Prometheus label cardinality: naming rules that stay sane
Prometheus label cardinality gets expensive fast when labels hold user IDs, URLs, or hashes. Use simple rules to keep dashboards fast and costs under control.
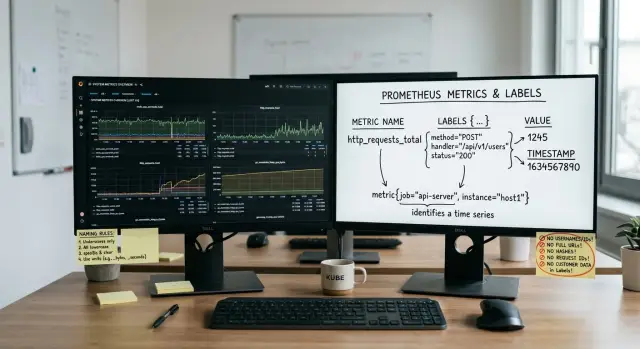
Table of Contents
What goes wrong when labels grow without limits
Prometheus label cardinality is the number of unique time series your metrics create. A metric with no labels is one series. Add method="GET" and method="POST", and now you have two. Add status, region, and instance, and the total multiplies fast.
Trouble starts when a label can produce almost endless new values. user_id, session_id, request_path, ip, or a raw error message might look harmless in code. In Prometheus, each new value creates another series to store, index, and scan.
That growth is easy to miss. Ten services with a few stable labels usually stay fine. The same ten services with labels that change on every request can turn one metric into thousands or millions of series. At that point, the metric stops helping and starts burning memory, disk, and query time.
You usually notice it in dashboards first. Panels that once loaded in a second start hanging or timing out. Simple graphs feel slow because Prometheus has to search far more series than the chart actually needs. If you also send metrics to long term storage, the bill rises with the noise.
There is a readability cost too. High cardinality labels turn dashboards into clutter. Instead of seeing error rate by service or latency by route, you get a wall of tiny slices split by random IDs and one off values. The signal is still there, but it is buried.
A common example is request latency with path set to the full URL. /product/123, /product/124, and /product/125 become separate series even though they all describe the same route. Add methods, status codes, and instances, and the chart bloats fast.
Prometheus works best when labels describe a small set of stable dimensions. Once labels start looking like logs, the monitoring system slows down and the data gets harder to trust.
Labels that usually cause the mess
Most label problems come from values that never settle down. A label helps when the same small set of values repeats over time. It gets expensive when almost every scrape brings a fresh value, because Prometheus stores a separate series for each unique label set.
User IDs are a common mistake. It feels useful to filter metrics by one person, but a user_id label creates a new series for every account. In a busy app, that count keeps rising all day.
Request IDs and trace IDs are worse. They change on every call, so they almost guarantee endless growth. Session IDs, cart IDs, order tokens, and similar fields create the same problem. Keep that detail in logs or traces, where event level data belongs.
Full URLs create a quieter version of the same mess. Prometheus does not know that /product/101 and /product/102 are the same page pattern. It only sees different label values. A route label like /product/:id keeps the metric readable and stops the series count from growing for no good reason.
Other bad fits include hashes, checksums, exact timestamps, full file paths, raw search terms, and email addresses. These values rarely repeat, and some hardly ever do. The data may still matter, but it belongs in logs, traces, or a database query, not in a metric.
A simple rule catches most mistakes: if a label will keep gaining new values every day and you cannot name a clear ceiling, do not put it in a metric. Teams often add these labels while chasing a short debugging problem, then forget to remove them. Saying no at the start is much easier than cleaning up months later.
Naming rules that stay readable
Many cardinality problems start with names that look harmless. A team adds labels quickly, each service invents its own style, and six months later nobody knows whether region, zone, and location mean the same thing.
Good label names are short, plain, and boring. That is a compliment. If someone opens a query at 2 a.m., they should understand each label without digging through code or old chat threads.
