Redis coordination layer: where it fits and fails
Learn when to use Redis coordination layer for locks, queues, and short-lived state, and when to keep business data in PostgreSQL or another durable store.
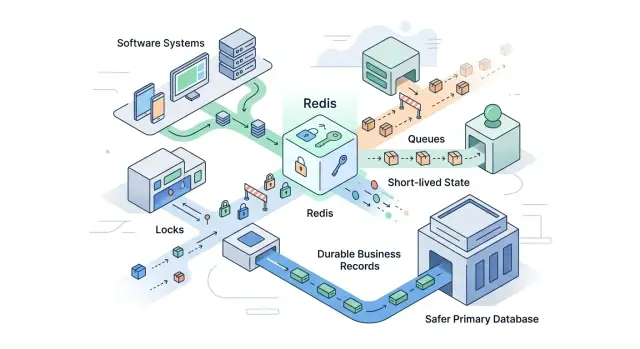
Table of Contents
Why this choice matters
Redis is a very fast place to keep small pieces of shared state. It helps different parts of an app stay in sync for a short time. One worker can claim a job, another can check a lock, and a web server can store a session without waiting on a slower system.
That speed is also why teams start putting too much in Redis. When it answers in milliseconds, it feels easy to move everything there: carts, order state, retry counters, rate limits, workflow steps, even records the business may need months later. The app feels quick, and the setup looks simple at first.
Problems start when temporary state and business facts get mixed together. A lock is temporary. A queue item is usually temporary. A user balance, signed agreement, invoice, or order history is not. Those records need stronger guarantees around persistence, recovery, backups, and audit history.
If you treat Redis as your source of truth, you can lose data the business cannot cleanly recreate. A restart, the wrong eviction policy, memory pressure, an operator mistake, or a partial failure can turn "fast" into "where did that record go?" That stops being a technical issue pretty quickly. It becomes a billing dispute, a support problem, or a compliance mess.
The distinction is simple. If Redis stores "worker 12 owns job 884 for 30 seconds," that is a good fit. If Redis stores "customer paid invoice 884," that is not. The first fact expires by design. The second may matter years later.
That is why Redis works best as a coordination layer. Use it for locks, job queues, rate limits, session data, and other short-lived state. Keep durable data in a database built for records you must keep, query, back up, and trust after a bad day.
It sounds boring. It also prevents painful cleanup later.
What Redis does well
Redis helps when several app processes need the same short-term answer, and they need it fast. It works well as shared memory for data that changes often, expires soon, or can be rebuilt without much trouble.
That makes it a good coordination layer. One worker can claim a task, another can see that claim right away, and a third can back off instead of doing the same work twice.
Short-lived locks are a strong example. If two workers try to send the same payout or run the same import, Redis can hold a lock for a few seconds or minutes with a clear expiry. If a worker crashes, the lock times out and another worker can continue.
Queues also fit naturally. Redis handles job queues well when work moves through simple states like waiting, running, retry, and done. For background jobs such as sending emails, resizing images, or syncing a CRM update, speed matters more than long-term storage.
It is also useful for temporary state such as:
- counters that reset every minute for rate limits
- sessions for signed-in users
- short cache entries that avoid repeated work
- shared flags that tell workers a job is already in progress
- small retry and backoff markers
This kind of data changes all the time. You want quick reads, quick writes, and easy expiry. Redis gives you that with very little overhead.
Take an AI document pipeline with five workers. One uploads a file, another extracts text, and another stores the result. Redis can track which file is in progress, which retry count is at 2, and which worker holds the lock for the next step. That lets workers share fast state without every step hitting the main database.
If the data can expire, be recomputed, or be retried, Redis is usually a good fit.
What should not live in Redis
Redis can hold work in flight, but it should not be the only place that records money, ownership, or history. If losing the data during a restart would hurt the business, keep it in a durable database.
