Multiple tech stacks: when team freedom slows the company
Multiple tech stacks may help one team move fast, but they often raise hiring, support, and release costs across the whole company.
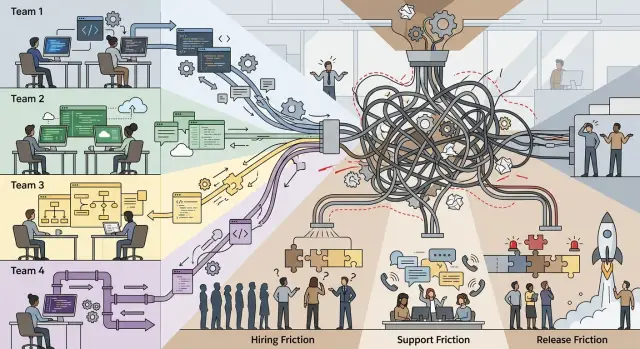
Table of Contents
Why this feels fine at first
At ten people, the fastest choice often wins. One team has a deadline, knows a language well, and ships in three weeks instead of six. That usually is a good decision in the moment.
Another team may hit a different problem and make a different choice for sensible local reasons. Maybe they need fast data work. Maybe they already know a tool that fits the job. They are not trying to create a mess. They are trying to get their work done.
Early on, almost nobody feels the shared cost. The same few engineers can jump between codebases, answer questions in chat, and patch problems without much process. Support volume is low. Hiring is slow enough to stay manageable. Releases do not involve many teams at once.
That is why multiple tech stacks can look harmless at first. Team leads feel trusted. Managers see features moving. Customers do not care which framework produced the screen they use every day.
The hidden cost stays quiet because the company has not grown into it yet. Each new stack adds its own libraries, build steps, testing habits, deployment scripts, and quirks. None of that hurts much when one or two people still remember everything.
A simple example shows why this feels fine. Team A builds an internal tool in Node because they can move fast. Team B picks Python a few months later because it fits their data work. Both teams ship. Nobody blocks anyone. The choice looks smart on both sides.
The drag shows up later, not on the day the decision gets made. It appears when the company needs to hire faster, support more systems, and release changes across several teams without delays. What looked like local speed turns into extra work nobody planned for.
Where the drag starts to show
The trouble starts when the company grows past one or two teams. Each team may still move quickly on its own, but the shared cost rises. You rarely see it in one big failure. You see it in slow hiring, messy support work, and release plans that need too many people in the room.
Recruiters often feel it first. If one team uses Go, another uses Node.js, and a third uses Python with a different cloud setup, each opening needs a different search, a different screening process, and often a different interviewer. That makes the candidate pool smaller for every role. A hire that should be simple turns into three separate hunts.
Managers feel it next. They cannot move people around easily when work spikes or deadlines slip. An engineer who could help with a bug or feature still needs time to learn a new build process, test setup, deploy flow, and service layout. On paper, the team has enough people. In practice, those people are locked inside separate islands.
Support work gets heavier too. The same issue looks different in every stack. Logs live in different places, alerts follow different rules, and each app has its own odd setup for local development and production fixes. Support staff and platform teams spend more time remembering how things work than fixing the problem.
Cross-team projects slow down for the same reason. Shared login, billing, reporting, or customer data sounds simple until systems do not match. Then teams add adapters, extra review steps, and custom release checks just to keep everything talking.
This is where local speed turns into company-wide drag. The company does not lose because one tool is bad. It loses because too many tools stop people from helping each other.
Hiring gets harder than it looks
Hiring is simple when a company bets on a small number of tools. The role is clear, the interview is focused, and managers know what skills they need. Once a company runs multiple tech stacks, that simple process starts to break.
Every extra stack shrinks the candidate pool. A strong engineer may fit one team well but miss half the tools used across the company. Someone great in Go may not want a job that expects occasional work in Rails and .NET. A frontend hire may know React deeply but still need months before they can help on a Kotlin service owned by another group.
That gap shows up in hiring loops. If each stack needs its own reviewer, interviews get longer fast. One candidate might need a backend reviewer, a frontend reviewer, and someone who understands the deployment setup. Calendar delays pile up. Good candidates often accept another offer before your team finishes the process.
A growing company feels this in a very practical way. Imagine a startup with 35 engineers split across four stacks. One manager needs a Python engineer, another needs a Node.js specialist, and a third needs someone who can maintain an older PHP system while helping with new work. Instead of hiring solid generalists, managers start chasing rare specialists. Then they compete with each other for the same few people.
The cost does not stop after the offer letter. New hires take longer to become useful across teams when each group uses different test tools, release habits, and coding patterns. Even smart engineers stay boxed into one area because they cannot safely jump into the rest of the codebase.
