Model federation on a startup budget: a simple setup
Model federation on a startup budget works best when you keep it simple: pick one default model, one fallback, and one local option first.
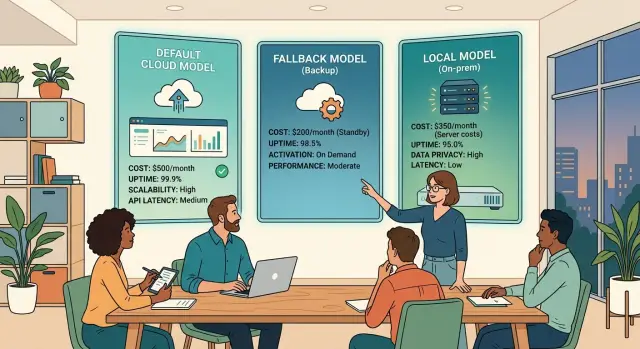
Table of Contents
Why small teams overbuild model stacks
Small teams often add models too early because choice feels like progress. A stack with five providers, custom routing rules, and task-specific prompts looks smart on a diagram. In day-to-day work, it usually creates more moving parts than a startup can manage.
Each new provider adds real overhead. You pay another bill, learn another API, track another set of limits, and store another stream of logs. When something breaks, the team has to answer a basic question the hard way: was it the model, the prompt, the context, or the router?
That support work grows fast. One model may fail in long conversations, another may format JSON badly, and a third may drift in tone after a prompt change. None of those problems sounds huge on its own, but together they can eat hours every week.
Teams also use routing to cover up process problems. If the prompt is vague, the retrieval step pulls weak context, or the task is split badly, clever routing will not fix it. It just makes the system harder to read and harder to repair.
A small SaaS team might spend days comparing four writing models for support replies, then find that most bad answers came from stale help docs. The extra tests feel productive, but they do not solve the real problem. Better source material would have done more than another provider.
A smaller setup gives you cleaner signals. With one default model, you learn what normal performance looks like. With one fallback, you can tell whether failures are rare edge cases or a sign that your main model is the wrong fit. One local model can cover private data, cheap batch work, or offline experiments without turning the whole stack into a mess.
That is why a startup budget calls for a simple model stack at the start. Clear prompts and a short model list give you data you can trust. If one model already handles most requests, adding three more usually gives you three more places to debug when the team should be shipping.
The three-model starter setup
Most small teams do better with three models than with ten. One model handles almost all user-facing work. One backup steps in when the first one fails. One local model takes the cheap, repetitive jobs that do not need a paid API call.
That is enough for an early AI stack. It keeps the system easy to debug, easy to price, and easy to explain.
A clean split on day one helps a lot:
- The default model handles customer replies, summaries, product copy, and normal chat flows.
- The fallback model runs only when the default times out, rate limits, or returns a hard error.
- The local model handles repeat work like tagging tickets, cleaning text, extracting fields, or rewriting content into a fixed format.
This separation matters because different jobs fail in different ways. A user-facing assistant needs steady quality and a predictable tone. A fallback model needs compatibility more than personality. A local model needs low cost and fast turnaround, even if its writing feels plain.
Keep the rules simple. Call the default model first. If the request fails for a clear technical reason, send the same request to the fallback. Do not use the fallback for every small quality complaint, or costs and behavior will drift fast.
The local model should stay away from high-stakes answers. It is a poor fit for sales conversations, legal wording, or anything a customer reads as final. It is great for background work. A small SaaS team can use it to sort support tickets by topic, remove sensitive data before storage, and generate short internal summaries for the support team.
If you start with clear boundaries, you can add routing later without tearing everything apart. If you start with clever routing first, you usually spend weeks chasing edge cases that a simple three-model setup would have avoided.
How to choose your default model
Pick the model that handles most of your daily work with the least friction. The best benchmark score rarely matters if your team mainly needs clean summaries, support drafts, code help, or structured extraction.
The default model matters more than the routing logic because it carries most requests, shapes your costs, and sets the pace for everyone using the product.
Start with your main task. If users mostly ask questions about documents, test the model on retrieval-style prompts. If your product writes emails, specs, or support replies, test those exact jobs. A model can look great on public charts and still miss the tone, format, or precision your product needs.
Use 20 real prompts from your own product. Pull them from support tickets, user actions, internal workflows, or failed edge cases. Keep the set messy on purpose. Real traffic includes vague requests, missing context, and odd formatting.
A simple scorecard works well. Check whether the model follows instructions on the first try, gives an answer that is correct or close enough to use, replies fast enough for the workflow, stays within budget, and respects your output format.
Instruction following matters more than many teams expect. If the model ignores format rules, adds extra text, or misses obvious constraints, your team will spend more time cleaning responses than building features. A slightly weaker model that obeys prompts can be the better default.
