Node.js libraries for event-driven apps that stay portable
Compare Node.js libraries for event-driven apps with retries, outbox flows, and clean local testing, so your code can move between brokers.
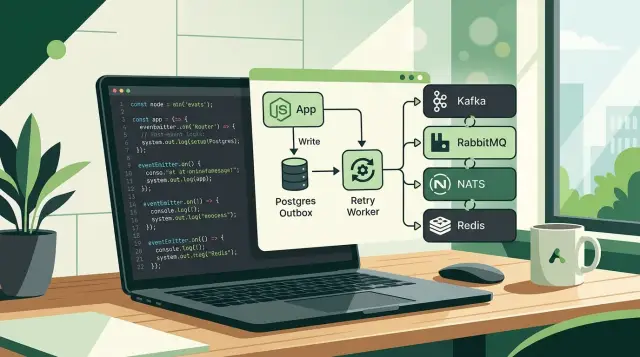
Table of Contents
Why broker lock-in becomes a problem
Lock-in usually starts as a convenience choice. A team picks Kafka, RabbitMQ, or Redis, then puts broker calls straight inside order logic, billing code, and background workers. It feels fast at first. A few months later, the app no longer talks about events in a simple way. It talks about topics, exchanges, routing rules, and retry queues from one broker.
That changes how people write code. Instead of publishing a plain domain event and letting an adapter handle delivery, developers start shaping business rules around broker features. A refund handler may depend on Kafka partition behavior. An email worker may assume RabbitMQ dead-letter handling. At that point, the broker is no longer just infrastructure. It is part of the product logic.
Local work gets painful too. A simple test run now needs Docker Compose, seed scripts, broker setup, and often one more tool to inspect messages. New developers spend too much time trying to boot the stack. They spend less time checking whether the code does the right thing.
Retries make this worse. One service retries with broker delays, another uses setTimeout, and a third stores failed jobs in a table and polls later. Idempotency checks end up scattered across handlers, controllers, and cron jobs. The system may still run, but failures become hard to reason about because every path follows a different rule.
The expensive part shows up later, when the team wants to switch. Maybe Kafka feels too heavy for a smaller product. Maybe Redis jobs are fine at first, but later you need better delivery guarantees or clearer audit trails. If business code calls the broker everywhere, the change is not a simple adapter swap. Developers have to touch handlers, tests, retry logic, observability, and deployment scripts at the same time.
That is why broker neutral Node.js architecture matters. If your app describes events once and hands delivery to a thin adapter, a broker change stays boring. If it does not, the broker becomes part of your codebase, and every future change costs more than it should.
How to keep your app broker neutral
Portability starts with the event itself. Define domain events as plain TypeScript objects that describe something your business knows happened, such as OrderPaid or InvoiceSent. Keep the payload focused on business data. If the event only makes sense because a specific broker adds special fields, your app already depends on that broker.
Use the same schema when you send and receive events. Zod or TypeBox both fit well here. Validate before publish, then validate again in the consumer. That sounds repetitive, but it saves time when one service changes a field name or sends the wrong shape. It also makes local event-driven development much easier because you can test handlers with plain objects.
Most teams only need a very small boundary between app code and messaging code:
- a
publish(event)function - a
subscribe(eventName, handler)function - one schema per event type
- one adapter for each broker
That boundary matters more than the broker client. Your order service should call publish, not a Kafka or RabbitMQ SDK directly. If you move from Redis streams to NATS later, you replace an adapter instead of rewriting business logic.
Keep delivery metadata out of business code. Retry count, message ID, delay settings, partition info, and dead-letter details belong in an envelope or transport layer. Your handler should care about orderId and paidAt, not broker headers.
Write handlers so they can run twice without causing damage. Duplicate delivery happens in every serious system. A payment event handler can check whether it already marked the order as paid before it sends another receipt or updates stock again. That one habit makes broker changes much less risky, because different systems retry and redeliver in different ways.
Small event libraries inside one service
A lot of event-driven design starts inside one Node.js process, not with a broker. Many Node.js libraries for event-driven apps are most useful at this stage, because they help you separate actions from reactions before you commit to Kafka, NATS, or anything else.