This is why stack standardization matters earlier than many teams think. The goal is not to make every team identical. It is to make hiring broad enough that strong engineers can join, ramp up fast, and help where the company needs them most.
Support work spreads across too many tools
Support pain starts when a simple alert no longer has one obvious place to inspect. One service writes logs in one place, another uses a different dashboard, and a third has its own deploy script that only one team trusts. The company still ships code, but support gets slower every month.
On-call work suffers first. An engineer wakes up for an incident and has to remember which app uses Grafana, which one hides details in a cloud console, and which one needs a manual check in a GitLab pipeline. Ten extra minutes during an outage feels small on paper. At 2 a.m., it feels expensive.
The bigger problem is handoffs. A bug starts in the frontend, shows up in an API, and ends in a background job that another team wrote in a different stack. Nobody can trace the full path with confidence, so the ticket moves from team to team. Each handoff adds delay, and users do not care which team owned the middle step.
Shared fixes also stop being simple. A security patch, a logging change, or a retry rule sounds like one task. In a company with multiple tech stacks, it becomes four slightly different tasks with four chances to miss something. One team updates fast, another needs a custom workaround, and a third breaks production because the same idea behaves differently in its framework.
Then small issues start to wait for the one person who knows that setup. That person becomes the bottleneck without asking for it. If they are on vacation, in meetings, or leaving the company, minor support work can sit for days.
Oleg Sotnikov sees this pattern often in growing teams. Local choices look harmless until support touches every system at once. The cost is not only tool sprawl. It is slower incident response, longer bug cycles, and too much company knowledge trapped in a few heads.
Releases turn into coordination work
Shipping one feature across three teams can take longer than building it. That happens when each team has its own build, test, and deploy routine, even if every team works well on its own.
One team pushes code twice a day. Another waits for a weekly release window. A third needs manual checks from ops before anything goes live. None of these choices seem terrible alone. Put them together, and release work turns into waiting.
The problem gets worse when one change crosses service boundaries. A small update to login, billing, or permissions often touches more than one codebase. Developers do not just finish their part and move on. They wait for another team to merge, run tests in a different pipeline, and deploy on a different schedule.
A growing company usually feels this in a few obvious places:
- Pull requests sit open because one dependent service is not ready.
- QA repeats the same checks in different environments.
- Release managers spend time chasing status instead of shipping.
- Small bugs miss the release because one pipeline failed late.
Rollback is where the pain gets obvious. If services behave differently, nobody can use one clear playbook when something breaks. One team rolls back with a feature flag. Another redeploys the previous container. Another restores a database change by hand. The clock keeps running while customers wait.
This is one reason multiple tech stacks cost more than the tool choice itself. The real expense shows up in coordination: meetings, handoffs, retesting, release freezes, and late-night fixes that should have been routine.
A simple case makes it clear. Say a company changes its pricing flow. The web app team ships through GitHub Actions, the API team uses GitLab runners, and the billing team still deploys from a manual checklist. The code may be done by Wednesday. The release slips to next week because the last dependency misses its slot.
Teams often blame planning when the release date moves. Sometimes planning is fine. The bigger issue is that the company has no shared release shape. If build steps, test rules, and rollback methods differ too much, every cross-team change becomes custom work.
A standard process does not mean every service must use the same language or framework. It means teams should share enough of the release path that changes move predictably and fixes do not depend on who happens to be online that night.
A simple example from a growing company
Picture a software company with three product squads and about 25 people. Leadership gives each squad freedom to pick its own tools. One team builds customer-facing features with TypeScript and Next.js, another writes backend services in Go, and a third handles internal workflows in Python.
At first, this looks smart. Each squad moves fast because nobody waits for a company rule, a shared template, or a long debate about stack standardization. Roadmap updates go out on time, and each team feels productive.
The trouble starts when customer problems stop fitting inside one squad.
A customer opens a ticket because their account upgraded, but their new features did not turn on. Support checks the billing screen, then the user profile, then the background job that applies plan changes. The bug crosses three services owned by three different teams.
Now support cannot solve the issue with one clear path. One squad checks app logs in one place, another uses a different deploy process, and the third names events differently. Nobody is doing bad work, but software support overhead climbs because the company has to join three small worlds just to answer one customer.
The same thing happens with product changes. A simple request, like adding a free trial extension for certain users, sounds small in a planning meeting. In practice, one squad updates checkout logic, another changes account permissions, and a third edits the admin tool that lets support apply the offer.
That one change touches several codebases, test setups, release calendars, and owners. What looked like a two-day task turns into a week of coordination, retesting, and waiting for matching releases.
