MVP architecture costs: why startups overspend too soon
MVP architecture costs rise fast when teams copy big-company stacks, split simple apps into many services, and overbuild infra before demand is clear.
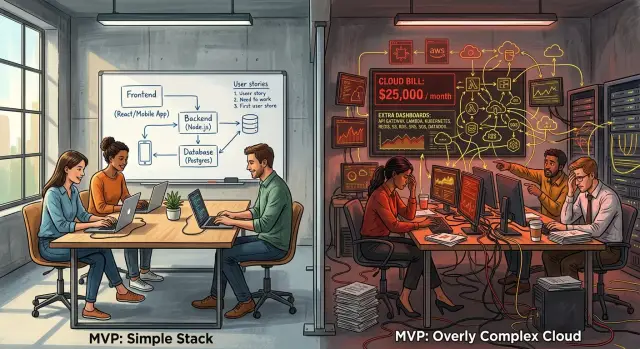
Table of Contents
Why early MVP costs hurt so much
A mature company can survive a bad technical choice for a while. An MVP usually cannot.
If a startup has $120,000 in the bank and burns $15,000 a month, it has 8 months to learn. Add another $3,000 a month in tools and cloud spend, and that drops to about 6.7 months. That is not a small hosting change. It is more than a month of lost experiments.
The damage usually does not come from one huge purchase. It comes from a pile of small charges that look harmless on their own. A managed database, paid auth, logging, monitoring, CI, email, analytics, feature flags, search, and a few AI services can turn a cheap first version into an expensive stack before users prove they want it.
Engineering time is the bigger cost. Teams often treat setup work as free because no invoice shows up. It still burns runway. If founders spend a week wiring services together, fixing deploy issues, or learning a stack they barely know, they are not talking to users or shipping product changes.
That slowdown is what hurts. Early products need constant changes: a shorter signup flow, a different onboarding step, a new pricing rule, a simpler dashboard. With a simple setup, a team can test those changes quickly. With too many moving parts, even a small edit can touch several services, break an integration, and need a long retest.
That is why early complexity is expensive even when the cloud bill still looks manageable. It locks the team into slower decisions, slower releases, and fewer chances to find product-market fit. Startups rarely die because one provider charged a few hundred dollars too much. They die because wasted runway leaves no time to learn what users will pay for.
Choices that lock a startup into higher spend
A lot of MVP cost comes from decisions that feel smart in week one and heavy by month three. The pattern is simple: the team builds for scale, edge cases, and technical neatness before real users ask for any of it.
One common mistake is splitting the product into many services too early. Signup becomes one service, billing becomes another, notifications get their own worker, and search gets a separate stack. That can make sense later. For an MVP with a few hundred or even a few thousand users, it usually means more hosting, more config, more failure points, and more time spent wiring things together.
The same thing happens with data. Teams create separate databases because it looks clean on a diagram. In practice, simple products usually work fine with one database and clear tables. If traffic is light, one solid database is easier to manage, cheaper to run, and easier to back up.
Costs also rise when founders buy a tool for every problem on day one. Paid auth before login volume exists. Hosted logs before errors are frequent. Managed queues before jobs are complex. Search before anyone needs real search. A job system that runs a few tasks per hour. Each tool adds a monthly bill, setup time, new limits, and another dashboard someone has to understand at 2 a.m.
Custom infrastructure work is another trap. A team with ten users does not need clever deployment logic, multi-region failover, or a hand built event system. That work can look impressive, but it does not help prove demand. It delays product learning, which is the one job an MVP has to do quickly.
The most expensive choice is picking a stack because it is popular instead of because the team knows it well. A familiar tool with a few rough edges is usually cheaper than a fashionable one that slows every feature. If your developers can ship fast with one codebase, one database, and a small set of boring tools, that is often the right call.
When planning for later turns into waste
Most early architecture waste comes from building for a future that may never arrive. A team reads an engineering post from a company with millions of users, then copies the setup for a product that still has 50 testers.
That gap gets expensive fast. Managed clusters, extra environments, complex queues, failover databases, and heavy observability all take time and money. Worse, they add moving parts that slow every release.
Kubernetes is a common example. Before one server feels tight, it often creates more work than value. Someone has to manage deployments, config, secrets, networking, logs, and alerts. If traffic is low and the app is simple, one reliable server with backups and basic monitoring usually does the job.
