Redis locks after crashes: short leases and safe retries
Redis locks need careful design after crashes. Learn why short leases, owner tokens, and idempotent handlers prevent double work.
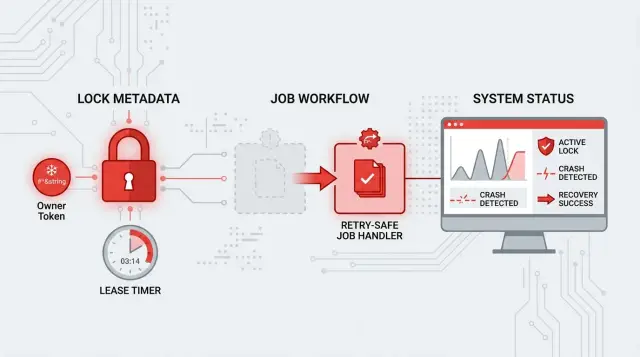
Table of Contents
Why a lock does not make the job safe
A Redis lock only answers one narrow question: who may start right now. It does not prove the worker will finish, release the lock cleanly, or leave the system in a correct state if it dies halfway through.
That gap creates a false sense of safety. People add Redis locks, see that two workers stop entering the same code at the same moment, and assume the job is now protected. It is not. The lock reduces overlap. It does not make the work itself correct.
A crash is enough to show the problem. Say a worker gets a lock, sends a charge request to a payment service, and then the process stops before it records "done" in the database. A few seconds later, the lease expires and another worker picks up the same job. The second worker may send the same charge again. The first worker crashed, but some of its work still escaped into the world.
The same thing happens with email sends, webhook delivery, invoice creation, inventory updates, and background sync jobs. Once a side effect happens, the lock cannot pull it back. If another worker retries the job, you can still get double work, duplicate messages, or conflicting state.
That is why locking and correctness are two different jobs. The lock helps coordinate access for a short window. Correctness comes from how you design the handler: can it retry safely, can it detect that work already happened, and can it avoid releasing or extending a lock it no longer owns.
Treat the lock as a small coordination tool, not as proof that the job is safe. The practical fix is simple: keep leases short, give each worker its own owner token, and make the handler idempotent so a retry does not create a second mess.
What breaks when a process crashes
A job can start cleanly and still leave a mess. One worker grabs a Redis lock, starts the task, and then the process dies before it releases the lock or saves what it finished. The lock helped for a moment, but the job is now in limbo.
Crashes almost never happen at a neat boundary. A worker might stop after it charged a customer but before it marked the order as paid. It might write half the rows for a report and never write the rest. If you only look at the lock, you cannot tell whether the job never started, finished fully, or stopped halfway through.
Once the lease ends, another worker can see the same task and pick it up again. That is where the real trouble starts:
- It repeats an action that already happened.
- It creates duplicate records.
- It overwrites partial work with stale data.
- It skips a step because it assumes the first worker already did it.
This is the weak spot in Redis locks. They reduce overlap while the lease is alive, but they do not prove that the work is safe. They do not preserve progress, clean up side effects, or tell the next worker what the dead process already changed.
A small example makes this plain. Say a worker creates a new customer account, sends a welcome email, and opens a billing profile. If the process dies right after the email, the next worker may send the same email again. If it dies after the billing profile is created but before the result is stored, the next worker may create a second billing profile. The lock did not stop either problem.
Sometimes the job fails in the opposite way. The second worker never picks it up because the lock lease is too long, so the task just sits there waiting. You do not get double work. You get stuck work.
That is why crash handling starts with a blunt assumption: a worker can die at any line of code. When you design for that, you stop treating the lock as a safety guarantee. You treat it as a short claim on who may try the job right now.
Use short leases instead of long lock times
A long lock feels safe, but it usually makes a crash more painful. If a worker grabs a 30 minute lock and dies after 2 seconds, the job sits there for 29 minutes and 58 seconds while nobody does useful work.
A short lease works better because it assumes failure will happen. The lock expires on its own, the stuck job becomes available again, and another worker can pick it up without human cleanup.
Start with an expiration that matches real job time, not wishful thinking. Measure how long the work usually takes, then add a small buffer. If a job finishes in about 8 seconds, a 15 second lease is sensible. If it often takes 40 to 50 seconds, try 90 seconds, not 10 minutes.
You do not need one perfect number forever. Different jobs can use different lease lengths. Fast email sends, cache rebuilds, and large imports do not belong under the same timeout.
A simple rule helps:
- Set the first lease close to normal runtime
- Leave enough margin for brief slowdowns
- Renew before the lease gets close to zero
- Stop renewing as soon as the worker is unhealthy
That last part matters more than people expect. Renewal should happen only while the worker is alive, still owns the lock, and can still do the job. If the process is half-dead, stuck, or shutting down, it should stop extending the lease and let the lock expire.
Keep the renewal loop boring and strict. Renew on a fixed interval, such as every 3 to 5 seconds for a 15 second lease. Check the owner token before each renewal. If Redis is unavailable or the worker misses a renewal window, let the lease lapse. Do not try to protect a broken worker with a longer timeout.
