Node.js webhook checklist for retries and signature checks
Use this Node.js webhook checklist to set up retries, signature checks, delivery logs, replay support, and idempotent handlers without gaps.

Table of Contents
Why webhook handling breaks so easily
Webhooks look simple. One service sends an HTTP request, your app receives it, and the job is done. Real traffic is messier. Networks slow down, servers restart, and a provider will often resend the same event if your endpoint does not answer fast enough with a clear success code.
That retry behavior is normal. A payment or billing service cannot assume your app handled the event just because it sent it once. If your server times out after 10 seconds, or returns a 500 error for a brief database issue, the provider usually tries again. Sometimes it tries again minutes later. Sometimes it does that several times.
This is where duplicate work starts. If your handler creates an invoice, sends a receipt, or marks an order as paid every time it sees the same event, one customer can get charged twice or receive three copies of the same email. The bug is often small: the code checks "did I get a webhook?" instead of "did I already process this event ID?"
Signature verification adds another sharp edge. Many providers sign the raw request body, not the parsed JSON object. If Express or another middleware changes the body before verification, even in a harmless way, the signature check fails. Extra whitespace, reordered fields, or automatic parsing can break it. Teams often waste hours on this because the payload looks correct in logs, but the raw bytes no longer match what the provider signed.
Weak delivery logs make all of this harder to debug. When an incident starts, you need to answer basic questions fast: which event arrived, how many times, what headers came with it, what your app returned, and whether the handler finished or crashed halfway through. If logs only say "webhook failed," you cannot tell whether the problem was a bad signature, a timeout, or duplicate processing.
A good Node.js webhook checklist starts with this reality: retries are expected, duplicates are normal, and vague logs turn a small bug into a long night.
What a safe webhook setup includes
A webhook endpoint should do five things in the right order. If you change that order, small bugs turn into double charges, missing updates, or support tickets that take hours to untangle. A good Node.js webhook checklist starts before business logic and ends with logs you can trust.
First, keep the raw request body exactly as it arrived. Many providers sign the raw bytes, not the parsed JSON object. If your Express or Fastify app parses the body too early, signature verification can fail even when the sender is real.
Then verify the signature before you trust anything in the payload. Check the shared secret, and if the provider sends a timestamp, check that too. Old signed requests should not pass forever.
After that, mark the event as seen before your app sends emails, updates orders, or writes billing records. Most teams store a provider event ID. If the provider does not send one, store a stable hash of the raw body plus a timestamp window. That one step makes idempotent handlers much easier to build.
A safe flow usually looks like this:
- Read the raw body and headers.
- Verify the signature and reject bad requests fast.
- Save the event ID or hash with a received status.
- Push slow work to a queue.
- Return a success response quickly and log the result.
The queue matters more than many teams expect. Email sending, third-party API calls, PDF generation, and large database updates should not block the webhook response. If the sender times out, it often retries, and now you have the same event racing through your app twice.
Logs close the loop. Keep one record per delivery attempt with the event ID, provider name, received time, response code, processing state, and error message if something failed. During an incident, that history tells you whether the sender retried, whether your app accepted the event, and whether the worker finished the job or stopped halfway.
If you only add one habit, add this one: treat every webhook as a message that may arrive late, twice, or out of order.
Node.js packages worth checking
You do not need a huge stack to make webhooks safe. In most Node.js apps, five tools cover the job: one web framework that preserves the raw request body, one way to verify signatures, one queue for retries, one logger, and one store for dedupe.
Express and Fastify both work well, but only if you keep the raw body before JSON parsing changes it. Signature checks often fail because a parser reformats the payload. In Express, teams usually save the raw buffer in middleware or use a raw parser for the webhook route. In Fastify, raw body support or a plugin gives you the same result.
For signature verification, start with node:crypto when the provider documents the algorithm clearly. It keeps the code small and removes one extra package. If the provider ships an SDK helper for signed webhooks, use it. Those helpers usually handle timestamp parsing and constant-time comparison better than hand-written code.
