Reduce infrastructure costs with better system choices
Learn why chasing cheap servers rarely works, and how clear boundaries, fewer services, and sane defaults reduce infrastructure costs for real.
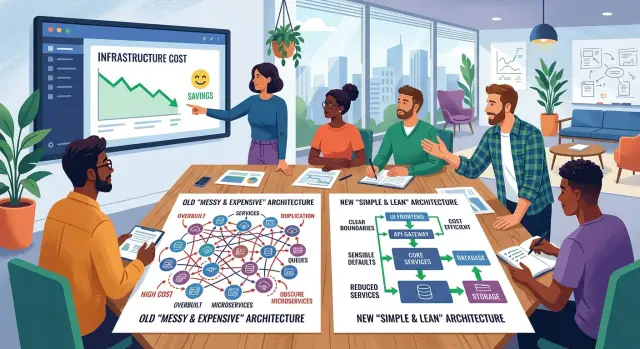
Table of Contents
Why low prices still turn into high bills
A low monthly price can fool you fast. The server looks cheap, the database has a free tier, and the first invoice feels harmless. Then storage grows, traffic spikes, backups pile up, and someone needs paid support because nobody on the team knows how to fix the mess at 2 a.m.
This is why small teams often miss the real bill. They compare sticker prices, not operating costs. A service that starts at $15 can end up costing far more once you add logs, snapshots, monitoring, extra regions, and the time people spend keeping it alive.
Tool count matters too. Every new service adds setup, access rules, alerts, updates, and another place where something can break. One database, one queue, one hosting layer, and one monitoring setup is often enough for an early product. Five separate services may look modern, but they also create five places to debug, patch, and pay for.
Bad boundaries make this worse. A simple product with a few screens and a modest user base does not need to act like a giant company. Yet many teams split it into microservices, separate admin systems, extra caches, and complex pipelines long before they need them. Now a small app behaves like a large one, with all the cost and none of the benefit.
Short-term discounts rarely help. A startup might save 40% for three months with credits or promotional pricing, but that does not fix waste built into the design. If the system moves too much data between services, stores the same records in three places, or depends on tools nobody fully uses, the bill climbs as soon as the discount ends.
If you want to reduce infrastructure costs, start with structure, not coupons. Simpler boundaries, fewer moving parts, and sensible defaults usually save more money than chasing the lowest advertised price. That is less exciting than a cloud deal, but it is what keeps a small product cheap when it starts to grow.
Where the money goes first
Most teams do not blow the budget on one giant mistake. They leak money in five boring places, then wonder why the monthly bill keeps climbing. The painful part is that each item looks reasonable on its own.
A common leak is duplicate data stores. One team keeps Postgres for the app, adds a second database for analytics, then spins up Redis because "we might need caching." Soon they pay for three systems, backups for all three, and extra engineer time to keep them in sync. If nobody can explain why each one exists in one sentence, one of them probably should go.
Another leak starts when a small product gets cut into too many services. A login service, billing service, notification service, and admin service may sound clean on a diagram. In practice, each service adds deploy steps, logs, alerts, secrets, network rules, and failure points. For an early product, one well-structured app is often cheaper and easier to run than six small ones.
Managed tools can also cost more than expected. Teams buy hosted search, queues, observability, feature flags, and workflow tools, but leave most settings at defaults. They keep too much data, run oversized plans, or pay twice for features they already have elsewhere. Paying for a tool is one cost. Paying for a tool nobody tunes is worse.
Old storage is another quiet bill. Unused volumes, forgotten snapshots, long log retention, and artifact buckets rarely break production, so nobody notices them. They just keep charging every month.
Full staging environments cause the same problem. Many teams run a complete copy of production all day and all night, even when nobody tests there. If staging gets used twice a week, schedule it to sleep, shrink it, or replace part of it with preview builds.
A simple check usually finds the first savings fast:
- List every database and ask who uses it every day.
- Count how many deployable services you run for one product.
- Open each paid tool and check storage, retention, and plan size.
- Delete unattached volumes, stale snapshots, and old logs.
- Measure staging use for two weeks before renewing anything.