Short leases also reduce the blast radius of bad guesses. Teams often set long lock times because one rare job once took much longer than expected. That trades an occasional retry for long periods of blocked work. In most systems, a fast retry is the better failure mode.
This is the practical mindset behind Redis locks that survive crashes. The lock is temporary, the work can retry, and expired leases free stuck jobs quickly. That keeps the queue moving even when a worker disappears at the worst time.
Give each lock holder its own owner token
A lock name alone is not enough. Every worker that gets the lock should create its own random token and store that token as the lock value.
That small step stops a common failure after a crash or long pause. Worker A gets the lock and stores token abc123. Its lease expires. Worker B gets the same lock later and stores xyz789. If worker A wakes up and runs a plain delete, it can remove worker B's lock by mistake.
With Redis locks, the safe rule is simple: a worker can renew or release a lock only if the value still matches its own token.
Why the token matters
The token is proof of ownership. The lock name tells you which job is protected. The token tells you who owns it right now.
Use a fresh random token every time a worker acquires the lock. Do not reuse a process ID, hostname, or job name. Those are easy to guess and easy to repeat after restarts.
A safe flow looks like this:
- The worker generates a random token.
- It writes the lock with that token and a short lease.
- Before it renews or deletes the lock, it checks that Redis still holds the same token.
That last check must happen atomically. If you split it into separate read and delete calls, another worker can slip in between them. A short Lua script solves that cleanly: compare the stored value to the worker's token, then renew or delete only on match.
This protects you from a nasty edge case. A stalled worker may think it still owns the lock because it never noticed the lease expired. The token check forces it to stop. It cannot touch a newer lock that belongs to another worker.
If you build AI jobs, queues, or background tasks for a small team, this rule saves real trouble. Oleg often pushes teams toward lean systems that survive restarts and retries. Owner tokens fit that style: tiny change, fewer double runs, much less confusion when something crashes.
Make the handler safe to run twice
Retries happen. A worker can crash after it starts the job but before it records success. The lease can expire, another worker can pick up the same task, and the job runs again. Redis locks reduce overlap, but they do not make duplicate work impossible.
Give every task a stable task ID and store it before any outside action starts. That ID should stay the same across retries. When the handler starts, it looks up that ID in durable storage. If it finds a finished record, it skips the work and returns the saved result. If it finds a partial record, it can decide whether to resume, wait, or stop.
This matters most when the task touches another system. Imagine a job that charges a customer and then writes "paid" to your database. If the process crashes after the charge succeeds but before the database update, a retry may charge the customer again. The fix is simple: save the task ID first, send that same ID with the external request when the API supports deduplication, and store the external reference you get back.
A small record is usually enough:
- task ID
- current state
- external reference ID
- final result or final error
Keep the states boring and easy to check. "pending", "sent", and "done" work better than a long list nobody trusts. On retry, the handler reads the record and acts on facts instead of guesses.
Record the result in a form you can verify later. Store the payment ID, email message ID, created order ID, or whatever proves the side effect already happened. Then the next run can ask one clear question: did this exact task already finish?
If you can answer that with one lookup, short leases and safe retries stop feeling risky.
A simple setup you can follow
Start with a task record, not the lock itself. In Redis locks, the lock only tells you who can work right now. The task record tells you whether the work already finished, who tried it last, and whether a retry should do anything at all.
Give every job a stable task id. Build it from the business action, not from the worker process. For example, use something like invoice-4821-send or user-991-sync. If the same job gets queued twice, both workers still talk about the same task.
A practical flow looks like this:
- Create the task id and a random owner token for this worker.
- Try to claim the lock with a short lease, such as 10 to 15 seconds.
- If Redis says no, stop and retry later. Do not sit there waiting.
- After you claim it, do one small unit of work and save progress.
- If the work may run longer than the lease, renew the lease only if the owner token still matches yours.
The small unit of work matters more than people think. Do not process a whole batch under one lease if you can process one item, save that result, and move to the next. Smaller steps make crashes less painful. They also make safe retries much easier.
The owner token is what keeps one worker from deleting another worker's lock. Store the token as the lock value. When you renew or release, first check that the token in Redis still matches your token. If it does not, your lease expired and someone else owns the lock now. Stop working.
Before you release the lock, write a done record for the task id. That record can be simple: status done, finished_at, and maybe a result id. This is the part that prevents double work after a crash. If a worker finishes the job but dies before cleanup, the lease will expire, another worker will pick up the task, see the done record, and exit.
A simple rule keeps the whole setup sane: the lock controls who works now, and the done record controls whether work is still needed. Keep leases short, renew only while you still own them, and make each handler safe to run twice. That is the setup that survives real process crashes.
A realistic example
Imagine a billing worker that sends monthly invoices on the first day of the month. It uses Redis locks so only one worker handles a customer and billing period at a time. The lock helps with coordination, but it does not prove the work finished.
Say the worker gets a 30-second lease, sends the invoice, writes a durable "done" record for that customer and month, and then plans to acknowledge the job. That last step matters less than people think. If the process dies after the invoice goes out, the lease will expire anyway.
