Nginx upload buffering: fix random failures on large imports
Nginx upload buffering affects temp files, body limits, and timeouts. Learn simple settings to stop large imports from failing at random.
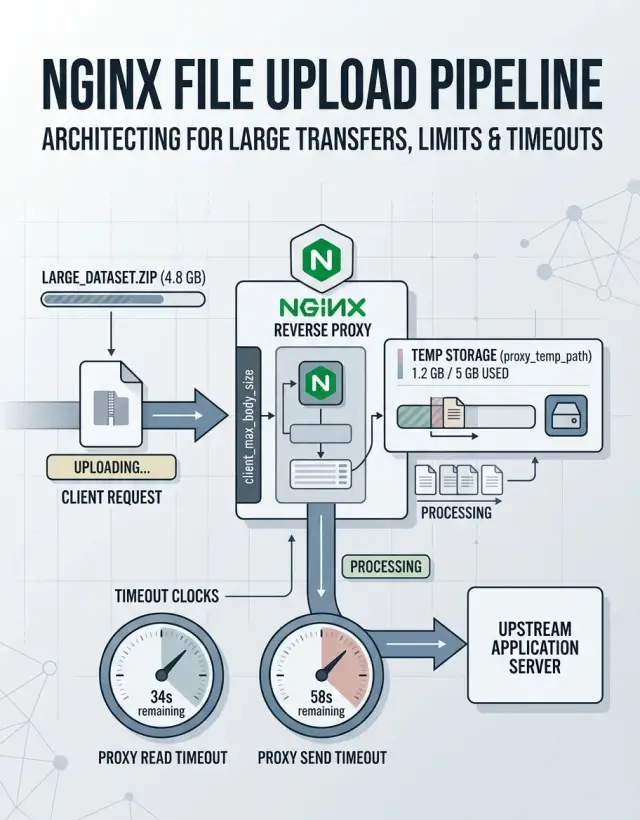
Table of Contents
Why large uploads fail at random
Large uploads fail in ways that seem random because the file does not travel through one simple path. A 5 MB file might pass every time, while a 500 MB import hits a size limit, fills temporary storage, or takes too long on a slow connection. The behavior feels inconsistent even when the rule is strict.
That is why one person can finish the upload while another gets an error a few minutes later. The difference often has nothing to do with the import code. It is usually network speed, file size, free disk space for Nginx temp files, or a timeout expiring before the upload finishes.
One of the most confusing parts of upload buffering is that your app may never see the failed request. Nginx usually reads the request body first. If it rejects the upload because the body is too large, the client is too slow, or temp storage runs out, the request can die before your app logs anything useful. Teams then search application logs, find almost nothing, and assume the bug is deeper than it is.
Temp storage causes a lot of this confusion. Nginx may keep part of the upload in memory and write the rest to disk before passing data upstream. Small files hide the problem. Larger imports expose it. The temp area fills up, shared storage gets crowded, or disk I/O slows down enough to trip a timeout.
Slow connections make the pattern even harder to spot. A user on a fast office line may upload the same file that fails every time for someone on weak Wi-Fi or a mobile hotspot. The file is fine in both cases. One client sends fast enough, the other does not.
A simple pattern usually shows up once you compare a few failed and successful uploads. Look at file size, total upload time, free space in Nginx temp storage, network quality, and whether the app receives the request at all. If small files work, larger ones stop halfway, and application logs stay quiet, start with Nginx before you blame the import code.
What Nginx does before your app sees the file
When someone uploads a 500 MB CSV, your app is often idle for most of that time. Nginx usually reads the request body first, decides where to keep it, and only then passes it to your backend.
By default, Nginx does not hand each byte straight to your app as it arrives. It buffers the body. A small part may stay in memory, but larger uploads spill into temp files on disk. Those files usually go to the path set by client_body_temp_path.
This is where a lot of "random" failures begin. If the temp disk is slow, full, or shared with other busy work, the upload can fail before your code runs. The app looks fine in logs because it never received the file.
