Lean security posture before Series A for small teams
A simple plan for a lean security posture before Series A: control admin access, store secrets well, test backups, keep useful logs, and set laptop rules.

Table of Contents
Why early security feels bigger than it is
Most early teams picture security as a huge program with audits, long policies, and tools they do not have time to manage. That picture makes people freeze. Before Series A, security is usually much smaller. It starts with a few clear rules for admin access, secrets, backups, logs, and company laptops.
It feels heavier than it is because startup habits create hidden mess fast. Two people share one admin account to save time. A founder pastes an API token into chat during a late night fix. Someone drops a database password into a doc and forgets it. Each choice looks harmless on its own. Together, they make it hard to tell who can touch what.
Backups create the same false comfort. A dashboard says the backup ran, so everyone assumes they are safe. Then a real problem hits. Someone tries a restore and finds an incomplete file, vague steps, or missing permissions. A boring checkbox turns into a long outage.
Logs cause a different version of the same problem. Teams collect plenty of data but miss the events that matter. After an incident, they still cannot answer basic questions: who signed in, who changed permissions, what shipped to production, or when customer data moved.
That is why security feels heavy early on. The work is not huge. The uncertainty is. Once a team puts sensitive information in one place, trims admin access, tests a restore, and keeps logs they can actually use, the whole thing starts to feel manageable.
Decide what you need to protect first
Small teams get stuck when they treat every system as if it carries the same risk. It does not. Start with one simple question: if this breaks or leaks tomorrow, what hurts the company first?
Write down the few systems that can stop revenue or block customers from using the product. For most startups, that means the production cloud account, the code repo and deploy pipeline, payment and banking tools, the customer data store, and the main email and identity system.
Then mark who can do the actions that matter most. You need to know who can move money, ship code, change DNS, read customer data, delete infrastructure, or reset other people's access. If one person can do all of that without anyone noticing, you found a real problem.
Do not fix everything at once. Split the list into two groups. The first group can stop sales, lock users out, leak data, or drain cash. The second group would be nice to tighten later but does not change your exposure much right now.
A simple example makes the difference clear. If your team uses one cloud account, one Git host, Stripe, and a shared support inbox, losing the support tool is annoying. Losing the cloud account or Git access can take the whole product offline. Put your time where the damage would be bigger.
Give each system one owner. Not a committee. One person. That owner keeps the access list current, knows where the backups live, and can answer basic questions during an incident. Even if you work with a Fractional CTO or an outside advisor, someone inside the company should still own each system.
That short map becomes the base for access controls, secrets handling, restore testing, and logging.
Keep admin access small and visible
Early security often starts with boring access cleanup. Trouble usually comes from old permissions, shared logins, and too many people with the power to change settings, delete data, or move money.
Keep a short admin list for every tool that matters. Email, cloud, code host, finance, payroll, domain and DNS, and your password manager do not need a crowd of admins. For most small teams, one or two admins per system is enough.
Put that list in one place people can check. A simple page in your internal notes works fine. Record who has admin access, who can approve changes if the main owner is away, and when someone last reviewed the list. If a contractor finishes work on Friday, remove access on Friday. Do the same when an employee leaves.
Turn on MFA anywhere an account can hurt you: company email, the cloud provider, the code host, finance and payroll tools, and the password manager.
Shared logins feel fast, but they erase responsibility. Replace them when you can. One named account per person gives you a clear record and makes offboarding much easier.
Use a separate admin account for risky changes. Daily work should happen in a normal account. Save the admin account for things like changing DNS, deleting production resources, or editing billing settings. That extra step is mildly annoying, and that is exactly why it helps.
Store secrets in one controlled place
Most early teams leak secrets by accident, not through some clever attack. A token ends up in chat, a support ticket, a shared doc, or a local notes app. A few months later, nobody knows which copy is current, who can see it, or whether it still works.
The fix is simple. Put passwords, API keys, signing keys, and service tokens in one vault, and make that the only approved place to store them. Good secrets management before Series A is mostly about reducing sprawl. If a secret lives in five places, you do not control it.
Clear names matter more than people expect. When teams guess, they make mistakes. A name should tell people what the secret is for, where it belongs, and whether it is safe to use. prod_stripe_api_key, staging_github_deploy_token, aws_billing_readonly, and postgres_app_prod are all easy to understand at a glance.
