Map handoffs before AI and cut waste before team changes
Map handoffs before AI to count approvals, status hops, and repeated data entry so you remove waste before you cut roles or automate work.
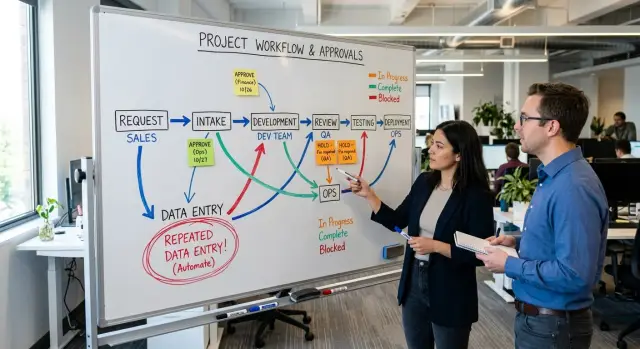
Table of Contents
Why work feels slow even with a full team
Work can move all day and still end up in the same place. The usual problem is not effort. It is the number of people, tools, and check-ins between the first request and the final result.
A single customer request often touches more people than anyone expects. Sales logs it. Support adds notes. A manager reviews it. Operations changes the status. Finance checks pricing. Then engineering gets asked for an estimate. Each step might take only a few minutes, but the task sits in queues between those minutes.
That wait hides inside routine updates. Someone posts "done on my side" and waits for the next person to notice. Someone else asks for a quick approval, but the approver is in meetings for four hours. On paper, the task took one day. In practice, it needed 40 minutes of real work and several hours of idle time.
Routine admin work makes the problem worse because people repeat the same facts in different places. The customer name goes into the CRM, then a ticket, then a project board, then an invoice draft. A deadline gets copied from chat into a task, then into a spreadsheet, then into an email summary. Every extra field looks minor, but the team pays for it again and again.
That is why busy calendars can fool you. A team can look fully occupied while customer results move slowly. People attend standups, answer messages, update statuses, and chase approvals. They are busy. Customers still wait because motion is not the same as completion.
Most slow processes share the same pattern. Too many people touch the same task. Handoffs depend on someone noticing a message. The same details get typed more than once. Approvals sit with people who do not change the outcome.
That is why it makes sense to map handoffs before adding AI. If you drop AI into a messy process, it usually speeds up the mess. You get faster updates, faster copying, and faster confusion.
A better first move is simple and a little boring. Count every person who touches one task, every place its status changes, and every time someone retypes the same fact. Teams often find that the work itself was not hard. The path was crowded.
What to count on the current path
Most teams count labor hours and miss the bigger drag: waiting, checking, and copying the same facts into multiple tools. To see the problem clearly, pick one task that happens often and follow it all the way through. A small bug fix, a pricing update, or a new customer onboarding step works better than a rare edge case.
Start with approvals. Count every time someone must say "yes" before the task can move. Teams often think they have one approval, but the real number is higher. A manager check in chat, a product check in email, and a final sign-off in the ticket are still three approvals.
Status changes matter too. Every move from "new" to "in progress" to "review" to "waiting" adds friction. The hidden moves are often worse. A person posts an update in chat, copies it into email, then edits the ticket so everyone feels informed. That is three status hops for one piece of progress.
Track repeated data entry with a cold eye. If someone types the same customer name, order number, deadline, or bug details into more than one tool, count every repeat. One extra copy might take 30 seconds. Ten repeats a week quietly burn hours.
It also helps to note what each person actually does at every step. Who decides? Who edits the work? Who only passes it along? Who watches but changes nothing? Who waits for others before acting? This view exposes bloated paths fast. In many teams, two people do the work while four others check, forward, or comment on it.
Time is the part people judge badly. Measure the wait between steps, not only the work itself. Someone may need 12 minutes to update a record, but the task can still take two days because it sits in a queue after each handoff.
A basic table is enough. For one common task, note the step, the tool, the person, the action, the work time, and the wait time. Add two more markers if they matter: whether someone had to retype data and whether the task changed owners. Once you see the counts, waste stops hiding behind busy calendars.
How to map one workflow from start to finish
Start with one recurring job that people already know well. Pick something with a clear trigger and a clear finish, such as onboarding a new client, approving an invoice, or publishing a product update. If the workflow happens every week or every day, even small delays add up fast.
