Recurring jobs in Go with clear scheduler boundaries
Recurring jobs in Go work better when the app owns business logic and the scheduler owns timing. Learn retries, idempotency, and safe job boundaries.
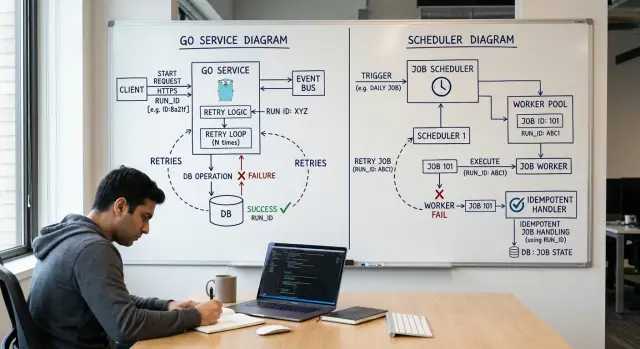
Table of Contents
What breaks when job timing lives in the app
With recurring jobs in Go, teams often start small. A shell script runs every night, one config file holds a cron rule, and the app has a little "run if it is 2:00" check. That setup works for a week or two. Then nobody can say where the real schedule lives.
One job ends up with timing rules in three places: cron, app code, and deployment config. A developer changes the cron expression but forgets the time check in Go. Another server still has the old script. The job now runs late, or twice, or not at all. The worst part is how normal this looks until something important slips.
Once the app starts deciding when work runs, it takes on a job it should not own. A web service should answer requests and do work when told. It should not guess whether "now" is the right moment, especially when you run more than one instance. A restart, a second replica, or a slow deploy can turn one scheduled run into several.
The usual warning signs show up fast:
- The same cron rule appears in code comments, scripts, and server config.
- One job behaves differently in staging and production.
- A deploy changes run timing even though nobody touched the schedule.
- People ask, "Did it fail, or did it never start?"
Retries get messy too. The outer scheduler retries because the process exited with an error. Inside the app, the handler also retries the API call. If both layers try to "help," one timeout can produce duplicate writes, repeat emails, or two invoice syncs that fight each other.
Tracing a bad run becomes its own project. Logs may show the command started, but not which attempt did the damage. The script wrapper has one timestamp, the app has another, and the third-party API has a different one. Teams lose hours answering a basic question: was this one failed run, or three partial runs?
This is a common pattern in startup teams, especially when a script slowly grows into a service. The pain is not the schedule itself. The pain comes from mixing timing, retries, and business logic in the same place.
Draw the line between app and scheduler
For recurring jobs in Go, the split is simple: the scheduler decides when a job should run, and the Go service decides what to do when that run request arrives. Mixing those two jobs sounds harmless at first, but it usually leads to handlers that know too much about time, cron text, and retry timing.
That boundary matters because schedule changes should not need a code change. If a team wants a job to run at 5:00 instead of 6:00, they should edit scheduler config and move on. They should not open handler code, touch time math, and redeploy the service.
A small contract between both sides
Keep the payload tiny. In many cases, the scheduler only needs to send the job name and the run date.
{
"job": "billing_sync",
"run_date": "2026-04-12"
}
That gives the service enough context to validate the request, load the right handler, and do the work for that date. It also makes testing much easier. A developer can send the same payload from a local script or test runner without waiting for cron.
The Go service should stay focused on a few things: check that the payload is valid, map the job name to a handler, run the business logic, and return a clear result. If the payload is bad, reject it fast. If the work fails, report that failure in a way the scheduler can understand.
Cron text does not belong in handler code. A function like RunBillingSync() should not know whether someone scheduled it with 0 5 * * *, every hour, or from a queue. It should only know that it must process one named run for one date.
This separation also gives you room to change tools later. You can move from a server cron entry to a workflow engine, a cloud scheduler, or a queue without rewriting the job logic. The service keeps the same input and the same behavior.
A good test is boring on purpose: if you can trigger the handler with a tiny payload and no clock logic, the boundary is probably right.
Make handlers safe to run again
A recurring job will run twice sooner or later. A deploy restarts it, a timeout hides a success, or the scheduler retries after a slow network call. If the handler cannot survive a second run, you get duplicate emails, double charges, and painful cleanup.
Give every run a stable ID. If the job works on a business object, use a dedupe key tied to that object, such as invoice:2026-04:customer_481 or account_77:billing_sync. Save that key before you do the side effect, then reject the same key on later attempts.
This matters most when money or messages leave your system. If a job creates a charge, sends an invoice, or pushes a webhook, the second run must see that the action already happened and return success without doing it again. Many payment and email tools support idempotency tokens. If they do not, keep your own send log and check it first.
Big jobs need progress tracking. If one handler touches 50,000 rows, do not treat it like one huge block of work. Save a checkpoint after each small batch or each completed record so a retry can continue from the last safe point instead of starting over.