Teams that want to reduce infrastructure costs often start with discounts and reserved instances. Those help, but design choices matter more. This is often the first pass a fractional CTO makes, because it cuts spend without slowing the team.
Draw boundaries before you add tools
Most teams split systems too early. They create an API service, a worker service, an auth service, a cron service, and a separate database for each one before real traffic shows up. The diagram looks neat, but the bill grows fast.
A single app and one database are often enough at the start. If one web app can handle signups, billing, admin tasks, and basic reporting, keep it together. You pay for fewer servers, fewer alerts, fewer backups, and less time spent figuring out which service broke.
Split parts only when they change for different reasons. If your customer dashboard changes every week but your billing logic changes twice a year, that can justify a boundary later. If everything ships together, depends on the same data, and has the same owner, forcing a split usually adds cost without solving a real problem.
Background jobs are a common example. Many teams move emails, imports, and report generation into a separate worker on day one. That makes sense only when those jobs slow down the main app or need different scaling. Until then, a simple job runner inside the main app can be the cheaper and calmer choice.
Write down why each service exists before you create it. Keep the note short:
- What does this service do that the main app should not do?
- What load or risk justifies the split?
- Who owns it day to day?
- What data does it need?
- What breaks if it goes down?
That small habit can reduce infrastructure costs more than another round of cloud discounts. A service with no clear reason usually turns into extra hosting, extra monitoring, and extra engineering time.
Oleg has shown this in practice with lean AI-first operations: simpler boundaries often cut more spend than aggressive coupon hunting. A startup with one product, one team, and one release flow rarely needs five separate runtime environments. Start simple. Split later, when the workload gives you a clear and boring reason.
Pick fewer services on purpose
Most cloud waste starts with one small decision: adding another service because it feels faster than fixing what you already have.
A new vendor can look cheap on paper. The monthly price might be low, or even free for a while. But the real cost shows up later in setup, alerts, logins, billing, renewals, access control, and the time your team spends learning one more dashboard.
To reduce infrastructure costs, pick one service that does the job well enough and stay with it until there is a clear reason to change. "Best in class" is often a trap for small teams. Five excellent services can cost more in attention than one decent service costs in money.
A simple rule helps: if a new service solves a small problem but creates a new system to manage, pause before you buy it.
Count the full cost, not just the subscription:
- setup and migration time
- on-call and support time
- training for the team
- failure points during incidents
- outside help you may need later
That last point matters more than people expect. If your team cannot run it, debug it, and replace it without calling a specialist, the service is probably too fancy for your current stage.
A common example is monitoring. If your team already has one setup for logs, metrics, and error tracking, adding separate niche services for each gap can make incidents slower, not faster. One person checks one dashboard, another checks a second tool, and nobody sees the whole picture. A smaller stack is easier to trust.
This is one reason experienced technical leaders often keep the stack boring on purpose. Oleg Sotnikov has shown this in practice by running production systems with a lean setup around tools like GitLab CI, Sentry, Grafana, and Prometheus instead of piling on overlapping services. The point is not to avoid all paid products. The point is to avoid paying twice for the same job.
If two tools are close, pick the one your team already knows. Familiar tools usually save more money than clever ones.
Set sane defaults from day one
To reduce infrastructure costs, defaults matter more than discounts. Teams overspend when every new server starts too large, every log stays forever, and every test environment runs long after people stop using it.
Start small and raise limits after real traffic proves you need more. A tiny app rarely needs large instances on day one. If CPU stays low and memory has headroom for two weeks, keep the smaller size. Many teams do the opposite. They buy comfort first, then forget to scale back.
Retention settings quietly grow into a monthly leak. Logs, metrics, backups, build artifacts, and database snapshots all look cheap in isolation. Together, they turn into a real bill. Keep log retention short unless legal or customer rules say otherwise. Do the same for backups. You do not need six months of test data if nobody ever reads it.
Idle environments are another common drain. Preview builds and test servers feel harmless, but they burn money every hour they sit unused. Put them on a schedule. Shut them down at night, on weekends, or after a fixed period with no activity. One small team can save a noticeable amount each month with that single rule.