The same mistake shows up in traffic planning. Founders picture a launch spike, viral growth, or enterprise demand, then design for ten times the load their roadmap can support. Growth does not come from architecture diagrams. It comes from a product people keep using.
Planning ahead is fine. Building ahead is where waste starts. You can prepare for change without paying for it now. Pick tools that are easy to replace, keep the system easy to understand, and wait until you feel a real bottleneck in usage, deploys, or reliability.
The same logic applies to outages. If a short outage would annoy a handful of test users, that is not the same as failing thousands of paying customers. Early on, fast recovery matters more than perfect redundancy.
A simple rule helps:
- Fix the problem you have this month.
- Leave room to change one layer later.
- Measure load before you buy more capacity.
- Add operational complexity only when it saves more time than it costs.
Oleg Sotnikov often works with teams that want enterprise infrastructure before they have steady demand. His advice is usually simple: keep the first version light, ship faster, and spend money only when usage proves the need.
A simple stack for the first version
For most MVPs, the cheapest setup is the one your team can understand at 2 a.m. when something breaks.
If the product allows it, start with one app and one database. A single codebase and one PostgreSQL instance can take many products much farther than founders expect. You do not need microservices because you might grow later. You need a setup that lets you ship, fix bugs, and change the product every week.
Hosting matters just as much. Pick something your current team can run without a dedicated infra hire. A managed app host, a simple VM, or one small container setup is often enough. If your developers already know one option well, that choice usually beats a supposedly better stack that nobody on the team can debug quickly.
Background work should stay simple too. For early email sends, reports, webhooks, and imports, a basic job runner or a worker inside the same app is usually enough. Many teams jump to Kafka, separate queue clusters, and event buses far too soon. That adds cost, setup time, and more places for simple jobs to fail.
Before you add a long list of tools, cover the boring basics:
- automatic backups
- uptime checks and error tracking
- a few alerts for failed jobs, high CPU, and low disk space
That small layer saves more pain than another platform service. If backups fail or alerts never fire, fancy architecture will not save you.
Keep the data flow easy to trace. When a user signs up, pays, or sends data, one person on the team should be able to follow that path without opening six dashboards and three repos. Early products change fast. A simple stack makes those changes cheaper.
A lean MVP is not about being cheap for its own sake. It is about buying time to learn what users want before infrastructure cost becomes a monthly habit.
How to choose architecture step by step
Most teams overspend because they plan for scale before anyone knows what users will actually do. A better rule is simple: build for the first month you expect to survive, not for the conference talk you hope to give next year.
Write down the few actions users must complete on day one. Usually that means signing up, logging in, creating one record, editing it, paying, and getting an email. If an architectural choice does not help one of those actions work well, push it out.
Then turn guesses into numbers. Do not say "high traffic." Say "200 daily users, 20 concurrent users, 5 GB of uploads, 10 support emails a week." Those numbers will be rough, but they are better than fear. They also keep infrastructure cost tied to actual demand.
A simple process works well:
- List the user flows that must work in month one.
- Put rough numbers on usage, files, background jobs, and support time.
- Pick one setup that covers those numbers with room for small mistakes.
- Check once a month whether cost, uptime, and release speed still look healthy.
- Split services only when one part clearly slows the team down or fails under load.
For many teams, the right first setup is one app, one database, one background worker, and basic monitoring. That is often enough for the first version of a SaaS product. You can ship faster, debug faster, and avoid architecture work that never pays back.
Teams get into trouble when they add separation too early. A microservice, a second database, and a message queue may sound safe, but each one adds deploy work, alerts, failure points, and engineer time. If nobody can point to the current bottleneck, those parts are just rent.
This is also how experienced fractional CTOs cut cloud spend. They start by sizing infrastructure to current needs, then expand only where the product proves it needs more. That order keeps the team focused on product-market fit instead of expensive guesses.
If users grow faster than expected, you can split the hot path later. Until then, boring architecture is usually the smart choice.
A realistic example from a small SaaS team
A five person SaaS team built an MVP for internal approvals. They had two founders, three engineers, and no clear product-market fit. Still, they started with microservices, a managed queue, Kubernetes, a separate auth service, and more than one environment because they wanted to "do it right" from day one.