EventEmitter2 works well when one action should trigger several internal handlers. Its wildcard listeners are handy if you name events in groups like "user." or "billing.invoice.", because logging, metrics, or audit code can subscribe without getting mixed into the main business logic.
Emittery is a good option when you want something smaller and async by default. The API is simple, and promise-based listeners make it easier to see when a handler does real work, such as sending an email or updating a cache.
These libraries should stay inside one process. They do not move messages between containers, they do not survive a restart, and they do not give you delivery guarantees. If your app runs in three Node.js instances, each instance has its own local bus.
That limitation is useful, not annoying. A local event layer gives you a seam: your service can emit clear business events now, and later you can route some of those same events to an outbox table or a broker with less rewiring.
A simple example helps. When a user signs up, your app can emit "user.created" once, then let separate handlers send a welcome email, create default settings, and write an audit record. The signup code stays small, and you learn which events are stable enough to keep when the system grows.
If you need retries across restarts or cross-service delivery, add those later. First, make the event names and payloads clean inside the service.
Broker clients you can swap later
The first broker client often leaks into everything. Soon your handlers know about Kafka partitions, RabbitMQ routing keys, or Redis stream IDs. When that happens, changing brokers gets expensive fast.
Pick the client that fits your current setup, then hide it behind one small adapter.
- Use kafkajs when Kafka already exists in your stack. It gives you the consumer group and admin features most teams need, without forcing business code to care about offsets.
- Use amqplib when you need RabbitMQ and full AMQP control. It is low level, which is useful, but that low level API should stay near the transport layer.
- Use nats when you want a smaller client surface. It is quick to understand and works well for simple publish-subscribe or request-reply flows.
- Use ioredis for lightweight pub-sub or Redis Streams tests. It is handy for local work and early experiments, but do not let Redis-specific behavior shape the whole app.
A good adapter stays boring. It usually needs only a few methods, such as publish, subscribe, and maybe ack if your delivery model needs it. Keep message names, payload validation, serialization, headers, and retry metadata inside that adapter.
Your order service, billing service, or email worker should receive plain data and return plain results. They should not know which client connected, how a message was encoded, or which broker handled delivery.
That boundary pays off in tests too. You can swap the real client for an in-memory fake and check that handlers react to events, not transport details. Teams that run lean infrastructure often rely on this pattern because it keeps local development simple and avoids a rewrite when the broker choice changes later.
Tools for retries and delayed jobs
Retries sound simple until each handler invents its own rules. One job waits 5 seconds, another retries forever, and a third hides the real error in logs. Put that logic in the worker layer instead. Your business code should decide whether an action is safe to retry. The queue should decide when and how often.
BullMQ is a practical pick when Redis already runs in your stack. It gives you delayed jobs, retry counts, backoff, concurrency control, and failure handling without much setup. For tasks like "try payment capture again in 10 minutes" or "send a follow-up email tomorrow," it feels direct and easy to reason about.
If you want fewer moving parts, Postgres-backed workers are often easier to live with.
- pg-boss fits teams that already trust Postgres for durability and do not want to add Redis just for jobs.
- Graphile Worker stays very simple in local development and works well when your app already centers on Postgres.
- BullMQ usually fits better when you expect heavy job volume or already use Redis for caching and sessions.
These are useful Node.js libraries for event-driven apps because they solve timing and retry problems without pushing retry code into every handler.
A payment sync worker should not contain hand-made loops and sleep calls. Set max attempts, delay rules, and backoff in one place. Then the handler can stay small: load data, call the API, save the result, throw on failure.
Also store the attempt count and last error. Support teams need to know if a job failed once because of a timeout or failed six times because the remote API kept rejecting it. That small bit of history saves real time when something breaks.
Graphile Worker and pg-boss are especially pleasant on a laptop because one Postgres instance is often enough. BullMQ is fine locally too, but only if your team already runs Redis in dev and test.