Deployment paths matter too. If you use one pipeline for production, use the same path for staging and previews when you can. A second deployment system often means extra servers, extra storage, and extra mistakes. One clear CI/CD path is easier to maintain and cheaper to run.
Spend alerts should not hide inside a billing dashboard that only one person checks. Put them where the team already looks every day, such as chat or email. Set a few simple thresholds and make someone own them. When a cost spike shows up in the same hour, teams fix it fast. When they see it at the end of the month, the money is already gone.
Review your stack in a simple order
To reduce infrastructure costs, start with a plain inventory. Open your billing dashboard, your password manager, and your cloud account. Then write down every paid service and the one job it handles.
That last part matters. If a tool does "monitoring, logs, alerts, dashboards, and incident chat," the description is too loose. Split it into one clear job. Once you do that, overlap gets obvious fast.
A simple review usually works best in this order:
- List every service, subscription, and cloud product you pay for.
- Write one sentence for each: what breaks if you turn it off?
- Mark tools that do the same job, even partly.
- Compare compute, storage, and database size with real usage from the last 30 to 90 days.
- Remove or downgrade one cost at a time, then watch errors, latency, and team friction for a week or two.
Most teams find duplicates first. They pay for one tool for logs, another for metrics, and a third because one engineer liked its dashboard. Or they keep both managed CI and self-hosted runners long after the migration finished. The bill looks normal until you group services by job instead of vendor.
The next win is sizing. Many teams choose instance sizes and database tiers during a busy week, then never revisit them. Six months later, the traffic is flat but the machines are still oversized. Storage drifts the same way. Old snapshots, unused volumes, and long log retention can quietly cost more than the app itself.
Change only one thing at a time. If you cut three services in one afternoon and the system gets noisy, you will not know which cut caused it. Slow changes save time because they make cause and effect clear.
Include engineer time in the review. A cheaper service is not cheaper if it adds five hours a week of manual fixes, awkward deploys, or confusing alerts. I have seen teams save $200 on hosting and lose far more in developer hours.
A lean stack is easier to run, easier to debug, and easier to trust. If one service has a clear job and earns its place, keep it. If nobody can explain why it is there, start there.
A small product team example
A small SaaS team launched with more services than it needed. The product had separate app servers, a cache, a queue, a search service, and two databases. Each choice sounded sensible on its own, but traffic stayed modest and the engineering team stayed small.
The cloud bill did not explode on day one. The work did. Every deploy crossed too many parts. When something slowed down, the team had to check logs, workers, database load, cache misses, search health, and alert noise before they found the real issue.
Their stack looked like this:
- app service for the main product
- Redis cache
- queue workers for background tasks
- separate search service
- PostgreSQL plus a second database for reporting
Most of those services sat mostly idle, but they still cost money every hour. They also created small taxes everywhere else: more backups, more dashboards, more secrets to manage, and more places for a release to fail.
After a review, the team simplified hard. They kept one app service and one PostgreSQL database. They replaced the queue with scheduled background jobs that ran every few minutes. For search, they used database search because the product only needed basic filtering and text matching.
The monthly bill dropped because the system got simpler, not because the team found a better discount. They cut out duplicate storage, extra monitoring, and idle compute. A setup that had cost around $1,800 a month fell closer to $900.
The time savings mattered just as much. Deploys stopped breaking in strange ways. Alerts got quieter. One engineer no longer spent part of every week checking worker health and tracing issues across several services.
This is how teams reduce infrastructure costs in real life. They draw better boundaries, keep fewer moving parts, and pick sane defaults early. Sometimes a fractional CTO spots that faster than the team can, because they are not attached to the original setup.
Mistakes that keep the bill growing
Teams trying to reduce infrastructure costs rarely fail because compute is too expensive. They fail because they keep adding weight to a product that is still small.
One of the most common mistakes is copying a big company design too early. A young product with modest traffic does not need the same split of services, queues, caches, search layers, and deployment rules as a company serving millions of users. Every extra service adds a monthly bill, setup work, alerts, and more things to break. Cheap services stop looking cheap when engineers spend hours babysitting them.
