Launch escalation tree for vendors before release day
Build a launch escalation tree before release day. Assign DNS, payments, email, and auth owners, set backup contacts, and avoid confusion.
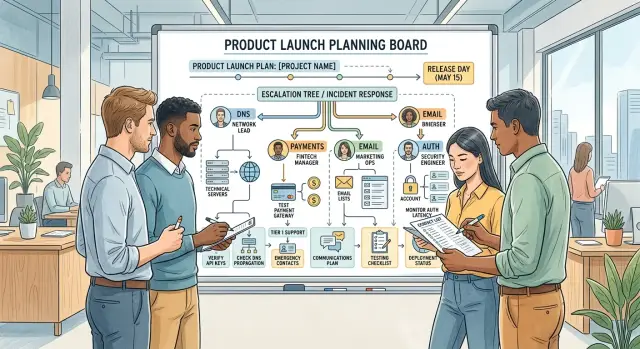
Table of Contents
Why launches stall without clear owners
A release can stop over one small question: "Who owns this?" If nobody can answer fast, the team starts guessing. A few minutes later, design waits on engineering, engineering waits on ops, and the vendor ticket still is not open.
Shared chat threads feel useful until something breaks. Messages pile up, people tag each other, and nobody has the job of making the call. A chat room shows activity. It does not show responsibility.
This gets worse when the launch depends on outside services. DNS might sit with one provider, payments with another, email with a third, and login with yet another service. If the site does not resolve, cards fail, password emails arrive late, or single sign-on rejects users, the team can lose half an hour just figuring out who can speak to the vendor.
Small failures spread fast on launch day. A DNS record points to the wrong place. Then checkout loads half-broken because a payment callback never returns. Then support fills up because confirmation emails are delayed. Customers do not see four separate issues. They see one broken launch.
Clear ownership cuts through that mess. One person tracks DNS. One person owns payments. One person can reach the email vendor. One person handles auth and knows how to escalate if tokens, sessions, or webhooks fail.
That is why a launch escalation tree matters. It does not need special software. It needs names, backup contacts, and one plain rule: if a vendor problem blocks revenue, access, or customer messages, the owner acts first and updates the team right after.
What belongs in the escalation tree
Start with every outside service that sits between your team and a clean release. If a vendor can block signups, payments, logins, emails, or traffic, it belongs on the page. Teams usually remember app servers and forget the less obvious parts like DNS, card processing, transactional email, identity providers, certificate management, feature flags, and status page tools.
For each service, write down one person who owns it and one backup who can act if the first person is asleep, traveling, or busy with another incident. Shared ownership sounds safe, but it slows people down. One name makes decisions faster.
You also need to separate decision rights from visibility. Some people can approve a DNS cutover or a payment setting change. Others only need updates because they handle support, marketing, or customer success. If you mix those roles, people waste time asking the wrong person for permission.
A good launch escalation tree should answer five questions fast:
- What vendor or service is this?
- What part of the release depends on it?
- Who is the primary owner and who is the backup?
- Who can approve a change, and who only needs updates?
- What breaks first if this service fails?
Keep the failure note short and plain. You are not writing a full incident plan. You are giving the team a fast answer to one question: if this breaks, what stops working first?
That distinction matters. If your payment provider fails, checkout may stop while browsing still works. If DNS fails, nobody reaches the product at all. Those two vendors do not belong at the same priority level.
The best version fits on one screen or one printed page. If someone has to dig through old chats to find who owns email sending or who can open a support case with the auth provider, the escalation tree is not ready.
Map every vendor tied to the release
Most launch delays start outside the app itself. A page can be ready, the code can pass review, and the release can still fail because DNS did not update, card payments got blocked, or login tokens stopped working.
A launch escalation tree only works if the vendor map is complete. If one outside service can block traffic, signups, checkout, emails, or logins, put it on the page.
Start with the services customers touch first. Domain and DNS come first, and you should list both the domain registrar and the DNS host because they are often different accounts. Then add payments, including the processor and any fraud, tax, or 3DS tools attached to checkout. Add email, including the sending platform and the domain setup behind it, such as SPF, DKIM, and DMARC. Add auth, including the login provider, SSO setup, magic links, and any token or session service. Then add the delivery layer, such as the CDN, hosting provider, and status page, if they affect traffic or customer trust.
