Model federation contracts for stable tool calling
Model federation contracts keep tool calls stable when teams switch models. Learn the request, response, error, and rollout rules to define.
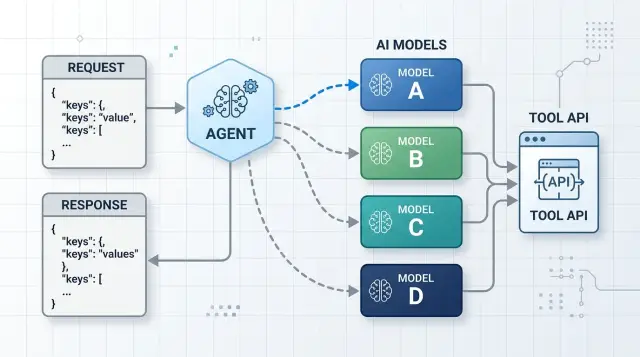
Table of Contents
Why tools break when models change
Tools usually fail for a simple reason: the model stops speaking in the exact shape your code expects.
With a clean tool call, the model returns something your app can parse without guessing:
{"tool":"lookup_order","arguments":{"order_id":"4821"}}
A plain text answer can look close enough to a person, but it is not the same thing:
"I should call lookup_order for order 4821."
A human can read that and understand it. Your parser usually cannot. Once you start adding special rules for plain text, every new model creates another repair job.
Small format changes break tools too. The break does not need to be dramatic. One model may send arguments as an object. Another may send the same data as a JSON string. A third may change lookup_order to LookupOrder, or put one friendly sentence before the JSON.
Most failures start with tiny differences: extra text before the payload, changed field names, numbers returned as strings, missing or renamed tool names, or invalid JSON with one stray comma.
Retries do not solve that. If the contract is weak, the model often fails in a different way on the second or third try. You do not get stability from repeated guesses. You get more logs, more edge cases, and code nobody wants to touch later.
This gets worse when teams want to swap models. A workflow may work with one model today, then fail when you switch to Claude, GPT, or an open source model tomorrow. The tool did not change. The wrapper around it did.
The fix is a shared contract. The request shape should stay the same no matter which model receives it, and the response shape should stay predictable no matter which model answers. Then you can swap models without rewriting tools, patching parsers, or changing error handling.
What a contract needs from day one
A good contract makes model changes boring. If one model writes tool calls a little differently from another, the agent still needs the same facts in the same places.
Every request should carry a fixed outer shape. In practice, that usually means a request_id, a session_id or conversation id, the message history in one standard array, tool definitions with stable names and input rules, and model metadata in a separate object.
That split matters more than it sounds. Tool data should describe the tool itself: name, arguments, and maybe a tool_call_id. Model metadata should stay elsewhere. If provider names, token counts, or vendor flags leak into the tool payload, you will spend time writing exceptions for each model.
Responses need the same discipline. Return the original request_id, a response_id, a top level status, the assistant output in one standard message format, a standard array for tool calls or tool results, and one error object with a code, message, and optional details.
Put ids, status, and errors at the top level. Do not hide them inside a tool result unless the tool itself failed and needs to report its own problem. That keeps routing simple. The agent can check one place to see whether the model replied cleanly, whether a tool should run, or whether the whole step should stop.
A small example makes this easier to picture. Say one model asks to call find_invoice and another asks for the same tool with different vendor formatting. If both responses still return the same status, the same tool_calls[] array, and the same error shape, the agent does not need to care which model produced them.
Choose the request shape first
Start with the smallest request your agents can share for a long time, not the richest format one provider likes today. That choice decides whether the contract stays calm under change or turns into adapter debt.
A good request stays plain. It asks for the same few fields every time, even when the model behind the adapter changes. For many teams, messages, tools, tool_choice, and a small metadata block or trace id are enough.
Keep chat history separate from tool definitions. Messages hold the conversation. Tools describe what the agent can call right now. When teams mix both into one large payload, caching gets harder and debugging gets slower. A changed tool description can also affect old prompts in ways that are hard to spot.
Use the same argument types in every adapter. Pick one JSON shape and stick to it. If user_id is a string in one adapter, keep it a string everywhere. If limit is a number, do not let another adapter turn it into "10". Type drift causes real tool failures.
Provider settings need their own lane. Put them in a separate object such as provider_options, then stop them there. Your app can pass reasoning, temperature, or cache flags into a Claude or OpenAI adapter, but the rest of the system should never depend on those fields. Downstream tools should only see the shared request and response format.
This matters even more in multi model setups. Oleg Sotnikov often works with teams that route work across Claude, GPT, and open models in one AI augmented workflow. When each adapter accepts the same request shape, the router can swap models without rewriting tool code, and failures stay much easier to trace.
A stable request shape is not fancy. It is strict where it needs to be, small by default, and open only at the edges.
Choose a response shape that stays predictable
A model can change its wording, tone, or reasoning style. Your response contract should not. If the outer shape moves every time you switch providers, tools break even when the model did the right work.
