PgBouncer and prepared statements when traffic grows
PgBouncer and prepared statements often fail in quiet ways. Learn the pooling modes, driver traps, quick checks, and safe fixes before traffic grows.
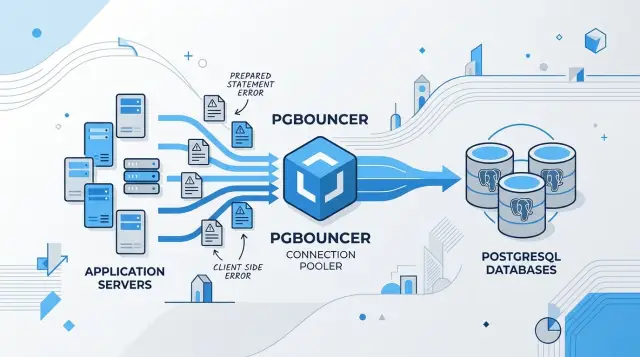
Table of Contents
Why this breaks after you add traffic
PgBouncer and prepared statements often look harmless in local testing. On a laptop, you might have one app process, a few requests, and a database session that sticks around long enough for everything to work. The bug stays hidden because nothing forces your code onto a different database connection at the wrong moment.
Production changes that. Many teams run PgBouncer in transaction pooling mode to keep PostgreSQL connection counts under control. In that mode, a request does not keep one fixed server connection. It gets a connection for a transaction, then PgBouncer puts that connection back in the pool.
That matters because a prepared statement lives on the PostgreSQL connection that created it. It does not live in your app process, and it does not follow a request when PgBouncer sends the next transaction to another backend. If your driver assumes the statement is still there, you get errors like "prepared statement does not exist". If the driver tries to create the same statement name again on a different path, you may see "already exists" instead.
Low traffic hides this surprisingly well. A quiet staging system may reuse the same few backend connections so often that the mistake looks harmless. Once traffic grows, requests spread across more pooled connections, timing shifts, and the errors start to look random. One request works, the next fails, and a retry passes.
That is why this bug feels slippery. The SQL can be correct. PostgreSQL can be healthy. PgBouncer can be doing exactly what you asked. The problem appears because the app, the driver, and the pool mode disagree about where session state lives.
A familiar example is an API that works for weeks, then starts failing only during busy hours. Nothing changed in the query. Traffic simply increased enough for transaction pooling to move requests across connections and expose an assumption that had been wrong from day one.
What PgBouncer pools
PgBouncer does not pool queries. It pools server connections to PostgreSQL. That sounds like a small detail, but it changes how your app behaves once many requests hit the database at the same time.
A typical app assumes it can talk to one database connection for a while. PgBouncer may keep that true, or it may swap that connection out between requests. The pool mode decides which behavior you get.
The three pool modes
In session mode, one client keeps the same server connection for the whole session. If your app creates a prepared statement, sets a session variable, or uses a temp table, that state stays attached to that client until it disconnects.
In transaction mode, PgBouncer gives your app a server connection only for the length of one transaction. After commit or rollback, it returns that connection to the pool. The next query may run on a different connection, with none of the earlier session state.
In statement mode, PgBouncer swaps connections even more aggressively. Each statement can run on a different server connection. That removes a lot of session behavior, so most apps avoid it unless the workload is extremely simple.
This is where prepared statements clash with pooling. A prepared statement usually lives on one PostgreSQL connection. If your app prepares a statement on connection A and the next execution lands on connection B, PostgreSQL has no idea that statement exists.
The pattern is simple. Request one prepares "get_user" and runs fine. Request two reuses the same client connection in the app, but PgBouncer sends it to another backend. The app tries to execute "get_user" again and gets an error because that prepared statement was never created on this new backend.
If you use session mode, prepared statements usually work as expected. If you use transaction mode, you need a driver setup that assumes session state can disappear after every transaction. In statement mode, you should assume most session based features will break unless you have tested them carefully.
What prepared statements really do
A prepared statement splits a database query into two steps. First, the app sends the SQL text to PostgreSQL and asks the server to keep it. Later, the app runs that statement again with new values, so it can reuse the same query shape instead of sending the full SQL every time.
That can save a little work on repeated queries. Think about a busy app that loads a user by ID, checks a session token, or inserts an order again and again. The SQL stays the same and only the values change.