Each label should mean one thing everywhere. If status means HTTP status on one metric, do not reuse status for order state or job state somewhere else. Call them http_status and job_state. Clear names save time.
Labels with small bounded sets are usually safe. region, method, status_code, and env stay readable because the list of values stays small and predictable. If a label can grow without a clear limit, like user_id, email, request_id, or a raw URL path, that label does not belong in a metric.
Consistency matters more than perfect naming. If one service uses method and another uses http_method, queries get messy fast. Dashboards become harder to reuse, and small mistakes creep into alerts. Pick one name and keep it across teams and services.
Readability also means choosing names people can guess on first sight. az saves two characters, but many people will stop and ask what it means. availability_zone is longer, but it is clear.
A quick test works well: show the metric to someone outside the team. If they can explain what each label means and what values it might hold, the naming is probably fine. If they need a tour, rename it before it spreads.
How to decide if a label belongs in a metric
A label should earn its place. Before you add one, ask a simple question: what decision will this label help you make when a graph spikes or an alert fires? If you cannot answer that clearly, the label is probably noise.
Good labels answer operational questions such as "which region is slow?" or "which status code is rising?" Bad labels answer one request trivia, like a request ID, email, session token, or full URL with user specific parts.
Then check the size of the value set, not just today but six months from now. region="us-east-1" stays small. customer_id="847221" does not. A label that starts with 20 values and grows to 200,000 will hurt query speed, memory use, and storage cost.
If nobody will group or filter by the label, drop it. A label that never appears in dashboards, alerts, or recording rules only adds cost. Teams keep labels "just in case" all the time, and they usually regret it.
Five questions before you add a label
Keep the label only if most of these answers are "yes":
- You can name the graph or alert that needs it.
- The set of values stays small and predictable.
- People will group or filter by it during incidents.
- The label is not a unique identifier.
- Logs or traces cannot carry the same detail better.
A small web app makes this easy to see. endpoint="/checkout" makes sense if the team compares latency across a handful of routes. user_id does not. If support needs to inspect one failed checkout, logs or traces can hold user_id and request_id, while the metric keeps only the labels that summarize behavior.
This rule sounds boring, which is exactly why it works. Metrics should stay coarse enough to answer system questions quickly. Put unique or growing values somewhere else.
How to drop bad labels step by step
Start with one metric, not your whole stack. Write down every label it emits. If a request metric has method, status, path, user_id, session_id, and trace_id, list all six before you change anything.
Then mark each label as bounded or unbounded. A bounded label has a small known set of values, such as GET and POST, 200 and 500, or a route like /users/:id. An unbounded label can keep growing forever: raw URLs, account IDs, email addresses, hashes, search terms, request bodies, and free text error messages.
That simple review catches most cardinality problems before they hit storage.
Keep labels with short fixed sets of values. Replace raw paths and URLs with route templates. Remove IDs, UUIDs, hashes, timestamps, and free text fields. If you can, drop the bad label in the app before it leaves the process. If you cannot change the app quickly, use relabeling to rewrite or remove it before storage.
Raw URLs are a common trap. /product/123 and /product/124 look almost the same to a person, but Prometheus stores them as different series. Change them to /product/:id or another stable pattern that matches your router.
If a label only helps when one person is debugging one request, it usually does not belong in a metric. Put that detail in logs or traces instead. Metrics should show patterns across many requests, not fingerprints for one event.
After the cleanup, test the result in dev or staging. Compare the number of time series before and after, then run the dashboard queries that matter most. If a metric drops from 50,000 series to 500, storage gets cheaper and dashboards usually feel fast again.
A simple example from a web app
Picture a small SaaS app with an API behind a dashboard. Every request hits the same counter, and the team wants enough labels to answer basic questions quickly: which service handled it, which route it used, which HTTP method came in, and which status code went out.