Keep access tight. Give each person only what they need for their job, and avoid shared logins when you can. A founder may need production access. A contractor fixing a staging bug usually does not. If one laptop gets stolen, limited access cuts the damage fast.
Keep rotation rules simple too. Rotate secrets after someone leaves, after a suspicious sign in, after a laptop loss, or after a token gets pasted into the wrong place. Do not wait for proof of misuse. If you are unsure, replace it.
One small habit helps a lot: every secret should have an owner. Someone should know why it exists, which system uses it, and when it was last rotated.
Make backups you can restore
A small team does not need a huge backup program. It needs copies of the few things that would hurt badly if they disappeared tomorrow.
Start with what your team cannot rebuild fast. For most products, that means the production database, user uploaded files, billing records, and the config needed to bring the app back up. Marketing pages and old test data matter less if you can recreate them in a day.
Backup timing should match the amount of loss you can live with. If losing one day of new customer data would create a real mess, daily backups are too loose. If four hours of loss is acceptable, back up at least that often.
One rule matters more than people expect: keep one copy away from the main system. If the same cloud account, same server, or same script can wipe both production and backups, you do not have much safety. Separation does not need to be fancy. It just needs to survive the same failure.
For most small teams, a simple setup works: back up the database on a fixed schedule, copy files and storage buckets separately, keep at least one backup in another location or account, and save a few recent versions instead of only the latest one.
Then do the part most teams skip. Restore something for real every month. Pick a recent backup, load it into a test environment, and check that the app can read it. A backup job that "succeeds" but produces broken data is common.
Write the restore steps in plain language where the team can find them fast. Include who can start the restore, where the backup lives, which order to recover systems in, and how to confirm the app is healthy again. At 2 a.m., clear notes beat memory.
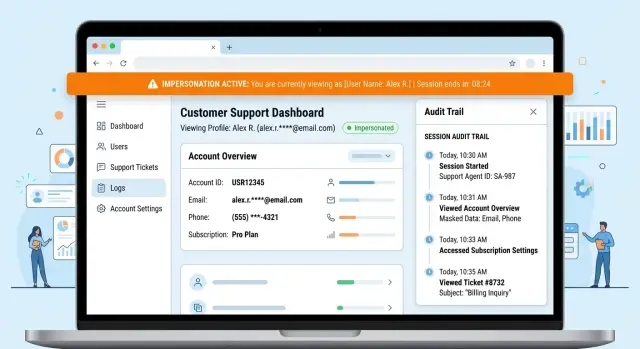
Keep logs that answer simple questions
Logs should help you answer a few plain questions fast. Who signed in? Who changed admin access? What went live in the last deploy? Did backups run, or did they fail quietly at 3 a.m.?
Start with the events that explain most real incidents: sign ins and bursts of failed logins, admin role changes and account removals, deploys with who pushed and when, and backup job success or failure. That is enough for many small teams. You do not need to track every click in every tool on day one.
Keep logs long enough to investigate a real problem. Seven days is usually too short. Thirty days is a reasonable minimum, and ninety days gives you more room when someone notices an issue late. If storage costs bother you, keep detailed logs for less time and a simpler summary for longer.
Alerts should stay rare and useful. Send one when a backup fails, when someone gains admin access, when login failures spike, or when a deploy breaks. Skip alerts that nobody will act on. A noisy alert channel trains people to ignore the next real problem.
After each deploy, and after any outage, one person should check the same small dashboard. If your team already uses Grafana, Sentry, or similar tools, one screen is enough. Show recent deploys, error rate, sign in failures, and backup status. When something looks off, you want one place to start, not five tabs and guesswork.
Give weekly log review to a named person. Ten minutes on Monday is often enough. They should look for strange sign ins, surprise admin changes, failed backup jobs, and any alert that stayed open too long. If nobody owns that check, nobody does it.
Set laptop rules people will follow
A laptop is often the easiest way into a small company. You do not need a big security program to lower that risk. You need a few rules that are easy to check and hard to ignore.
Keep the policy short. If it takes ten minutes to explain, people will forget half of it. Start with the basics: every work laptop uses full disk encryption, every screen locks after a short idle time, and auto updates stay on for the operating system and browser.
Those three choices cover a lot. Disk encryption protects data if someone steals a laptop from a car or a cafe. Screen lock helps when a founder walks away during a meeting. Auto updates fix known holes without asking the team to remember patch days.