Nginx also checks size limits early. If the request is larger than client_max_body_size, Nginx rejects it before the app sees a single byte. That is why a user can get a 413 error while your backend shows nothing.
Timing matters too. One timeout covers how long Nginx waits while the client sends the upload. Other timeouts cover the connection to the app and how long Nginx waits for a response after it forwards the request.
The basic flow is simple: the client starts sending the file, Nginx reads the body and checks size rules, Nginx stores the body in memory, on disk, or both, and only after that does it pass the request to the app.
That last step catches many teams off guard. A slow upload can spend minutes inside Nginx while the app does nothing yet. If a timeout fires or temp storage fills up first, the import fails and your app never gets a chance to handle it.
Picture a user uploading a large ZIP over weak Wi-Fi. Nginx reads it slowly, writes part of it to temp storage, and forwards it only when the body is ready. If the upload stalls for too long, or disk space runs out, the request ends there.
Start with the settings that fail most often
Most upload failures come from the same small set of settings. When one of them is too small, too short, or points to the wrong disk, imports break only for some files or some users.
Start with client_max_body_size. If a user sends a 220 MB file and Nginx allows only 100 MB, the request stops before your app gets anything. This is easy to miss because small test files work fine, then real customer imports fail with a 413 error or a vague browser message.
Next, check client_body_buffer_size. This is not the total upload limit. It controls how much of the request body Nginx keeps in memory before writing to disk. If the buffer is too small for your traffic pattern, Nginx will use temp files more often. That is normal, but it makes disk speed and free space much more important.
client_body_temp_path deserves special attention. Put it on a disk with enough space, stable permissions, and predictable performance. Leaving it on a tiny root volume is a common mistake when users upload large CSV, ZIP, or media files. A full temp area creates failures that look random because they depend on timing and file size.
Slow users need enough time to send the body. client_body_timeout controls how long Nginx waits between read operations. If someone uploads over weak mobile data or hotel Wi-Fi, a short timeout can kill a valid import halfway through.
After the upload finishes, the app may still need time to parse, unzip, validate, or write rows to the database. That is where upstream timeouts matter. If Nginx waits only 60 seconds for a response but your app needs three minutes to process a large import, the user still sees a failure even though the file arrived.
A practical baseline looks like this:
client_max_body_size 250m;
client_body_buffer_size 512k;
client_body_temp_path /var/lib/nginx/body 1 2;
client_body_timeout 120s;
proxy_read_timeout 300s;
proxy_send_timeout 300s;
Work through the basics in order. Match client_max_body_size to real file sizes, make sure the temp path has free space and correct permissions, set client_body_buffer_size with memory limits and upload volume in mind, increase client_body_timeout for slow senders, and raise upstream timeouts if parsing starts only after the upload ends.
If one import works at 20 MB but fails at 180 MB, the app should not be your first suspect. Nginx usually tells the story first.
Tune temp storage step by step
Large imports often fail because Nginx writes part of the request body to disk before your app reads it. When that disk is small, full, or busy, the upload fails in a way that looks random.
Temp storage is often the first thing to check. Start by finding the real path Nginx uses for request body temp files, not the path you assume it uses from an old note or a stale config file.
Start with the actual temp path
Look for client_body_temp_path in the live config:
nginx -T | grep client_body_temp_path
Then check free space on that volume during a real upload. Watch the disk while someone uploads a file that usually fails. A 2 GB import does not just need room for one file. If two or three users upload at the same time, space disappears fast.
Small root volumes cause a lot of trouble here. Logs, package updates, and upload temp data often compete for the same disk. When they share space, one noisy service can break imports for everyone else.
If that is your setup, move temp files to a larger disk and keep them separate from logs when you can:
client_body_temp_path /data/nginx/client_temp 1 2;
Create the directory, give the Nginx user permission to write there, then reload Nginx. Keep the change small. Do not change limits, timeouts, and temp storage in one push or you will not know which fix helped.