That usually looks like this:
http_requests_total{service="billing",route="/users/:id",method="GET",status="200"}
Those labels stay useful because they have clear limits. You may have a handful of services, a fixed set of routes, a few methods, and a small status code range. Dashboards stay quick, and the numbers still tell a clear story.
The trouble starts when someone adds customer_id to every request metric.
http_requests_total{service="billing",route="/users/123",method="GET",status="200",customer_id="84721"}
Now each customer creates a new time series. If one service has 20 routes, 2 methods, and 5 common status codes, you start with about 200 series. Add 50,000 customer IDs and that metric starts pushing toward 10 million series.
The route value creates a second problem. If the app exports /users/123, /users/124, and /users/125 as different labels, every user page creates more series. The fix is simple: turn dynamic paths into templates before export. /users/123 becomes /users/:id. /orders/9981/items/7 becomes /orders/:id/items/:item_id.
Customer details still matter, but metrics are the wrong place for them. Put customer_id, email, account name, and other per user values in logs. Then add a request ID or trace ID there so you can match an error spike to the exact customer session later.
One small change does most of the work: remove customer_id from request metrics and normalize the route. You keep the dashboard questions people ask every day, and you stop series growth before memory use climbs and query speed drops.
Mistakes that make dashboards slow
Most slow Prometheus dashboards come from one small choice: a label that creates a new time series for almost every request. One metric turns into thousands before anyone notices, and then queries get heavy, panels time out, and storage costs rise.
session_id is a classic example. It feels useful because it helps you inspect one user journey, but metrics are the wrong place for that detail. If almost every request has a different session ID, the series count jumps fast.
Raw error text causes the same problem. Teams often add the full error message as a label so they can group failures in Grafana. It sounds handy until each wording change creates a new label value. A timeout, a SQL error, and a validation error should usually become a small set such as error_type="timeout" or error_type="db".
Another easy mistake is keeping both a route and the full path on one metric. The route might be /users/:id, while the full path is /users/123. The route gives you clean aggregation, but the full path still explodes the series count. Use the route in metrics and leave raw paths to logs or traces.
Naming drift hurts too. One team uses service, another uses app, and a third uses app_name for the same thing. Queries get longer, dashboards get messy, and people end up duplicating panels because the labels do not line up.
Copying labels from traces into every metric is another trap. Trace data often includes request IDs, user IDs, full URLs, and other unbounded values. Metrics need the opposite approach: a small stable set of labels that stays useful over time.
Safe defaults are usually plain. Use route, not full path. Use a status code or a small error type, not raw error text. Use one label name per concept across teams. Keep request IDs, session IDs, and trace IDs out of metrics.
If a label helps you inspect one request but not a pattern across many requests, it probably belongs somewhere other than Prometheus.
Quick checks before you ship
A metric can look harmless in code and still turn into noise in production. Most label mistakes are obvious if you spend five minutes looking at real output instead of trusting the code that produced it.
Before shipping a new metric or label change, count how many distinct values each label can produce. A few HTTP status codes are fine. A label tied to users, orders, or requests is not. Scan for anything unbounded: IDs, UUIDs, hashes, email addresses, session tokens, timestamps, and raw URL paths. Ask what question the metric answers on a dashboard or alert. If nobody will group or filter by that label, remove it.
Then compare the label names with the rest of your metrics. If one service says env and another says environment for the same thing, queries get messy fast. Finally, review one sample scrape before release. Real output exposes surprises such as full paths, dynamic job names, or labels copied from request headers.
These problems usually start with one label that felt convenient during development. Someone wants more detail, adds user_id or path, and the metric still works on a laptop. A week later the dashboards lag, memory use climbs, and the bill follows.
A good label stays small and predictable over time. It should also help someone answer a real question. method makes sense because people compare GET and POST. build_sha usually does not, unless you truly need to split every metric by every deploy.