Use a plain document, whiteboard, or spreadsheet. The format does not matter much. The rule that matters is this: keep the full path on one page. When teams spread steps across chat, tickets, email, and memory, they miss where time actually goes.
Write each step in the exact order it happens. Keep the wording blunt and specific. "Sales sends request to operations" is better than "request is reviewed." Name who does the step, what they do, and where they do it.
For every step, add the tool in use. That detail matters because wasted motion often hides in tool switches. A task might start in email, move to a CRM, jump into a spreadsheet, then return to chat for approval. That is usually where duplicate entry and extra status updates begin.
For each step, capture a few simple facts: how many minutes of actual work it takes, how long it waits before someone touches it, whether someone copies the same data again, whether ownership changes, and whether anyone can clearly explain why the step exists.
This split exposes the truth quickly. Ten minutes of work can sit under two days of waiting. A task can pass through four people even though only one of them changes anything.
Watch for steps that nobody can explain in one sentence. If one person says, "We always do it that way," and another says, "I think finance asked for it once," mark that step. Confused steps are often old rules that outlived the reason for them.
A small example makes this easy to see. Imagine a bug fix request. Support logs it in a help desk, copies the summary into chat, a manager copies it into a ticket system, engineering asks for missing details, and support goes back to the customer. The code change may take 20 minutes, but the request spends six hours bouncing between tools and people.
When you finish, redraw the workflow as one clean line from start to finish. Put every handoff, tool, work time, and wait time in one view. That page gives you the real target: not team size, but the waste between steps.
Which approvals and status hops deserve a challenge
Most approvals are habits, not controls. A team adds one signer, one watcher, and one extra status update, and six months later nobody knows why the step exists. This is where a lot of wasted time shows up.
Ask a blunt question for every approval: what risk does this step control? If nobody can answer in one sentence, the approval is probably there for comfort, not for safety. A real approval should stop a specific problem, such as overspending, a legal issue, a security risk, or a promise that could hurt a customer.
If two people approve the same thing for the same reason, keep one. If a manager only says "looks good" after a team lead already checked the work, that second review may add delay without changing a single decision. Teams often protect old mistakes with more approvals, then wonder why work crawls.
The same logic applies to status hops. If work moves from "in progress" to "review" in a ticket, and someone also posts the same update in chat, email, and a spreadsheet, that is not visibility. It is duplicate entry. Pick one place where progress lives and make everyone use it.
A few steps deserve immediate scrutiny:
- approvals where the reviewer almost never says no
- status updates copied into more than one tool
- watchers who read updates but never change the outcome
- escalations for routine work with low cost or low risk
- check-ins that only confirm the previous check-in
Watchers create drag in a quieter way. People get added "just in case," then they ask for extra context, reopen settled points, or slow replies because everyone assumes someone else will answer. If a person does not decide, review, or act, remove them from the loop and let them read the final update if they need it.
Set a simple rule for single-owner decisions. One person can approve routine requests under a set budget, minor copy changes, or bug fixes that do not touch billing or security. That cuts wait time and removes fake urgency from managers' calendars.
One source of truth matters more than most teams think. If a designer updates a ticket, a project manager updates a spreadsheet, and a founder asks for a chat summary, the team now maintains three versions of the same story. Keep one record of progress, and let every other update pull from that.
A simple example from a real workflow
Take a customer refund for a damaged order. One buyer writes to support, shares photos, and asks for a refund. The request looks simple, but the delay sits in the handoffs.
Support starts the case and checks the order number, order date, payment amount, and shipping status. The agent then copies those details into a refund form for finance. Finance opens that form, checks the order number and amount again, and types the customer name, refund amount, and transaction ID into the accounting tool.
Operations gets pulled in because the package may be lost or damaged in transit. An ops lead checks the warehouse scan, carrier note, and stock record, then adds a note in a shared sheet. Now support, finance, and operations have all touched one refund.
The odd part is that each team often checks the same detail. Support wants to know the claim matches the order. Finance wants to know the refund amount matches the payment. Operations wants to know the shipment really failed. In practice, all three often look at the same order screen and the same customer photos.