Price and rate limits can ruin an otherwise good choice. Cheap per-token pricing does not help if the provider caps requests during busy hours. Slow replies add hidden cost too. If a support agent waits three extra seconds on every draft, the tool feels worse even when the answers are decent.
A practical approach is to run the same 20 prompts through two or three candidates and pick the boring winner. That usually means the model with the fewest surprises, steady speed, and clean formatting, not the one with the flashiest demo.
Pick one model for the bulk of traffic, then watch it for a week. If it handles around 80 percent of requests without manual cleanup, you probably chose well. If your team keeps adding prompt patches to make it behave, switch early.
When a fallback model earns its place
A fallback model starts paying for itself when failure hurts more than a small drop in output quality. If your app writes customer replies, sorts tickets, or powers an internal assistant, a dead request often costs more than a less polished answer.
Three cases usually justify failover: timeouts, hard errors, and provider outages. You cannot stop those events, so you need a calm response when they happen.
Keep that response boring. Your default and fallback models should use prompts that stay as close as possible in structure, tone, and output format. If the first model returns JSON with fixed fields, ask the backup for the same JSON. If one prompt says "reply in plain text" and the other asks for a table, failover will break more than uptime.
A small drop in quality is often fine. Steady service usually beats perfect wording. A customer would rather get a usable answer in eight seconds than watch a spinner and get nothing.
A simple example makes this clear. Say a small SaaS team uses one model to classify inbound support tickets. They give the default model 10 seconds. If it times out or returns a hard error, the app sends the same prompt to a cheaper backup model and marks the result as "fallback." That label lets the team review those cases later without stopping the workflow.
That trade is not always acceptable. If the task involves legal text, finance, or sensitive customer messaging, lower quality can create real risk. In those cases, retry once or send the task to a human.
Log every failover. Track when it happened, which provider failed, how long recovery took, and whether the backup output passed review. After a week or two, patterns start to show. If failovers spike at the same hour every day, you may have a rate-limit problem, not a model problem.
Where a local model makes sense
A local model pays off when the job is repetitive, cheap, and private. It works best on tasks where you need steady output, not brilliant output.
Good first uses are simple internal workflows: support ticket tagging, lead classification, short batch summaries of meeting notes, or pulling topics from a pile of customer comments. These jobs often run in bulk, so API costs add up fast, and a small local model can handle them well enough.
Use it for text that stays inside your company and does not need top-tier writing or deep reasoning. If a summary only helps your team sort, search, or route work, a local model is often enough. If the output goes straight to customers, keep that work on a stronger hosted model.
Privacy is another reason to run something locally. Some teams are fine sending routine text to an API. Others deal with internal notes, support logs, or drafts that they would rather keep in-house. A local setup gives you that option without forcing every task onto local hardware.
There is still a trade-off. Local models take setup work, monitoring, and some care around performance. If your team only runs a few requests a day, the savings may not justify the effort. They make more sense when the task is frequent, predictable, and easy to score.
A simple rollout plan
Start with one workflow that already has real volume. Pick something your team runs every day, not a rare edge case. Support replies, lead qualification, ticket summaries, and spec drafts are all good starting points because they produce enough requests to show cost and failure patterns quickly.
Use one prompt template and one output format for that workflow. Keep both boring. If the model should return JSON, make it return the same JSON every time. If the task needs a short answer, set a clear length limit. Most teams create chaos when they test three prompt styles at once and then blame the model.
Set a few basic rules before you send real traffic. Give the default model a clear timeout. Retry once for short network or provider errors. Send the request to the fallback only when the first call times out, fails, or breaks the output format. Route to the local model only for tasks you already know it can handle well.
That is enough to start. You do not need clever routing on day one. You need stable behavior, a bill you can predict, and a way to see when the setup breaks.
Check the same three numbers every week: cost, latency, and success rate. Cost tells you if the workflow still makes sense. Latency tells you if users will wait for it. Success rate tells you if the output is usable without cleanup. Put those numbers in one simple table and review them on the same day each week.
Only add routing rules after you see the same pattern more than once. Maybe long documents always need the fallback model. Maybe short classification tasks run fine on the local model. Maybe the default model handles 90 percent of requests and the rest do not matter yet. Those patterns should come from traffic, not guesses.
If you cannot explain the rollout on one page, it is already too complex.
A realistic example from a small SaaS team
A six-person SaaS team gets about 60 support emails and bug reports on a normal weekday. They do not need fancy routing. They need faster replies, fewer missed issues, and less repeat work.
Their default model handles the front line. It reads new messages, drafts a reply in the team's tone, and sorts each item into a few plain buckets like "billing," "bug," "feature request," or "account access." It also marks anything urgent, such as payment failures or reports that the app is down, so a human sees those first.
Most days, that is enough. One support lead reviews the drafts before sending them, fixes weak wording, and keeps a short prompt file up to date. After two weeks, the team notices a pattern: the model writes solid first drafts for routine questions, but it gets vague when users describe broken workflows. The support lead adds two better examples to the prompt, and reply quality improves right away.