This map should reflect the real release path, not a generic stack diagram. If a new pricing page changes billing, payment webhooks matter. If the launch adds passwordless login, email delivery and auth move into the risk zone.
A simple SaaS example makes this obvious. The app may run on one host, but the release still depends on DNS, payments, an email sender for receipts and login links, and an auth vendor for sessions. Miss one vendor and you create a blind spot.
For each vendor, add a short note about what it controls in production. "DNS for app domain," "card authorization," or "login sessions" is enough. That small line saves time under pressure because people stop guessing where the fault sits.
Be strict about scope. If a tool cannot affect the release, leave it off. If it can stop revenue, access, or traffic for even ten minutes, include it.
Assign owners for DNS, payments, email, and auth
A release slows down fast when everyone assumes someone else can fix the problem. For each outside system, name one primary owner and one backup who can make changes right away. Put their names, phone numbers, and admin access level in the launch escalation tree before release day.
DNS needs one person with access to the registrar, DNS host, and any proxy layer. If the site points to the wrong IP, a verification record is missing, or a subdomain does not resolve, that person should not need to ask around for approval.
Payments need the same clarity. One person should own gateway settings, live mode checks, tax or currency rules, and webhook delivery. If checkout works but orders do not reach your app, the payment owner should know where to look first and be able to rotate secrets or replay failed events.
Email often gets ignored until password resets or receipts stop arriving. Pick one owner for sender setup, domain authentication, suppression lists, and bounce complaints. If launch traffic starts landing in spam, that person should know how to check SPF, DKIM, DMARC, and provider-side sending limits.
Auth needs its own owner too. That person handles login rules, OAuth settings, token lifetimes, callback URLs, and emergency fixes for blocked users. If people cannot sign in after a domain change or a new environment goes live, auth problems can look like product bugs when they are really config mistakes.
A good ownership note answers a few basic questions. Who can log in and change settings? Who approves risky changes if approval is needed? Who is the backup? What systems does this person control? How do you reach them in under five minutes?
The backup matters as much as the primary. If your DNS owner is on a flight or your payment owner is asleep in another time zone, the backup must have working access and clear permission to act. If they still need someone to say yes, they are not really a backup.
Build the contact ladder step by step
Start with the person who can fix the problem, not the most senior person on the org chart. If DNS breaks, the first call goes to the engineer or admin who can log in and change records right away. If payments fail, call the person who owns the gateway account and can check webhooks, fraud rules, or a blocked API key.
Each step in the ladder needs one owner and one time limit. Keep it strict. If the first contact does not respond in 10 minutes for a checkout issue, move to the next person. For lower-risk problems, such as delayed marketing emails, 15 to 20 minutes is usually enough.
Each contact entry should include the details people forget under pressure:
- Full name and role
- Mobile number and backup number
- Vendor account ID or merchant ID
- Access level or system owned
- Exact point when the team escalates
Put the fast approver near the top of the ladder. This is often a founder, product lead, or manager who can say "do it" without a long discussion. Teams lose time when the person fixing the issue still needs permission to roll back a release, pause ads, or switch settings.
Vendor contacts matter too. Do not just write "payment support" or "DNS support." Add the support route, account name, and account ID. When someone opens a ticket during an outage, those details save real time.
Separate paths for different failures
Revenue loss and login outages need different ladders. If checkout stops working, the path should move fast from the internal payments owner to the approver, then to vendor support. Every minute can cost money.
Login failures need a different path because auth issues often lock out staff and customers at the same time. Put the identity provider admin first, then the person who can change DNS or email settings if password resets depend on them, then the approver who can trigger a temporary fallback.
Keep the ladder in one shared document. Print it if the launch is high risk. During a release, nobody wants to search old messages for a phone number.
Run a short launch-day drill
A short drill exposes confusion fast. Ten calm minutes on a practice call can save an hour of panic when the release is live.
Run it a few days before launch, not the night before. Put the real owners on the call, open the actual dashboards, and ask people to act instead of talk.
