Missed launch recovery plan for resetting engineering
A practical missed launch recovery plan that cuts scope, clears blocked work, and sets new decision rules so your team can ship without more overtime.

Table of Contents
What breaks after a missed launch
A missed launch rarely fails in one place. It changes the team's sense of what is real, what matters, and what can still ship.
After the date slips, people often keep the old deadline in their heads and the old scope on the board. Product still asks for the full feature set. Engineering still tries to save all of it. The plan says one thing, daily work says another, and confusion spreads fast.
That is usually where recovery starts. The problem is not only the delay itself. The problem is that nobody has reset the plan in public.
Pause the scramble and name the real goal
When a launch slips, teams often react by pushing harder. That usually makes the next week worse. Work continues, new requests keep landing, and nobody can say what must ship first.
Start with a short reset window. Freeze new feature requests for a few days. Do not promise extra fixes unless they block the release. It can feel slow, but it is often the fastest move because it stops the pileup.
Then write one sentence that defines the release. Keep it plain and testable. A strong version sounds like this: "This release lets current customers create invoices and send them without manual workarounds." A weak version sounds like this: "This release improves the billing experience." If the sentence is vague, scope will grow again.
One person also needs the final say on scope. Not a committee. Not a chat thread. Pick one owner, usually the product lead, founder, or CTO, and make that clear to everyone. Engineers should not lose half a day debating whether a request is small enough to squeeze in.
A simple filter helps. Keep work that is required for the release sentence. Consider work that clearly lowers launch risk. Move optional items out. Cut anything nobody can explain.
Tell the team exactly what changed, why it changed, and what now belongs to the next release. Put that message in one place, in plain language. After a missed date, a shared target matters more than motivation speeches or another late night push.
Cut scope until one launch slice is left
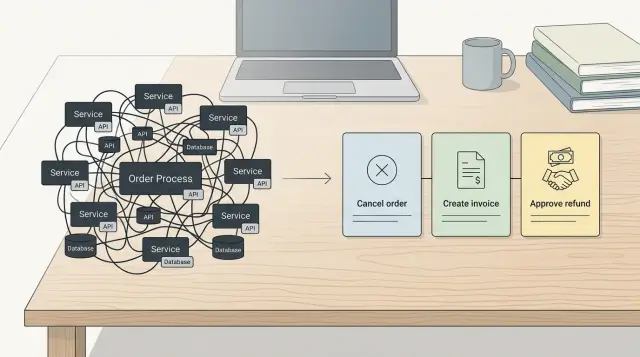
After a missed date, many teams make the same mistake. They keep almost everything in the sprint and hope extra effort will close the gap. It rarely works. The faster fix is to make the release smaller until it has one clear purpose and one working path.
Put every open item on one page: bugs, design tweaks, QA work, copy, analytics, migrations, admin tools, and every late idea that slipped in. If work stays scattered across tickets, chat, and someone's memory, nobody can cut it cleanly.
Most teams cut too softly. They remove a few obvious extras, then keep all the hard parts. Recovery works better when the bar gets strict. If users cannot reach the main result on day one, the item should probably move out.
What stays in scope
Keep work that lets a user start and finish the main job. Keep work that prevents failure on that path. Keep legal, billing, or support tasks that block real use. Move polish, rare settings, and low-use extras to a later release. If a task is too large, split it into a first version and a follow-up.
A simple example makes this easier to see. If you are launching a reporting tool, day one may only need sign-up, one data source, one dashboard, and one export. Custom roles, advanced filters, white-label options, and perfect mobile layouts can wait. Users usually care more about getting the first useful result than seeing every planned feature.
Write down every cut in one place. Name the item, explain why it moved, and give it a later release bucket. This matters because cut work has a habit of sneaking back into the sprint through side chats and good intentions.
Once the cuts are written down, protect them. If someone wants an item back, they should remove something else of similar size. That rule keeps the launch slice stable.
Small does not mean weak. It means the team can finish, test, and explain what is shipping without guesswork.