Test one size at a time
A simple routine works better than a big retest:
- Upload one file size that already fails, such as 200 MB.
- Watch disk space, disk activity, and the Nginx error log.
- Repeat the same upload twice after each change.
- Move to a larger file only after the smaller one works.
- Add one concurrent upload and test again.
It feels slow, but it saves time. Most "random" failures stop looking random once you watch the temp disk during real uploads.
Set body limits that match real imports
A body limit should come from real upload sizes, not guesswork. Check import logs, support tickets, or sample customer files and find the size that covers normal use. If most imports stay under 80 MB and a few reach 120 MB, set the limit for that range. Do not jump straight to 2 GB because one person asked for it once.
Nginx applies request body rules before your app can process the file. If the limit is too low, Nginx rejects the request early and users see failures that seem random, especially when file sizes vary from customer to customer.
Leave some room for multipart form overhead. A browser upload is not just the raw file. The request also includes form boundaries, field names, and headers. The overhead is usually small, but a limit set exactly to the file size can still fail. A simple rule works well: add 10% to 20% above the largest normal file, round up to a clean number like 100 MB or 250 MB, and keep the cap close to real use.
Every layer needs the same limit story. If Cloudflare, a load balancer, Nginx, and your app all use different limits, the smallest one wins. That is why these failures often get blamed on the app even when the request never reaches it. Check the limit in every proxy, then match the app setting for request size or import size.
When a file is too large, tell the user clearly. Return a plain message that gives the maximum allowed size and, if possible, suggests a smaller export or a split import. A clean 413 response is much better than a timeout, a dropped connection, or a generic "upload failed" message.
If you run import systems for clients with very different file sizes, use separate routes or server blocks instead of one huge global limit. That keeps ordinary endpoints tighter and reduces abuse risk. This is also a practical approach in production systems Oleg Sotnikov reviews: set limits from actual traffic, then raise them only where there is a clear need.
Choose timeouts for slow networks
Large imports usually fail for two different reasons, and the fix depends on which one you are seeing. Sometimes the user uploads over a weak connection and Nginx gives up before the body finishes. Other times the upload succeeds, but the app needs extra time to unpack, validate, or import the file.
client_body_timeout covers the first case. It controls how long Nginx waits between chunks of the request body from the client. A user on hotel Wi-Fi or mobile data may pause long enough to hit the default, even when the file would finish if you gave it a bit more time.
For upload-heavy apps, raising client_body_timeout to something practical often helps. Start with a moderate number, not an extreme one. For example, 120s or 180s gives slow connections room to breathe without leaving dead connections open all day.
After the upload ends, different timers matter. If your app spends two to four minutes parsing a CSV, unzipping an archive, or checking rows before it sends a response, look at proxy_read_timeout. That setting controls how long Nginx waits for data back from the upstream app.
proxy_send_timeout matters during the handoff. Nginx uses it while sending the request to the upstream server. If Nginx buffers the body and then forwards a large request to an app server that reads slowly, this timeout can fire even though the client finished uploading.
A simple starting point looks like this:
client_body_timeout 180s;
proxy_send_timeout 180s;
proxy_read_timeout 300s;
That is usually enough for slow but real traffic. It is not enough for a broken import job that never finishes, and that is the point. Very large timeout values hide real problems. If you set everything to an hour, failed workers, blocked disks, and frozen parsers sit there much longer before anyone notices.
Use timeouts to match normal behavior with a little safety margin. If users need two minutes to upload on weak networks, give them three. If parsing takes 90 seconds on large files, give the app three to five minutes. Then watch the logs. When a timeout fires, it should tell you something useful.
A simple import example
A small team offers a CSV import for product data. One customer uploads a 250 MB file from a shared office connection where the speed drops every few minutes and the upload arrives in bursts instead of a smooth stream.
Nginx takes the request first. Before the app can parse anything, Nginx stores much of the request body in its temp area. On this server, that temp path sits on a small disk that also holds logs and other scratch data. Halfway through the upload, the disk fills up.