Original path and shorter path
A common version looks like this:
- support reviews the ticket and fills a refund form
- a support manager approves refunds above a set amount
- finance re-enters the same order and payment data
- a finance lead approves the refund
- operations logs the shipment issue in a separate sheet
That path has at least five touches, two approvals, and repeated entry across two or three systems. If the teams work in batches, the customer may wait a full day for a refund that takes about 15 minutes of actual work.
A shorter version cuts the waste first. Support collects the proof once in a shared record. If the refund is under a clear limit and the shipment already shows damage or delivery failure, finance processes it without a second manager check. Operations only reviews cases where stock, fraud, or carrier disputes are unclear.
Now the case has three touches instead of five, one approval instead of two, and very little retyping. That gain is bigger than it sounds. An AI tool might draft the customer reply a bit faster, but removing one approval and one copy step can save hours of waiting.
For a refund flow like this, the best fix is usually plain: fewer checks, one shared record, and a clear rule for exceptions.
Mistakes that waste time before automation starts
The most common mistake is buying an AI tool before anyone measures how work moves today. A team says it needs automation because the week feels busy, then points the tool at the noisiest task. Two months later, people still wait on approvals, retype the same details in three places, and chase updates in chat.
AI can speed up one step. It does not fix a messy route. If a request touches five people, changes status six times, and gets entered into two systems by hand, the delay lives in the path.
Another mistake is automating a bad approval chain. Teams often keep approvals that nobody can explain. One manager signs off because they always have. Another person checks the same field again because an older policy required it. When AI pushes requests faster, it only feeds a queue that should not exist.
A lot of workflow maps also show only the normal case. That is a problem. Real work includes missing information, urgent requests, customer changes, failed checks, and rework. Those exceptions create the longest waits and the most duplicate entry. If you skip them, your workflow looks neat on paper and falls apart in real use.
Teams also waste time when each group defends its own step without proof. Sales says the handoff note matters. Operations says the extra status helps. Finance says one more approval keeps risk low. Maybe they are right. But each step needs evidence, not habit.
A few questions cut through the noise:
- Who uses this step's output?
- What breaks if we remove it for two weeks?
- How often does it catch a real issue?
- Does someone else already check the same thing?
One more mistake causes more damage than people expect: cutting roles before removing duplicate work. If two coordinators copy the same order details into different tools, removing one person does not fix the design. The remaining person still does the same waste, just with more pressure.
A small example makes this obvious. A support request enters a form, then a coordinator copies it into a tracker, a manager approves priority, and an engineer asks for missing details. AI can draft the engineer's reply in seconds. Useful, sure. But the bigger win comes from removing the extra copy step, setting clear priority rules, and collecting the missing details at the start.
Teams usually find more savings in fewer approvals, fewer status hops, and fewer duplicate entries than in early automation alone.
A quick check before you automate
Automation freezes habits. If a task already has too many handoffs, AI will repeat the same waste faster and make it harder to spot. A short check can tell you whether the work is ready or still needs cleanup.
Ask one person to explain the full path in plain words. They should be able to say where the task starts, who touches it, what information moves, and how it ends. If that explanation breaks halfway through, the issue is not the tool. The path itself is unclear.
Use a simple checklist before you automate anything:
- one person can describe the task from first request to final result without guessing
- the work stays inside three teams or fewer
- people enter the same customer, order, or project data once, then reuse it
- every approval has a clear reason, such as policy, legal risk, or spending limits
- you can carve out a smaller version of the flow and test it in one week
Approvals deserve extra scrutiny. If someone signs off on the same kind of request every day and almost never says no, that step probably does not protect the business. It only slows the work.
Task travel is another warning sign. A request that moves from support to sales to finance to operations and back may look organized on paper, but each status change adds wait time. If the same details get copied into email, a ticket, and a spreadsheet, repeated entry is doing more damage than most teams think.
If the flow fails two or more checks, pause the automation plan. Clean up the path first. Cut one approval, remove one status hop, and keep the data in one place. Then run a small pilot. A narrow test on a cleaner workflow tells you far more than automating a messy process end to end.
Next steps for a small, low-risk pilot
Start with one process that happens often and gets stuck in plain sight. Good candidates have a clear start, a clear finish, and a delay people already complain about. If a task shows up every day or every week, even a small fix is easy to measure.