Use one assistant message envelope for every final result. Keep the same top level fields whether the model returns plain text, asks for a tool, or reports a failure. That makes routing, logging, retries, and tests much simpler.
A compact response usually needs four fields: role, content, tool_calls, and error. Set role to assistant every time. Keep content as the user facing text, or an empty string when the model only calls a tool. Make tool_calls an array, even when there is only one call. Set error to null on success and to an object on failure.
Tool calls should never hide inside free text like "I will now call search_orders". Put them in a dedicated tool_calls field with a tool name, a call id, and structured arguments. Text is for people. Tool call objects are for code.
That choice saves a lot of pain later. If one model returns JSON like text and another returns a clean tool object, your agent layer starts guessing. Guessing works in demos. It fails in production.
Keep streaming separate from the final message
Streaming needs a different shape than the final assistant response. During streaming, send chunks as event frames such as text_delta, tool_call_delta, or status. When the stream ends, assemble those parts into the same final assistant message envelope every time.
Do not mix partial chunks with the finished response object. A caller should know whether it is reading live updates or a complete answer. If both shapes look similar, someone will parse the wrong one sooner or later.
A simple rule helps: event frames for streaming, one full assistant object for completion.
Make errors easy to read
Errors need structure, but they also need plain language. A good error object gives machines something stable and gives humans something they can scan in two seconds.
Use fields such as code, message, and retryable. Keep message short and direct, like "Tool arguments failed validation" or "Model returned malformed JSON". Avoid vague text like "unexpected issue occurred".
This matters even more when one agent may hit different model quirks on the same task. Clear error fields let you decide fast: retry, switch models, ask the user for missing input, or stop and log the problem.
Define tool names, inputs, and errors clearly
In teams that switch between Claude, GPT, and open source models, tool failures often start with small naming mistakes. A tool called search, web_search, and runSearch might mean the same thing to people, but models do not treat them as the same.
Use short tool names, and give each tool one job. send_email is clear. manage_communications is not. When a name tries to cover too much, models guess, and bad calls follow.
Inputs need the same level of care. Each argument should have a plain label and a simple type that leaves little room for interpretation. email tells the model more than target. start_date and end_date are safer than range because the model does not need to invent structure.
You also need one rule for bad input. Decide what happens when a required field is missing, when a value has the wrong type, and when the model sends extra fields you do not want. If one tool ignores extra input and another rejects it, the agent will behave differently after a model swap.
A small example makes this obvious. Imagine a tool named create_ticket with three inputs: title as text, priority as low, medium, or high, and assignee_id as a number. If the model sends priority: "urgent", every model should get the same response shape back. Do not let one tool coerce it silently while another throws a custom error string.
Keep one error format for every tool. A simple pattern works well: an error code like missing_field or invalid_type, a short message written for humans, the field name when one field caused the problem, and an optional hint that shows the expected value.
When agents can rely on the same names, the same input rules, and the same error shape, swapping models stops breaking tools in random ways.
Build the contract in small steps
Start with one page of JSON. Keep it plain. Write one request object, one response object, and a short note for each field.
If three people read the page and give three different meanings to a field, the contract is not ready. Clear names beat clever ones every time.
Begin with the request shape. Keep only the fields you truly need: messages, tools, tool choice, model id, and a small metadata block if you use one. Leave provider specific extras out for now.
Then map one provider to that shape. Pick a single model and build one adapter that turns your contract into that provider's API call. If you run Claude, GPT, and open source models in one workflow, resist the urge to support all of them on day one. One adapter will show you where the contract is too loose.
Next, run one tool end to end before you add a second one. Choose something simple, such as get_customer_status with a tiny JSON input and a plain JSON result. Watch the whole path: request in, model output, tool call, tool result, final reply out. That is where schema mistakes usually show up.
Tests need to start early. Cover a few plain cases first:
- a valid tool call with complete arguments
- a bad call with missing or wrong arguments
- an empty model output
- a response that mixes text and a tool call
- an unknown tool name
After that, freeze v1. Do not rename fields because another provider prefers a different shape. Keep the public contract stable and fix differences inside adapters.
Log every mismatch. Record missing arguments, wrong types, unknown tools, malformed JSON, and empty responses. Those logs tell you whether the adapter failed or the contract itself needs work.
Good contracts usually start small: one clean request shape, one predictable response shape, one real tool, and enough logs to catch drift before users do.
A simple two-model example
Picture an agent that books support calls. A user writes, "I need help with deployment tomorrow afternoon." The agent should collect a time, an email address, and a short reason for the call, then pass that data to one booking tool.
Now send the same tool definition to two different models. Model A might answer with a clean tool call like book_support_call and a tidy JSON input. Model B might choose the same tool but format the fields a little differently, such as customer_email instead of email, or time_slot instead of start_time. Both models understood the task. They just expressed it differently.
The tool should never need to guess what a model meant. Your agent layer should normalize both outputs before anything touches the calendar.