Remove blockers in your dependency chain
Teams often lose another week after a missed date because they keep pushing on tasks that still cannot ship. One blocked approval or one shaky integration can stall ten other pieces of work. Put the whole chain on one page so everyone can see what sits between "almost done" and a real launch.
Start with the steps outside the build itself: internal approvals, third-party integrations, missing data or content, account access, vendor actions, and support replies. Keep it plain. If a payment provider must approve the account before anyone can test checkout, write that down. If a partner still has not sent the product feed, write that down too.
Then pick the blocker that freezes the most work. That is usually the one worth fixing first. A legal signoff that holds pricing, billing, and launch emails matters more than three small bugs on one screen.
Every blocker needs one owner and one due date. Do not give it to "the team." Give it to a person who will chase it, update the board, and raise a flag fast if the date slips. Shared ownership sounds polite, but it usually means nobody acts.
If a dependency looks fragile, replace it with a manual step for the first release. That is often the fastest reset. A person can upload a CSV, check records by hand, send invoices manually, or turn on accounts for the first 20 customers. It is not elegant, but it breaks the logjam.
Check blockers every day
Review blocker status daily and keep it short. Ask three questions: what changed, what is still stuck, and what someone will do today.
This is where a recovery plan becomes real. Once the team can see the few outside steps that control the date, people stop guessing and start clearing the path.
Set decision rules the team will actually use
After a missed launch, most teams do not need more effort. They need rules that cut down daily debate. The reset falls apart when every change feels urgent and nobody knows who can say yes or no.
Start with scope. One person should approve scope changes, and everyone should know who that is. If three people can add work, scope grows in private conversations and the plan breaks by Friday.
Keep work in progress low on purpose. If each engineer carries several active items, handoffs get messy and blockers stay hidden. A simple cap works better: one main task per person, plus one small follow-up if needed. It feels strict, but delays show up earlier.
Blockers also need a clock. If a developer asks a question about product behavior, data access, design, or another team, someone should answer within one workday. Waiting three days for a yes or no is how a two-hour task turns into a week of drift.
Keep the current plan, status, and changes on one board. Do not split that across chat, docs, and memory. If a task changes, update the board the same day. If a task is blocked, mark the blocker in plain language so nobody has to guess.
A few rules usually cover most of the mess:
- Only the named owner can approve new scope or swap priorities.
- Each person keeps a small amount of active work.
- Product and engineering answer blocker questions within one day.
- The team raises a risk after the second slip, not after a week of hope.
That last rule matters more than people admit. Teams often wait for the fifth warning sign because they want to avoid noise. By then, the date is already fiction. Raise the risk on the second miss, check the cause, and either cut scope, make a decision, or remove the dependency.
A 7-day reset plan
A reset works best when the week feels calm, not heroic. No rescue push, no extra features, no debates that drag on for hours. Pick one launch slice, assign owners, remove the biggest blocker, and test the product the way customers will actually use it.
- Day 1: Lock the smallest version that can ship. Give every task one owner. If two people share a task, nobody owns it.
- Day 2: Clear the single blocker slowing everyone else down. That might be a broken integration, missing access, or a waiting decision from product or leadership.
- Day 3: Finish the core user path from start to end. A user should be able to sign up, do the main action, and see the result without manual help.
- Day 4: Test with real accounts, real data, and normal user permissions. Fake data hides problems. Admin access hides even more.
- Day 5: Fix only the issues that block launch. Save small UI complaints and cleanup for the next cycle.
- Days 6 and 7: Check the date against your decision rules. If the product fails the rules, move the date and keep the scope fixed.
Day 3 is where teams often drift. Someone asks for one more setting, one more edge case, one more polish pass. Say no. If the core path still feels shaky on day 3, the scope is still too big.
Use simple launch rules. The core path works. Support can explain it. Monitoring is in place. The team knows who handles issues on launch day. If one of those is missing, you are not ready.