This is where multiple tech stacks stop feeling like team freedom and start feeling like company drag. Local speed is real, but it stays local. Once work crosses team boundaries, release process complexity and engineering hiring costs usually follow the same pattern: every shared task gets slower, and every new person needs longer to become useful.
How to set stack rules without freezing teams
Freedom works better when people start with a default instead of a blank page. Teams still get room to build, but the company stops paying for random choices years later.
Start with a plain inventory. Write down every language, framework, database, background job tool, hosting setup, and deploy path people use today. Most companies think they have five or six stack choices. When they list everything, they usually find two or three times more.
Then mark the choices that cost the most outside the original team. A stack can be fast for one group and still create trouble later if hiring takes longer, on-call support needs special knowledge, or releases depend on one person who knows the odd setup.
A good rule set is usually small:
- Pick one default backend language and one default frontend framework for new products.
- Pick one or two database options that cover most normal cases.
- Pick one standard deploy path with the same CI/CD pattern and monitoring setup.
- Allow exceptions only when a team writes down the reason, expected gain, and who will own support.
- Review the full list every quarter or twice a year and retire old choices on purpose.
This is not about forcing every team into the same mold. It is about making the easy choice the safe choice. If a team wants something outside the default, they should show why the gain is worth the extra hiring and support cost.
One startup rule works well: new work uses the default stack unless the team can point to a real limit, not a preference. "We already know this tool" is usually a weak reason. "This customer needs offline sync and our default stack cannot handle it" is much stronger.
Oleg Sotnikov often helps companies adopt AI-first development without letting cost grow at the same pace. The same idea applies here: keep the default path lean, make exceptions visible, and remove old tools before they turn into permanent baggage.
That gives teams some freedom, but it keeps multiple tech stacks from quietly becoming company policy.
Mistakes that make stack sprawl worse
The trouble with multiple tech stacks rarely starts with a bad idea. It usually starts with a reasonable shortcut. A team prefers a language, knows a framework well, or wants to move fast for one project. That is fine once or twice. It turns into drag when team preference gets treated like a business need.
"We know this tool" is not the same as "the company needs this tool." If the reason is comfort, the cost shows up later in hiring, support, and release work.
Another common mistake is keeping old tools forever because changing them feels painful. Teams avoid one hard migration, then pay a smaller tax every month. Someone has to patch old services, keep strange build scripts alive, and answer questions about code nobody wants to touch.
One cleanup project often costs less than years of low-grade friction.
Urgent work makes this worse. When every rush project starts from a blank slate, teams grab whatever feels fastest that week. One group ships in Node.js, another uses Go, and a third adds Python because a contractor already has code. Each choice makes sense on its own. Together, they create more CI pipelines, more deployment rules, and more people who can support only one slice of the product.
A growing company should at least define a few defaults:
- Which languages and frameworks new projects should use.
- When a team can ask for an exception.
- Who owns shared tooling and deployment templates.
- When older stacks should be retired.
The opposite mistake is forcing everything into one stack at once. That usually creates more resistance than progress. Teams stop trusting the rule because it ignores real differences between products, deadlines, and customer needs.
A better approach is boring, and that is why it works. Pick defaults for new work first. Keep a short exception list. Move older systems over when you touch them anyway, or when the support cost gets too high to ignore.
Last, many companies choose defaults but skip the parts that make defaults usable. They write the rule, then stop. No docs, no starter repos, no training, no examples. Teams fall back to whatever they already know.
A rule on a slide does nothing. A simple setup guide, a working template, and one person who can help during the first week will do far more. If a team asks for a new stack, ask two things: what problem the default cannot solve, and who will support this choice a year from now.
A quick check before you add another stack
This is how multiple tech stacks sneak in: each choice sounds small on its own. One team wants to move faster, one feature needs a special library, one engineer knows a tool well. The bill arrives later, when other people have to support, test, secure, and deploy it.
A short pause before approval helps more than a long cleanup later.
- Check who can support it after hours. If only one person can fix it at 10 p.m., the team does not really support it yet. You have a weak spot.
- Check whether you can hire for it at your pay range. Some stacks look easy to adopt, but finding solid people for them takes longer and costs more.
- Check whether another team will need to read or change the code. If data, support, infra, or product engineers may touch it later, familiar tools usually save time.
- Check whether it creates a new deploy, test, or security path. A new runtime, package system, CI job, or secrets setup adds work to every release, not just this one.
- Check whether the business gain fits in one sentence. "This cuts invoice processing from 15 minutes to 3" is clear. "It feels cleaner" is not a strong enough reason on its own.