Orders and payments sit at the top of that list. When a customer pays, your system needs a record you can trust later for refunds, support, tax, and disputes. Redis can tell a worker what to process next. It should not be the only place that says whether order 4812 exists, whether the charge succeeded, or when the refund happened.
User balances also need a safer home. If a customer has store credit, prepaid usage, reward points, or wallet funds, you need a clear source of truth. Redis is fine for caching the current number for a few seconds. It is a bad place to keep the only copy.
Audit history belongs outside Redis for the same reason. When finance, support, or a customer asks, "Who changed this, and when?" you need an answer that does not depend on memory settings or key expiration. Good audit records show sequence and ownership. They belong in durable storage, often with append-only logs or immutable history tables.
A practical rule works well here:
- Keep locks, rate limits, short-lived queues, and session-like state in Redis.
- Keep orders, payments, balances, contracts, and audit trails in durable storage.
- Cache copies in Redis if speed helps, but rebuild them from the durable source.
- Treat Redis data as replaceable unless you can explain exactly how it survives mistakes.
Picture a checkout flow. Redis can hold "send receipt," "reserve stock for 10 minutes," and "retry failed webhook." Your main database should still hold the order, payment status, line items, and every balance change. If you may need to explain a number to a customer six months later, that fact does not belong in Redis.
A split that works
Put durable business facts in PostgreSQL or another primary store that gives you transactions, backups, and a clear recovery path. Customer accounts, orders, invoices, subscription status, and audit history belong there. When someone asks, "What is true right now?" your team should check one source of truth.
Redis works best beside that store, not in place of it. Use it to coordinate work around durable data. Good fits include short locks, job queues, rate limits, deduplication tokens, and temporary states such as "processing" or "retry in 30 seconds." If Redis loses that data, the system should slow down or retry. It should not lose the business record itself.
A simple rule keeps the boundary clear: if the business needs the data tomorrow, keep it in PostgreSQL. If the app needs the data for a few seconds or minutes to control concurrent work, keep it in Redis with a TTL.
The write order matters more than most tuning work:
- Write the durable fact to PostgreSQL first.
- Commit that change.
- Put follow-up work in Redis, such as a queue message or short-lived lock.
- Make workers read the current record from PostgreSQL before they act.
- Let Redis entries expire or clear them when the work ends.
A payment flow shows why this works. When a customer pays, your app saves the payment and order status in PostgreSQL first. After that commit succeeds, the app pushes a fulfillment job into Redis. A worker picks up the job, reads the order from PostgreSQL, sends the receipt, and marks the work done. If Redis restarts in the middle, you may need to requeue the job, but the payment record and order state are still intact.
That is the real job split. Redis helps the app move in the right order and avoid collisions. PostgreSQL keeps the facts safe.
How to set it up step by step
Start with a write inventory, not with Redis commands. Open the code that handles signups, checkouts, emails, background jobs, and rate limits. Write down every value the app stores: order records, retry counters, email tokens, lock flags, queue items, session hints, and cached progress.
For each value, ask one blunt question: if this disappears during a restart, do users lose a business fact? If the answer is yes, keep it in your primary database. Orders, invoices, account changes, and audit history belong there. If the answer is no, Redis is usually fine.
Then fix the write order before you tune anything else. Save the durable fact first in PostgreSQL or your main database, then write the Redis entry that coordinates follow-up work. In a checkout flow, create the order row first, then push an email job to a Redis queue and set a short lock to stop double processing.
Keep Redis entries small. Store IDs, short status values, timestamps, and retry counts. Skip full customer objects or large JSON blobs when an ID can point to the durable record.
Name Redis entries so any engineer can understand them fast. lock:invoice:123, queue:emails, and rate_limit:user:456 work because they are plain. Plain wins when someone is debugging a live issue at 2 a.m.
Put an expiry on almost everything temporary. Sessions, locks, duplicate request markers, and retry counters should disappear on their own. Add a small cleanup job that removes stale queue items, reports locks that outlived their TTL, and counts leftover entries with no clear owner.