The detail that trips teams up is where the prepared statement lives. A named prepared statement stays on one specific server connection. If the app prepared get_user on connection A, PostgreSQL only knows that name on connection A. Connection B has no idea what get_user means.
So the app thinks it created one reusable query. PostgreSQL actually stored it inside one backend session.
A plain query sends the full SQL each time. A named prepared statement stores SQL on one server connection and runs it later by name. An unnamed prepared statement is more temporary, but drivers handle it differently, which makes it less predictable.
That last part causes trouble. One driver may reuse the unnamed slot for the next execution. Another may prepare and execute in one step. Another may skip prepare on the server unless you turn on a setting. The SQL in your code can look identical while the wire behavior changes a lot.
Some drivers also wait before they prepare anything. They watch for the same query to run a few times, then switch to automatic prepare. That makes local testing misleading. A query may run as a plain statement during early tests, then turn into a named prepared statement only after traffic increases.
A small example makes the problem obvious. Suppose your app runs select * from accounts where id = $1 a hundred times per minute. At first, the driver sends it as a normal query. After the fifth or tenth repeat, the driver decides to prepare it and reuse a name. Your code did not change, but the conversation with PostgreSQL did.
That hidden switch is where many failures begin.
Driver behavior that causes surprises
Most teams do not break this setup on day one. The bug shows up later, when traffic rises and the driver quietly changes how it talks to PostgreSQL.
A common pattern looks harmless at first. The app sends the same query a few times, the driver crosses its automatic prepare threshold, and then it starts using a named prepared statement. That can work fine on a direct database connection. It often fails once transaction pooling sends the next request to a different backend.
Many drivers and ORMs enable this behavior without making it obvious. Sometimes you have to dig through driver docs, ORM settings, or a connection string option to find it at all.
That is why the bug feels random. Local tests pass, staging looks fine, and production starts throwing errors only after enough repeated queries push the driver into prepared mode.
Statement naming is another trap. Some drivers reuse short names like "stmt_1" or cycle through a tiny set of names across many requests. In transaction pooling, that can collide with whatever state already exists on the backend connection PgBouncer picked for the next transaction.
The usual result is one of a few familiar errors: "prepared statement already exists", "prepared statement does not exist", type mismatch errors after a name gets reused for a different query, or failures that appear only during retries and burst traffic.
Retries make this worse. A request may fail for one reason, retry cleanly at the app level, and then land on another backend connection. If the driver assumes its prepared statement still exists there, the retry fails for a reason that looks unrelated to the original error.
ORMs add another layer of confusion. They hide the driver setting, wrap the query path, and make it hard to tell whether they use plain queries, unnamed prepared statements, or named statements with caching.
Before release, check four things: whether automatic prepare turns on after a threshold, how the driver names statements, whether the ORM exposes the setting, and how retries behave after a connection hop. That small audit saves a lot of guesswork later.
Choosing a safe setup
Start with your PgBouncer pool mode. This one choice decides whether a client keeps the same PostgreSQL session or gets a different one on the next query. Session pooling usually works with prepared statements. Transaction pooling often does not, because the next transaction may land on another backend.
That is why this issue becomes real only after a service gets busy. Low traffic can hide it for weeks. Under concurrency, connection reuse gets more aggressive, and statement state starts drifting away from what the driver expects.
A safe setup usually comes down to four steps:
- Check whether your driver or ORM creates prepared statements on its own. Many do this quietly after the same query runs a few times.
- If the service must use transaction pooling, turn off prepare on the server for that path.
- If the service really needs prepared statements, move it to session pooling instead of hoping the driver will behave.
- Test with real concurrency. One local script that sends requests one by one will miss the bug.
A mixed setup is often the least painful option. A public API with many short requests can run through transaction pooling with prepare disabled. A background worker or admin service that keeps longer sessions can use session pooling.
Before release, add logs for prepared statement failures and pool waits. Watch for messages such as "prepared statement does not exist" or "already exists". Also watch request latency when the pool gets tight. Those two signals often show up before users report anything.
If you want one simple rule, use transaction pooling only with stateless query behavior. The moment a driver starts caching session state, either switch that service to session mode or turn the feature off.
A real failure pattern under load
A small SaaS API can look perfectly healthy for weeks. A few users log in, background jobs run, and queries return fast enough. The team adds PgBouncer with transaction pooling, sees lower connection pressure, and ships.