Keep work and personal accounts separate. Use a work email for work apps, work documents, and browser profiles. Do not mix company files with a personal cloud drive, and do not save work passwords in a personal browser profile. When someone leaves, clean separation saves hours and closes loose ends.
If a laptop goes missing
Write the procedure before you need it, then test it once. A simple version is enough:
- Report the loss the same day in team chat and to one named owner.
- Revoke the laptop's access to email, chat, VPN, and admin tools.
- Change any passwords or tokens stored on that device.
- Check that current work files still exist in shared systems, not only on the laptop.
Run through this as a short drill with one teammate. Time it. If the steps feel messy, fix the process, not the person.
Good laptop rules do not try to control everything. They reduce the damage from ordinary mistakes, lost devices, and delayed updates. For a small team, that is enough to matter.
A simple example from a small startup
A five person SaaS team runs on AWS, GitHub, Stripe, and Google Workspace. The setup is common for an early company, and so are the problems.
One founder still uses a shared root login because "everyone needs it sometimes." A few API tokens live in phone notes and a text file on a laptop. Nobody thinks of this as a security program. It is just how the team got through busy weeks.
They clean up the obvious risks first. In one week, they turn on MFA for every admin account and move secrets into a vault instead of keeping them in personal notes. The change is simple, but it matters. Now the team knows where credentials live, who can open them, and how to replace them.
They also cut admin access hard. Instead of giving broad rights to all five people, they keep two admins per system. AWS has two. GitHub has two. Google Workspace has two. Stripe has two. The names are visible, and the list stays short. If someone only needs billing reports or deployment logs, they get that and nothing more.
The backup check gives them the biggest surprise. They already have database backups, so they assume they are safe. Then they try a restore. The script breaks because it still points to an old storage path. They fix it that day, while the issue is still cheap and boring.
That is what a practical early security setup looks like. It is not a giant policy set. It is a small team removing shared access, storing secrets in one controlled place, testing restore steps, and making admin rights easy to count.
Build it in 30 days
You do not need a policy binder or a full time security hire. You need one owner, a short checklist, and four weeks of steady cleanup. For most small teams, the founder or engineering lead can do this in a few hours each week.
Week 1 is inventory. Write down every system the company depends on: email, cloud, code repo, payments, analytics, domain registrar, support tools, and production databases. Next to each one, name the owner and every admin account. If no one knows who owns a system, that is already a risk.
Week 2 is access. Turn on MFA for every admin account first, then work outward from there. Move passwords, API tokens, and signing keys into one controlled place, like a password manager or secret store. Shared logins should go away now, not later. Named accounts make offboarding and reviews much easier.
Week 3 is where many teams learn the truth about their backups. Run one real restore test for the database and one for files or object storage. Time it. Write the restore steps in plain English so another person can follow them under stress. Add logs for logins, admin changes, deploys, and backup jobs. You do not need perfect observability yet. You need enough detail to answer simple questions fast.
Week 4 closes the obvious gaps on employee laptops and around exits. Turn on full disk encryption, auto lock, automatic updates, and a basic screen lock timeout. Then run a short offboarding drill: disable one test user across email, code, cloud, and chat, and see what you miss.
By day 30, a small startup should have a current list of systems, owners, and admin accounts, MFA on admin access, secrets stored in one place, a tested restore with written notes, and laptop rules people can actually follow. That is enough to cut a lot of avoidable risk without pretending to be a 200 person company.
Common mistakes that waste time
Early security work usually fails for a boring reason: the team buys tools before it fixes simple access problems. If three people still share one admin login, a new security product will not save you. First clean up who can reach production, billing, domains, and code.
Another common mess starts when one founder keeps every password, every recovery code, and every mental note about how systems work. That feels fast at the start. It also means one sick day, one lost phone, or one vacation can lock everyone out. Put shared access, recovery steps, and account ownership in a place the company controls, not in one person's head.
Logs often turn into storage with no purpose. Teams turn them on, pay the bill, and never decide who checks them or what should trigger action. Keep fewer logs if needed, but make them useful. Someone should own the habit of reviewing failed logins, admin changes, and odd activity in the systems that matter most.