A sample scrape is often the best reality check. In a web app, route="/users/:id" is usually safe. path="/users/123" is not, because every new ID creates another series. The same rule applies to tenant names, file names, and anything copied straight from user input.
If you cannot estimate the label's value count in a minute, treat it as suspicious. That short pause before release is much cheaper than cleaning up a noisy Prometheus server later.
What to do next
Write down a short naming policy and keep it where every engineer can see it. Decide how metric names should read, which labels are allowed, and which values never belong in labels, such as user IDs, raw URLs, email addresses, request IDs, and timestamps.
Keep that policy small. One page is often enough. If people need a long meeting to add one metric, the rules are probably too vague.
Then make the policy part of daily work. Check new metrics in code review. Add CI checks for common bad patterns. Block obvious cases where labels contain unbounded values. Keep a few good metric examples in team docs so engineers can copy the right pattern instead of inventing a new one.
It pays off quickly. Bad labels take minutes to add, but they can slow dashboards, raise storage costs, and bury the numbers your team needs during an incident.
Review older dashboards and alerts too. Look for panels that scan too many series, depend on wide regex matches, or pull labels that nobody uses to make a decision. Old queries often keep expensive metrics alive long after the original reason is gone.
Clean the source, not just the chart. Hiding a noisy label in a dashboard does not reduce cardinality. Remove bad labels in instrumentation or relabeling, then cut unused metrics from scrape jobs, alerts, and recording rules.
It also helps to give one person ownership of metric hygiene. They do not need to approve every change, but they should keep the rules clear, answer edge cases, and call out drift before it spreads.
If your Prometheus setup already feels messy, a second opinion can save time. Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor, and his experience running production infrastructure makes this kind of cleanup easier to reason through.
Put a recurring audit on the calendar. Check new metrics, high series jobs, and slow dashboards once a month. Cardinality problems come back quietly, so a short review now is much cheaper than another cleanup after bills jump.
Frequently Asked Questions
What is label cardinality in Prometheus?
Prometheus creates one time series for each unique metric and label set. If you add labels with many values, one metric can turn into thousands or millions of series and slow queries, raise memory use, and grow storage cost.
Which labels usually cause cardinality problems?
Avoid labels that keep getting new values, such as user_id, request_id, session_id, trace_id, email addresses, raw IPs, hashes, timestamps, and raw error messages. Those values fit logs or traces much better than metrics.
Is `path` a bad label for request metrics?
Yes, if you store the full path like /users/123. That creates a new series for every ID. Use a stable route label such as /users/:id so Prometheus groups similar requests together.
How do I decide if a label belongs in a metric?
Keep a label only if someone will group or filter by it on a dashboard, alert, or recording rule. Good labels answer system questions like which route is slow or which status code is rising. If a label only helps with one request, leave it out.
How can I tell if a label set is too large?
Look at real metric output and ask how many distinct values each label can have in a month, not just today. If you cannot name a clear ceiling in a minute, treat that label as risky.
What should I use instead of `user_id` or `request_id` in metrics?
Put that detail in logs or traces and keep the metric coarse. You can store user_id, request_id, and full URLs there, then use a request or trace ID to connect a spike in metrics to one failing request.
Can relabeling help if I cannot change the app yet?
Yes. If you cannot change instrumentation right away, use relabeling to drop or rewrite bad labels before Prometheus stores them. That works well for raw paths, copied headers, and other noisy values.
What naming rules keep metrics readable?
Pick one name for each concept and use it everywhere. If one service says method and another says http_method, queries get messy fast. Clear names like http_status, route, service, and env usually age well.
Should I put `build_sha` or version info in labels?
Usually no. A build_sha label splits every metric by every deploy, which adds series fast and often gives little value. Keep deploy details in release metadata unless you truly compare metrics by version every day.
How often should we audit metrics and labels?
Review new metrics before release and audit the stack on a schedule, often once a month. If your dashboards already lag or series counts look messy, get a fresh review from someone who knows Prometheus and production systems well.