Then traffic jumps after a launch or a new customer rollout. Most requests still work, which makes the problem harder to pin down. A small share starts failing with errors like "prepared statement does not exist" or "prepared statement already exists". The same endpoint may fail once, then work fine on the next call.
The team often assumes one app connection maps to one database backend for a while. In transaction pooling, that is simply not true. PgBouncer can send each new transaction to any free backend.
The failure pattern is usually straightforward. The driver decides to prepare a query after it runs several times. One request prepares that statement on backend A. The next request reuses the app connection but lands on backend B. Backend B has no matching prepared statement, so the request fails.
Low traffic can hide this for a long time. With only a handful of users, the same backend often gets reused by chance, so nobody notices. More traffic breaks that luck. Backend reuse becomes less predictable, and the error rate climbs just enough to hurt customers without crashing the whole service.
That is why teams lose time on this bug. They check PostgreSQL settings, inspect slow queries, and blame random network issues. In many cases, the problem sits in one driver setting.
The fix is usually simple: keep transaction pooling, but stop the driver from using prepared statements on the server in that path. Depending on the driver, that means disabling automatic prepare, turning off the prepared statement cache, or forcing a plain query mode for pooled connections.
It is a little less elegant, but much safer. You keep the connection savings from PgBouncer, and the random failures disappear under load.
Mistakes that waste time
Most wasted time comes from checking the wrong path first. A team tests against a direct PostgreSQL connection, sees no errors, and assumes production is safe. Then traffic goes through PgBouncer and the failures start. The code did not change. The connection path did.
Another common mistake is blaming PostgreSQL first. In many cases, the database is fine. Check the PgBouncer pool mode and the driver settings before you inspect query plans or tune memory. If the app depends on session state, transaction pooling can break things in ways that look random.
This happens a lot when someone turns on transaction pooling to save connections, but the app still expects a stable session. Named prepared statements, temp tables, session variables, and some driver caches all assume that one client stays tied to one server connection. Transaction pooling does not promise that.
Teams also change PgBouncer and leave app defaults untouched. That is where automatic prepare bugs hide. A driver may start preparing a statement after the same query runs a few times. In development, this looks fine. Under load, the next transaction may land on a different backend connection, and the app starts throwing "prepared statement does not exist" or "already exists".
Deploys and failover events expose this fast. New connections come up, old ones drain, and cached assumptions fall apart. If errors appear only during releases, do not dismiss them as deploy noise. Those short bursts often reveal the real bug.
A quick check helps: test the full production path from app to PgBouncer to PostgreSQL, compare session and transaction pooling with the same workload, review driver settings for automatic prepare and statement caching, and run deploy and failover drills in staging.
Most of these problems come from mismatched settings, not one broken part. When the pool mode, driver behavior, and app assumptions line up, the strange errors usually disappear.
Quick checks before release
Small config gaps can stay hidden for weeks, then show up the day traffic gets real. This problem usually fails that way. Light testing looks fine, then pooled connections start reusing backend sessions in ways the driver did not expect.
Release checklist
Check each service one by one. Do not assume every app can share the same pool settings just because they all use PostgreSQL.
- Confirm the pool mode for every service. Transaction pooling is often where the trouble starts.
- Check whether the driver creates named prepared statements and whether it turns that on automatically after repeated queries.
- Run concurrent tests through the same PgBouncer entry point you will use in production. Direct database tests are not enough.
- Keep one fast rollback option ready, whether that means disabling prepared statements, changing pool mode for one service, or routing one app around PgBouncer.
A simple test catches a lot. Start two or three app instances, send repeated requests for the same SQL, and keep concurrency high enough that connections get reused. If the setup is unsafe, errors often appear within minutes instead of after a week of normal traffic.
Teams also waste time by testing with one process, one connection, and no PgBouncer in the path. That proves the query works. It does not prove the deployment works.
If you want a boring release, make rollback cheap. One config flag can save a late night.
What to watch after traffic grows
This issue often looks fine at low traffic, then starts failing in short bursts once more app instances, retries, and reconnects enter the picture. The pattern matters as much as the error count. A few random failures after each deploy can point to a different cause than a steady rise during peak hours.
Start by counting prepared statement errors per service and per deploy. If one service throws most of them, the bug is usually in that client, not in PostgreSQL itself. If the errors start right after a release, check what changed in the driver, connection settings, or retry logic before you blame PgBouncer.
Track pool wait time too. When wait time climbs, apps sit longer before they get a server connection, and timing bugs show up more often. At the same time, watch server connection churn. If connections open and close too often, prepared state disappears more often, and the errors look random even when the cause is stable.
