Postgres logical decoding for audit and sync choices
Postgres logical decoding helps when you need near-real-time audit trails or data sync, but polling still wins for small, simple jobs.
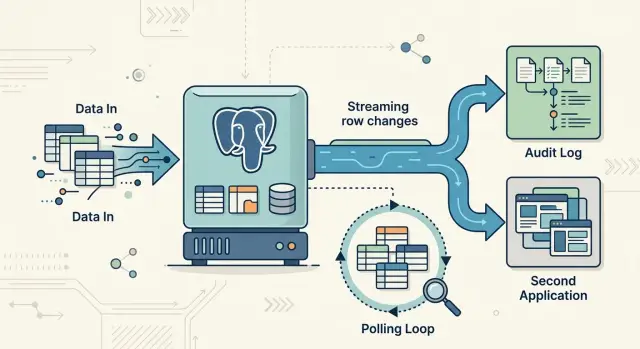
Table of Contents
Why polling starts to hurt
Polling looks cheap at first. A team adds an updated_at column, runs a query every 30 seconds, and ships the feature. On a small table with light traffic, that can work just fine.
The trouble shows up later. Polling asks the same question over and over, even when almost nothing changed. The database still checks indexes, reads rows, sorts results, and sends data back. Your app still compares timestamps, stores offsets, and throws away duplicates. Most of that work finds nothing new.
Short intervals make the waste easy to see. A job that runs every five seconds across several busy tables creates constant background load, even if only a few rows changed in the last minute. For audit logging or data sync from Postgres, that gets expensive quickly. You end up paying for lots of reads to catch a very small amount of new data.
Long intervals reduce the load, but they create a different problem. Fresh changes sit and wait for the next poll. A support tool can show old status for a minute. A reporting system can lag behind. A sync worker can dump many updates at once, which makes downstream systems work harder than they need to.
Polling also pushes teams into awkward rules. They add watermarks, retry windows, and "just in case" overlap queries so they do not miss rows with the same timestamp. The code grows quietly. A quick script turns into a small reliability project.
That is why polling often feels simple right up to the moment it does not. Many teams start there, and that is perfectly reasonable. But once change volume rises or the business wants near real time data, polling stops being the easy option. At that point, Postgres logical decoding often wins because it captures actual changes instead of repeatedly asking whether something changed.
What logical decoding actually gives you
Postgres logical decoding reads changes from the write ahead log instead of checking the same tables again and again. That matters because the log already records what the database committed. Rather than running a query every 10 seconds and asking "what changed since last time?", another service can read the change stream directly.
In plain terms, logical decoding gives you a feed of row events. It can stream inserts, updates, and deletes in commit order, so a consumer sees changes in the same sequence Postgres accepted them. For audit work, that order helps you rebuild a clear timeline. For sync work, it helps another system stay close to the source without constant rescans.
A polling job usually needs extra logic to find new or changed rows. Teams add updated_at columns, compare IDs, or keep checkpoint tables. That can work, but it gets awkward fast when updates happen often or when you need low delay. Logical decoding skips the repeated table scan and sends only real changes.
A simple example helps. Say an app stores customer orders in Postgres and a second service keeps a search index or an audit trail. With logical decoding, the second service can react when an order appears, changes status, or gets deleted. It does not need to sweep the whole orders table every minute just to find two changed rows.
Still, the stream only tells you what changed in Postgres. It does not decide your business rules for you. If your audit log must hide sensitive fields, you still need code for that. If two systems disagree, you still need conflict handling, retries, and rules about which side wins.
That is the right mental model: logical decoding gives you a reliable stream of committed database changes. It saves you from rescanning tables. It does not remove application logic.
When it beats polling
Polling looks harmless when changes are rare. It gets messy when rows change all day and other systems need those updates quickly. In that situation, Postgres logical decoding often wins because Postgres tells you what changed instead of forcing your app to keep asking.
An audit trail is the clearest case. If you need every insert, update, and delete in the right order, polling leaves gaps. A row can change twice between checks, and your poller only sees the latest state. Logical decoding gives you the change stream itself, so you can record what happened, not just what the row looks like now.
It also fits sync work well. If you send Postgres data into search, analytics, a warehouse, or another app, polling usually means repeated scans or tricky updated_at filters. Both get noisy on busy tables. A change stream is cleaner. Your search index updates within seconds, your analytics pipeline stays fresh, and you stop rereading rows that never changed.