A small example makes the tradeoff obvious. If a team adds a new language for one internal service, they may ship the first version fast. Six months later, another team needs to change that service, security needs a new scan setup, and the release team has one more deployment pattern to maintain. The first win was real, but the ongoing cost is real too.
One rule works well: if a new stack adds a new hiring problem, a new on-call burden, and a new release workflow, treat it as a company decision. If you cannot explain the business gain clearly, stick with what your team already knows.
What to do next
Start with a one-page map. Write down every stack in use, who owns it, what it runs, and where it causes pain. Keep it plain: hiring delays, release blockers, flaky handoffs, on-call gaps, or tools only one person understands. You do not need a perfect audit. You need a clear view of where multiple tech stacks already cost time.
Then pick the noisiest area and fix that first. A growing company usually gets more from one clean repair than from a wide standardization plan nobody finishes. If three teams use different ways to ship the same kind of service, start there. If support work keeps bouncing between frontend, backend, and infra because each team uses different tools, fix that instead.
A simple plan often looks like this:
- List each stack, its owner, and the pain it creates today.
- Choose one area where the same work happens in too many different ways.
- Set default tools for new projects and for shared services such as logging, CI, alerts, and deployment.
- Let teams ask for exceptions, but make them explain the extra hiring, support, and release cost.
Defaults matter more than strict bans. Most teams will follow a standard if it saves them time and if the path is easy to use. Write a short internal note that says what the default backend, frontend, database, testing setup, and deployment path should be for new work. Keep it short enough that people will actually read it.
If this gets stuck in debate, an outside view helps. Oleg Sotnikov, through oleg.is, works with startups and smaller companies on practical stack decisions, Fractional CTO support, and AI-driven development workflows. The useful part is not a grand rewrite. It is getting clear guardrails that reduce hiring friction, support overhead, and release delays.
The goal is not one stack everywhere. The goal is fewer avoidable choices, fewer handoffs, and a release process people can trust.
Frequently Asked Questions
Is it ever okay for teams to use different stacks?
Yes, if the reason is real and the gain is clear. A few exceptions will not hurt you.
Trouble starts when every team picks from scratch because it feels faster. Set a default stack for new work, then allow exceptions only when the default cannot handle the job well.
We're only 20 to 30 people. Do we need stack rules already?
Probably yes. You do not need a huge policy, but you do need defaults before habits spread.
Once work starts crossing squads, the cost rises fast. If you wait until support, hiring, and releases already hurt, cleanup gets much harder.
Why does hiring get slower when every team picks its own tools?
More stacks mean more narrow job openings, more interview paths, and a smaller pool for each role. Managers stop hiring strong engineers who can grow into the product and start chasing exact matches.
That also slows ramp-up. New hires can help one team, but they need more time before they can move where the company needs them most.
How do multiple stacks make support tickets harder to solve?
Support pain shows up when one customer issue touches several systems that all work differently. Logs live in different places, teams name events differently, and each service has its own fix process.
The ticket starts moving from team to team instead of getting solved in one pass. That wastes time and traps too much knowledge in a few people.
Why do releases slip even when each team ships fast on its own?
Local speed does not guarantee company speed. One team may ship twice a day while another waits for a weekly window and a third still uses manual checks.
A change that crosses those teams turns into coordination work. People wait on merges, test runs, approvals, and different rollback methods instead of shipping the feature.
What should we standardize first?
Begin with the shared path. Standardize logging, monitoring, CI, deploy steps, and the default backend and frontend choices for new work.
Those changes cut daily friction faster than a broad language debate. They also make support and releases more predictable right away.
How do we allow exceptions without creating chaos?
Keep one default path and make teams justify exceptions in plain language. They should explain the business reason, the expected gain, and who will own support later.
If the reason is mostly familiarity or personal taste, reject it. That keeps freedom for real needs without turning preference into policy.
Should we rewrite old services into one stack right away?
In most cases, no. A forced rewrite adds risk and burns time that teams could spend on product work.
Move old services when support pain gets too high, when hiring for that stack keeps failing, or when you already need to change the code for other reasons.
What should I check before approving a new stack?
Look at after-hours support, hiring, and release impact first. If only one person can fix it, if recruiting will be hard at your budget, or if it creates a new test and deploy path, the choice is bigger than one team.
When a new stack adds all three costs, treat it as a company decision, not a quick local shortcut.
Who should own the stack rules?
Put one technical owner in charge of the defaults. In a small company, that is often the CTO or a fractional CTO working with engineering leads.
That person should keep the standard current, review exceptions, and retire old choices before they pile up. Shared rules fail when nobody owns them.