A week like this can feel almost too plain. That is usually a good sign. After a miss, boring work wins.
A simple example from a small product team
A six-person SaaS team misses a release for a new billing flow. They planned too much at once: card payments, retries, advanced reports, custom invoice formats, and a sync with an outside finance tool. In the final week, bugs pile up, support docs stay half done, and nobody agrees on what must ship first.
So they stop treating the whole project like one bundle. The team writes down one launch goal: a customer can enter payment details, get charged, and receive a correct invoice. If a task does not support that path, it moves out of the release.
That decision cuts more than people expect. Advanced reports go to the next cycle. Custom invoice formats go too. They are useful, but they do not block a customer from paying. One engineer says the finance sync still needs another week of testing, so the team drops it from launch and uses a manual export for the first week instead. It is a little messy, but it is safe and clear.
The founder also changes one habit that was making everything worse. He stops making daily scope changes in chat. New ideas go into a separate list, and the team reviews them after launch. That one rule calms the room fast. Engineers stop guessing what might change tomorrow and start finishing work.
By midweek, the work looks smaller and more real. One person fixes the payment form. One tests failed charges and retry emails. Another checks invoice totals and tax rules. The team lead tracks three questions each day: can a customer pay, can the team see when payment fails, and can support handle the first week without extra tools?
They ship the payment path first. Customers can buy, finance can reconcile with the manual export, and support has a short playbook for common issues. Reports, custom invoice layouts, and the full vendor sync ship later.
That is what recovery often looks like in practice: less drama, fewer moving parts, and one working path that earns the right to grow.
Mistakes that cause a second miss
Teams often miss twice for the same reason. They treat the reset as a motivation problem and try to fix it with more effort. The plan breaks again when people keep changing the work but act as if the plan is stable.
The first trap is scope drift through small messages. A founder sends a note, sales adds one customer request, support asks for one more edge case, and the team quietly puts all of it back in. Each request looks minor on its own. Together, they rebuild the same oversized launch that already slipped.
Hidden work causes the next problem. If decisions live in chat, private notes, or side calls, nobody sees the real plan anymore. Engineers start building different versions of the same feature, testing misses the latest change, and product thinks the team agreed on things that never made it into the backlog.
A reset also fails when senior people ignore the new rules. If everyone else has to cut scope, log trade-offs, and get approval, the same should apply to the most experienced person in the room. Once one leader can jump the line, the process stops being a process.
Overtime is another bad patch. It can hide weak decisions for a week or two, but it does not remove confusion. If the team does not know which user path matters most, longer hours just produce more half-finished work and more bugs.
A common pattern goes like this: the team cuts a few features and keeps one launch slice, a stakeholder asks for a "small" addition and nobody says no, an engineer gets a private message and starts work outside the board, then the launch date gets announced before the core path passes testing.
That last mistake hurts the most. Teams feel pressure the moment a date goes public, even when checkout, signup, or onboarding still breaks in basic tests. Pick the date after the core path works end to end, not before.
If you want the reset to hold, make all work visible, keep the rules the same for everyone, and treat new requests as swaps, not additions. When a new item comes in, something else goes out.
Quick checks before you pick a new date
A new date should come after clarity, not hope. If your team cannot answer a few plain questions in one meeting, the date is still a guess.
Start with one sentence that explains what will ship. It should be specific enough that support, sales, engineering, and leadership all hear the same thing. If each group retells the plan in a different way, you do not have a release plan yet.
Then look at the task list without sugar coating it. Every remaining task needs one owner and one due date. Shared ownership sounds polite, but it hides delay.
Scope also needs to be visible, not implied. Teams get into trouble when they talk about the new launch date but never say what moved out of scope. Write down what is out, what stays in, and what will wait until after release.
Dependency risk is where dates usually fall apart. Check whether one blocked item can stop the whole release. If the answer is yes, either break that dependency, ship without it, or build a temporary workaround. A date tied to one fragile step is not a real commitment.