Once that split is in place, Redis becomes much easier to trust. It handles timing, contention, and short-lived state. Your database keeps the records you may need tomorrow, next month, or during an audit.
A realistic example
An online store is a good test case because it mixes durable business facts with short-lived work. A customer places an order, pays, and expects updates fast. If you keep that whole flow in Redis, recovery gets much harder than it needs to be.
The safer split is straightforward. PostgreSQL keeps the order, the payment state, and the line items. Redis handles the moving parts around that order: follow-up jobs, short locks, and temporary state while workers do their work.
A typical flow looks like this:
- The app writes a new order to PostgreSQL with a status like "paid" or "awaiting_fulfillment."
- After that write succeeds, the app pushes job IDs into Redis for tasks such as sending the receipt, reserving stock, or creating a shipment.
- A worker picks up one job and takes a Redis lock for that order step, with a short TTL.
- The worker finishes the task, updates PostgreSQL if needed, and removes the lock.
That lock matters. Payment providers retry webhooks. Users click twice. Workers restart at awkward moments. Without a lock, two workers can reserve the same stock or send the same confirmation email.
This is exactly where Redis earns its keep. It helps workers agree on who does what right now. It should not decide what is true in the business.
Now imagine Redis restarts and the queue disappears. That is annoying, but it is not fatal. The order still exists in PostgreSQL. The payment state is still there too. Support can still find the order, finance can still reconcile it, and a repair job can scan for orders marked "paid" but not "fulfilled" and recreate the missing Redis jobs.
If the only copy of that order state lived in Redis, you would have a mess: no clear source of truth, no clean replay, and a lot of manual checking.
Mistakes teams make
Teams get into trouble when they treat Redis like a permanent database. Its speed can hide bad decisions for months. Then one restart, one eviction, or one bad deploy turns a shortcut into lost business data.
One common mistake is writing the only copy of an order, payment state, or signup record to Redis. That data is not temporary. If a customer buys something, you need a durable record in a relational database or another primary store.
Locks cause another class of failure. Teams add a lock, forget the timeout, and assume the job will always release it. Real systems crash. Workers get killed. Networks fail. If the lock never expires, the next job waits forever and nobody sees the problem until users complain.
Queues can fail more quietly. A job queue with no size limit looks fine in testing, then grows all weekend after one downstream service slows down. Memory climbs, latency gets worse, and Redis starts fighting for space. Put limits in place, watch queue depth, and decide what should happen when producers outrun workers.
Large blobs are another slow problem. Teams store full API responses, report files, or huge JSON payloads in Redis because it feels convenient. A few weeks later, nobody remembers who wrote them or when they should expire. Memory costs rise, failover gets heavier, and cleanup turns into detective work.
Another mistake is mixing cache keys and business records under loose naming rules. A broad delete meant for cached pages can wipe session markers or job state if everything shares a weak prefix. Keep namespaces strict and boring.
A checkout flow shows the boundary clearly:
- store the order in a durable database
- keep a short lock in Redis while one worker processes payment
- push retry jobs through a queue with limits
- expire temporary state on purpose
That setup is less clever, but it fails in smaller, easier-to-fix ways.
A quick review
A Redis review should feel a little harsh. If you unplug it for five minutes, your app should slow down, retry, or rebuild state. It should not lose orders, payments, user balances, or anything else you would need to explain to a customer later.
Check a few basics.
Restart Redis in staging and watch what breaks. Sessions may expire and workers may pause for a moment. That is acceptable. Missing invoices or broken account history is not.
Pick one business event, like "customer paid invoice 1842," and trace where it lives. If the only copy sits in Redis, move it to durable storage first.
Read every lock timeout with a stopwatch mindset. A 5 second lock on a job that often runs for 40 seconds will create duplicate work. A 30 minute lock can block recovery after a crash.