Use a timer. If a handoff takes more than a minute or two, write it down. Slow handoffs usually mean the owner is unclear, access is missing, or the team still relies on one person who might not answer.
You do not need a full disaster exercise. A few small, realistic scenarios are enough. Test a broken payment webhook. Test a DNS change that needs quick verification. Test a case where staff can log in but customers cannot, then flip it. Test an email problem where the team needs to pause sends or switch to a safe template.
Make people show access while you are on the call. The DNS owner should log in. The email owner should show where they pause sends. The auth owner should show where they check failed logins for staff and customers. If nobody can do that live, release day will get messy.
End with a short cleanup note. Record the owner, backup owner, first contact method, and maximum wait time before escalation. That note is usually more useful than a long vendor checklist because it reflects what your team can actually do under pressure.
A simple release example
At 11:58 a.m., a SaaS team is ready to publish a new pricing page. Marketing has scheduled an email for noon, support is online, and the product team expects a spike in trial signups within minutes.
At 12:07 p.m., something breaks. New customers can still fill out the checkout form, but card charges start failing. The change looks small at first, yet failed payments can turn a clean launch into a messy one fast.
The team does not guess. They open the written launch escalation tree and follow it.
The payment owner goes first because the error touches money. She checks gateway logs, recent webhook events, and the last config change. Within a few minutes, she sees that a webhook setting changed during the release window, so payment confirmations are not reaching the app.
At the same time, the DNS owner rules out a domain problem. He confirms the pricing page resolves correctly, checkout endpoints respond, and no recent DNS change sent traffic to the wrong place. That removes one whole branch of debate.
The auth owner tests active sessions and new signups. He makes sure users can log in, create accounts, and return to checkout without losing state. The email owner pauses launch notices so the team does not send more people into a broken payment flow.
Instead of ten people arguing in chat, four people each answer one clear question:
- Is the payment provider receiving the right events?
- Is traffic going to the right domain and service?
- Can users still sign in and keep their session?
- Should outbound email pause until checkout works again?
By 12:19 p.m., the payment owner rolls back the webhook change. Charges start working again. The email owner resumes the campaign, support posts one short update, and the team notes the fix in the release log.
That is the point of a launch escalation tree. It cuts panic, protects revenue, and gives every person one job at the moment it matters.
Mistakes that cause long delays
Most launch delays start before release day. They start when two groups make different assumptions about ownership and nobody checks them. A launch escalation tree falls apart when names, logins, and backup contacts live in people's heads instead of a shared document.
DNS causes a lot of avoidable pain. The product team thinks the infra team owns the registrar. The infra team thinks the web agency set it up years ago and still controls it. Then the release needs one record change, and nobody can log in. A five-minute task turns into two hours of message chasing and password resets.
Payments break the same way. If one person holds the only admin login for the payment account, the team waits on that person for every live check, webhook fix, or emergency rollback. If that person is on a flight, asleep, or simply offline, the release stops.
Email often looks fine until the exact moment you need it. A contractor or agency may control the sending platform, domain verification, or suppression list, but they may not work your launch hours. If a confirmation email fails after go-live, customers see a broken product even when the app itself works.
Auth issues get ugly because they hide in private inboxes. One founder may receive all identity provider alerts, MFA prompts, and security notices. If nobody else can reach that inbox, the team cannot approve a domain, fix SSO, or answer a fraud block during the release window.
The usual weak spots are easy to spot once you look for them: two teams each assume the other owns DNS access, one admin account controls payments, an outside agency manages email but does not cover launch time, auth alerts go to one private mailbox, and nobody names an after-hours backup.
The fix is plain. Put one direct owner and one backup next to every vendor. Add working phone numbers, not just email. Confirm admin access a few days before release, and test it with the exact people on call. If your release happens on a Saturday night, your contact list needs to work on Saturday night too.
Quick checks before you press go
A release can still stall in the last ten minutes if one person cannot get into the right account or nobody knows who can approve a rollback. This is where your launch escalation tree stops being a document and becomes a real test.
Start with names, not teams. For DNS, payments, email, and auth, write down one owner and one backup who can act without waiting for permission. If the main contact goes offline, the backup should know the plan, have the same access, and know when to step in.