A queue helps when your handler does more than quick checks and one database write. BullMQ is a solid pick if you already run Redis and want retry delays, backoff, and job visibility. Bee-Queue is lighter and easier to keep in your head, though it gives you fewer extras.
Structured logs save real time during incidents. Pino is fast and simple. Winston also works, especially if the app already uses it. Log the provider, event ID, delivery ID, signature result, attempt number, handler outcome, and processing time.
For dedupe and locks, use the data store you already trust in production:
- Use
pgwhen you want durable idempotency records with unique constraints. - Use
ioredisfor fast duplicate checks and short-lived locks. - Use both if Postgres stores the truth and Redis handles retry bursts.
That setup is enough for a practical Node.js webhook checklist. It stays small, and it covers the failures that cause most duplicate work and missed events.
How to build the flow step by step
A webhook flow should do two things well: reject fake requests and avoid doing the same work twice. If either part is weak, small issues turn into refunds sent twice, orders marked paid twice, or hours lost during an incident.
Start at the HTTP edge. In Node.js, read the raw request body before any JSON parsing changes it. Many signature schemes depend on the exact byte content, so even harmless formatting changes can break verification. Keep the headers too, especially the timestamp, signature, and any event metadata the sender includes.
Next, check freshness and authenticity. Compare the timestamp against a short tolerance window, then compute the expected signature from the raw body and your shared secret. If either check fails, stop there and record the attempt in your delivery log with a clear status such as "invalid signature" or "expired timestamp".
After that, pull out the fields you need to track the event: a stable event ID, the event type, and the source system. Those three fields matter more than most teams think. They tell you whether this request is a retry, which handler should run, and where the event came from when two providers use similar names.
Before you touch business data, write a dedupe record keyed by the event ID and source. Do this first, not after processing. If two identical requests arrive a second apart, the second one should hit that record and stop. This is one of the most useful parts of any Node.js webhook checklist because it prevents duplicate work even when retries pile up.
Then enqueue the real work and return a 2xx response fast. Webhook senders usually retry when your endpoint stays open too long. A queue keeps the request path short and gives you room to retry downstream work safely.
When the worker picks up the job, process it with idempotent handlers. For example, if an order is already marked paid, do not mark it paid again and fire a second email. Update the delivery log as the job moves from received to queued to processed or failed. During a bad day, that log is what lets you answer one simple question fast: what happened to this event?
Delivery logs that help during incidents
When a webhook fails at 2 a.m., plain app logs rarely answer the first question: "What happened to this event?" You need a delivery log that shows each webhook as a traceable record, not a pile of scattered lines.
Start with identity. Save the provider event ID on arrival, then attach your own internal job ID when your app queues or processes the work. That pair solves a lot of confusion fast. The provider ID tells you what the sender thinks it delivered. Your job ID tells your team what your system actually did with it.
Time data matters just as much. Store the first receipt time, the last attempt time, and the retry count in the same record. During an incident, that tells you whether the problem is new, whether the sender keeps retrying, and whether your fix worked or the event is still bouncing.
Keep the outcome visible. For each attempt, record the HTTP response code, a short error message, and processing time in milliseconds. If a handler starts timing out after 8 seconds, you want to see that pattern in one screen. If signature verification fails, the error text should say that plainly instead of hiding it inside a generic "bad request".
Support teams also need fast search, not just raw data. Let them search delivery logs by customer ID, order ID, and event ID. A customer usually opens with "my payment went through but nothing updated." Support should be able to find the related deliveries in seconds, without asking an engineer to grep logs.
Status labels make the log easier to read under pressure. Mark events clearly as received, processed, duplicate, ignored, failed, or replayed. Those labels stop people from guessing. A duplicate event and a replayed event may look similar in traffic, but they mean different things when you investigate.