On paper, the setup looked clean. In practice, small changes got messy fast. A simple feature like adding one extra approval step touched the frontend, API, worker, queue, and auth rules.
The team spent a surprising amount of time on work users never saw:
- fixing deploy order between services
- chasing auth sync bugs between systems
- helping each other get local setups running
- checking why one service worked in staging but failed in production
That overhead hurt more than the cloud bill. Engineers lost hours each week to setup and release issues while customer feedback stayed basic and direct. Users wanted workflow changes, fewer clicks, and simpler notifications. None of that needed complex architecture, but the architecture slowed every release.
After a few months, the team made a hard but smart decision. They moved back to one app with one database and kept only the parts they actually used. Background jobs stayed, but they ran inside the main app. They dropped Kubernetes, removed several paid services, and cut back infrastructure they had added for scale that had not arrived.
The difference showed up almost at once. Local setup got easier. Deploys stopped feeling risky. Product changes shipped in days instead of dragging across multiple services and handoffs. The monthly bill dropped, but the bigger win was speed.
That is why MVP costs often feel unfair. Startups do not usually fail because their first version could not handle 10 million users. They fail because they burn time and money before they learn what users want.
A simple stack will not impress other engineers as much as a complex diagram. It will let a small team change direction without paying for every guess.
Mistakes teams repeat
A lot of startup waste starts in meetings, not in code. A founder hears an investor ask about scale, security, multi-region failover, or enterprise controls, and the team treats that question like a build order. The MVP ends up carrying costs for customers who do not exist yet.
Investor questions matter, but they are not product requirements. If ten users are testing your product, you do not need the same setup as a company with ten thousand paying accounts. Teams often spend months answering future concerns while current users still wait for basic fixes.
Another common problem is more human than technical: engineers build things they want on their CV. A custom event system, a complicated Kubernetes setup, or an early microservice split can look impressive. For a young product, it usually adds more dashboards, more deploy work, and more ways to break simple features.
Founders need a clear rule here. Every new piece of tech should solve a pain the team already feels, not a pain they imagine they might feel next year.
Tool buying goes wrong in the same way. A team pays for monitoring, analytics, feature flags, support software, workflow automation, and security scanners before anyone owns the process around them. The tools sit half configured. Alerts go nowhere. Reports pile up. The bill still arrives.
A good check is boring, and that is why it works:
- Who will use this every week?
- What decision will it change?
- What manual work will it replace now?
- What happens if we wait 60 days?
Reliability work gets mixed up with urgent product work too. Teams call everything "stability" and give it the same priority as broken onboarding or failed payments. Some reliability work is necessary. Most of it can wait until real usage exposes a real weak spot.
Vendor lock in is the quiet cost many teams ignore. A hosted service may look cheap at the start, but moving away later can mean rewriting data models, auth flows, background jobs, or internal tools. That does not mean you should avoid every vendor. It means you should ask one plain question before you commit: if this price doubles, how painful is the exit?
The cheapest early architecture is rarely the clever one. It is the one a small team can understand, change, and replace without drama.
A quick cost check before each new decision
Most teams do not overspend through one huge mistake. They do it through small choices that feel reasonable on their own. A new database tier, a logging tool, a queue, a second service, paid auth, managed search. Each one sounds cheap. Together, they push costs up before the product proves anything.
A simple rule helps: if a new piece of tech does not solve a real problem now, treat it as a future idea, not a current need. Planning ahead is fine. Paying ahead usually is not.
Before you add anything, ask five plain questions:
- Can one app handle the next 12 months if traffic grows slowly, not magically?
- Does this tool fix a bottleneck you already feel this quarter?
- Can the team you have run it at 2 a.m. when something breaks?
- If usage stays flat for six months, what will this decision cost every month?
- If you regret it later, can you remove it without a rewrite?
Those questions cut through a lot of startup wishful thinking. A two person team often says it needs microservices for scale. In practice, one solid app, one database, and basic monitoring can carry a product much longer than founders expect.
The third question matters more than people think. A tool that needs rare skills gets expensive fast, even if the invoice looks small. If your current team knows Postgres well and nobody knows Kafka, adding Kafka creates operational debt on day one. During an urgent issue, familiarity beats elegance.