From the customer side, it looks random. One attempt hangs for a long time. Another ends with an error page. The team opens the app logs and finds almost nothing because the app never received the full file. Nginx failed earlier, so the parser never had a chance to run.
This is why upload buffering fools people. The first fix often sounds sensible but solves nothing. The team raises client_max_body_size, tests again, and still gets failed imports. That setting only says how large the request may be. It does not create disk space for temp files, and it does not give a slow network more time.
The real fix is much less dramatic: move the temp body path to a larger disk, leave enough free space for more than one upload at a time, increase client_body_timeout so a slow office line can finish, and keep client_max_body_size above the real file size with some margin.
After that, the same 250 MB CSV finishes. Nginx writes the body without filling the disk, the upload stays open long enough, and the app finally starts parsing rows instead of failing before it begins.
That last part matters. Once the upload path works, errors become normal and readable. If the CSV has a bad column or a broken row, the app can report that clearly. Before the fix, the server hid the real problem behind random failures.
Mistakes that keep coming back
The most common mistake is simple: someone raises client_max_body_size, sees a few uploads succeed, and assumes the problem is gone. Then imports start failing again because Nginx still needs enough temp space, write access, and sane buffering rules while it receives the body.
That gap causes a lot of confusing failures. The body limit may be fine, but the temp directory fills up, the disk gets slow, or another layer rejects the request first.
A common setup makes this worse. Teams keep Nginx temp files on the same small disk as logs, app caches, and system files. A burst of large imports can eat free space quickly, and logs keep growing at the same time. The result is messy: one upload works, the next returns 413, 499, 502, or just times out.
This is a common pattern in systems Oleg Sotnikov audits. The app gets blamed first, even when the server runs out of room before the request reaches it.
Another repeat problem sits outside Nginx. A load balancer, CDN, ingress controller, or WAF may enforce its own body size and timeout rules. You can set client_max_body_size 500m; in Nginx and still fail at 100 MB because an upstream service cuts the request off earlier.
Slow users expose the next blind spot. Uploads that pass on a fast office connection may fail for real users on weak Wi-Fi, hotel internet, or mobile data. If you test only on a clean local network, your timeout values will look fine right up until customers start sending bigger files from slower places.
The last mistake is easy to avoid and still happens all the time: changing five settings at once. If you increase body size, move temp files, raise timeouts, tweak buffering, and reload everything together, you lose the trail. When the upload starts working, you do not know why. When it still fails, you do not know where to look.
A calmer process works better. Change one setting, test with one known file size, watch disk space and Nginx logs during the upload, and check limits in every hop before and after Nginx. It feels slower for an hour. It is usually faster by the end of the day.
Quick checks before you blame the app
Many upload failures are not really buffering problems. The file fails somewhere along the path, and Nginx is just the first place where you notice it.
Start with the Nginx error log. Look for 413 when the file is too large, 408 when the client took too long, and messages about request body temp files when Nginx ran out of space or could not write fast enough. If your team already collects logs in Loki or another tool, filter by those terms first. Five minutes there can save hours of guessing.
Then check the disk where request body temp files live. Large imports often touch temp storage before your app reads a byte. If that filesystem is nearly full, uploads fail in messy, inconsistent ways. One user succeeds with a 300 MB file, another fails with 280 MB, and the pattern looks random when it is really just free space and I/O pressure.
A short checklist helps:
- Read the Nginx error log for the exact failure time.
- Check free space and write speed on the temp file volume.
- Compare size limits at every hop.
- Time one real upload on a slow connection.
- Test whether the app can process the file after Nginx accepts it.
The size check matters more than people expect. You may set client_max_body_size in Nginx, but a load balancer, CDN, ingress, framework, or app server can still reject the same file earlier or later. If one layer allows 1 GB and another allows 100 MB, users get different failures depending on which path they hit.
Timeouts need a real-world test, not a guess. Upload one sample file from the slowest network you support and measure the full request time. A hotel Wi-Fi connection or weak mobile hotspot can turn a harmless import into a timeout. If the upload takes three minutes in real use, a 60-second timeout is the problem.
