Pydantic models for API drift across Python services
Pydantic models for API drift help Python teams reject bad payloads early, but over-modeling every field can slow releases and reviews.
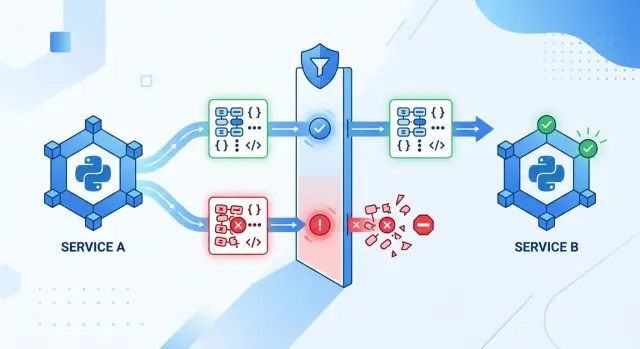
Table of Contents
What API drift looks like in real teams
API drift rarely starts with a dramatic break. It usually starts with one small change that looks harmless during a normal deploy. One service sends user_id, another still expects customer_id, and nobody notices because both names seem close enough when you read the code quickly.
That kind of mismatch is common when two Python services change on different schedules. A payments service may rename a field to match a new database column, while an orders service keeps the old name because its release is next week. The payload still moves through the queue or API call, but one side now reads empty data or falls back to a default that should never be used.
Types drift just as easily. A field that used to be an integer becomes a string because a frontend team needs to preserve leading zeros, or because a partner API sends everything as text. Nothing explodes at first. Python often accepts the value, logs look normal, and the deploy goes out. The bug shows up later when another service sorts, compares, or adds that field and gets a result that makes no sense.
Optional fields cause a slower kind of damage. A team adds coupon_code as optional, then a month later builds logic that assumes it is always present for a certain checkout flow. After that, another team treats it as required in their serializer because every recent test payload included it. Soon you have three services with three different ideas about the same field.
The worst part is distance. The real problem starts in one payload, but the visible bug appears somewhere else. A signup service accepts a half-wrong request, a profile service stores it, and an analytics job fails six hours later with a confusing type error. By then, the person reading the alert is nowhere near the original deploy.
Teams feel this most when they move fast. A startup can ship five small API changes in a week. Each one looks reasonable on its own. Together, they turn the contract between services into guesswork, and guesswork is where expensive debugging begins.
Why Pydantic stops bad payloads early
Most API bugs start before your business logic does. One service sends "42" instead of 42, slips in an extra field, or forgets a nested value, and the next service tries to guess what the sender meant.
Pydantic fixes that at the edge of the service, where requests first arrive. The model parses the payload, checks each field, and either turns it into a known shape or rejects it right away. That is why Pydantic models for API drift work so well between Python services. They stop bad data before it spreads.
This changes the failure point in a useful way. Instead of a strange bug deep in order processing, billing, or notifications, the request fails at the boundary. The team sees a clear validation error tied to the exact payload that caused it. That saves time because developers do not need to trace a bad value through five functions and two queues.
Strict validation helps most with a few common problems:
- wrong types, like a string where the contract expects an integer
- missing required fields, especially in nested objects
- unknown fields on public endpoints that should reject surprise input
Unknown fields matter more than people think. If a public endpoint accepts extra data silently, clients can start depending on behavior you never planned to support. Later, removing or renaming that field turns into a breaking change. When you forbid extras on public models, you keep the contract small and clear.
Pydantic strict mode also reduces hidden coercion. A loose parser may accept values that look close enough and move on. That feels convenient for a week, then painful for months. If a price arrives as "free" or a boolean arrives as "yes", you want the request to fail early, not after the service already made decisions with bad input.
A small example shows the difference. Service A sends a user event with user_id as a string and an extra field called debug. Service B expects an integer and does not support extra input. With strict models, Service B rejects the request immediately and returns a useful error. Without that check, the event may enter the system, fail later, and leave the team arguing about where the bug started.
Good validation keeps errors close to the request. That is the cheapest place to find them, explain them, and fix them.
Start with the contract that matters
Most teams model too much too soon. That sounds careful, but it often creates more work than protection. The safer move is smaller: define the request and response at the service boundary, then leave the inside of each service alone unless another service truly depends on it.
A Python service contract should cover the data that crosses the wire. If Service A sends customer_id, plan, and currency to Service B, model those fields first. If Service B returns status and next_billing_date, model that too. That gives you a clean checkpoint where bad payloads fail early.
The trap is pulling internal objects into the API model. Database columns, helper flags, retry counters, UI labels, and half-finished business logic do not belong in a shared contract just because they exist somewhere in the code. Once they enter the model, other teams start depending on them, and simple changes turn into coordination work.
A small example helps. Say a billing service only needs four fields to create a subscription:
customer_idplan_codetrial_dayscoupon_codeonly if a coupon exists
That is enough. You do not need to expose the full customer profile, sales notes, internal pricing rules, or every audit field from the database.