Another quiet leak is leaving every environment online all the time. Staging, preview apps, test systems, and demo setups often run day and night even when nobody touches them after work. One extra server looks harmless. Six of them do not. Schedules, auto-sleep, and short-lived environments often cut waste faster than hunting for a cheaper host.
Teams also love to prepare for scale they do not have yet. They add Redis, a queue, and a search engine before they measure where the app is slow. Then they learn the real problem was a bad database query, oversized images, or too many API calls between services. Simpler software architecture usually wins until the numbers prove otherwise.
Observability is another place where small waste turns into a serious bill. Logs, traces, metrics, and error events grow with traffic, retries, and noisy code. If nobody sets retention limits, sampling rules, and sane dashboards, monitoring can cost more than the app it watches. Oleg Sotnikov has run Sentry at more than 25 million events a day, which makes the point clearly: monitoring needs limits and discipline, not endless collection.
The last mistake is chasing a lower hosting price while ignoring engineer time. Saving $80 a month on infrastructure is not a win if the team burns five extra hours dealing with awkward deploys, poor tooling, or fragile servers. A fractional CTO usually sees this fast because the full bill includes payroll, not just cloud invoices.
The pattern is simple. Most growing bills come from premature complexity, always-on environments, unbounded monitoring, and false savings. If a cheaper server creates more work every week, it was never the cheaper option.
A quick cost check for this week
You can spot waste in 20 minutes if you put last month's bill next to the list of services your team runs. Don't start with discounts. Start with overlap, idle systems, and data nobody uses. This kind of review does more to reduce infrastructure costs than another round of coupon hunting.
First, look for services that do the same job. Many teams add one tool for app hosting, another for background jobs, and a third for scheduled tasks, even though the main host can run all three. If one service can take over without making operations messy, remove the extra bill.
Then check for systems that stay on while almost nobody touches them. A reporting database, a staging copy, or a test environment often runs day and night even when the team uses it for a few hours a week. If staging runs only during office hours, a timer can cut runtime by about 70%.
Use this short check:
- Mark every service that overlaps with another paid service.
- Circle databases with low traffic most days.
- Flag log storage you never search after the first day.
- List test systems that can shut down at night or on weekends.
- Ask which service you would remove first if next month's bill doubled.
That last question is useful because it forces honesty. If a tool would be the first thing you cut in a budget shock, you probably do not need it now.
Logs deserve extra attention. Teams often keep full debug logs, long retention, and multiple copies across tools. That gets expensive fast. Keep the logs you actually use to fix production issues. Lower retention for noisy logs and stop collecting data nobody reads.
A simple rule helps: if a service is idle, duplicated, or ignored, it needs a reason to stay. If nobody can give that reason in one sentence, put it on the removal list this week.
What to do next
Most teams do not need a grand cost program. They need one clean decision. Pick the part of your stack that creates the most waste each month, even if the number looks small on its own.
That could be two services doing the same job, a CI pipeline that runs on every tiny change, or a database tier sized for traffic you do not have. One change like that often does more to reduce infrastructure costs than another round of discount hunting.
Before you change anything, write down three things on one page. Name the current monthly cost. Estimate the new monthly cost. Then write the risk in plain language, such as slower deploys, weaker rollback options, or less room for traffic spikes. If you cannot explain the risk simply, you probably do not understand the change yet.
A short monthly review is enough for most small teams:
- Pick one area only: hosting, CI/CD, observability, background jobs, or third-party SaaS.
- Write the current cost and the expected saving.
- Choose one safety metric, such as uptime, error rate, or deploy time.
- Check the result after 30 days.
This keeps the work honest. It also stops the usual mistake of changing five things at once and learning nothing from the result.
When the tradeoffs feel unclear, ask an experienced fractional CTO for a short review. A good outside view can tell you where complexity is helping and where it is just expensive habit. You do not need a long engagement for that. Sometimes one careful review saves months of slow drift.
Oleg Sotnikov helps startups cut spend through clearer architecture, lean infrastructure, and simpler delivery choices. He has done this in real production systems, including running global software with a very small AI-augmented team and tight infrastructure discipline. If your bill keeps growing but the reason is still fuzzy, a short review is often the fastest next step.