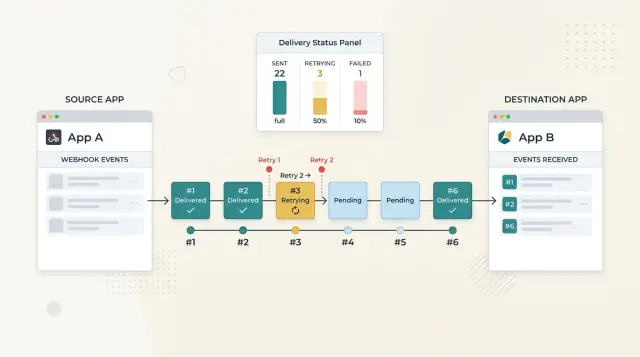
A small example makes this concrete. If an "order.paid" webhook arrives three times, your log should show one provider event ID, one order ID, first seen at 10:02:14, last attempt at 10:06:41, retry count 2, one successful job ID, and later attempts marked duplicate. That is the sort of record that ends an incident faster than any dashboard chart.
Replay support without repeat damage
Manual replay is worth adding because failed events do not always mean bad data. Sometimes your app restarts at the wrong moment, a queue stalls, or a database lock slows one request too long. A replay button in your delivery logs gives support and engineers a safe way to try again without waiting for the sender.
Replay should not use a shortcut path. Use the same raw payload, headers, and event metadata that came with the original request, then run the same signature verification and source checks again. If your system did not store enough data to repeat those checks, do not guess. Refuse the replay and mark the event as not replayable.
Keep one execution path
The safest setup is simple: the live webhook and the manual replay both call the same handler. That handler checks whether the event already changed state before it does anything else. If a payment event already marked an invoice as paid, the replay should record "already applied" and stop. It should not send another receipt, create another ledger entry, or notify the warehouse twice.
This is where idempotent handlers earn their keep. They make replay boring, which is exactly what you want.
Store a small audit trail every time someone replays an event:
- who started the replay
- why they did it
- when they ran it
- which event they replayed
- what the result was
That record helps during incidents. It also stops the quiet mess where three people retry the same event and nobody knows why the customer got duplicate emails.
Set an expiry rule
Old events can do more harm than good. A replay from six months ago may point to deleted records, old business rules, or a schema you no longer support. Pick a clear cutoff and enforce it. Many teams use a short window such as 7, 14, or 30 days, then require a manual data fix after that.
If you add only one thing from a Node.js webhook checklist, make it this: replay is useful only when it is verified, logged, and safe to run twice.
A simple order-paid webhook example
A payment provider sends order.paid to your Node.js app. The first delivery reaches your server, but the provider times out before it sees your response. It tries again a few seconds later, so your app gets the same event twice.
Your first check is the signature, and it has to use the raw request body. If you parse JSON first, even a small change in spacing or field order can break the hash check. In practice, the route reads the raw payload, compares the provider signature with your own HMAC result, and rejects the request fast if they do not match.
After that, the handler stores the provider event ID in a dedupe table with a unique constraint. Think of rows like evt_10492, event type, order ID, received time, and status. If the insert works, the event is new and your app can queue work. If the database says that ID already exists, you stop there and return success so the provider does not keep retrying.
The actual order update should happen in a worker, not in the webhook route. The worker loads the order, checks whether it is already paid, and only then changes the status and sends the receipt. That step matters because retries, manual replays, and queue redelivery can all happen later.
A simple flow looks like this:
- verify signature on the raw payload
- insert event ID into the dedupe table
- queue a job for order processing
- mark the order as paid once and send one receipt
Your delivery log should make the outcome obvious during an incident:
10:02:14 received order.paid evt_10492 for order_781
10:02:14 signature ok
10:02:14 dedupe insert ok
10:02:15 worker marked order_781 as paid
10:02:16 receipt sent
10:02:21 received order.paid evt_10492 for order_781
10:02:21 signature ok
10:02:21 duplicate event, skipped
That is the result you want: one real success, one harmless duplicate, and no second receipt in the customer inbox.
Mistakes that cause duplicate work or lost events
Most duplicate work starts with one bad assumption: a 200 response means the event is safe. It does not. If your process crashes before you store the event, the sender thinks delivery succeeded, but your app forgets it ever happened.