The fourth question is where bad assumptions show up. Founders often model cost for growth, but flat usage is the real test. If nobody new signs up for half a year, will this still feel like a smart bill to pay? That is when many "temporary" tools start to look permanent and wasteful.
Undo cost is the last filter. Some decisions are easy to reverse. Others spread through code, deployments, and team habits. If a choice is hard to back out of, the bar should be much higher. That keeps infrastructure cost tied to evidence, not optimism.
Next steps before you add more tech
When costs start creeping up, stop shopping for tools and audit what you already have. Look at every service, plugin, database, and paid platform in the stack. Ask a blunt question: why does this exist right now?
If the answer is "we may need it later," pause. Early on, every extra part adds setup time, more alerts, more bills, and more things that only one person understands.
A simple test helps. For each tool, try to name its job in one sentence, who uses it each week, and what breaks this month if you remove it. If nobody can answer clearly, the tool is probably early.
Write upgrade rules before you upgrade
Teams make better choices when they set a few rules before the next purchase or migration:
- Split a service only when separate releases keep blocking each other.
- Upgrade infrastructure only when users feel the problem, not when a graph looks busy.
- Add a new database only when the current one creates a real limit.
- Buy automation only when it saves repeated team time every week.
These rules stop emotional decisions and make technical debates much shorter.
Pause any new tooling until the team can name the current bottleneck in simple words. "Deploys take 35 minutes" is a bottleneck. "We should prepare for scale" is not. "Support keeps missing errors because logs are scattered" is a bottleneck. "A bigger stack would look more serious" is just expensive anxiety.
A small SaaS team can go a long way on one app, one database, basic logging, and a clean deploy process. That is often enough to learn what users want. Product-market fit rarely fails because a startup did not buy one more service.
The goal is simple: learn from users faster than you spend.
If you want a second opinion before adding more tech, Oleg Sotnikov reviews stacks as a Fractional CTO and startup advisor. On oleg.is, his work focuses on helping small teams keep infrastructure practical, cut waste, and adopt AI in a way that speeds up development instead of adding more tools.
Frequently Asked Questions
Is one app and one database enough for an MVP?
For many MVPs, yes. One app and one PostgreSQL database let a small team ship, debug, and change features fast. Split things later if one part clearly slows releases or breaks under real load.
When should we move to microservices?
Split only when you feel a real bottleneck. If one area needs its own release cycle, hits load limits, or keeps causing failures for the rest of the product, then separation may pay off. Before that, extra services usually add cost and delay.
Is Kubernetes too much for an early startup?
For most early products, yes. Kubernetes adds setup and ops work that many small teams do not need yet. If one server or a basic container setup handles your traffic, keep it boring and spend time on product changes instead.
What should we actually pay for first?
Start with backups, uptime checks, error tracking, and a few alerts. Those tools help you recover fast when something breaks. You can wait on paid search, complex queues, extra analytics, and other add-ons until users prove the need.
How do I know if a new tool is worth adding?
Ask one plain question: what problem does this solve this month? If nobody can name the bottleneck, the tool is probably early. Also check whether your team can run it during an outage and remove it later without a rewrite.
What costs more early on: cloud spend or engineering time?
Engineering time usually hurts more. A small cloud bill stings, but slow releases burn runway faster because the team learns less each month. If setup work keeps founders away from users, the product loses time it may never get back.
Should we architect for viral growth from day one?
No. Plan for sane growth, not fantasy traffic. Build something you can upgrade later, but do not pay for scale before people use the product enough to justify it.
How can we cut costs without making the product fragile?
Keep the stack small, but do not skip the basics. Use one codebase if you can, keep backups working, watch errors, and make deploys easy to undo. Fast recovery matters more than perfect redundancy when you have a small test group.
What does a practical first-month architecture look like?
A good first version often looks like one app, one database, one background worker, and basic monitoring. That setup covers signup, payments, emails, and normal product changes without creating a pile of dashboards and deploy steps.
How should we think about vendor lock-in at the MVP stage?
Use vendors carefully, not blindly. A hosted service can save time early, but check how hard it would be to leave if pricing jumps or the product no longer fits. If the exit would force a large rewrite, raise the bar before you commit.