Open your queue settings and read the retry rules from the user's point of view. How many retries happen, how long do they wait, and when does a poisoned job stop coming back?
Scan your Redis keys. If nobody on the team can say who creates a key, who deletes it, and when it should expire, that key will become a bug later.
That last check catches more issues than people expect. Old feature flags, stale rate-limit counters, abandoned locks, and half-finished cache experiments pile up quietly. Months later, nobody trusts what Redis contains.
A small rule helps: every Redis key should have a reason to exist and a reason to disappear. If you cannot explain both in one sentence, the design is probably sloppy.
What to do next
Pick one flow where Redis handles short-lived coordination and your primary database keeps the business facts. Good first targets include webhook processing, checkout follow-up jobs, or email work tied to customer records. Treat Redis as a coordination layer first, not as the place where orders, payments, or account history live.
Write down ownership in plain language. Redis owns locks, retry counters, queue state, and temporary progress markers. Postgres, or your main database, owns customers, invoices, subscription status, and audit history.
That small document prevents a common mess. Teams start with a fast cache, then add one more field, then another, and a month later Redis holds facts nobody wants to lose.
After that, test failure cases before you chase speed numbers. Fast workers look good on a dashboard. Duplicate jobs, missing updates, and stale state cost more.
A short test pass usually tells you enough:
- stop a worker halfway through a job and check whether the job retries safely
- let a lock expire early and see whether two workers write the same record
- restart Redis and confirm your durable data still tells the full story
- delay the database write and make sure the queue does not mark work as done too soon
If your current setup already mixes these concerns, do not jump into a big rewrite. Map one workflow, fix one boundary, and run it under failure tests. Then move to the next one.
If you want an outside review, Oleg Sotnikov at oleg.is does this kind of Fractional CTO work with startups and small teams. A short architecture review can usually show where Redis is helping, where it is carrying too much, and what to fix first without turning it into a massive project.
Frequently Asked Questions
When is Redis a good fit?
Use Redis for short-lived shared state that helps workers and app servers stay in sync. Good fits include locks, rate limits, sessions, retry counters, deduplication tokens, and queue state that you can rebuild or retry.
Can Redis be my main database?
No. Redis is great for speed and coordination, but it is a risky place for the only copy of business data. Keep orders, payments, balances, contracts, and audit history in a durable database such as PostgreSQL.
Is it safe to store orders or payments only in Redis?
Do not keep the only copy there. A restart, memory pressure, eviction, or a bad deploy can wipe data you need for refunds, support, tax, or disputes.
What kind of data belongs in Redis?
Think of Redis as shared memory for work in flight. Store small values like IDs, short status markers, timestamps, session data, queue entries, and lock flags, then set a TTL on almost all of them.
What should stay in PostgreSQL or another durable store?
Your primary database should keep the facts you may need tomorrow or six months from now. That includes customer records, invoices, subscription status, payment history, ownership changes, and audit logs.
What is the right write order for PostgreSQL and Redis?
Write the durable record first, commit it, then push follow-up work into Redis. When a worker picks up that work, make it read the current record from the database before it acts.
What should happen if Redis restarts?
The app should slow down, retry, or rebuild missing temporary state. It should not lose the business record itself. If a queue disappears, you should be able to recreate jobs from the durable data.
Do Redis locks always need a TTL?
Yes, always. A lock without an expiry can block work forever after a crash or network problem. Pick a TTL that matches the real job time, then renew it if the job runs longer.
Should I store full JSON objects in Redis?
Usually no. Large blobs waste memory, slow failover, and turn cleanup into guesswork. Store a small ID in Redis and fetch the full record from your database when you need it.
How do I review whether my app uses Redis the right way?
Start with one workflow and trace every value it writes. Ask a blunt question for each one: if this disappears during a restart, do we lose a business fact? If the answer is yes, move it out of Redis.