They also keep a fallback model ready. When their main provider slows down or has an outage, new tickets go to the backup automatically. The drafts are a little less polished, but the inbox keeps moving. That matters more than perfect wording when customers are waiting.
At night, a local model runs two boring jobs on a cheap server. It tags old tickets for reporting, groups near-duplicate bug reports, spots repeat complaints after a release, and marks likely spam or low-signal messages. That local step saves money because those jobs do not need the best hosted model. They need steady output at low cost.
By the end of the month, the team has a simple setup that works: one model for daily work, one for bad days, and one for background cleanup. One person still checks the results, which is the part many teams try to skip. They should not. A simple review loop catches weak prompts early and keeps the whole system useful instead of noisy.
Mistakes that waste time and money
Most teams do not burn money on model prices first. They burn it on extra choices. The fastest way to get stuck is to add five models before one real task works from start to finish.
A common version looks like this: the team connects several APIs, names them by speed or price, and builds routing rules on day one. Then the prompt breaks, outputs drift, and nobody knows whether the problem came from the model, the prompt, or the router. One default model, one fallback, and one local option give you enough contrast to learn what is actually happening.
Logs matter more than guesses. If you route by gut feeling, you usually send expensive requests to the wrong place and cheap requests to jobs they cannot handle. Track simple facts first: which task ran, which model handled it, how long it took, what it cost, and whether a person accepted the result. That small habit saves a lot of money.
Teams also waste time when they force one prompt onto models that behave very differently. A prompt that works well on one model may turn vague, too wordy, or too strict on another. Keep the task the same, but tune prompts per model when needed. If you skip that step, you are not comparing models fairly.
Benchmark scores cause another expensive detour. A model can rank well in public tests and still do a poor job on your support replies, lead sorting, or internal summaries. Real tasks beat leaderboard numbers every time. Run a small test set from your own work and score the outputs with simple pass-or-fail rules.
The bill often surprises teams because they ignore budgets until the monthly invoice lands. Set hard limits early: a spend cap per day or week, a max cost per task, alerts when fallback use rises, and a short review of failed or retried calls.
This plain setup is easier to repair because the logs tell a clear story. A clever system that nobody can explain usually stays broken longer.
Quick checks before you add more routing
If your default model still needs frequent manual rescue, more routing will only hide the problem. Most requests should pass through the main model cleanly, with stable prompts, predictable output, and only occasional human fixes.
The fallback model also needs to switch in without drama. Timeouts, rate limits, or bad responses should trigger a clear handoff. Users should not get stuck waiting while your app tries three things in a row.
A local model should earn its keep in a plain way: it should save money on repeat jobs. Good examples are tagging, fixed-format summaries, draft classification, or internal data cleanup. If the local option is slower, harder to maintain, and only handles edge cases, it is probably a hobby project, not part of a sane startup stack.
Before you add more routing, check five things:
- The default model handles about 80 to 90 percent of requests without rescue.
- The fallback model works through the same prompt contract, or something very close to it.
- The local model cuts cost on repeat tasks enough to justify setup and monitoring.
- One person owns logs, monthly spend, and prompt updates.
- Failures show up fast in dashboards or alerts, not from angry users.
That fourth point matters more than most teams expect. If nobody owns logs, budgets, and prompt changes, routing logic turns into a mess within weeks. One engineer changes a prompt, another swaps a model, and now nobody knows why support tickets doubled on Tuesday.
A small SaaS team can keep this simple. The app sends almost everything to one hosted model, falls back to a second provider during outages, and runs a local model overnight for batch summaries. That setup is enough for many companies.
If one of those checks fails, stop there and fix it before you add more routing. Better logs, tighter prompts, and cleaner failover usually save more time than fancy model selection rules.
Next steps that keep the stack manageable
Once the first setup works, freeze it on paper. Give each model one clear job on a single page. One handles most prompts, one catches failures or rate limits, and one local model covers private or low-cost tasks. If a model does not have a short plain-English job description, it probably should not be in the stack.
That page should also note three limits: cost, speed, and acceptable failure rate. This keeps a small model stack from turning into a pile of exceptions that nobody wants to touch a month later.
For most small teams, a monthly review is enough. Pull one month of logs and look for patterns, not edge cases. Which requests failed, and why? Which prompts were slow enough to annoy users? Which provider added cost without a clear gain? Which tasks could move to the local model without hurting quality?
Teams often keep old providers around long after they stop earning their place. Remove them when they no longer solve a real problem. Every extra model adds maintenance, monitoring, and one more place for behavior to drift.
If your team needs help making those calls, Oleg Sotnikov at oleg.is works with startups and small businesses on lean AI-first product and infrastructure decisions. The goal is simple: keep the stack small enough to understand, cheap enough to run, and reliable enough for real work.
That is usually the better path. Start with one default model, one fallback, and one local option. Let real traffic tell you what to add next.