A useful check is simple: compare prepared statement errors with retries, failover, and restarts on the same timeline. A restart may clear session state on the server. A retry storm can then hammer the same broken path and make a small issue look much bigger.
You should also test latency after disabling prepare for one service. Some teams expect a huge slowdown, but the real cost is often small for short queries. If errors disappear and latency barely moves, that service may be safer without automatic prepare.
A common pattern looks like this: an API runs clean for weeks, then fails only after a deploy plus a brief database reconnect. The deploy changes the client pool size, reconnects rise, and one driver starts reusing statements in transaction mode. The bug stays hidden until enough traffic hits that exact path.
Finish with a short review of which services still need session mode and which can stay in transaction mode without prepared statements. That list is small, but it saves hours when the next traffic spike arrives.
Next steps for a safer rollout
Traffic rarely breaks this setup on day one. Problems show up when one service uses session based behavior, another uses transaction pooling, and nobody wrote that difference down. The fix starts with a simple inventory: which apps need session features, and which can live with stateless pooling.
That inventory should include prepared statements, temp tables, session variables, and anything else that depends on a stable backend connection. A background worker may work fine behind transaction pooling, while an admin tool or migration job may need session mode. Putting both behind the same rules is a good way to create a bug that appears only under load.
A clean rollout usually means splitting traffic by behavior. Put stateless web traffic in one pool. Put jobs or tools that need session behavior in another. Keep driver settings close to app config instead of burying them in defaults, and review automatic prepare before you raise concurrency.
That last step saves a lot of time. Many teams tune PgBouncer, then forget that the driver still decides when to prepare, reuse, or rename statements. If those settings live next to the app config, developers see them during reviews and environment changes. They stop being hidden surprises.
A good release plan also tests failure, not only success. Restart PgBouncer in staging. Rotate connections. Push enough parallel requests to force pool reuse. If prepared statement errors appear only after churn, you found the real risk before users do.
If your stack includes several services, mixed drivers, or newer AI generated code paths, an outside review can be worth it. Oleg Sotnikov at oleg.is helps teams sort out problems like pooling strategy, driver behavior, rollout safety, and the move toward AI first development without turning infrastructure into guesswork.
Frequently Asked Questions
Why do I get "prepared statement does not exist" with PgBouncer?
This usually happens when your driver prepares a statement on one PostgreSQL connection, then PgBouncer sends the next transaction to another one. The SQL still looks fine, but the new backend does not know that statement name.
Can I use prepared statements with transaction pooling?
Not by default. Transaction pooling works best when each transaction acts like a fresh visit with no session memory. Named prepared statements keep session state on one backend, so they often break there.
Why does this work on my laptop and fail under load?
Local tests often reuse the same small set of backend connections by luck, so the bug stays hidden. Once traffic grows, PgBouncer spreads work across more connections and the wrong assumption shows up fast.
What is the simplest fix if I want to keep PgBouncer?
Start by turning off server-side prepared statements for the services that use transaction pooling. That keeps PgBouncer in place and removes the session state that causes the random failures.
When should I switch from transaction pooling to session pooling?
Use session pooling when that service really needs prepared statements, temp tables, or session variables. You trade some connection efficiency for stable session behavior, which often makes sense for workers, admin tools, or long-lived jobs.
Can my ORM cause this even if I never call PREPARE myself?
Yes. Many ORMs hide driver settings and may turn on automatic prepare after the same query runs a few times. That makes the app look fine in testing, then fail later when traffic crosses that threshold.
Why do deploys and retries make the errors look random?
They can. A retry may land on a different backend, and a deploy or failover often resets connections and clears session state. Those events expose the bug because they break whatever connection reuse looked stable before.
What else breaks in transaction pooling besides prepared statements?
Look at temp tables, session variables, advisory locks tied to a session, and any driver cache that assumes one stable backend. Transaction pooling swaps backends after each transaction, so those features often fail the same way prepared statements do.
How should I test this before release?
Run the test through the same PgBouncer entry point you will use in production and add real concurrency. Send the same queries many times from more than one app instance so the driver can switch into prepared mode and PgBouncer can reuse backends.
Will disabling prepared statements slow my app down a lot?
Usually not by much for short queries. In many apps, the small parsing cost matters less than random production errors, so plain queries give you a calmer system and a simpler rollout.