A normal failure looks like this:
- Worker A gets the lock for customer 1842 and month 2026-04.
- It creates the invoice and sends it to the mail or billing service.
- It stores a done record in the database, such as
(customer_id, month), and then crashes before it can mark the queue job complete. - The Redis lock expires, Worker B picks up the retry, checks the done record first, and exits without sending another invoice.
That done record is the part that keeps money and trust intact. Without it, Worker B only knows the lease ended. It cannot know whether Worker A finished the send or died halfway through. A second invoice can go out, and now support has a mess to clean up.
This is why short leases work well when the handler is idempotent. You let the lock expire fast if a process crashes, so another worker can retry soon. Then you make the retry safe by checking a durable record before doing the external action again.
If you want one simple rule for Redis locks, use this: the lock decides who may try the work right now, and the done record decides whether the work already happened. Keep those two ideas separate, and crash recovery gets much simpler.
Mistakes that lead to double work
Most double work starts with one bad assumption: "If I took the lock, the job is safe." A lock only limits who starts at the same moment. It does not tell you whether a crashed worker already sent the email, charged the card, or wrote half the record.
One common mistake is using one long lease for every job. Teams pick 10 or 30 minutes "just to be safe," then a dead worker blocks retries for far too long. A short lease with renewal gives you a much smaller failure window and lets another worker retry sooner.
Another mistake is releasing a lock by name alone. If worker A loses its lease, and worker B gets the same lock, worker A must not delete it on the way out. That old worker needs to check its owner token first. If the token does not match, it should leave the lock alone.
Lock expiry also fools people. An expired lock does not prove that no work happened. A worker can finish the outside effect, crash before it stores progress, and leave the next worker to repeat the same action. That is how customers get charged twice or receive the same message again.
Order matters more than many teams expect. If your code calls an outside API before it writes retry state, a crash erases the only clue that the call already happened. Write enough state first to recognize the retry, then make the call, then save the result. If the API supports an idempotency key, use it every time.
Redis locks also do not fix every race in the system. They do not protect your database row, queue message, and third-party API unless each step can survive a repeat. The lock helps reduce overlap, but the handler still needs to behave well when a retry shows up.
A safer setup is usually simple:
- Keep leases short and renew them while the worker is alive.
- Store a unique owner token with each lock.
- Save retry state before outside calls.
- Make every handler safe to run twice.
- Expect crashes and retries, then design for them.
A small example makes this clear. A worker sends an invoice email and plans to mark it as sent afterward. It crashes after the email call but before the database write. The retry sees an expired lock and sends the invoice again. If the worker writes a send-attempt record first and reuses the same idempotency key on retry, the second run does no harm.
A short checklist before you ship
If a worker dies in the middle of a job, the system should recover without guesswork. The lock should disappear soon, another worker should retry, and the job should still end with one correct result.
Before you trust Redis locks in production, check these five points:
- Keep the lease short. If a worker crashes, the lock should expire in seconds, not sit there for minutes. Healthy workers can renew the lease as they go.
- Tie the lock to an owner token. Each worker gets a unique random token, and Redis only accepts renew or release calls from the worker that holds that exact token.
- Give every task a stable ID. Use the same ID on every retry, such as an order ID, invoice ID, or email job ID, so the system knows it is the same work.
- Make the handler safe to run twice. A retry should check what already happened and skip duplicate actions instead of charging twice, sending two emails, or writing conflicting rows.
- Record enough state to tell done from half-done. "Started" is not the same as "finished." Save a clear final result, and save progress in a way the next worker can read.
A payment job is a good test. Kill the worker after it charges the card but before it stores success. On retry, the new worker should use the same task ID, see that the charge already exists, and finish the bookkeeping instead of charging again.
That is the standard to aim for. If one item on this list is missing, the lock may reduce overlap, but it does not make the work safe.
Next steps
Pick one background job that hurts the most when it runs twice or gets stuck. Good candidates are payment capture, invoice creation, stock updates, email sends, or account provisioning. Start there. Fixing one job end to end teaches more than adding Redis locks everywhere and hoping they hold.
A practical first move is small: keep the lock, but stop treating it like a safety guarantee. Give each lock holder its own owner token, and store a separate done record for the job. That way, the worker can prove "this is my lock" before it extends or releases it, and the system can prove "this work already finished" before it runs the handler again.
After that, shorten lease times. Long leases feel safer, but they usually hide stuck workers and slow recovery after a crash. A short lease with renewals is easier to reason about. If the process dies, another worker can pick up the job soon instead of waiting through a long timeout.
Then test the ugly cases on purpose:
- kill the worker in the middle of the handler
- pause it so the lease expires
- start two workers on the same job
- retry the same message after the first run succeeds
- check that the second run exits cleanly without doing the work again
If that test fails, the lock is not your main problem. The handler still needs to be idempotent, and the job flow still needs a clear record of completion.
This review usually finds weak spots fast. One missing owner token or one handler that writes twice can create days of cleanup later. If you want another set of eyes on the design, Oleg Sotnikov can review the architecture, the retry path, and the crash cases before they show up in production.