Do not start with the biggest mess in the company. Pick something one team owns, where one person can approve a small change without a long debate. A narrow pilot gives you cleaner results and fewer excuses.
Before you add AI, remove one piece of waste. Cut a single approval if it exists only because "that is how we do it." Or remove one copy step if someone keeps pasting the same details into a second tool. That small cleanup matters more than it sounds. If the flow is bloated, the pilot tests the mess, not the AI.
A practical pilot plan often fits on one page:
- pick one high-volume workflow with a visible delay
- record the current cycle time, error rate, and handoff count
- remove one approval or one repeated entry step
- test AI on one cleaned-up task, not the full process
- compare the numbers after one or two weeks
Keep the AI test narrow. Use it for one job that people can review quickly, such as pulling fields from an email, drafting a first response, or filling a ticket from a form. Leave the rest of the process alone in the first round. That way, if results change, you know what caused it.
Track three numbers after the change: cycle time, error rate, and handoff count. Cycle time tells you whether the work moves faster. Error rate tells you whether speed created new problems. Handoff count tells you whether the process is actually simpler. If you want one more measure, count how often someone had to fix the AI output before it could move forward.
Teams usually find that one removed approval and one removed copy step save time even before automation does anything.
Some pilots look small but touch product rules, internal tools, and team structure at the same time. That is where outside review can help. Oleg Sotnikov at oleg.is works as a fractional CTO and startup advisor, and this kind of process cleanup is often the difference between a useful AI pilot and an expensive detour.
Frequently Asked Questions
Why should I map handoffs before adding AI?
Because AI will copy the same waste faster if your process already has too many handoffs, approvals, and duplicate updates. You save more time by cleaning the route first than by speeding up one messy step.
Map the work once, cut obvious drag, then test AI on the cleaner version. That gives you a fair result and fewer surprises.
What should I count first in a slow workflow?
Start with one common task and count four things: how many people touch it, how many approvals it needs, how many status changes it goes through, and how many times someone retypes the same facts.
Then measure work time and wait time for each step. Teams often find that the waits hurt more than the work itself.
How do I choose the first workflow to map?
Pick a job that happens often, has a clear start and finish, and already causes complaints. Refunds, onboarding, invoice approval, and small bug fixes usually work well.
Skip rare edge cases at first. A frequent workflow shows waste faster and gives you numbers you can compare after a small fix.
How can I tell if an approval is worth keeping?
Ask a blunt question: what specific risk does this approval stop? If nobody answers in one sentence, the step probably stays there out of habit.
Look at the history too. If the reviewer almost never says no and only repeats what someone else already checked, remove or narrow that approval.
What counts as a status hop?
A status hop is any move that tells people work changed state, like updating a ticket, posting the same update in chat, or editing a spreadsheet. One useful update helps; three copies of the same update waste time.
Keep one place where progress lives. Let people check that record instead of rewriting the same status across tools.
How do I spot repeated data entry?
Follow one request from start to finish and watch where names, order numbers, deadlines, or notes get entered again. If the same detail shows up in a CRM, ticket, spreadsheet, and email, count every repeat.
Small copy steps look harmless on their own, but they stack up fast over a week.
Should I automate the biggest problem first?
No. Start with a smaller workflow that one team mostly owns and someone can change without a long argument. You want a clean test, not a rescue mission.
The biggest mess usually mixes policy problems, tool problems, and ownership problems. Fixing a narrower flow first gives you better proof and less noise.
What should I measure in a small AI pilot?
Track cycle time, error rate, and handoff count. Those three numbers tell you if work moves faster, stays accurate, and gets simpler.
If you want one more measure, track how often people must fix the AI output before the task can move on.
How many teams should touch one workflow?
Fewer is usually better. If a routine task crosses more than three teams, wait time often grows faster than the work itself.
Try to keep ownership tight. One team should do the work, one person should own the decision, and only real exceptions should leave that path.
When does it make sense to ask for outside help?
Bring in outside help when your team cannot explain the full path clearly, or when every group defends its own step and nobody has proof. An external review helps when politics hide the waste.
If you want a practical cleanup before an AI pilot, a fractional CTO can map the flow, cut unnecessary steps, and set up a small test without turning it into a big project.


