior, not code. Trace a few everyday actions like sign in, checkout, and data updates from the UI to the last database write so you can see where systems actually connect.
How do we choose what to rebuild first?
Pick the area that causes the most pain right now. Support tickets, manual fixes, duplicate charges, broken roles, or bad report data usually point to the best first slice.
How can we swap auth without locking users out?
Keep the old login path alive for a while and let current sessions keep working. Map old user IDs to new identity records, test password resets and invites, and keep a fast switch that sends new sign-ins back to the old system if errors jump.
What is the safest way to change billing?
Move new purchases first and leave existing subscriptions where they are until the new flow proves itself. Compare totals every day, give support one place to check payment history, and avoid a mass billing migration.
How do we move data flows without breaking reports?
Treat reporting as its own migration. Copy data into the new flow, compare counts and money totals every day, and switch reports one by one before you remove old writes.
Which metrics matter during each cutover?
Watch a small set of numbers that you can check the same day. Login success, password reset completion, paid orders, refund accuracy, error rate, and support tickets tell you fast if a slice works.
When should we roll back instead of pushing through?
Roll back when the new path misses the success mark you set before launch. If logins fail, invoices disappear, or totals drift, turn the slice off fast and fix it while users keep using the old path.
Can we keep shipping product changes during a staged rebuild?
Yes, if you keep each cut small. Teams usually do better when they ship one slice, watch it in production, fix rough edges, and then return to normal product work before the next move.
When does it make sense to ask a fractional CTO for help?
Bring in outside help when the team cannot agree on slice order, boundaries, rollback rules, or infrastructure tradeoffs. A short review from an experienced CTO can cut weeks of rework and help you protect users while you change the core.