Read load matters too. On a write heavy system, polling adds extra pressure right where you do not want it. Every frequent check competes with normal queries. Logical decoding changes the job from "scan and compare" to "read the next change," which is usually lighter and cheaper.
Fast downstream updates are another strong reason. If a customer changes an order status, waits 10 minutes, and still sees stale data in a dashboard or support tool, polling starts to feel broken. Change data capture fixes that. The update can reach other systems almost right away.
A simple rule works well. Choose decoding when every row change matters, when other systems must stay close to real time, when polling hits busy tables too often, or when you need the sequence of changes rather than just the final row state.
If your app needs a reliable history and quick sync with less database churn, logical decoding is usually the better tool.
When polling stays simpler
Polling is still the better choice in plenty of small systems. If only a few rows change each hour, a simple query on a schedule often beats a full change stream.
Think about a back office app where staff update order notes, mark invoices as paid, or fix a customer record now and then. If a worker checks every five or 10 minutes, picks up the changed rows, and stores the last checkpoint, that delay is usually fine. You get the result you need without building a second system next to your database.
This works especially well when you can shape the table for the job. Add an updated_at column, make sure the app changes it on every write, and put a good index on the columns your worker uses. In many cases, that is enough to keep the query fast even as the table grows.
Polling tends to stay simpler when change volume is low, a few minutes of delay does not hurt, one background worker can handle the load, and the team wants less operational work.
That last point matters more than people admit. Logical decoding can give you near real time events, but it also asks you to run extra consumers, track offsets, handle retries, and recover cleanly after failures. If your team is small, or if nobody wants to own that plumbing, a boring polling job is often the safer pick.
It is also easier to explain to future teammates. "Query rows changed since the last run" is easy to read, easy to test, and easy to fix at 2 a.m. if something stops. A missed polling run usually means you rerun the job. A broken change stream can mean lag, duplicates, or a slot that keeps old WAL files around longer than you expected.
If the data changes slowly and the timing is loose, keep it plain. One worker, one checkpoint, and one indexed query are hard to beat.
How to choose step by step
Start with the tables, not the tool. Make a short map of which tables change, what kind of change matters, and who needs to hear about it. Teams often say they need CDC, then realize only three tables matter and only one downstream app cares.
A short decision path works better than a long architecture debate. List the tables that change often and the systems or teams that depend on them. Write down how much delay each consumer can accept: seconds, minutes, or hours. Decide which failure hurts more: missing a change, sending the same change twice, or being unable to replay history. Then count the parts you will run in production, not just the code you will write, and choose the simplest setup that still meets the timing and reliability target.
Timing decides more than people expect. If another system only needs fresh data every 15 minutes, polling can be good enough and much easier to run. If you need near real time updates, or every row change must be captured in order, logical decoding starts to make sense.
Risk matters just as much. Audit trails and financial events often need replay. You may need to prove what changed, in what order, and recover after a consumer outage. Polling can miss short lived states unless you add extra logic. Logical decoding gives you the change stream, which often fits that job better.
Then count the ownership cost honestly. Logical decoding is not just a database switch. You will own replication slots, consumer lag, retries, schema change handling, and monitoring. If your team is small and the business can live with slower updates, polling may save a lot of time and stress.
A quick gut check helps. If one internal dashboard reads a few tables every hour, keep it boring and poll. If several systems need the same changes within seconds and you cannot afford missed events, use logical decoding and plan for the extra operational work.
A realistic example
Imagine a small SaaS that handles online orders. Its Postgres database has three busy areas: orders, refunds, and customer notes. Support uses those records to settle disputes, and the product team uses them to keep search fresh.
A customer writes in and says, "I never asked for this refund." Support needs a clear timeline. They want to see when the order changed, who opened the refund, and whether an agent added a note right after the call.
If those facts sit in separate tables with no shared event trail, the team spends too much time stitching the story together. That gets worse when several people touch the same order in a short window.
Search has a second requirement. When an order changes from paid to refunded, or when a note marks an account as sensitive, the search index should update within seconds. Polling the orders table every five seconds sounds harmless, but it keeps reading rows even when nothing changed.
Then the team notices that orders alone are not enough. Refunds and notes matter too, so they add more polling jobs and more updated_at rules to keep everything in sync. Reads go up, edge cases pile up, and the audit story still feels patchy.