Optional fields need the same discipline. Mark a field optional only when the receiving service can truly handle its absence without guessing. Teams often label fields optional because they are not sure yet, or because one old caller does not send them. That choice spreads uncertainty fast. A field should be optional for a real business reason, not to avoid a short conversation.
This is where Pydantic strict mode helps most. It works best on the narrow edge that other services rely on every day. In practice, that means fewer surprise nulls, fewer silent type conversions, and less API schema drift. It also keeps the model readable, which matters more than people admit. If another developer cannot understand the contract in one minute, it is already too big.
Add strict validation step by step
Pydantic models for API drift work best when you tighten the contract in small steps. If you try to lock down every field on day one, teams spend more time fixing model noise than real breakage.
Start with one model for the incoming JSON your service actually depends on. Keep it small. If your billing service only needs customer_id, plan, and price_cents, model those first and leave the rest alone.
Roll it out in layers
A simple order helps.
- Define one input model at the service boundary, where raw JSON enters your app.
- Turn on strict types for fields that often cause money, auth, or state bugs.
- Forbid unexpected fields only on routes where silent changes cause real damage.
- Log validation failures with the request id, route name, field name, and a safe sample of the bad value.
- Add tests for both the current payload and the older shape you still accept during the transition.
Strict types matter most when Python would otherwise coerce bad data. A string like "10" turning into an integer may look harmless until one service sends "10.0" or "ten". For risky fields such as prices, IDs, flags, and timestamps, strict payload validation cuts off bad input before it spreads.
Be selective with extra="forbid". It is useful on endpoints where an extra field may mean another service changed its contract without telling anyone. It is less useful on payloads that include metadata you do not care about yet.
Logging needs enough context to help the next person fix it fast. "Validation failed" is not enough. A good log tells you which service sent the payload, which route rejected it, and which field failed.
Tests should cover change over time, not just one happy path. Keep one test for the new payload shape and one for the old shape if you still support both. That small habit catches drift early and keeps upgrades calm.
This gradual approach is usually the right one for small teams. It gives you a real contract without turning every minor payload change into a small fire.
A simple example with two Python services
A small break between services can turn into a real billing bug. Picture an order service that sends checkout data to a billing service after the customer clicks "pay".
At first, the order service sends total as a float. That feels harmless: 19.99 looks like a price. The billing service, though, expects total_cents as an integer, because charge systems usually work better with whole cents.
from pydantic import BaseModel, ConfigDict, ValidationError
class BillingRequest(BaseModel):
model_config = ConfigDict(strict=True)
order_id: str
total_cents: int
currency: str
bad_payload_1 = {
"order_id": "ord_123",
"total": 19.99,
"currency": "USD"
}
bad_payload_2 = {
"order_id": "ord_123",
"total_cents": 1999,
"currency_code": "USD"
}
try:
BillingRequest.model_validate(bad_payload_1)
except ValidationError as e:
print(e)
try:
BillingRequest.model_validate(bad_payload_2)
except ValidationError as e:
print(e)
The first payload fails for two good reasons. It sends total instead of total_cents, and it sends a float instead of an integer. Without strict payload validation, a team might quietly convert 19.99 and later hit rounding trouble.
The second payload shows a different kind of drift. Someone renamed currency to currency_code in the order service. Maybe the new name made sense there. The billing service still expects the old field, so the request stops at validation.
That stop matters. Billing code should never guess what a payload means. If validation runs before charge logic, the service rejects the request, logs the exact mismatch, and avoids charging the wrong amount or creating a partial payment record.
This is where Pydantic models for API drift earn their keep. They fail fast, close to the boundary, and make the break obvious. The tradeoff comes later, when teams start modeling every tiny field change instead of fixing the contract both services actually share.
Where strict models slow teams down
Strict models catch bad data fast, but they also make small changes more expensive. Rename one field, split one enum value, or change a date format, and two or three services may need updates in the same release window. That is fine for a billing event that almost never changes. It gets annoying for internal APIs that still move every week.
A lot of teams feel this pain when the payload change is tiny but the process around it is not. One extra field can mean a model update, test fixture edits, review comments, and another deploy for the consumer. The work is not hard. It just keeps interrupting people.
When outside payloads are messy
Partner APIs rarely stay neat for long. One customer sends "userId", another sends "user_id", and a third sends an empty string where your model expects an integer. If your service uses very strict Pydantic models at the edge, the team often ends up building wrapper code just to reshape those payloads before validation.
That wrapper layer can grow fast. Soon you are not maintaining one clear contract. You are maintaining a contract plus a pile of cleanup rules for every odd case a partner sends.
Large models create another kind of drag. A 60 field model looks safe on paper, but every small change takes longer to review because people have to scan defaults, aliases, validators, test data, and downstream assumptions. The model becomes a checklist item instead of a useful guardrail.
Early product work is where over-modeling hurts most. If a feature is still a prototype, strict rules can freeze decisions too soon. Teams start debating every optional field before they even know what users will send. In that stage, it is usually better to lock down the few fields that drive behavior and leave the rest flexible for a while.