A cursor, a last processed ID, or a table of completed items is usually enough. Pick the one your team can inspect easily at 2 a.m. when a job gets stuck.
Write changes in a safe order. Record intent, perform the action once, then save the confirmed result. If you send first and write later, a crash in the middle leaves you guessing whether to retry or stop.
Your handler should return one clear result:
donewhen the work finished or already happenedretrywhen a temporary error blocked progressstopwhen bad input or a business rule means another attempt will fail again
That small contract keeps job retry rules clean. It also makes idempotent job handlers much easier to test, because running the same input twice should leave the system in the same final state.
Choose retry rules before you ship
Not every failed job deserves another try. A timeout from an API often clears up on its own. A bad customer ID will not. If you treat both the same, you waste compute, spam logs, and hide the real problem.
Split failures into two buckets. Temporary failures should retry. Permanent failures should stop right away and ask for a fix. Teams moving from scripts to services often skip this step, then wonder why a simple recurring job keeps looping for hours.
A small rule set is usually enough:
- Retry network timeouts, short 5xx outages, rate limits, and brief database connection drops.
- Stop on bad input, missing records that should already exist, broken config, and permission errors.
- Set a hard cap on attempts. Three to five tries is enough for most jobs.
- Wait between attempts. Start with 30 seconds or a few minutes, then increase the delay if the same error keeps happening.
The wait time matters. If a job retries every second, it can turn a short upstream outage into extra load for both sides. Backoff gives the other system room to recover and keeps your own service calmer.
Every attempt should leave a clear record. Save the attempt number, the error message, the reason code, and the next action. That action might be "retry in 2 minutes", "stop and alert", or "drop because input is invalid". When someone checks the job later, they should not have to guess what happened.
Set one more limit: total retry time. If a job runs every 10 minutes but can keep retrying for an hour, you can pile up overlapping work. That gets messy fast. End the retry window, mark the run as failed, and let a person or the next clean run pick it up.
Retry rules do not need to be clever. They need to be boring, predictable, and easy to explain. If your team can read a failure and know the next action in a few seconds, the rule set is doing its job.
Move from scripts to a service in small steps
Most teams do not need a full rewrite. When recurring jobs in Go start as shell scripts, the safer path is to map what you already run, then move one job at a time into a small service.
Start with a plain inventory. Write down every script, what it does, how often it runs, where it runs, and who starts it today. You will usually find a messy mix: one cron job on a VM, one script started by a founder, another task hidden in a CI pipeline. That list gives you the real migration plan, not the one people remember from memory.
Next, group the jobs by timing and owner. A nightly billing sync belongs with finance. A product import every 15 minutes belongs with the team that owns the catalog. This sounds boring, but it stops a common problem: the software team runs the job, but nobody in the business notices when the result looks wrong.
Before you move anything, pick one handler shape and one job envelope for every job. Keep it boring and consistent. Each run should carry the same basic fields:
- job name
- scheduled time
- run ID
- attempt number
- payload
That envelope makes logs, retries, and alerts much easier to read. It also keeps one-off jobs from growing their own special rules.
Put schedule definitions in one place. That can be a scheduler config file, a small table, or a single package in the service. Do not scatter timing rules across code, cron tabs, and deployment scripts. When someone asks, "When does this run?", you want one answer.
Then ship one low-risk job first. Pick something useful but easy to verify, like a daily report or a cache refresh. Watch it for a few days. Check run times, failures, duplicates, and how long recovery takes after an error. If the team can explain what happened during one bad run, the setup is good enough to move the next job.
Small SaaS teams often rush this step. They regret it later. A slow, visible migration usually beats a clever one.
Example: daily invoice sync for a small SaaS
A small SaaS that pulls invoices from customer billing accounts often runs the sync at night, when API traffic is lower. At 02:00, the scheduler creates one job per account. It only creates the run request with an account ID, a planned time, and a run ID. It does not fetch invoices or decide whether the sync succeeded.
The Go service handles the business work. A job handler loads the account, reads the last saved sync cursor, and asks the billing API for invoices newer than that cursor. After it stores any new invoices, it saves the newest cursor. That split keeps the boundary clean. The scheduler owns timing. The app owns sync logic.
Say one account usually finishes in under a minute, but the provider API slows down and the handler hits its timeout. The run should end with a timeout status, and the scheduler should queue one retry 10 minutes later. That gives the provider a chance to recover without creating a storm of duplicate runs.
If the retry starts after the first attempt already saved some invoices, the handler should still stay safe. It reads the current cursor again before processing. If that cursor already covers the invoices from the earlier attempt, it skips them. No duplicate rows, no second webhook, no messy cleanup the next morning.
Some failures need a hard stop. If the provider says the access token expired, the job should not retry at all. The handler should mark the account as needing manual action, store the reason, and exit. A delayed retry will never fix broken credentials.