Last, make sure the app can handle the file after Nginx accepts it. Nginx may finish cleanly while the app crashes during parsing, runs out of memory, or times out during import work. Check app logs, queue logs, and error tracking too. When both sides agree on what happened, the fix gets much easier.
Next steps for a stable upload path
Random upload failures usually come from mismatched limits, not one broken setting. If you want a stable result, write down three real numbers first: the largest file users send, the slowest connection you expect to support, and the free space available for Nginx temp files during peak traffic.
That small baseline changes the whole conversation. A 2 GB import over office fiber behaves very differently from a 2 GB import over hotel Wi-Fi. If your team skips that step, people often raise client_max_body_size and still get failures because disk space, buffering, or timeouts fail somewhere else.
A simple rollout plan works better than a big config rewrite: adjust body size limits first, then review temp file location and free space, then increase read and send timeouts for slow uploads, test with one file size that should pass and one that should fail, and keep notes on each change and the exact result.
Change one group at a time. If you change limits, temp storage, and proxy settings together, you will not know which fix helped or which one caused the next problem.
Monitoring matters just as much as config. Add alerts for low disk space on the temp volume, rising 413 errors, repeated timeout responses, and sudden spikes in canceled uploads. Those signals usually appear before support tickets do.
If buffering is only one part of the problem, check the whole path. App workers may time out while Nginx still accepts data. Container storage may fill up even when the main disk looks fine. Load balancers and CDNs may also cut long uploads earlier than your app expects.
When uploads cross Nginx, app code, workers, and cloud limits, an outside review can save days of trial and error. Oleg Sotnikov at oleg.is helps startups and small teams audit infrastructure limits, upload paths, and application flow as part of Fractional CTO and startup advisory work. That kind of review is most useful when the same failures keep coming back after small config fixes.
Frequently Asked Questions
Why do my app logs stay empty when a large upload fails?
Nginx often stops the request before it forwards anything upstream. If the file hits client_max_body_size, the temp disk fills up, or the client sends too slowly, your app never receives the request. Check the Nginx error log and the temp file volume first.
What should I check first when I see a 413 error?
Start with client_max_body_size. If that value sits below the real request size, Nginx returns 413 right away and your app never sees the file.
Does client_body_buffer_size control the maximum upload size?
No. client_body_buffer_size only controls how much of the request body Nginx keeps in memory before it writes the rest to disk. client_max_body_size sets the actual upload limit.
Where should I put client_body_temp_path?
Point it to a disk with enough free space, steady write speed, and correct permissions for the Nginx user. Avoid a small root volume that also stores logs and other scratch data, because large uploads can fill it fast.
How much space should I allow above the real file size?
Give yourself a little margin above real file sizes. A simple rule is to set the limit about 10% to 20% above the largest normal upload so multipart overhead does not trigger avoidable failures.
Which timeout helps users on slow connections?
Use client_body_timeout for slow uploaders. That setting tells Nginx how long to wait between chunks from the client, so raising it helps users on weak Wi-Fi or mobile data finish the upload.
Why does the same file work for one user and fail for another?
Those uploads usually stop because of network speed, temp disk space, or timeouts, not because the file changed. One person sends the same file fast enough, while another hits a timeout or fills the temp area later in the request.
Should I change body limits, temp storage, and timeouts all at once?
No. Change one group of settings, test one known file size, and watch the Nginx log and temp disk during the upload. That way you can see what fixed the problem instead of guessing.
Can another service reject the upload even if Nginx looks fine?
Yes. A CDN, load balancer, ingress controller, WAF, or your app server may enforce a smaller body limit or a shorter timeout. The smallest limit in the path wins, so compare every hop.
What is the best way to test upload fixes after I change the config?
Run one file size that should succeed and one that should fail. Measure upload time on a slow connection, watch free space on the Nginx temp volume, and read the Nginx error log at the exact failure time.