Backups create false confidence more often than people admit. A file copy is not a backup if nobody has restored it. A backup job that sends green check marks every night can still leave you with corrupt data, missing permissions, or a restore process nobody remembers. Run a small restore test on a schedule and write down the steps while they still feel obvious.
Security rules also fail when they fight normal work. If people need six annoying steps to open a staging server, they will look for a shortcut. Good rules fit the way the team actually works. A short laptop policy, basic device encryption, screen lock, and a clear rule for lost devices usually beat a long document nobody reads.
Quick checks and next steps
You do not need a thick security manual to know where you stand. Five plain questions tell you most of what you need to fix:
- Can you name every admin account today across cloud, code, email, and billing?
- Can one person restore the product from written steps without calling the usual expert?
- Can you see sign ins, admin changes, and failed backup jobs without digging for an hour?
- Can you lock a lost laptop fast and know what data was on it?
- Do the rules fit the way your team actually works, or do people skip them?
If any answer is "no," do not open a giant security project. Pick one owner, one deadline, and one proof that the fix works. A screenshot of backup alerts, a current admin list, or a real laptop lock test is better than a policy doc nobody reads.
One check is worth doing this week: ask someone other than the person who set up the system to restore from the backup notes. If they get stuck, the notes are incomplete. The same logic applies to access. If you cannot list admins in a few minutes, you either have too many or you do not review them often enough.
Keep logging simple. You want enough signal to answer basic questions after a bad day: who signed in, who changed admin access, and whether backups failed. Anything beyond that can wait until the team and the product are bigger.
If your team wants a practical outside review, Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor. The useful version of that review is small and direct: trim admin access, tighten secrets handling, test restores, check logging, and set laptop rules people will actually follow.
Frequently Asked Questions
What should a small startup protect first?
Start with the systems that can stop revenue, lock users out, leak customer data, or move money. For most teams, that means company email, the cloud account, the code repo and deploy path, billing tools, and the customer data store.
Give each system one owner and write down who has admin access. That small map usually shows the biggest risks fast.
How many admins should we keep for each tool?
For most teams, one or two admins per system is enough. Keep the list short for email, cloud, code hosting, finance, payroll, DNS, and the password manager.
Too many admins make mistakes harder to spot and offboarding harder to finish. Use named accounts so you can see who did what.
Do we really need MFA before Series A?
Yes. Turn on MFA anywhere an account can hurt the company, especially email, cloud, code hosting, finance, payroll, and the password manager.
That step blocks a lot of ordinary account takeovers. Start with admin accounts first if you need to phase it in.
Where should we store passwords and API keys?
Keep passwords, API tokens, signing keys, and service credentials in one vault that the company controls. Do not leave them in chat, docs, phone notes, or personal browser storage.
Clear names help too. People make fewer mistakes when they can tell what a secret does and where it belongs.
When should we rotate secrets?
Rotate secrets when someone leaves, when a laptop goes missing, after a strange sign-in, or when a token lands in the wrong place. If you feel unsure, replace it.
You do not need a giant rotation schedule for every secret on day one. Focus on events that raise risk.
What actually counts as a good backup?
A real backup is a copy you can restore, not just a job that shows a green check. Back up the data and config you cannot rebuild fast, and keep at least one copy away from the main system.
If the same account or script can wipe production and backups together, you still have a weak setup.
How often should we test restores?
Test a restore every month. Use a recent backup, load it into a test environment, and confirm the app can read it.
Write the steps while they still feel obvious. Clear notes save time when the usual person is asleep or offline.
Which logs matter most for a small team?
Track the events that answer simple questions fast: who signed in, who changed admin access, what shipped, and whether backups ran or failed.
Keep logs for at least 30 days, and send alerts only for things someone will act on. A noisy channel teaches the team to ignore real trouble.
What laptop rules are worth enforcing early?
Keep the laptop rules short and easy to check. Use full disk encryption, a short screen lock timeout, and automatic updates for the operating system and browser.
Separate work from personal accounts and cloud storage. If a laptop disappears, revoke access the same day and change any credentials stored on it.
Can we build a lean security setup in 30 days without hiring security staff?
Yes, if one person owns the work and the team follows a short plan. In four weeks, most small teams can inventory their systems, trim admin access, turn on MFA, move secrets into a vault, test restores, and tighten laptop settings.
You do not need a huge program for that. Steady cleanup beats buying more tools too early.