That is what idempotent job handlers and clear retry rules look like in practice. When a team moves from scripts to a service, this kind of daily invoice sync stays predictable: one scheduler decision, one handler job, one saved cursor, and clear cases for retry or manual follow-up.
Mistakes teams make early
The first version of recurring jobs in Go often starts as one function that does everything. It reads the cron schedule, decides whether it should run, loads data, writes to the database, calls an API, and sends a message when it finishes. That feels fast at first. A month later, nobody wants to touch it.
This mix causes small bugs that are hard to see. If timing logic lives next to business logic, every change becomes risky. A simple change to when a job runs can break what the job does, and a change to the job can affect when it runs.
Another common mistake is hiding retries inside the handler. A developer wraps an API call in a loop, then the scheduler also retries the whole job after a failure. One bad request can turn into six calls, duplicate writes, or a partner API rate limit. Teams usually notice this only after customers get two emails or two invoices.
Time handling causes trouble too. Developers call time.Now() deep inside the business code, then tests depend on the clock. The test passes at 10:00, fails at midnight, and nobody trusts it. Pass the current time into the handler instead. That keeps the rules clear and makes tests boring, which is what you want.
Email and side effects trip teams up early. A job updates an order, sends a confirmation email, and only then finishes the database transaction. If the commit fails, the customer has an email for something that never actually happened. The order of operations matters. Save the state first, then trigger side effects from committed data.
Tracing is often missing from day one. A job runs, fails, retries, half-succeeds, and leaves behind a mess. Without a run ID, you cannot tell which logs, rows, and outbound calls belong to the same attempt. You end up guessing. Guessing is slow, and it gets expensive when the job touches money or customer accounts.
A cleaner setup is plain: the scheduler decides when to run, the handler does one unit of work, and every attempt has an ID you can follow across logs and storage. That separation looks boring in code. Boring code is easier to trust at 2 a.m.
Quick checks before a job goes live
Before you ship recurring jobs in Go, test the boring parts first. Most job failures do not come from the business logic. They come from reruns, vague errors, missing visibility, and one bad tenant blocking everyone else.
A short preflight check saves a lot of cleanup later:
- Run the handler twice with the same input. The second run should do nothing harmful. If it creates duplicate rows, sends a second email, or charges twice, stop and fix that before launch.
- Split errors into two groups. Temporary failures, like a timeout or a rate limit, should retry. Permanent failures, like bad input or a missing customer record, should stop and report the issue.
- Isolate tenants or accounts. One customer with broken data should not freeze the whole job. Process each tenant in its own unit so you can skip, retry, or pause one without touching the rest.
- Keep enough input to replay one failed run. Store the request payload, the selected tenant, and the job version, or log them clearly. If support cannot rerun one case without guessing, debugging will drag on.
- Show the last success time and the latest error in a place humans can read fast. A simple admin page or dashboard is often enough.
These checks sound small, but they shape the whole design. Idempotent job handlers need stable identifiers and clear write rules. Retry rules need error types that mean something. Tenant isolation often means you stop thinking about "the daily sync" as one giant task and start thinking in smaller runs.
A simple example makes the point. Say a billing sync runs every night for 200 customers. Customer 37 has bad credentials. The job should mark that tenant as failed, record the error, and keep going. The team should still see that 199 customers finished, one customer needs attention, and the failed case can run again after the credentials are fixed.
If you cannot answer these checks in plain language, the job is not ready yet.
Next steps for a cleaner Go job setup
A cleaner setup starts on paper, not in code. For each recurring task, write down three things: who decides when it runs, what input it needs, and when it should stop retrying. If those rules stay fuzzy, the handler turns into a grab bag of timing, business logic, and recovery code.
A simple job note is enough at first. Keep it short and specific:
- Scheduler owns timing and trigger rules
- The Go service owns the handler and business checks
- Each run gets a run ID for tracing and logs
- Retries stop after a fixed limit or a clear terminal error
That one page saves time later. When a job fails at 2 a.m., the team can see whether the problem sits in the schedule, the input, or the handler itself.
Then pick one job this week and pull schedule logic out of the handler. Do not start with the messiest one. Choose a task that already runs on a fixed interval, such as a daily sync or a cleanup task. Move the timing rule into your scheduler, keep the handler focused on one unit of work, and pass the run context in as input. Small wins matter here. One clean job teaches the pattern better than a big rewrite.
Before you add more jobs, add the basics teams often skip. Store the last success time. Include a run ID in logs, metrics, and alerts. Decide who gets notified when retries run out, and what counts as noise versus a real problem. Without that, jobs pile up quietly until someone notices stale data.
If your team is moving from scripts to services and wants a second opinion, Oleg Sotnikov can review your Go job design and retry model as a Fractional CTO. That kind of review usually catches simple issues early: retries that hit the same bad record forever, handlers that are not safe to rerun, or schedules that live in two places and drift apart.
Good recurring jobs are boring. They run on time, fail in clear ways, and leave enough evidence for someone else to fix them fast.