Then test access while everyone is still calm. Each owner should sign in to the vendor account before the release window starts. That simple step catches expired passwords, missing two-factor devices, and surprise permission problems that waste 30 minutes when the clock is already ticking.
Keep one shared document open during the launch. It should hold account IDs, vendor support paths, and the direct phone or chat details your team may need. If someone has to hunt through old emails for a merchant ID or hosting account number, the release already got harder than it needed to be.
Right before go-live, confirm a few basics:
- Every service has a named owner and backup
- Each owner can log in right now
- Account IDs and support contacts are in one shared place
- Launch time, freeze window, and on-call coverage match across teams
- The rollback rule is written in plain language
That last item saves real time. "If checkout errors rise above 2% for 10 minutes, revert to the previous version" is clear. "Rollback if things look bad" is not.
What to do next
Do not leave your launch escalation tree buried in chat or in one project manager's notes. Put it next to the release plan, rollback steps, and launch checklist so the team sees it when they need it.
Then treat it like a working document, not a one-time setup. Every launch exposes something small you missed: an old phone number, a billing contact who left, a DNS login that only an agency can access, or an auth setting that nobody wants to touch under pressure.
A simple routine works well. Save the tree in the same place as the release plan. Update it right after each launch while the problems are fresh. Review ownership whenever you add a new vendor, tool, agency, or contractor. Check that each area still has a primary owner and a real backup.
This takes little time, but it prevents long delays later. Ten minutes of cleanup after a release can save an hour of confusion on the next one.
If your team still cannot answer who owns DNS, payments, email, or auth, you do not have a documentation problem. You have an ownership problem. Someone needs to sort roles, access, and decision rights before release day.
That is often where a fractional CTO helps. Oleg Sotnikov at oleg.is works with startups and small businesses on release planning, infrastructure ownership, and practical AI-first engineering operations. If the same launch problems keep coming back, an outside technical lead can clean up ownership, access, and escalation before the next release.
Start with one release. Build the tree, run it once, and fix what broke. The teams that avoid launch-day chaos usually do not have more people. They just know exactly who to call first.
Frequently Asked Questions
What is a launch escalation tree?
It is a short page that names each outside service, who owns it, who backs them up, who can approve risky changes, and how to reach them fast. You use it when DNS, payments, email, or login breaks so the team stops guessing and starts acting.
Which vendors should go in the tree?
Put in every service that can block traffic, signups, checkout, customer messages, or logins. That usually includes the domain registrar, DNS host, payment provider, email sender, auth provider, and any CDN, hosting, or status tool tied to the release.
Do I really need one owner per vendor?
Yes. One named owner makes decisions faster than a shared group. Add one backup with the same access so the release does not stop when the primary is asleep, traveling, or busy with another issue.
What is the difference between an owner and an approver?
The owner makes the change or opens the vendor case. The approver says yes to moves like a rollback, a DNS cutover, or pausing launch emails. Keep those jobs separate so the person fixing the issue does not wait on the wrong person.
How fast should we escalate on launch day?
Set the time limit before launch. For checkout or login failures, many teams use 10 minutes. For lower-impact issues, you can allow a bit more time, but write the rule down so nobody argues during the incident.
What contact details should we store?
Keep the full name, phone number, backup number, vendor account or merchant ID, and access level in one shared document. Add the exact vendor support route too, so opening a case takes seconds instead of a search.
How do we test the escalation tree before launch?
Run a short drill a few days before release and make each owner log in live. Have them open the real dashboard, find the setting they would change, and show how they would escalate. If a handoff drags, fix the owner, access, or timing before go-live.
What mistakes cause the longest launch delays?
Teams often leave ownership in chat, keep one admin login for payments, or let an agency control DNS or email without launch coverage. Auth alerts sent to one private inbox cause the same problem. Those gaps stay hidden until the release window gets tight.
What should a rollback rule look like?
Write one clear trigger tied to a customer-facing problem. For example, revert if checkout errors stay above a set rate for 10 minutes. A plain threshold works better than a vague rule like rolling back when things feel bad.
Where should we keep the escalation tree?
Keep it next to the release plan and rollback steps in one place the whole team can open fast. Update it after every launch while the details are fresh, so phone numbers, access, and ownership stay current.