Ways to handle the outbox pattern
The outbox pattern fixes a common failure: your app saves a record, then crashes before it publishes the event. To avoid that split, write the business change and the outbox row in the same database transaction. If an order row goes in, the event row goes in too. If the transaction fails, neither one stays behind.
Most teams build this with the database layer they already use. Prisma, Drizzle, Knex, and TypeORM can all save domain data and an outbox record together. Keep that table simple: event name, payload, aggregate ID, created time, status, and maybe a retry counter. Plain tables are easier to debug at 2 a.m.
After that, run a poller. It reads new outbox rows, publishes each event, and waits for the broker to accept it. Only then should the app mark the row as sent. If publish fails, leave the row pending or record another retry attempt. That gives you a clear recovery path and keeps the Node.js outbox pattern boring in the best way.
A simple order flow looks like this:
- Save the order and outbox row in one transaction.
- Poll for unsent rows every few seconds.
- Publish the event.
- Mark the row sent after broker confirmation.
If Postgres already sits at the center of your stack, pg-boss or Graphile Worker can save a lot of time. Both fit well when you want retries, scheduling, and local testing without adding another moving part on day one. For many small teams, that is the right trade-off: fewer systems, easier debugging, and a path to switch brokers later if the app grows.
Set up local development in small steps
You do not need Kafka on day one. For local event-driven development, start with Postgres or Redis and a small worker process. That gives you enough to model events, retries, and the Node.js outbox pattern without adding four more things to debug.
A simple setup usually has three services:
- the app that writes business data and event records
- the worker that reads events and delivers them
- Postgres or Redis for storage and queues
Docker Compose makes this easy. One command should start the whole stack, so a new developer can run the app, trigger an action, and watch an event move through the system in a few minutes.
Make failure visible
Local setups break in quiet ways. A message fails, disappears into logs, and nobody notices. Save failed deliveries in a table or queue that people can inspect with a normal query. Add the error, retry count, next attempt time, and the event payload.
That small step pays off fast. When someone changes a schema or breaks a handler, the team can see what failed instead of guessing.
A seed script also helps more than most teams expect. It should create a few realistic records and publish sample events such as "order.created" or "invoice.sent". Good seed data turns a blank local environment into something you can test in under a minute.
Test one ugly case
Run one test that kills the broker or queue connection in the middle of delivery. Then check that your worker retries, waits, and does not lose the message. If that test fails, your local setup is telling you something useful early, while the fix is still cheap.
This is where many Node.js libraries for event-driven apps either feel practical or annoying. A good library lets you run this failure test without special cloud services, hidden daemons, or a pile of config files.
Keep the first version boring. If Postgres plus a worker handles your local flow cleanly, add RabbitMQ or Kafka later only when your traffic or team size gives you a real reason.
A simple order flow example
A portable event flow starts in the database, not in the broker. Imagine a checkout service that takes payment, saves the order, and inserts one more row into an outbox table in the same transaction. That row might include an event ID, the event name "order.paid", the order ID, and the payload the rest of the system needs.
That small detail matters. If the app saves the order but crashes before it publishes the event, the outbox row is still there. Nothing gets lost, and you do not depend on broker-specific transactions to stay safe.
A worker process then polls the outbox table, picks up unpublished rows, and sends them through a thin adapter. The adapter hides the broker client, so the worker calls one method like publish(eventName, payload). Behind that method, you can point the same flow at Redis today and RabbitMQ, NATS, or Kafka later.
The email service subscribes to "order.paid" and sends a receipt. Real systems fail in boring ways, so this service should treat temporary errors as normal. If the email provider times out, the service retries after a short delay. If it receives the same event twice, it checks the event ID against a small processed-events table and skips the duplicate.
A clean version of the flow looks like this:
- Checkout saves the order and the outbox row together.
- The worker reads pending rows and publishes through the adapter.
- The email service retries temporary failures.
- The email service ignores duplicate deliveries.
This setup stays simple in local development too. You can run the checkout app, database, worker, and email consumer on one machine, then swap only the adapter when you want to test another broker. That is the practical side of broker neutral Node.js architecture: the business flow stays the same while the transport changes.