The riskiest remaining step also needs a fallback. That might mean a manual process, a feature flag, a staged rollout, or a smaller version of the feature. Teams often skip this because it feels like extra work. It usually saves the release.
A quick review should confirm five things:
- The release fits in one clear sentence.
- Each task has one owner.
- Each task has a due date.
- Everyone knows what left scope.
- The riskiest step has a backup plan.
This check is often more useful than another status meeting because it forces the team to test whether the plan can survive normal problems, not perfect conditions.
If you still hear phrases like "we should be fine" or "it depends on one last thing," do not pick the date yet. Fix the plan first.
Next steps after the reset
A reset only works if the team keeps it alive after the first calm week. This is where many teams slip back into old habits.
Keep one short scope review on the calendar every week until launch. Fifteen minutes is enough if the group stays strict. Check what shipped, what slipped, and what you are willing to cut now instead of arguing about it later.
Write your decision rules down and keep them for the next release. Put them in one place that everyone uses. If the team debates the same trade-off twice, the rule is either missing or too vague.
A few rules hold up well over time:
- No new feature enters the release without a named owner.
- Any dependency without a date gets cut or replaced.
- Launch blockers beat polish.
- If one task creates work for three teams, split it or drop it.
Repeated blockers deserve more attention than one late task. If approvals always stall, fix approvals. If handoffs keep breaking, change the handoff. If one shared service slows every release, stop treating it like bad luck and put someone in charge of removing that bottleneck.
Track patterns, not drama. A small note each week is enough: what blocked progress, how often it happened, and who owns the fix. After a month, the same names and steps usually show up. That tells you where the system is weak.
Outside help can be useful when the team is too close to the problem. Founders often push for more scope. Engineers often protect work they already started. A neutral review can cut through both. Oleg Sotnikov at oleg.is works as a fractional CTO and can review scope, dependencies, and delivery rules with that kind of practical focus.
If the new launch date still depends on overtime, the reset is not done. If it depends on smaller scope, cleaner dependencies, and rules people actually follow, the team has a real shot.
Frequently Asked Questions
What should we do first after a missed launch?
Stop the scramble for a couple of days. Freeze new feature requests, write one clear release sentence, and name one person who owns scope. That reset gives the team one target instead of ten half-agreed ones.
How do we decide what stays in scope?
Keep only the work that lets a user finish the main job and the work that stops that path from failing. Move polish, rare settings, and nice-to-have extras to a later release.
Who should make scope decisions?
One person should make the final call on scope. That is usually the product lead, founder, or CTO. If several people can add work, the release grows in side chats and the plan breaks again.
Should we keep the old launch date?
Usually no. Pick a new date only after the core user path works end to end, every remaining task has one owner, and the biggest dependency has a backup plan. Until then, the date is still a guess.
How should we handle launch dependencies?
Put every blocker on one page, including approvals, vendor actions, missing data, and account access. Fix the blocker that freezes the most work first, give it one owner and one due date, and use a manual fallback if that gets you unstuck.
Is a manual workaround okay for the first release?
Yes, if it helps you ship the main path safely. A manual export, manual account setup, or hand-checked records can buy time for the first release as long as support and operations can handle it.
What rules help a team recover after a slip?
Set a few simple rules and follow them every day. Only one person can approve scope changes, each person keeps a small amount of active work, blocker questions get answers within one workday, and the team raises risk on the second slip instead of waiting a week.
Should we use overtime to catch up?
Overtime rarely fixes the real problem. If the team still argues about scope or waits on blockers, longer hours just create more half-finished work and more bugs. Cut scope and clear dependencies first.
What should happen during the first reset week?
Keep the week calm and narrow. Lock the smallest release on day one, remove the biggest blocker next, finish the core path, test with real accounts and real data, and fix only the issues that block launch.
When should we ask for outside help?
Bring in outside help when the team cannot agree on scope, leaders keep adding work, or the new date still depends on hope. A neutral CTO review can cut dead weight, expose weak dependencies, and give the team rules they will actually use.