Logical decoding fits this case better. A small relay reads the change stream from a replication slot and sends only new events to both consumers. One consumer writes an audit log in commit order. The other updates the search index as soon as Postgres commits the change.
That changes daily work. Support opens one dispute and sees a clear chain: order created at 10:02, refund requested at 10:14, agent note added at 10:15, refund approved at 10:19. Search also reflects the refund almost right away, so agents do not search stale data during the call.
You still need to run the relay, watch slot lag, and handle schema changes carefully. But in this setup, the extra plumbing pays for itself. For a lean SaaS team, that usually beats three quiet but constant polling workers.
The moving parts you must run
Logical decoding adds a small pipeline, not just a database setting. Postgres needs to keep a replication slot open, and you need a consumer that reads changes fast enough. If that consumer falls behind, Postgres keeps old WAL files longer, and disk use can climb much faster than people expect.
Start with the slot. Create one slot for each consumer pattern you actually need, not one for every experiment. Then watch lag the same way you watch free disk space, because the two are tied together.
A few numbers matter every day:
- slot lag in bytes and time
- WAL disk growth
- consumer delay since the last processed change
- restart success after a crash
- backlog after traffic spikes
The consumer needs more care than most teams expect. It should store offsets, usually the last confirmed LSN, so it can stop and resume cleanly. If it keeps state only in memory, one restart can give you duplicate records, gaps, or both.
For audit work, row changes do not automatically become useful audit records. You need rules for mapping inserts, updates, and deletes into something people can read later. Most teams need at least the table name, primary key, operation type, changed fields, and commit order. If you want a human friendly audit trail, decide early how you will attach user or request context, because the database change alone often does not tell the full story.
You also need a plan for bad days. Networks fail, downstream APIs slow down, and consumers crash right after they process a message but before they save the offset. Build retries with limits. Add backpressure so a slow sink does not drag down the whole pipeline. If some events still cannot be processed, send them to a dead letter queue or a separate error table and review them.
One test tells you a lot: stop the consumer for a full day in staging. Then restart it and measure catch up time, WAL growth, duplicate handling, and whether your alerts fire early enough. If that drill looks messy, production will look worse.
Mistakes that cause trouble
Teams often get excited about logical decoding and start shipping row changes before they decide what an event should look like. That usually ends badly. One consumer expects full rows, another wants only changed fields, and a third needs business events such as "invoice paid" instead of raw table updates.
Define the event shape first. Decide what each message must contain, how consumers will read it, and which fields must stay stable over time.
Deletes cause a lot of quiet damage. Many teams handle inserts and updates, then forget deletes until a customer asks why old records still show up in search, cache, or a reporting table. If your downstream system cannot remove rows, your sync is incomplete.
Duplicates create the same kind of mess, just faster. A consumer can crash after it writes data but before it saves its offset. When it restarts, it may process the same change again. If your writes are not idempotent, one order turns into two shipments, or one user update creates two audit entries.
Slot lag is the mistake that turns into a bill. A replication slot keeps old WAL files until a consumer catches up. If nobody watches lag, disk usage climbs, backups get noisy, and the database starts feeling pressure for a problem that lives outside the app.
The warning signs usually appear early: consumers fall behind during normal traffic, downstream tables never delete old rows, replays create extra records, or different teams argue about what a change event means.
Another common mistake is mixing two jobs in one consumer. Audit logging and app integration sound similar, but they pull in different directions. Audit data should stay close to the original change and remain easy to trace. App integrations often need filtering, reshaping, retries, and business rules. Put both into one pipeline and every small change becomes risky.
I have seen this in startup advisory work more than once: a team uses one CDC consumer for audit, analytics, search indexing, and webhook delivery. It works for a month, then one rule change breaks three downstream systems. Separate consumers cost a bit more up front, but they save a lot of cleanup later.
Quick checks before you commit
Logical decoding pays off when change volume is high and the target system needs fresh data in seconds. If your tables change a few times an hour, a scheduled query with a good index may be easier to live with.
Start with numbers, not architecture diagrams. Count inserts, updates, and deletes on the tables you care about during a normal day and during peak periods. A table with 80 changes a day is a very different problem from one with 80,000 before lunch.
Then decide how fresh the downstream data really needs to be. If another system can be five or 10 minutes behind, polling may already meet the need. If support, billing, or fraud checks need near real time updates, logical decoding starts to earn its keep.