A simple rule helps: keep the center strict and the edges loose. Validate IDs, status values, and fields that trigger money, security, or data writes. For fields that are still moving, allow a bit of slack until the shape stops changing.
Mistakes that create busywork
Pydantic models for API drift help most when teams treat them as a small contract, not a full copy of reality. Busywork starts when people model every nested object on day one. A simple event suddenly turns into six files, twenty classes, and long review threads about fields nobody uses.
That usually happens when a team sees one messy payload and tries to lock down all of it at once. If service B only needs customer_id, status, and total, model those fields first. Leave the rest as a plain object or ignore them until they matter. You cut risk without turning a small change into a week of cleanup.
Another common mistake is reusing database models as API contracts. Database rows change for storage reasons. API payloads change for communication reasons. Those are not the same job. If you tie them together, a harmless column rename can break a service boundary that did not need to change.
Error handling creates its own mess. When validation fails and the API returns a generic 500, nobody learns anything. The sender retries. The receiver logs a stack trace. Two teams waste an afternoon guessing whether the issue came from code, data, or infrastructure. A clear 400 response with field-level details saves time fast.
Loose typing also looks friendly until it piles up repair work. If you accept strings for numbers and dates, every service adds its own parsing rules. One team sends "10", another sends "10.00", and someone else sends "next Friday". The model stops being a contract and turns into a cleanup script.
A small warning sign shows up in code review: fields keep getting added, but nobody reads them. That is how contracts become cluttered. Extra fields raise test costs, docs costs, and migration costs. They also make real breaking changes harder to spot.
A better default is boring on purpose:
- model only fields a consumer reads
- keep API models separate from ORM models
- return clear validation errors
- use strict types for money, IDs, and dates
- delete unused fields after a short review
Oleg Sotnikov often pushes teams toward this lean approach in AI-first development work, and it makes sense. Strict validation should catch bad payloads early. It should not turn every message into a giant schema project.
Quick checks before you add another field
Most extra fields start as a harmless request and end as long-term maintenance. A new field changes tests, docs, deploy order, and the mental load for every team that touches the payload.
Before you add one, check whether anyone reads it right now. If no service uses it today, you may be storing future guesswork inside a contract. That is how APIs get wider, harder to reason about, and easier to break by accident.
A short pause helps more than another quick patch:
- Name the service or person that reads the field today.
- Ask what happens if the type is wrong. Does it affect billing, access checks, or another sensitive path?
- Decide whether a safe default exists when the field is missing.
- Use Pydantic strict mode only on fields where bad input causes real damage.
- Pick one owner for version changes, even if two teams share the API.
The second check matters more than most teams admit. A wrong string in a notes field is annoying. A wrong type in price, currency, user_id, or role can create bad charges or loose auth checks. Those fields deserve hard validation early, even if it makes local testing a bit slower.
Defaults need the same care. If timezone can safely fall back to UTC, fine. If discount_percent falls back to 0, that may hide a sender bug for weeks. Silent defaults feel convenient until finance asks why totals changed.
This is where Pydantic models for API drift help most: they make the risky parts explicit. They help less when a team models every optional bit of metadata with the same level of force. If a field is informational and no downstream logic depends on it, a looser model often keeps work moving.
One more rule saves a lot of friction: version changes need a clear owner. Someone has to say when a field is added, when it becomes required, and when old payloads stop working. Without that, both teams assume the other side will handle it, and drift starts again.
What to do next
Pick one endpoint that causes real pain and model that first. A login callback, billing webhook, or internal job trigger usually gives you enough traffic and enough messy payloads to learn fast.
Pydantic models for API drift work best when the first pass stays small. Model the fields that break downstream code, not every field you might want one day. If one service only needs user_id, plan, and status, keep the contract there and leave the rest loose for now.
A practical rollout looks like this:
- Choose one noisy endpoint with a history of bad payloads, missing fields, or type mismatches.
- Add validation at the service boundary and log every rejected payload with a short reason.
- Watch those rejections for two weeks and group them by cause.
- Remove or relax rules that do not prevent real failures in production.
This part matters because teams often over-model too early. They add enums for every status, strict limits for strings nobody reads, and nested models for data no caller uses. That feels neat for a week, then every small upstream change turns into busywork.
A better test is simple: did this rule stop an outage, a bad write, or a support issue? If not, cut it. Strict payload validation should block expensive mistakes, not make routine changes harder.
If you want a concrete example, imagine two Python services that share order updates. Service A sends amount as a string on Friday, a number on Monday, and sometimes skips currency when a new code path runs. A small Pydantic model catches that at the edge, and your logs tell you which mistake shows up most. That gives you facts, not guesswork.
If your Python service contracts drift often, an outside review can save time. Oleg Sotnikov does this kind of contract and rollout planning as a Fractional CTO, with a strong track record in Python services, production systems, and lean engineering teams. A short review is usually enough to pick the right endpoints, set sane rules, and avoid a cleanup project later.