A safer pattern is boring on purpose:
- read the raw body first
- verify the signature against those exact bytes
- store the event ID and request details in shared storage
- return 200 only after that write succeeds
- do the slow work in a background job
The raw body part trips up a lot of Node.js teams. Signature verification often uses the exact request bytes. If middleware parses JSON first, it can change spacing, field order, or encoding. Your check fails, or worse, you skip the check because it feels flaky. In Express, this usually means you capture the raw payload before express.json() touches it.
Another common mistake is doing side effects inside the request handler. If that handler sends an email, writes to several tables, or calls another API, a timeout can leave you in a half-done state. The provider retries. Now the customer gets two emails, or the same order ships twice.
Keeping dedupe records only in memory fails the moment you restart the app or run more than one instance. One server remembers the event. Another one does not. Store dedupe data in a database or Redis, and put a unique rule on the event ID when you can.
Logging can make a bad day much worse. If your logs only say "signature failed" or "job error," you will waste an hour guessing which request broke. Log the provider event ID, your request ID, the attempt time, and the handler result. That small habit makes delivery logs and replay work much easier.
If you want a simple test for your Node.js webhook checklist, kill the app right after receipt, resend the same event three times, and see what happens. Good handlers stay calm. They store once, process once, and tell you exactly why if something goes wrong.
Quick checks before launch
A Node.js webhook checklist only matters if you test the messy cases, not just the first successful request. Run these checks in staging with real signatures, real retry rules, and the same queue and worker setup you plan to use in production.
Before release, prove these five points:
- You can replay one failed event from the delivery logs and watch it finish cleanly. If replay needs a manual database fix first, the flow is still fragile.
- Two copies of the same event leave the system in the same state as one copy. One order should stay one order, one refund should stay one refund, and one email should stay one email.
- You can trace a single event from receipt to worker result. Start with the provider event ID, then follow it through validation, queueing, processing, and final status.
- Retries stop after a fixed limit. After that, the event should move to a review bucket or dead letter queue, not keep failing forever.
- Alerts fire when failures start stacking up. Force several bad deliveries in a row and confirm that someone on the team actually gets the warning.
A short drill catches a lot. Send an "order.paid" event with a valid signature. Send the same event again. Then send one with a broken payload or bad signature. Your logs should show the first event succeed, the duplicate get ignored without damage, and the bad request fail for a clear reason.
Time matters too. A webhook can pass basic tests and still fail under pressure if workers lag or retries pile up. Watch how long one event takes from receipt to final result, and watch what happens when ten arrive together.
Teams often skip these checks because the main flow already works. That is usually a mistake. Most webhook incidents come from duplicates, weak tracing, or retries that never stop. Catch those before launch, and your first production incident gets much smaller.
What to do next
Start small. Pick one webhook, such as order_paid, and draw its full path on paper: receive the request, verify the signature, save the raw payload, check the event ID, push work to a queue, run the handler, and record the result. Most teams skip this step, then end up debugging blind when retries stack up.
Make three early choices and keep them boring: one queue, one log format, and one dedupe store. Mixing tools too soon makes incidents harder to read. A simple Redis record or a Postgres table for processed event IDs often works better than a clever setup nobody trusts under pressure.
A Node.js webhook checklist only helps if you test the ugly cases, not just the happy path. Break your flow on purpose and see where it bends.
- Send a request with a bad signature and make sure your app rejects it fast.
- Force a timeout and check that webhook retries do not create double work.
- Replay the same event ID several times and confirm the handler exits without doing the job again.
- Read your delivery logs and ask if another developer could explain the failure in five minutes.
If you only finish one thing this week, finish that test loop for a single event before you add more providers. One clean webhook path teaches more than ten half-built endpoints.
Keep the system easy to inspect. You want logs that show when the request arrived, what signature check happened, whether the event entered the queue, and why the handler accepted or skipped it. When an incident hits, plain records beat clever guesses.
If your team wants a serious review, Oleg Sotnikov can help shape webhook flows, retry queues, and idempotent handlers as a Fractional CTO. That kind of review can catch the missing guard that turns one retry into a customer bug.