You should also test the simple path properly. Many teams assume polling is clumsy, but one indexed query on updated_at or a monotonic ID can work well for a long time. For one audit log or one internal sync, a narrow trigger or a small job may solve the whole problem with less code and less operational noise.
The hard part is not only reading changes. Someone has to watch replication slot lag, handle retries, replay events safely, and notice when a consumer falls behind. Small teams feel that cost fast, especially teams that keep infrastructure lean.
Before you commit, answer five plain questions. What are the daily and peak change counts on the tables that matter? How much delay can the target system tolerate? Have you benchmarked a polling query with the right index instead of dismissing it on instinct? Who owns slot lag, retries, and replay issues? And does a trigger or scheduled job already solve the use case you have today?
If those answers are vague, wait. CDC versus polling is rarely a debate about elegance. It is usually a choice between one more moving part now and one real limitation later.
What to do next
Start small on purpose. Pick one table and one consumer, then watch that path long enough to see normal traffic, a few edits, and at least one small mistake. A narrow test tells you whether logical decoding fits your real workload, not the one you imagined on a whiteboard.
Choose a table that matters but will not cause chaos if you pause the test. Orders, invoices, or account changes are usually easier to reason about than a giant catch all events table. Keep the first version boring.
Before you touch production, write the rollback steps in plain language. Decide who turns off the consumer, who pauses or removes the replication slot, how you switch back to polling, and how you verify that no changes were lost. If those steps live only in someone's head, the first incident will feel worse than it should.
A simple first pass is enough. Enable logical decoding for one source table, feed changes to one consumer, compare decoded changes with the current table state for a few days, run a failure drill, and record database load, slot lag, and consumer lag.
Those numbers matter more than opinions. After the failure drill, check how long replay takes when the consumer falls behind, how much load the database sees during catch up, and whether the downstream system can keep pace. A design that looks clean on day one can still hurt you if recovery takes too long after a restart.
If the test works, widen the scope one table at a time. Do not add three new consumers, schema changes, and backfill logic all at once. Slow growth is easier to debug and cheaper to reverse.
If your startup needs a second opinion on the trade offs, Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor and can help review the design, pressure test the rollback plan, and keep the system lean instead of adding moving parts you do not need.
Frequently Asked Questions
What is Postgres logical decoding in simple terms?
Postgres writes every committed change to the WAL. Logical decoding reads that stream and gives your app inserts, updates, and deletes in commit order, so you react to real changes instead of rescanning tables.
When should I keep polling instead of using logical decoding?
Use polling when change volume stays low and a few minutes of delay do not hurt. One worker, one checkpoint, and one indexed updated_at query usually stay easier to run than a CDC pipeline.
Why does polling work poorly for audit trails?
Polling often sees only the latest row state. If a row changes twice between checks, your job can miss the middle step. Logical decoding gives you each committed change in order, which makes audit timelines much clearer.
Does logical decoding lower database load?
Usually, yes. Polling keeps asking the database the same question, even when nothing changed. Logical decoding reads the next change from the log, so you stop doing repeated scans on busy tables.
Does logical decoding remove the need for application logic?
No. Logical decoding gives you raw database changes, not business meaning. You still need code for masking sensitive fields, shaping events, retries, conflict rules, and whatever your downstream system expects.
What can go wrong if I set up logical decoding badly?
Watch replication slot lag, WAL disk growth, consumer lag, and restart behavior. If the consumer falls behind, Postgres keeps old WAL files longer, and disk usage can rise fast.
How should I test CDC before I use it in production?
Start with one table and one consumer. Run it in staging, stop the consumer for a while, restart it, and measure catch-up time, duplicates, slot lag, and downstream delay before you widen the scope.
Should one CDC consumer handle audit logs, search, and webhooks together?
Split them. Audit logging and app integrations want different event shapes, retry rules, and failure handling. If you mix them in one consumer, one change can break several downstream jobs at once.
What should a good change event contain?
Include the table name, primary key, operation type, commit order, and the fields that changed. Add user or request context if people need to read the audit trail later, because row changes alone rarely tell the whole story.
Can I switch back to polling if logical decoding adds too much overhead?
Yes, if you plan for it. Write down how to stop the consumer, remove or pause the slot, return to polling, and verify that you did not lose changes. A rollback plan saves time when the first test gets messy.