A simple normalizer usually does four jobs:
- map alternate field names to one approved name
- convert dates and times into one format
- fill missing optional fields with defaults
- reject unknown tools or invalid inputs early
After normalization, both model outputs become the same internal request. Your system can turn either response into one shape: tool name, arguments, request id, and validation status if you track it. Then the booking tool runs once, in one predictable way.
The return path should stay just as strict. If the booking succeeds, send the same result shape back to either model: status, booking id, scheduled time, and a user safe message. If the booking fails, return the same error shape too, with a clear code such as slot_unavailable or missing_email.
That consistency keeps the model interchangeable. You can switch models for price, speed, or quality without rewriting the tool. The model can vary. The contract should not.
Mistakes that cause breakage later
Most breakage starts small. A team adds one provider specific shortcut, nobody notices, and a month later one agent sends the wrong payload to a tool.
The first trap is letting each model provider name arguments its own way. One model sends query, another sends search_term, a third sends q. The tool now needs custom mapping for every model, and each new model adds one more place to fail. Pick one field name and keep it everywhere, even if a provider uses different labels under the hood.
Another common mess happens when teams mix tool errors with model errors. These are not the same thing. If the model times out, that is one failure. If the tool returns "customer not found" or "rate limit reached", that is a different failure. Put them in separate fields so the agent can decide what to retry, what to show the user, and what to log.
Free form text causes quiet damage too. If a tool result comes back as a paragraph like "I found three matching orders and one is delayed," the next model has to guess where the actual data is. That works until it does not. Return structured fields instead, such as status, data, and error, and keep human readable text as a separate optional field.
Schema changes also break systems long after release. A tiny rename from customer_id to client_id can knock out old agents, cached prompts, or tests. Version the contract on purpose. Even a simple schema_version: "1.1" gives you a clean way to support old and new callers during a transition.
Null, empty, and partial values deserve more attention than most teams give them. Decide what null means when a value is unknown, what an empty string means when the user gave no input, what an empty array means when the tool found nothing, and how you represent partial data when one step failed but other fields are still usable.
A small example makes this clear. If a weather tool returns temperature: null, does that mean the city was invalid, the provider failed, or the temperature is temporarily unavailable? If the contract does not say, every model will guess differently.
Good contracts feel boring on purpose. That is usually a good sign.
Quick checks before rollout
Before you send real traffic through a new model, run a short preflight. Most tool failures start in tiny mismatches: a missing field, a renamed status, or an error hidden inside plain text.
Your tool layer should see one shape every time, no matter which model sits behind the adapter.
Use a small checklist and test it with real prompts, not only happy path samples:
- Every adapter should emit the same request fields in the same places, even if the source model uses different names.
- Every normalized response should declare one clear outcome: text,
tool_call, orerror. - Logs should store both the raw model output and the normalized output your system actually used.
- One bad model should fail on its own, without freezing the whole tool pipeline.
The first check sounds boring, but it saves a lot of pain. If one adapter sends tool_name and another sends name, the tool runner should never deal with that mismatch. The adapter should fix it before anything reaches execution.
The response check matters just as much. If a model mixes chat text with a half formed tool call, your parser should not guess. Pick one result type, reject the rest, and record why.
Good logs make debugging much faster. Raw output shows what the model actually said. Normalized output shows what your system understood. When those two differ, you can spot whether the bug lives in the model, the adapter, or the parser.
Isolation is the last check, and it is easy to skip. Do not let one broken adapter block every tool call in the queue. Add timeouts, per model error handling, and a fallback path. If one model starts returning junk at 2 a.m., the rest of the system should keep working.
A small startup can test this in one afternoon. Send the same ten prompts through two models, compare the normalized results, then break one adapter on purpose. If the tools still run through the other adapter, your contract is doing its job.
What to do next
Ship a small contract first. That beats designing a giant standard that nobody uses.
Pick one tool that matters right away, such as search, file write, or ticket creation. Define version 1 for that tool this week, then freeze the request and response format long enough to test it under real traffic. Most teams learn more from one live tool than from ten whiteboard diagrams.
A practical next move looks like this:
- Choose the tool where breakage hurts most, and write one exact schema for inputs, outputs, and errors.
- Add adapter tests before you plug in more models. Send the same call through each adapter and compare the final JSON, not the model's wording.
- Review real logs after a few days. Tighten fields that stay vague, optional, or inconsistent across models.
- Bump the version only when the shape truly changes. Small wording tweaks should not force every agent to update.
Logs usually tell you where the contract is too loose. One model may return timeout, another may return tool_error, and a third may hide the failure inside a text message. Fix that early. Give every error a clear code, a short message, and a place for machine readable details. Keep extra fields rare. If a field does not help routing, retries, or debugging, cut it.
This is the point where a shared layer either stays simple or starts drifting. Teams often add exceptions for one model, then another, until the shared layer stops being shared. A stricter contract feels slower for a day or two. After that, it saves hours.
If you want a second review before rollout, Oleg Sotnikov at oleg.is helps startups and smaller teams tighten contracts, adapters, and AI driven development workflows without rebuilding the whole stack.