Mistakes that make switching expensive
Many Node.js libraries for event-driven apps look portable at first. The trouble starts when app code learns too much about one broker and too little about the event itself.
A common mistake is calling a broker SDK from controllers or service methods. An Express route that imports a Kafka or NATS client feels harmless on day one. Six months later, publishing logic sits in ten files, error handling differs in each place, and every migration turns into search-and-replace plus bug hunting.
Retry logic causes the same kind of mess. Some teams hide retry loops inside handler code with custom sleeps, counters, and catch blocks. That works until you need different retry rules, delayed processing, or dead-letter handling. Put retry policy outside business logic whenever you can. A handler should decide whether work succeeded, failed, or should wait. It should not manage its own mini scheduler.
Event names also age badly when teams skip versions and schema checks. "order.created" is fine for a start, but changes pile up fast. One service sends a new field, another still expects the old shape, and nobody knows which payload is safe. A small version rule and a schema check save a lot of pain later.
Broker-specific features are another trap. If you build around one product's exact delay queues, routing rules, or delivery guarantees too early, you stop owning the design. The broker owns it. Keep those features at the edges until you know you truly need them.
The most expensive mistake is skipping idempotency. Then every retry feels dangerous. A payment handler that can safely ignore the same event twice is much easier to move, test, and trust. If retries scare the team, the design is already brittle.
A simple rule helps: keep broker code thin, keep event contracts explicit, and make handlers safe to run more than once.
Quick checks before you choose
A library can look fine in a demo and still cause real pain later. The fastest way to spot trouble is to test how it behaves on a normal laptop, in CI, and during failure. That tells you more than a feature list.
When you compare Node.js libraries for event-driven apps, keep the checks boring and practical:
- Start the whole app with one command. If local setup needs a long README, extra shell scripts, and manual topic creation, people will skip it.
- Hide the broker behind one adapter. Your app code should publish and consume through your own interface, not call one vendor client from every file.
- Assume duplicate delivery. If a handler sees the same event twice, it should not charge twice, send two emails, or write two rows.
- Give support people a place to inspect failures. A clear log line helps, but a small table for failed deliveries helps even more.
- Test the unhappy paths in CI. Publish, retry, dead-letter, and permanent failure should all run in automated tests.
A small example makes this obvious. If an "order.paid" event times out and your worker retries it, do you create one invoice or two? If you switch from one broker to another, do you change one adapter file or twenty service files? Those answers tell you how portable your design really is.
I would also check how much the package assumes about your stack. Some tools quietly pull you into one queue, one cloud pattern, or one storage model. That may be fine for a small side project. For a product team, it gets expensive fast.
If you need a rule, pick the tool that makes local development easy, failure visible, and replacement boring. Fancy features matter less than that.
Next steps for your team
If you are comparing Node.js libraries for event-driven apps, do not make the choice bigger than it needs to be. Start with one package for in-process events and one tool for background delivery. That gives your team a clean place to publish events now, while keeping retries and delayed work out of request code.
A small team usually moves faster with a short plan like this:
- Pick one event library for use inside a single service.
- Pick one job or queue tool for retries, delays, and backoff.
- Write one adapter layer between your app and the broker client.
- Add one real flow end to end, then test failure cases on purpose.
Code review matters more than the package list. If an event changes state, reviewers should see the contract, retry rules, idempotency check, and failure path in the same pull request. Hidden retry logic causes expensive bugs. So does vague event naming.
Do not rush to prove your app is portable by swapping brokers on day one. First prove that your boundary is real. Run the same flow through your adapter in tests, keep broker-specific code in one place, and make sure your handlers stay boring. If changing brokers means touching business logic, the boundary is not done yet.
A simple checkpoint helps: one event schema, one retry policy, one idempotency rule, one local setup script. If your team can explain those four things in five minutes, your design is probably in good shape.
If you want an outside review before the system grows, Oleg at oleg.is offers Fractional CTO help for software architecture, infrastructure, and practical automation. That kind of review is most useful early, when the cost of changing direction is still low.


